一、背景
现代软件部署中,容器技术已成为不可或缺的一环,在云计算和微服务架构中发挥着核心作用。随着容器化应用的普及,确保容器环境的可靠性成为了一个至关重要的任务。这就是容器SRE(Site Reliability Engineering,站点可靠性工程)的职责所在。容器SRE工程师不仅要保证系统的高可用性,还需要优化运行效率,确保系统在各种压力和突发情况下的韧性。
然而,容器SRE的工作常常是背后默默的付出,通常涉及着大量看似琐碎却极其关键的维护任务。例如某一天,你可能发现K8s集群中的Kubelet进程CPU使用异常飙高,这就需要容器SRE工程师立即介入,进行深入的诊断和问题排查,避免类似问题成为生产环境中的隐患。这种排查过程往往涉及复杂且难以预测的环境,通常需要SRE工程师具备高度的专业知识和快速应变能力。因此,虽然容器SRE工程师的努力可能不为大众所见,但对于现代依赖软件和云服务的任何系统来说,这些工作显得尤为严谨和重要。
通过本文,我们将深入探讨容器SRE在日常工作中面临的挑战和如何通过专业技能和创新技术方案来定位和解决问题,确保技术平台的稳健运行。这些看似"摸不着头脑"的琐碎事务,实际上是确保企业技术架构弹性和可靠性的关键所在。
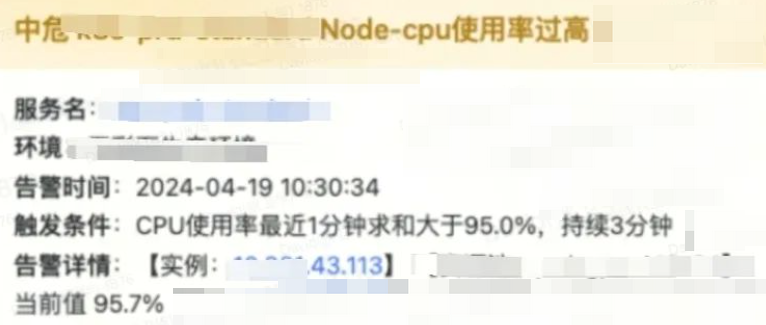
2024.4.19日,一条普通的宿主机Node CPU告警引起了我们的关注,自此开始了排查的旅程......
二、问题现象
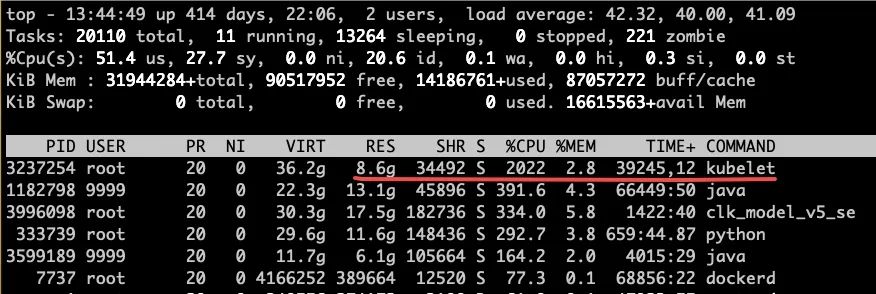
容器单机上容器管理组件Kubelet CPU和内存过高,Kubelet进程的资源使用在top命令中一直处于遥遥领先的位置,CPU占用2022%(为正常实例200倍),内存占用8.6G,这里我们以机器43.113为例排查分析。
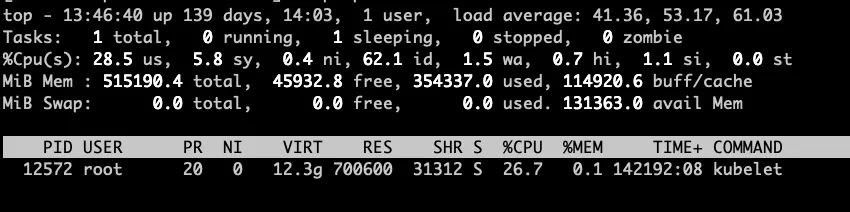
我们从集群中随机抽取多台配置相同的机器进行对比分析:正常的Kubelet CPU占用26.7%,内存占用仅在700M左右,K8s单机的Kubelet进程作为单机的管控程序,资源占用不会出现如此大的波动。
经过单机和多台主机对比分析,我们可以确定主机43.113的Kubelet进程出现了异常,那么是什么原因导致的CPU和内存使用飙升呢?
