一、特征构建
概述
从原始数据中构建新的特征,一般需要根据业务分析,生成能更好体现业务特性的新特征,这些新特征要与目标关系紧密,能提升模型表现或更好地解释模型。
方法
时间周期:不同的时间切片长度,例如近1个月,近3个月,最近一次,最远一次等;按照上午、下午、晚上等进行构建
特征聚合(求和,均值,方差,最大值,最小值,计数),如地址、手机号数等
修饰词(维度):维度是描述事情的角度 ,依赖于指标,如性别,地区,所属机构等
特征组合
业务角度:地址,正常建模无法直接使用,可进行标准化后,根据用户是否存在频繁更换地址等进行分析;手机号个数等
技术角度:任意特征交叉、log变换、连续值离散化,one-hot编码、woe编码
二、特征提取
概述
将一些原始的输入的数据维度减少或者将原始的特征进行重新组合以便于后续的使用
方法
主成分分析
主成分分析是特征提取中的常用方法,用于数据降维,目的是通过线性变换将原始数据变换为一组各维度线性无关的表示,核心思想n维特征映射到k维空间上k<n,这k维特征是全新的正交特征。
可消除数据的多重共线性。

python
from sklearn.decomposition import PCA
import numpy as np
pca = PCA()
pca.fit(data)
eigenvalues = pca.explained_variance_
eigenvectors = pca.components_
print("特征值:")
print(eigenvalues)
print("特征向量:")
print(eigenvectors)
'''
特征值:
[32.499999999999986, 0.0, 0.0]
特征向量:
[[ 0.57735027 0.57735027 0.57735027]
[ 0.68092061 -0.68092061 0.28205707]
[-0.4472136 0.4472136 -0.77459667]]
'''独立成分分析(ICA)
ICA独立成分分析是从多元(多维)统计数据中寻找潜在因子或成分的一种方法.ICA与其它的方法重要的区别在于,它寻找满足统计独立和非高斯的成分。
线性判别分析(LDA)
LDA是将通过投影的方法,投影到维度更低的空间,使得投影后的点,会形成按类别区分,相同类别的点,将会在投影后更接近,不同类别的点距离越远。
LDA的思想是设法将样本投影到一条直线上,使得:
同类样本的投影点尽可能近
异类样本的投影点尽可能远
LDA也称为Fisher判别分析,是从更利于分类的角度来降维,利用到了训练样本的类别标记,追求的是最能够分开各个类别数据的投影方法。
三、特征筛选
概述
从特征集合中筛选出一组最具统计意义的特征子集,原则:获取尽可能小的特征子集,不显著降低分类精度、不影响分类分布以及特征子集应具有稳定、适应性强等特点。
目的
- 减少特征数量、降维
- 降低学习任务的难度,提升模型的效率
- 使模型泛华能力更强,减少过拟合
- 增强对特征和特征值之间的理解
方法
过滤式(Filter)
Correlation coefficient scores(相关系数)
python
import pandas as pd
import numpy as np
# 假设 df 是包含特征和目标变量的数据框
correlation_matrix = df.corr()
target_column = 'target' # 目标变量的列名
important_features = correlation_matrix[target_column].abs().sort_values(ascending=False)Information gain(信息增益)
信息增益,基于信息熵来计算,它表示信息消除不确定性的程度,可以通过信息增益的大小为变量排序进行特征选择。信息量与概率呈单调递减关系,概率越小,信息量越大。
基于信息增益的特征选择有两种方式,即信息增益和信息增益率。
1) 信息增益,即先验熵到后验熵减少的部分,反映了信息消除不确定性的程度,定义如下:
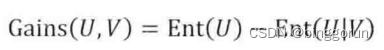
**特征选择原理:**在进行特征选择时,以目标变量作为信息U,由特征变量作为信息V,带入公式计算信息增益,通过信息增益的大小排序,来确定特征的顺序,以此进行特征选择。信息增益越大,表示变量消除不确定性的能力越强。
**缺点:**当接收信号V为全不相同的类别时,将会使Ent(U|V)=0,信息增益将最大。由于每一个V值都是一个类别,对应的U值也只有一个值,取该值的概率为1,这明显是一种过拟合,因此基于信息增益来进行特征选择存在不足。
2)信息增益率
为解决信息增益的不足,在计算信息增益的同时,考虑接收信号V的自身特点,定义信息增益率如下:

当接收信号V具有较多类别值时,它自己的信息熵范围会增大 (即各类别出现的概率相等时,有最大熵Ent(U)=log2k,因此当k较大时,其熵的取值范围更大),而信息增益率不会随着增大,从而消除类别数目带来的影响。
互信息
互信息法是一种基于信息论的特征筛选方法。它通过计算特征与目标变量之间的互信息值来评估特征的重要性。互信息值越大,说明特征与目标变量之间的关联性越强。在Python中,可以使用minepy库来计算互信息值。
Gini-index尼基系数
Chi-squared test(卡方检验)
经典的卡方检验是检验类别型变量对类别型变量的相关性。

Sklearn的实现是通过矩阵相乘快速得出所有特征的观测值和期望值,在计算出各特征的 χ2 值后排序进行选择。在扩大了 chi2 的在连续型变量适用范围的同时,也方便了特征选择。
python
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
x, y = load_iris(return_X_y=True)
x_new = SelectKBest(chi2, k=2).fit_transform(x, y)缺失率
剔除缺失值较多的特征
python
# 特征缺失率
miss_rate_df = df.isnull().sum().sort_values(ascending=False) / df.shape[0]iv(Information Value,信息量)
IV表征特征的预测能力:小于0.02,几乎没有预测能力;小于0.1,弱;小于0.3,中等;小于0.5,强;大于0.5,难以置信,需进一步确认


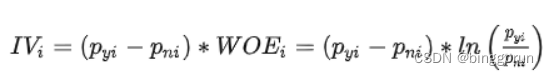
python
#先封装计算IV的方法
def CalcIV(Xvar,Yvar):
N_0=np.sum(Yvar==0)
N_1=np.sum(Yvar==1)
N_0_group=np.zeros(np.unique(Xvar).shape)
N_1_group=np.zeros(np.unique(Xvar).shape)
for i in range(len(np.unique(Xvar))):
N_0_group[i] = Yvar[(Xvar==np.unique(Xvar)[i])&(Yvar==0)].count()
N_1_group[i] = Yvar[(Xvar==np.unique(Xvar)[i])&(Yvar==1)].count()
iv = np.sum((N_0_group/N_0-N_1_group/N_1)*np.log((N_0_group/N_0)/(N_1_group/N_1)))
if iv>=1.0:## 处理极端值
iv=1
return iv
def caliv_batch(df,Yvar):
ivlist=[]
for col in df.columns:
iv=CalcIV(df[col],Yvar)
ivlist.append(iv)
names=list(df.columns)
iv_df=pd.DataFrame({'Var':names,'Iv':ivlist},columns=['Var','Iv'])
return iv_df,ivlist
im_iv, ivl = caliv_batch(datafinal,data_train)