首先我们想到的是从宿主机43.113整体状况和Kubelet进程两个方向进行分析,从宿主机维度分析为了确定是否单机负载或者进程异常导致Kubelet异常,从进程维度排查是为了定位Kubelet资源异常使用具体原因。当然,这两个维度的分析也并不是独立进行,中间分析过程中可能会涉及到多次的交替验证过程。
三、问题分析
1. 单机整体分析
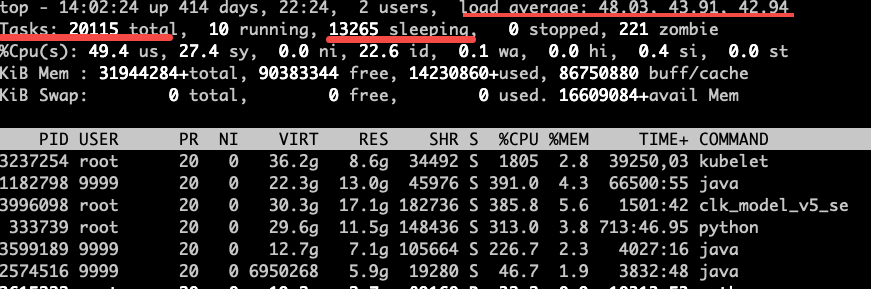
首先,我们整体交代一下43.113整体环境信息:
-
硬件规格及资源:vCPU为48核、内存310GiB;
-
操作系统内核:操作系统为云厂商提供的操作系统,内核版本4.19.91-26.6.al7.x86_64;
-
近期负载:1分钟、5分钟、15分钟负载分别为48.03、43.91和42.94,与单机的48核vCPU来讲,负载正常(一般的排查经验是运行负载小于<1.5vCPU,则表明机器负载并不过高,但是高负载并完全对等CPU饱和)。
通过在主机上运行top命令,我们可以发现尽管单机负载在合理范围内,但是单机的进程数量存在过大的情况,48个vCPU单机运行的进程总量有20155个(Linux内核中一般称作Task任务),运行中的进程仅有10个,处于睡眠状态(Sleeping)的进程有13265个。为了定位进程的数量异常,我们继续使用"ps | wc -l"命令进行了再次确认,系统中的确存在2万多个进程。
$ ps aux|wc -l20135基于ps详情进行进一步确认分析,我们可发现数量众多的"jbd2/vdnx-y/jbd2-ckpt/vdx"格式的进程,"xxx"格式的任务属于内核线程,由内核进行管理和分配,比如我们常见的用于管理内核软中断管理的ksoftirqd/7。内核中的线程一般都是针对某类资源进行管理,前缀一般为会表明内核作用,比如"ksoftirqd"就代表内核软中断处理,7表示为系统CPU#7上运行。通过查询资料,确认了"jbd2/vdx-y"格式中的jbd2代表的是:Journaling Block Device2,jbd2是Ext4文件系统中实现日志文件系统的组件,其工作原理是通过记录对文件系统所做的更改来提高数据的完整性和恢复能力。在系统崩溃或非正常关机的情况下,日志可以用来恢复文件系统到早期一致的状态,减少数据损坏的风险。
通过内核线程数量确认,内核线程总量为19798,为以jbd2/vdx-y开头的内核线程有12769个,ext4-rsv-conver内核线程的数量为6385个,两者总和为19154个,占内核线程的97%。同时在进程详情中,还有个明显的特征基本上3个内核线程为一组,比如jbd2/vdfiw-8、jbd2-ckpt/vdfiw和ext4-rsv-conver,后续类似基本上都有这种特征,初步判断这一组内核线程是针对设备vdfiw(/dev/vdfiw-8)在内核中的进行管理的一组内核线程。
$ ps aux|grep '\['|wc -l # 内核线程总量
19798
$ ps aux|grep '\[jbd2'|wc -l # 内核线程以 jbd2 开头的总量
12769
$ ps aux|grep -v '\[jbd2'|grep ext4-rsv-conver |wc -l # 内核中 ext4-rsv-conver 的线程数量
6385
$ ps aux|grep '\['|more
...
root 1951 0.0 0.0 0 0 ? S Feb01 0:00 [jbd2/vdfiw-8]
root 1952 0.0 0.0 0 0 ? S Feb01 0:00 [jbd2-ckpt/vdfiw]
root 1953 0.0 0.0 0 0 ? I< Feb01 0:00 [ext4-rsv-conver]
root 2078 0.0 0.0 0 0 ? I< 2023 4:26 [kworker/6:1H-kb]
root 3009 0.0 0.0 0 0 ? S Feb01 0:00 [jbd2/vdfjp-8]
root 3010 0.0 0.0 0 0 ? S Feb01 0:00 [jbd2-ckpt/vdfjp]
root 3011 0.0 0.0 0 0 ? I< Feb01 0:00 [ext4-rsv-conver]
...以设备vdfiw为例:
-
jbd2/vdfiw-8是一个与jbd2(Journaling Block Device version 2)内核文件操作日志系统存储的的内核线程;
-
jbd2-ckpt/vdfiw是一个特定于jbd2的内核线程,其中ckpt代表"checkpoint"(检查点)。在jbd2和使用它的文件系统(如ext4)中,检查点是一种机制,用于定期将日志中的信息转移到文件系统本身,以减少在系统崩溃后恢复所需的时间;
-
ext4-rsv-conver则是ext4由实现用于处理来自写回的转换工作,即"需要未写入的扩展处理并保留事务的已完成IO"。
文件系统是否启用日志文件功能,可通过dumpe2fs命令进程检查确认:
dumpe2fs /dev/vdc | grep has_journal
dumpe2fs 1.43.5 (04-Aug-2017)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
通过"df"命令查看设备vdfiw的详情:
df |grep vdfiw/dev/vdfiw 308521792 56841364 251664044 19% /var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount本机磁盘/dev/vdfiw为通过K8s存储机制动态挂载的磁盘设备,在K8s持久化存储通过PV/PVC机制进行管理,由单机负责管理存储的进程负责磁盘的创建和挂载(这里的场景为ESSD远端云盘)。简单一点讲,在K8s中,持久卷(PV)是集群中预先配置的一块存储空间,而持久卷申领(PVC)则像是存储空间的"订票",用户通过PVC来请求使用特定大小和特性的存储空间。通过PV/PVC机制就可实现使用存储的业务实例,不再用关心存储空间的创建,只需要声明所需存储空间即可,整个存储空间分配、挂载和释放的过程都是有K8s系统中的存储插件负责(存储一般为云厂商提供)。
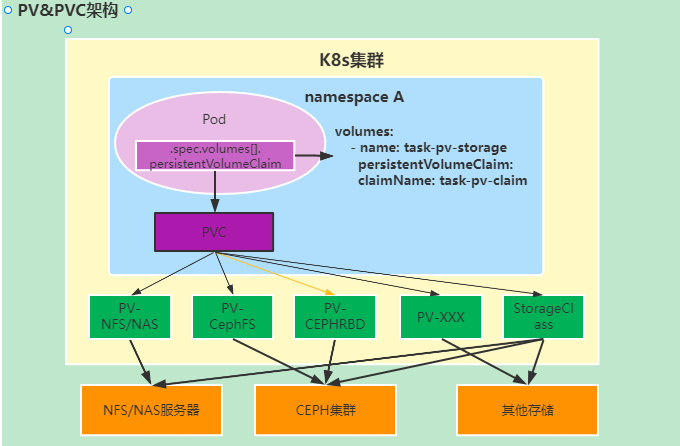
经过和单机上运行任务的业务方确认,这台机器上运行的Job任务实例(并非长期运行的任务)会在运行的时候声明存储空间,在Job任务运行完成后释放存储空间。
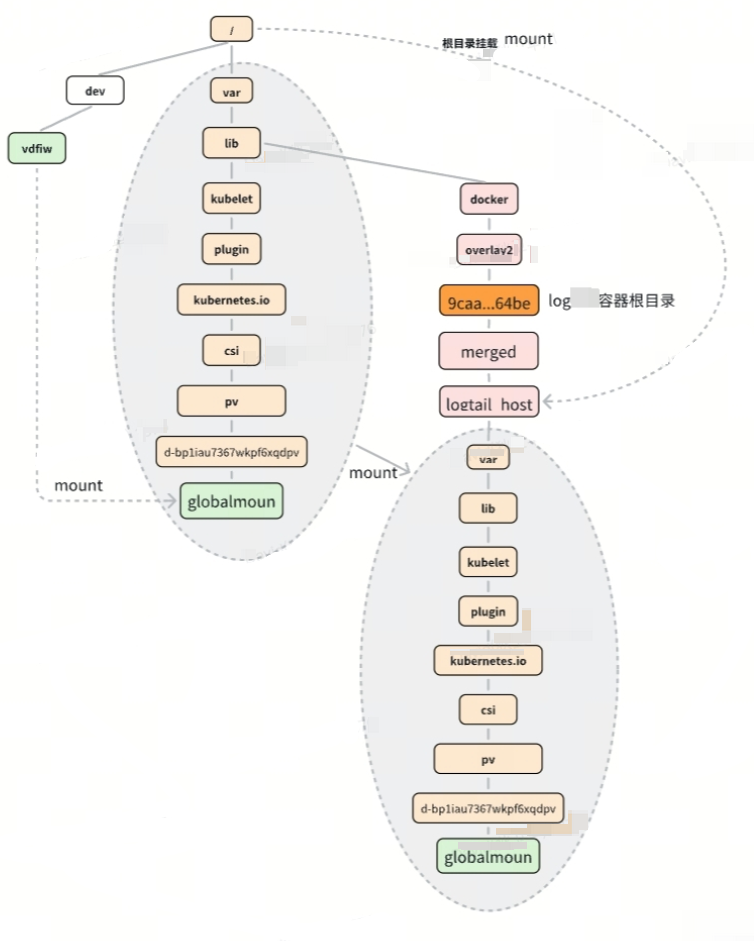
排查到此,我们可确定众多的内核线程与单机频繁的云盘挂载和释放有关。以jbd2-ckpt/vdfiw为例,vdfiw为本地挂载的磁盘的编号,设备挂载在路径/dev/vdfiw中,在K8s系中使用,会将设备目录挂载到:
/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount,但同时,K8s中挂载的文件也被该挂载到某个容器的根目录:
/var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount。请记住这个特殊目录,后续我们的突破口也将在这里。
单机中/var/lib/container/docker通过挂载bind的方式到/var/lib/docker中,两者可以认为是同一个目录,/var/lib/kubelt类型。
挂载关系如下图所示:
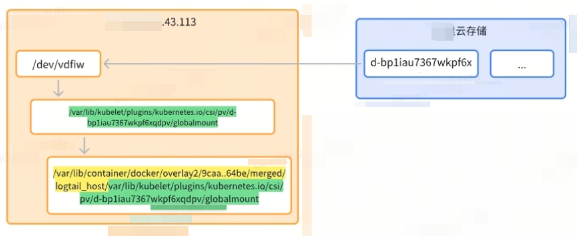
命令行详情:
$mount|grep vdfiw
/dev/vdfiw on /var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount type ext4 (ro,relatime)
/dev/vdfiw on /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount type ext4 (ro,relatime)在确定了磁盘/dev/vdfiw挂载情况后,经过排查发现在系统存在6385个类似于/dev/vdfiw场景的磁盘设备,也就是意味着本地挂载的远程磁盘数量有6385 个。而本地真正挂载的磁盘却非常少,这是属于磁盘挂载异常导致。
$lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
vdiko ext4 0442c714-4a4d-4d2b-8771-038edaefcf3f /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/kubelet/pods/e2c23872-1f
vdb ext4 ef9f6dfa-d518-44f9-914f-b141ff423191 /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/opt/hybrid-data
vdiau ext4 e403a2ef-2e1d-4cb7-9382-8ca33637c381 /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/kubelet/pods/da088c11-29
vdc ext4 34c4dbcf-d514-4948-94fe-81ccf6ae5c90 /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/container
vda
└─vda1 ext4 1612a49b-a79d-4e87-819a-a5bad80fe2a9 /var/lib/container/docker/overl远端磁盘要在K8s和容器中使用必须需要针对设备进行挂载操作,通过排查挂载信息,可以看到有26503条单机磁盘类挂载为Ext4的记录,其中12777条mount记录都齐刷刷挂载到某个特殊目录,/var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/目录中。
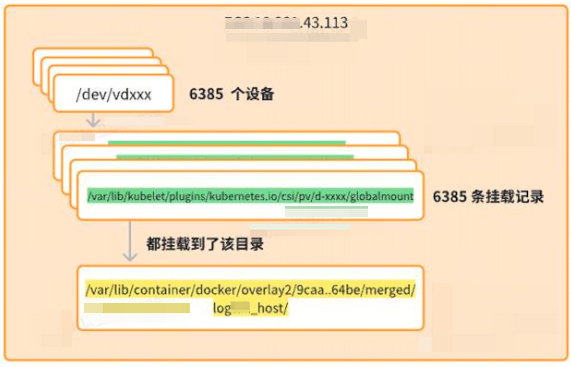
$ mount |grep '/dev/vd' |awk '{print $1}'|sort|uniq|more
/dev/vda1
/dev/vdaa
/dev/vdaaa
....