#再进行数据处理:
threshold = 0.02
threshold2 = 0.6
data_index=[]
for i in range(len(ivl)):
if (im_iv['Iv'][i]< threshold)|(im_iv['Iv'][i] > threshold2):
data_index.append(im_iv['Var'][i])
datafinal.drop(data_index,axis=1,inplace=True)psi(Population Stability Index,群体稳定性指标)
一般在风控中会拿0.25来作为筛选阈值,即PSI>0.25我们就认定这个变量或者模型不稳定了。
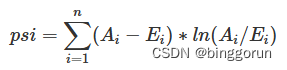
其中,Ai代表第i组的实际占比(占全部数量),Ei代表第i组的期望占比(也就是训练时或者上线时的分组占比)
计算步骤:
step1:将变量预期分布(excepted)进行分箱(binning)离散化,统计各个分箱里的样本占比。
注意:
a) 分箱可以是等频、等距或其他方式,分箱方式不同,将导致计算结果略微有差异;
b) 对于连续型变量(特征变量、模型分数等),分箱数需要设置合理,一般设为10或20;对于离散型变量,如果分箱太多可以提前考虑合并小分箱;分箱数太多,可能会导致每个分箱内的样本量太少而失去统计意义;分箱数太少,又会导致计算结果精度降低。
step2: 按相同分箱区间,对实际分布(actual)统计各分箱内的样本占比。
step3:计 算各分箱内的A - E和Ln(A / E),计算index = (实际占比 - 预期占比)* ln(实际占比 / 预期占比) 。
step4: 将各分箱的index进行求和,即得到最终的PSI。
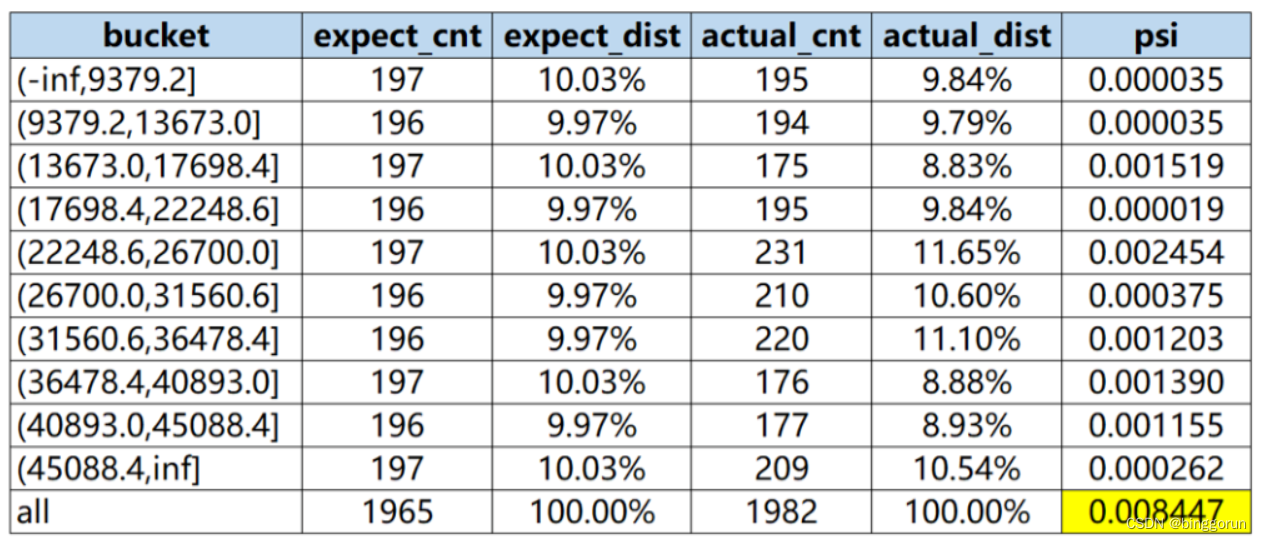
筛选变量
1)选择训练数据,并且确定变量的最优分箱
2)初始化变量的期望占比分布
3)计算变量每个月的变量PSI
4)观察是否有PSI超过0.25的变量,剔除。
python
df = pd.read_csv('../0-数据/var_sample.csv')
def calculate_psi(base_list, test_list, bins=10, min_sample=10):
# @东哥的风控小密圈
try:
base_df = pd.DataFrame(base_list, columns=['score'])
test_df = pd.DataFrame(test_list, columns=['score'])
# 1.去除缺失值后,统计两个分布的样本量
base_notnull_cnt = len(list(base_df['score'].dropna()))
test_notnull_cnt = len(list(test_df['score'].dropna()))
# 空分箱
base_null_cnt = len(base_df) - base_notnull_cnt
test_null_cnt = len(test_df) - test_notnull_cnt
# 2.最小分箱数
q_list = []
if type(bins) == int:
bin_num = min(bins, int(base_notnull_cnt / min_sample))
q_list = [x / bin_num for x in range(1, bin_num)]
break_list = []
for q in q_list:
bk = base_df['score'].quantile(q)
break_list.append(bk)
break_list = sorted(list(set(break_list))) # 去重复后排序
score_bin_list = [-np.inf] + break_list + [np.inf]
else:
score_bin_list = bins
...