$mount |grep '/dev/vd' |awk '{print $1}'|sort|uniq|wc -l
6385
$ mount |grep "/dev/vd"| wc -l
26503
$ mount |grep '/dev/vd' |grep -v 9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be|wc -l
12777既然所有的本地磁盘都挂载到了这个特殊的容器目录,那么我们就需要看看这个容器目录到底归属于何方神圣?通过检查本地所有容器的挂载目录,我们将线索定位到了 logxxx-ds-hsbv9容器。
$ docker inspect `docker ps -a | awk '{ print $1}'|grep -v CONTAINER` > /tmp/docker_inspect.log
$ grep 9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be /tmp/docker_inspect.log 定位到容器 ID e4261544f8eb
nspect.log 定位到容器 ID e4261544f8eb通过docker ps -a基于容器ID过滤,可发现这个特殊的容器为k8s_logxxx_logxxx-ds,为云厂商日志采集的单机容器实例logxxx-ds-hsbv9 ,而该容器实例卡在了一个称之为Removal In Progress的状态。
$ docker ps -a|grep e4261544f8ebe4261544f8eb 889ceee008bf "/usr/local/ilogxxx..." 8 months ago Removal In Progress k8s_logxxx_logxxx-ds-hsbv9_kube-system_93e182b4-ed88-4344-8c8d-e22af0407be8_0进一步通过docker inspect检查该容器删除的状态信息,可以看到该容器由于自己的根目录清理出错一直卡在被删除阶段,从而导致旧的容器实例异常。
$ docker inspect e4261544f8e
[
{
"Id": "e4261544f8eb355ee438c61a5c121217d54b54244d2957e495aa234f77444288",
"Created": "2023-07-25T07:23:28.927382459Z",
"Path": "/usr/local/ilogxxx/run_logxxx.sh",
"Args": [],
"State": {
"Status": "dead",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": true,
"Pid": 0,
"ExitCode": 137,
"Error": "container e4261544f8eb355ee438c61a5c121217d54b54244d2957e495aa234f77444288: driver \"overlay2\" failed to remove root filesystem: unlinkat /var/lib/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged: device or resource busy",
"StartedAt": "2023-07-25T07:23:29.135183205Z",
"FinishedAt": "2023-08-15T06:18:44.69693858Z"
},而上述出错的文件目录我们进行查看并没有任何文件:

简单来说就是这个文件目录已经被清空,但是还在被其他地方引用。
看到这里你一定会比较好奇,为什么所有的磁盘记录有会挂载到容器logxxx-ds-hsbv9中?
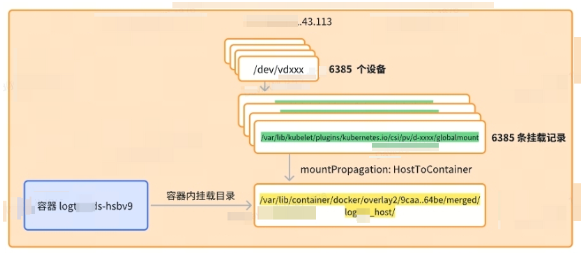
我们可以通过检查logxxx-ds的YAML文件可以看到端倪:
kubectl get ds logxxx-ds -o yaml -n kube-system
apiVersion: apps/v1
kind: DaemonSet
spec:
spec:
containers:
...
volumeMounts:
- mountPath: /var/run
name: run
- mountPath: /logxxx_host
mountPropagation: HostToContainer
name: root