# 5.汇总统计结果
stat_df = pd.DataFrame({"bucket": bucket_list, "base_cnt": base_cnt_list, "test_cnt": test_cnt_list})
stat_df['base_dist'] = stat_df['base_cnt'] / len(base_df)
stat_df['test_dist'] = stat_df['test_cnt'] / len(test_df)
def sub_psi(row):
# 6.计算PSI
base_list = row['base_dist']
test_dist = row['test_dist']
# 处理某分箱内样本量为0的情况
if base_list == 0 and test_dist == 0:
return 0
elif base_list == 0 and test_dist > 0:
base_list = 1 / base_notnull_cnt
elif base_list > 0 and test_dist == 0:
test_dist = 1 / test_notnull_cnt
return (test_dist - base_list) * np.log(test_dist / base_list)
stat_df['psi'] = stat_df.apply(lambda row: sub_psi(row), axis=1)
stat_df = stat_df[['bucket', 'base_cnt', 'base_dist', 'test_cnt', 'test_dist', 'psi']]
psi = stat_df['psi'].sum()
except:
print('error!!!')
psi = np.nan
stat_df = None
return psi, stat_df
#现在我们想对LoanAmount借款金额这个单变量,以5月为预期分布6月为实际分布进行稳定性计算。
var = 'LoanAmount'
base = df.loc[df['date']=='2023-05',var]
test = df.loc[df['date']=='2023-06',var]
calculate_psi(base_list=list(base),test_list=list(test))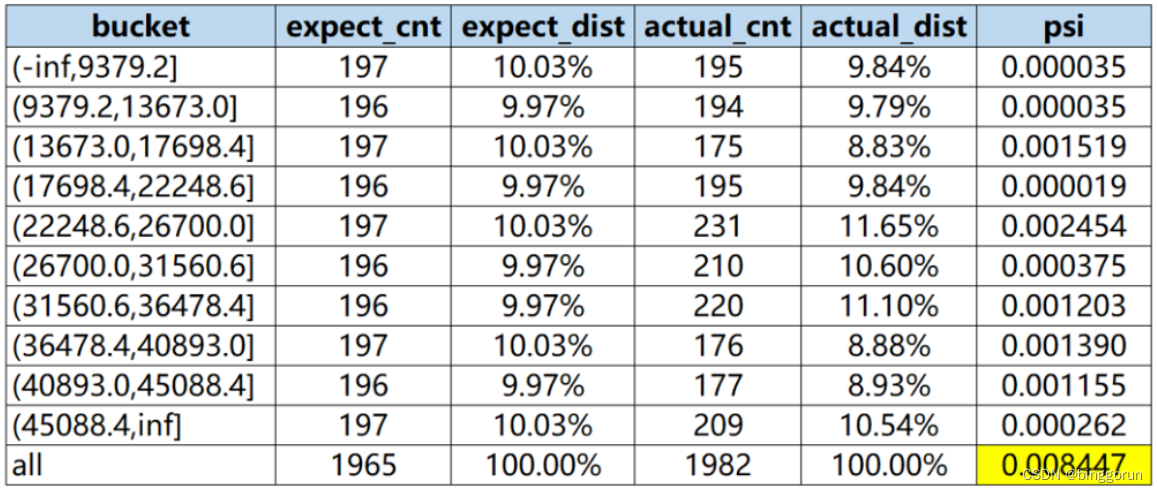
优缺点
优点:计算高效,对于过拟合问题具有较高的鲁棒性;
缺点:倾向于选择冗余特征,因为不考虑特征间的相关性,有可能某一特征分类能力较差,但是和其他特征组合后具有较强的分类效果;
包裹式(Wrapper)
主要思想:这种方法将特征选择过程与模型训练过程相结合,通过评估不同特征子集对模型性能的影响来选择特征。常见的包裹式特征筛选方法包括递归特征消除(通过递归地考虑越来越小的特征集来选择特征)和基于模型的特征重要性评估(如使用随机森林或梯度提升机等模型来评估特征的重要性)。包裹式特征筛选的优点是能够考虑特征之间的交互作用,选择出对模型性能贡献最大的特征;缺点是计算成本较高,尤其是在特征数量较多时。
错误分类率(Classifier error)
使用特定的分类器,用给定的特征子集对样本集进行分类,用分类的精度来衡量特征子集的好坏;
前向搜索(forword search)
初始时假定选定的特征集合为空,采用贪心的方式逐步扩充该集合,直到集合的特征数量达到阈值,阈值可提前设定,也可通过交叉验证获得。
后向搜索(backward search)
初始时假定特征集合为所有的特征,算法每次删除一个特征,指导特征集合中的特征数达到阈值
python
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# 构造回归问题的数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.1)
# 初始化线性回归模型作为评估器
estimator = LinearRegression()
# 使用递归特征消除选择特征
selector = RFE(estimator, n_features_to_select=10, step=1)
X_new = selector.fit_transform(X, y)嵌入式(Embeded)
这种方法在模型训练过程中自动进行特征选择。一些机器学习算法(如决策树、随机森林和深度学习模型等)具有内置的特征重要性评估机制,可以在训练过程中自动评估每个特征的重要性。嵌入式特征筛选的优点是计算效率高且能够考虑特征之间的交互作用;缺点是需要依赖于特定的机器学习算法,并且不同算法可能给出不同的特征重要性评估结果。
L1正则化
L1正则方法具有稀疏解的特性,直观从二维解空间来看L1-ball 为正方形,在顶点处时(如W2=C, W1=0的稀疏解),更容易达到最优解。可见基于L1正则方法的会趋向于产生少量的特征,而其他的特征都为0。
python
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
x_new = SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(x, y)随机森林
随机森林具有准确率高、鲁棒性好、易于使用等优点,这使得它成为了目前最流行的机器学习算法之一。随机森林提供了两种特征选择的方法:mean decrease impurity和mean decrease accuracy。
1)平均不纯度减少(Mean decrease impurity)
(1)随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。
(2)利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。
(3)当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
(4)程序实现:直接使用sklearn训练RF模型,然后通过feature_importances_属性可以得到每个特征的特征重要性,该特征重要性是根据不纯度减少计算而来。
2)平均精确度减少(Mean decrease accuracy)
(1)另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。
(2)主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
python
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
# 初始化随机森林模型
rf = RandomForestRegressor(n_estimators=100, random_state=0)
rf.fit(X, y)
# 获取特征重要性
importances = rf.feature_importances_
feature_importances_df = pd.DataFrame({'feature': X.columns, 'importance': importances})
feature_importances_df = feature_importances_df.sort_values(by='importance', ascending=False)决策树
其他
1)稳定性选择(Stability selection)
(1)稳定性选择是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。
(2)它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果。
比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。
(3)理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
2)递归特征消除(Recursive feature elimination,RFE)
(1)递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一遍,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。
(2)这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
(3)RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。
例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;
假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
python
from sklearn.feature_selection import RFE
rfe = RFE(estimator,n_features_to_select,step)
rfe = rfe.fit(x, y)
print(rfe.support_)
print(rfe.ranking_)