readOnly: true
volumes:
- hostPath:
path: /var/run
type: Directory
name: run
- hostPath:
path: /
type: Directory
name: root可以看到logxxx-ds-hsbv9实例会将宿主机的根目录挂载到容器根目录下的 /logxxx_host目录下。
这里会涉及到一些容器文件与宿主机目录文件共享 的机制,这里简单基于当前挂载进行介绍。这里的场景是logxxx-ds-hsbv9实例要搜集单机上的日志目录,所以它需要能够在容器里面访问主机上所有主机文件且感知宿主机上的文件的变化能力,但是主机上并需要感知logxxx-ds-hsbv9在该目录下的操作变化,因此这是一个单向的传播关系。
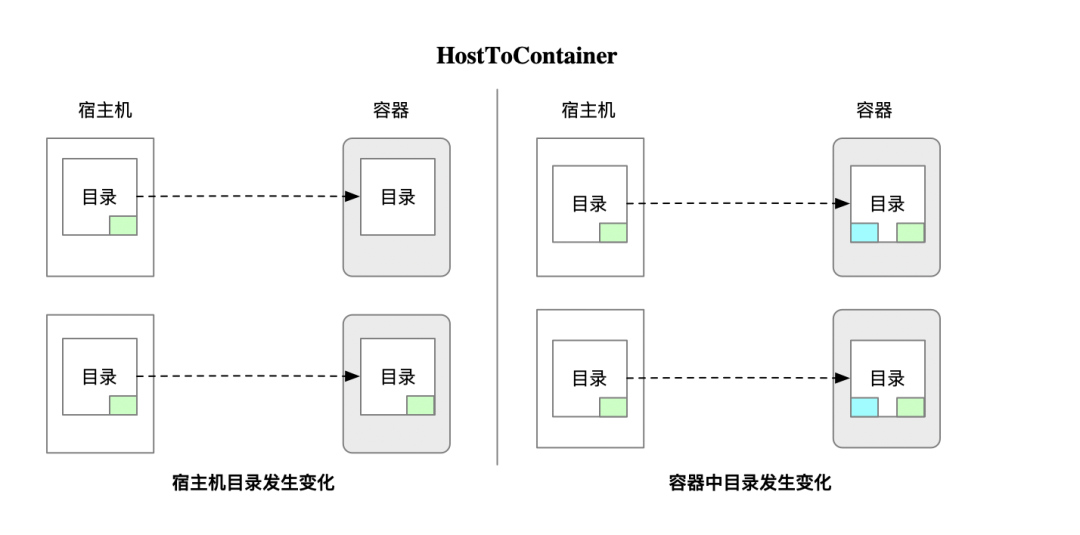
这里的挂载选项mountPropagation: HostToContainer就是实现了个效果:
- HostToContainer:宿主机上挂载到容器中的目录,宿主机目录中的变化,容器中单向可见。反之,容器中目录的变化对宿主机中的目录不可见。
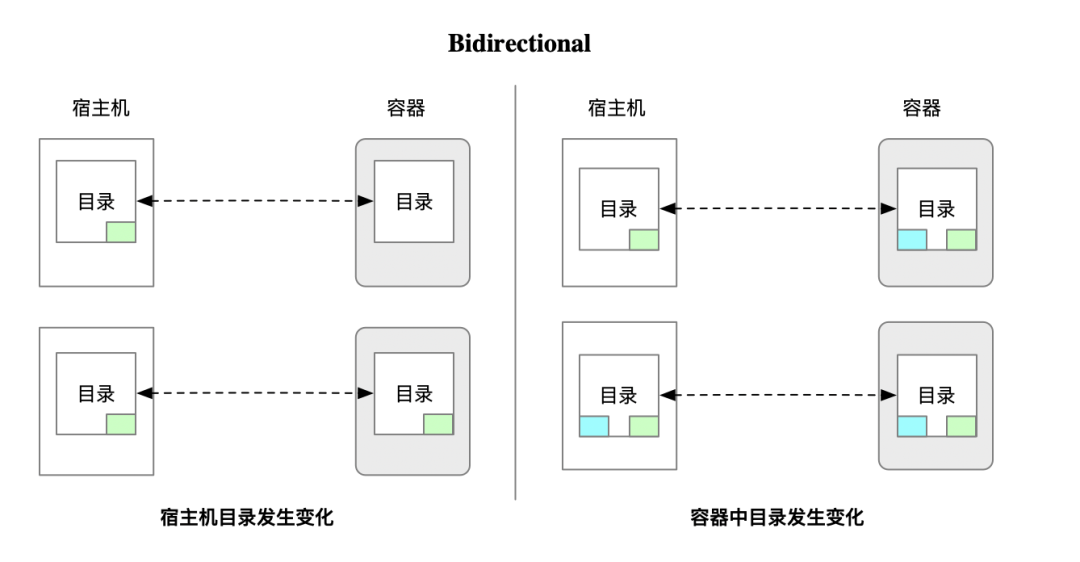
- Bidirectional:宿主机上挂载到容器中的目录,无论是在宿主机还是在容器中的变化,宿主机和容器中都可见。
基于上述的整体挂载关系,单个磁盘设备挂载的整体关系可在下图中得到展示:
2. 单机分析初步结论
到此,针对单机的分析我们大概有个初步结论:系统中出现了6385个挂载的设备,这些设备在内核中每个启动了3个对应的内核线程,导致整个系统出现了20000多个内核线程,这些出现异常的设备基本都是容器单机通过K8s持久卷的挂载机制挂载到K8s目录,同时由于logxxx-ds-hsbv9容器挂载了整个根目录,所以导致磁盘挂载到 k8s的目录也挂载到了 logxxx的logxxx_host路径下。系统中有将近6385个设备都遵循了这个上述图中的挂载机制,所以导致logxxx-ds-hsbv9的挂载记录众多。容器logxxx-ds-hsbv9实例则在删除merged子设备的时候报错**"device or resource busy"**卡主了。问题分析到这里单机侧有了一个初步方向,我们将方向再转向CPU和内存都占用异常的Kubelet进程。
3. Kubelet进程资源占用分析
首先,查看Kubelet日志,通过最近几分钟的日志分析发现了大量的相似报错,短短几分钟内的日志报错就多达4000条Operation for "{volumeName:kubernetes.io/csi/diskplugin.csi.xxx.com^d-bp1dtkaipms3op820vnb podName: nodeName:}" failed。
$ journalctl -u kubelet --no-pager --since="2024-04-12 15:25"
Apr 12 15:28:39 k8s-prd-standard-43.113 kubelet[3237254]: E0412 15:28:39.437193 3237254 nestedpendingoperations.go:301] Operation for "{volumeName:kubernetes.io/csi/diskplugin.csi.xxx.com^d-bp1dtkaipms3op820vnb podName: nodeName:}" failed. No retries permitted until 2024-04-12 15:30:41.437168443 +0800 CST m=+21254165.582404754 (durationBeforeRetry 2m2s). Error: "GetDeviceMountRefs check failed for volume \"d-bp1dtkaipms3op820vnb\" (UniqueName: \"kubernetes.io/csi/diskplugin.csi.xxx.com^d-bp1dtkaipms3op820vnb\") on node \"k8s-prd-standard-43.113\" : the device mount path \"/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1dtkaipms3op820vnb/globalmount\" is still mounted by other references [/var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1dtkaipms3op820vnb/globalmount /var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1dtkaipms3op820vnb/globalmount /var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1dtkaipms3op820vnb/globalmount]"
...看日志描述会略微费劲,简单总结一下就是:
"我打算移除这个设备d-bp1dtkaipms3op820vnb,但重试过程中遇到了这个设备仍然被/var/lib/container/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged/logxxx_host/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1dtkaipms3op820vnb/globalmount这个目录挂载,删除失败,但是我仍然会持续重试"。
我们从K8s的磁盘挂载文件PV中去查询d-bp1dtkaipms3op820vnb这个设备,发现该PV已经被移除,同时通过云厂商产品控制台以该ID查询也发现磁盘已经被释放了。
ID为d-bp1dtkaipms3op820vnb磁盘在2023-08-21号已经被释放。
到这里简单总结异常的整体的关系流程图如下所示:
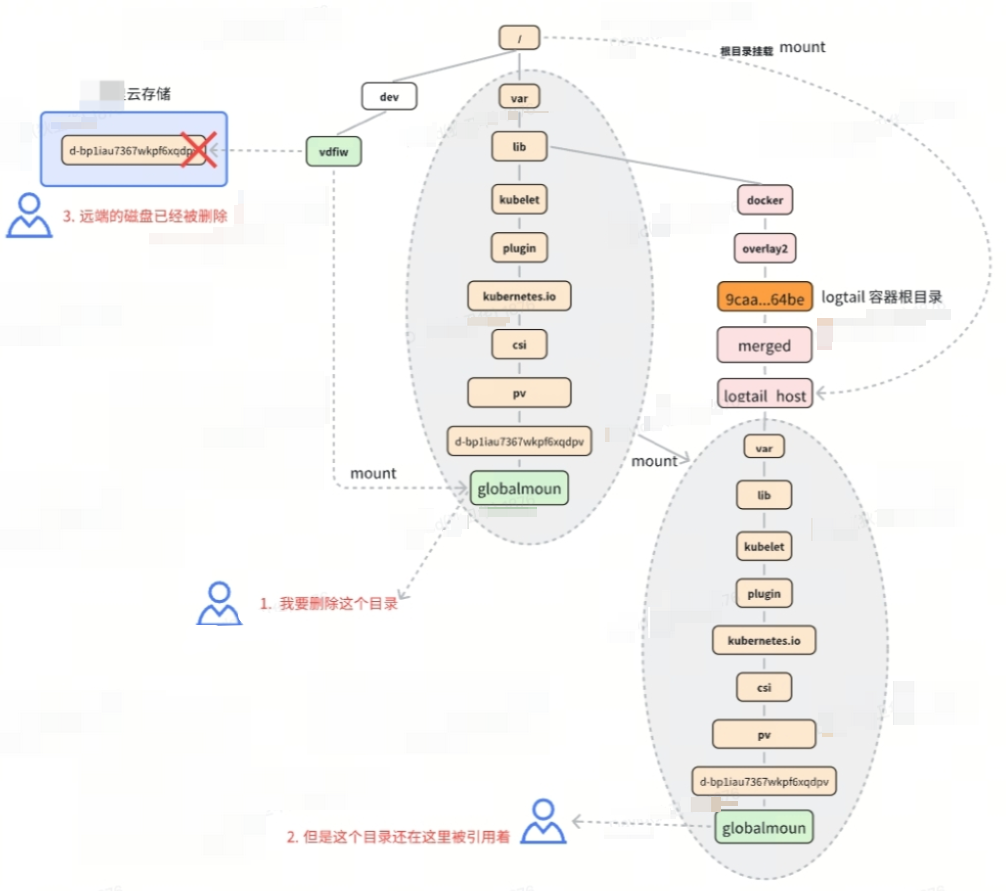
没有例外,我们前面分析的样例/dev/vdfiw on /var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount,也在这个错误的日志中。

通过Kubelet的日志报错分析,发现在删除PV挂载的远端云磁盘时,发现磁盘的挂载路径仍然被logxxx-ds-hsbv9的路径挂载,因此删除出错,由于系统长时间运行异常积累了6000多个磁盘设备,因此每个轮训周期中都要进行大量设备的删除重试,而且这个重试是持续进行中。Kubelet的报错日志与我们分析单机挂载设备能够完全匹配。
为了验证Kubelet CPU占用的高的确是由于大量设备卸载报错导致,这里针对Kubelet进行了一次性能数据分析。我们从单机的Kubelet采集了CPU的pprof文件进行分析,结果与预期一致,的确是由于数量众多的删除失败和重试导致了Kubelet CPU使用率异常,80.88%的CPU都在进行挂载点删除的操作(与Kubelet日志报错完全吻合: kubelet3237254: E0412 15:36:39.827608 3237254 nestedpendingoperations.go:301] Operation for)。
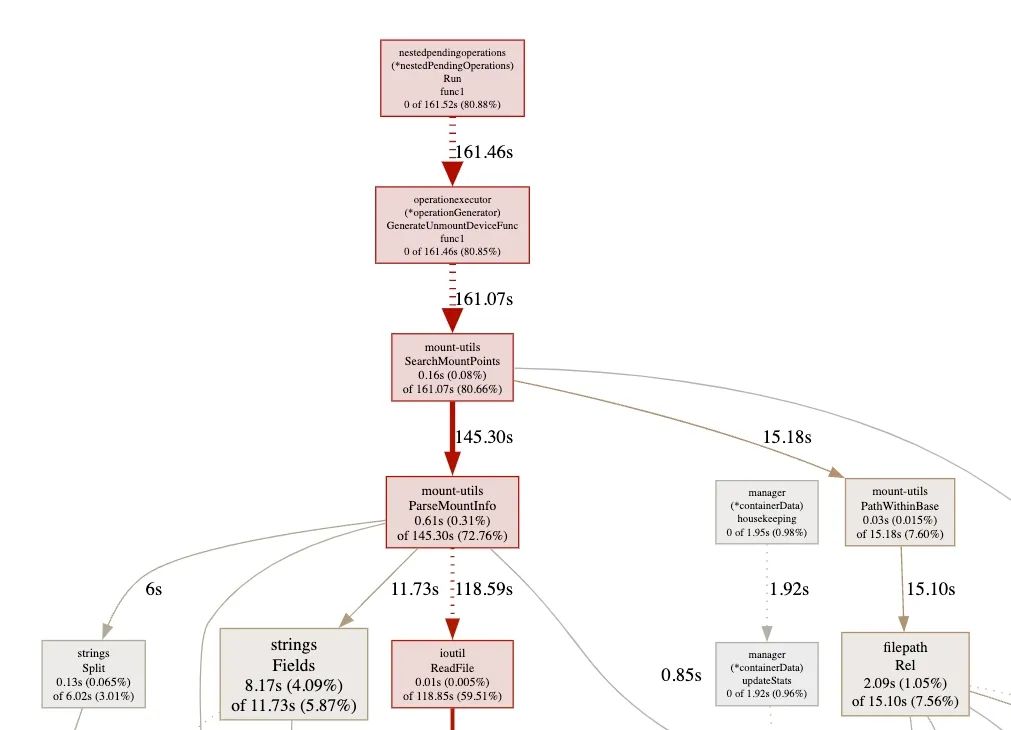
4. Kubelet分析初步结论
至此,我们完成了Kubelet单机CPU异常的分析:
-
Kubelet删除挂载设备失败,失败原因是设备目录被logxxx容器占用,锲而不舍的持续删除,接近81%的CPU使用率消耗在了卸载本地大量挂载的云盘记录上;
-
而删除异常的磁盘设备被云厂商日志产品单机实例logxxx-ds-hsbv9挂载占用,持续重复卸载失败。
-
挂载设备目录的的logxxx-ds-hsbv9容器,删除过程中卡在了容器目录的删除上。
那么是否解决了logxxx-ds-hsbv9本地容器删除失败的情况,所有非法被占用的设备挂载就可以释放,让Kubelet恢复正常呢?带着这个问题,我们持续往下跟踪分析。
四、根因确定
既然所有的问题都指向了这个卡在"Removal In Progress"状态logxxx-ds-hsbv9容器,相信它就是打开单机异常的钥匙🔑。
该容器卡在删除失败的问题是,删除自己的时候自己的容器挂载根目录"device or resource busy" 。
"Error": "container e4261544f8eb355ee438c61a5c121217d54b54244d2957e495aa234f77444288: driver \"overlay2\" failed to remove root filesystem: unlinkat /var/lib/docker/overlay2/9caa9580e946898718f97e9d205d0ac34048d5242ea30c0bc859627483b664be/merged: device or resource busy",前面我们提到过,手工查看logxxx-ds-hsbv9容器的merged下面为空,通过查看docker源码发现unlinkat针对目录的操作底层与rmdir删除一致,因此我们可以简单通过rmdir删除目录进行重现分析(unlinkat会尝试以文件删除,如果删除发现是目录则设置函数flag以目录方式递归删除)。
不出意外,使用rmdir删除也是同样报错:
$ rmdir /var/lib/container/docker/overlay2/9caa..64be/merged
rmdir: failed to remove '/var/lib/container/docker/overlay2/9caa..64be/merged': Device or resource busy通过分析rmdir的内核代码实现,最终定位到删除失败的函数范围是在目录挂载点的函数判断上(具体分析方式可参见no space left问题定位过程(https://www.ebpf.top/post/no_space_left_on_devices/):
bool __is_local_mountpoint(struct dentry *dentry)
{
struct mnt_namespace *ns = current->nsproxy->mnt_ns;
struct mount *mnt;
bool is_covered = false;
if (!d_mountpoint(dentry))
goto out;
down_read(&namespace_sem);
list_for_each_entry(mnt, &ns->list, mnt_list) {
is_covered = (mnt->mnt_mountpoint == dentry);
if (is_covered)
break;
}
up_read(&namespace_sem);
out:
return is_covered;
}简单总结就是尝试删除merged目录时候,这个目录还在系统中存在挂载关系。尝试通过挂载在merged目录下的logxxx_host文件访问,我们发现仍然能够访问,说明尽管merged目录下的内容虽然表面看被删除了,但是其目录下的挂载点仍然存在,导致merged目录不能够被正常删除。
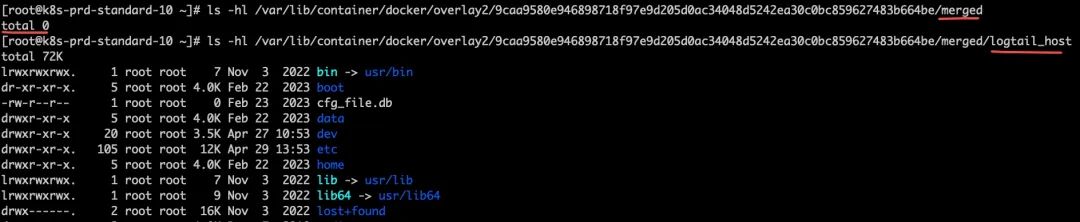
当尝试访问云盘挂载的根目录会出现Input/output error的错误,这是因为K8s中的存储插件已经将该目录对应的 /dev/vdfiw 设备在远端删除所导致。
$ ls -hl /var/lib/container/docker/overlay2/9caa...64be/merged/logxxx_host/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount/
ls: reading directory /var/lib/container/docker/overlay2/9caa...64be/merged/logxxx_host/var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1iau7367wkpf6xqdpv/globalmount/: Input/output error继续在内核日志中查找线索(在内核日志中搜索vdfiw):
grep "vdfiw" /tmp/dmsg.log
[Mon Apr 8 10:19:15 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Mon Apr 8 10:19:15 2024] EXT4-fs error (device vdfiw): __ext4_get_inode_loc:4317: inode #2: block 1095: comm find: unable to read itable block
[Mon Apr 8 10:19:15 2024] EXT4-fs error (device vdfiw) in ext4_reserve_inode_write:5543: IO failure
[Mon Apr 8 10:19:21 2024] Aborting journal on device vdfiw-8.
[Mon Apr 8 10:19:21 2024] JBD2: Error -5 detected when updating journal superblock for vdfiw-8.
[Mon Apr 8 11:05:38 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Mon Apr 8 13:29:36 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Tue Apr 9 10:20:55 2024] EXT4-fs (vdfiw): error count since last fsck: 2
[Tue Apr 9 10:20:55 2024] EXT4-fs (vdfiw): initial error at time 1712543485: __ext4_get_inode_loc:4317
[Tue Apr 9 10:20:55 2024] EXT4-fs (vdfiw): last error at time 1712543485: ext4_reserve_inode_write:5543
[Wed Apr 10 10:48:53 2024] EXT4-fs (vdfiw): error count since last fsck: 2
[Wed Apr 10 10:48:53 2024] EXT4-fs (vdfiw): initial error at time 1712543485: __ext4_get_inode_loc:4317
[Wed Apr 10 10:48:53 2024] EXT4-fs (vdfiw): last error at time 1712543485: ext4_reserve_inode_write:5543
[Thu Apr 11 11:16:52 2024] EXT4-fs (vdfiw): error count since last fsck: 2
[Thu Apr 11 11:16:52 2024] EXT4-fs (vdfiw): initial error at time 1712543485: __ext4_get_inode_loc:4317
[Thu Apr 11 11:16:52 2024] EXT4-fs (vdfiw): last error at time 1712543485: ext4_reserve_inode_write:5543
[Fri Apr 12 09:49:08 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Fri Apr 12 09:49:08 2024] EXT4-fs error (device vdfiw): ext4_journal_check_start:61: Detected aborted journal
[Fri Apr 12 09:49:08 2024] EXT4-fs (vdfiw): Remounting filesystem read-only
[Fri Apr 12 09:49:39 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Fri Apr 12 09:56:20 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm find: error -5 reading directory block
[Fri Apr 12 11:44:50 2024] EXT4-fs (vdfiw): error count since last fsck: 4
[Fri Apr 12 11:44:50 2024] EXT4-fs (vdfiw): initial error at time 1712543485: __ext4_get_inode_loc:4317
[Fri Apr 12 11:44:50 2024] EXT4-fs (vdfiw): last error at time 1712887285: ext4_journal_check_start:61
[Fri Apr 12 14:36:00 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm ls: error -5 reading directory block
[Fri Apr 12 14:36:44 2024] EXT4-fs warning (device vdfiw): htree_dirblock_to_tree:995: inode #2: lblock 0: comm ls: error -5 reading directory block内核中的针对磁盘/dev/vdfiw磁盘的错误error (device vdfiw): __ext4_get_inode_loc:4317: inode #2: block 1095: comm find: unable to read itable block ,表明查询挂载磁盘失败,内核线程卡在异常场景上。本地系统中对应的/dev/vdfiw所对应的远程云盘已经被移除,而本地的磁盘/dev/vdfiw对应的内核线程jbd2/vdfiw-8和jbd2-ckpt/vdfiw等则出现了异常。经和云厂商工单处理人确认,所对应的磁盘2024-02-01已经在后台被移除。
我们初步推断是由于设备挂载的目录对应云盘提前卸载,在容器清理访问过程中出现 Input/output error异常错误,导致整个清理过程不能够在容器侧通过unlikat操作正常进行。
五、修复验证测试
既然所有的症结是云盘非预期挂载在logxxx-ds-hsbv9容器实例的merged目录下,那么我们只需要手工减掉这个依赖,那么理论上Kubelet删除挂载的PV就会成功,挂载云盘所对应的内核线程也可能会自动退出。我找了一台已经隔离的机器进行验证验证测试,在手动卸载容器实例前,先检查内核线程、磁盘、磁盘挂载记录和内核日志等进行确认。
1. 手动卸载单条记录确认
内核线程确认(这里以/dev/vdmgd为例):
$ ps aux|grep vdmgd
root 1078726 0.0 0.0 0 0 ? S 20:11 0:00 [jbd2/vdmgd-8]
root 1078727 0.0 0.0 0 0 ? S 20:11 0:00 [jbd2-ckpt/vdmgd]本地磁盘确认:
$ df |grep vdmgd
/dev/vdmgd 挂载记录确认:
$ mount |grep d-bp1gr027v6iq2etcfsvk
/dev/vdmgd on /var/lib/kubelet/plugins/kubernetes.io/csi/pv/d-bp1gr027v6iq2etcfsvk/globalmount type ext4 (rw,relatime)
/dev/vdmgd on /var/lib/container/docker/overlay2/f605aea15446c49d10108264b5f377a022e9c7c041487deb0c70189bf07a49c7/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1gr027v6iq2etcfsvk/globalmount type ext4 (rw,relatime)挂载点访问确认:
$ ls -hl /var/lib/container/docker/overlay2/f605aea15446c49d10108264b5f377a022e9c7c041487deb0c70189bf07a49c7/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1gr027v6iq2etcfsvk/globalmount
ls: reading directory /var/lib/container/docker/overlay2/f605aea15446c49d10108264b5f377a022e9c7c041487deb0c70189bf07a49c7/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1gr027v6iq2etcfsvk/globalmount: Input/output error进行到验证阶段,手动卸载这条泄露的挂载记录:
$ umount /var/lib/container/docker/overlay2/f605aea15446c49d10108264b5f377a022e9c7c041487deb0c70189bf07a49c7/merged/logxxx_host/var/lib/container/kubelet/plugins/kubernetes.io/csi/pv/d-bp1gr027v6iq2etcfsvk/globalmount手动卸载完成后,经过确认对应的内核线程、本地磁盘、挂载记录都已经消失、挂载点访问也恢复正常。
检查内核日志发现,手动释放挂载记录后,内核进程在异常报错后,没有再持续进行报错,逐步退出。

2. 全部清理确认
动清理泄露挂载记录,清理完成后,发现Kubelet恢复到正常的CPU水位线,CPU性能分析也恢复正常。
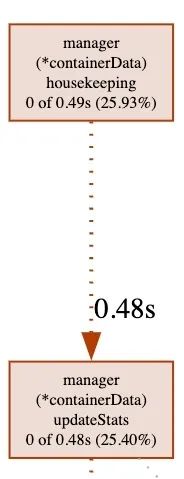
随着挂载记录逐步被移除,单机的磁盘挂载记录也被正常卸载。

同时内核线程也开始正常消失,整个机器负载基本恢复正常。

至此整个流程得到了验证,内核进程(任务)数量和kubelet进程已经恢复正常。
六、总结
至此这个问题根因总算水落石出,验证方式也得到了确认,问题的触发会有几个条件同时作用:
-
日志采集单机容器实例挂载了Linux系统根目录,主机挂载记录全部传递到日志采集单机的容器实例中;
-
运行的服务使用K8s持久存储挂载远程云盘,挂载到本地的磁盘开启了日志功能;
-
单机运行的服务频繁申请远程云盘,云厂商提供的存储插件提前卸载远程云盘,使得磁盘挂载记录持续泄露;
-
设备文件系统日志功能的内核线程,在远端云盘被删除后的异常场景,并不会异常终止,而是持续重试;
上述的这些条件作用在一起,可能导致容器侧在挂载点清理过程异常,导致挂载记录无法清除和对应内核线程无法终止,最终导致大量内核线程遗留和单机Kubelet CPU 使用非预期过高。整个过程的排查和解决需要涉及到云厂商日志采集、存储插件和内核等多个产品在异常场景下的协同流程。
后续我们会加强单机设备挂载和单机残留容器指标的监控,能够在问题早期就能够发现和处理;同时我们也将这个情况反馈到了云厂商侧,希望能够从日志采集产品、存储插件和内核侧进行容错规避。