目录
介绍
Kafka Streams是构建在Apache Kafka之上的客户端库,用于构建高效、实时的流处理应用。它允许你以高吞吐量和低延迟的方式处理记录流,并且可以容易地扩展和复制数据处理流程。这种流处理方式适用于从简单的数据转换到复杂的事件驱动的应用程序。
关键特性
- **易用性:**Kafka Streams提供了简洁的API,允许开发者轻松构建复杂的流处理应用。这些API包括高级的DSL(Domain Specific Language)和低级的处理器API,两者可以相互配合使用。
- **无需单独的处理集群:**与其他流处理技术不同,Kafka Streams应用是作为常规的Java应用运行的,不需要维护一个专门的处理集群。你可以在你自己的应用中直接包含流处理逻辑,这使得部署和维护变得更容易。
- **强大的状态处理能力:**Kafka Streams支持状态化处理,并允许容错、持久化的本地状态存储。这是通过管理和复制RocksDB实例来实现的,为应用程序的状态提供了持久化和容错支持。
- **时间窗口处理:**Kafka Streams支持多种类型的时间窗口操作,如滑动窗口、跳跃窗口和会话窗口,使得在处理时间敏感的数据流时非常有效。
- **流式表格双模型:**Kafka Streams引入了一个流式表格双模型,允许用户将流处理结果看作是一张动态更新的表。这个模型提供了一种理解流数据和转换流数据的直观方式。
- **可扩展和容错:**由于Kafka Streams建立在Apache Kafka之上,它继承了Kafka的可扩展性和高可用性。应用可通过增加实例来水平扩展,故障转移由Kafka负责处理。
应用场景
Kafka Streams适用于多种实时数据处理场景,包括:
- 实时分析和监控:对即时生成的数据进行聚合、过滤和分析。事件驱动的应用:基于特定事件自动触发流程和操作。
- 数据转换和清洗:实时处理数据流,并将结果输出到Kafka主题或其他存储系统中。个性化推荐:根据用户行为实时更新推荐内容。
- Kafka Streams的设计目标是提供一种简单、强大且易于部署的流处理方式。
- 通过利用Kafka本身的优点,Kafka Streams可以帮助开发者更方便地构建和部署实时数据处理应用。
核心概念
-
DFP:以数据为中心的流式出来的方式
-
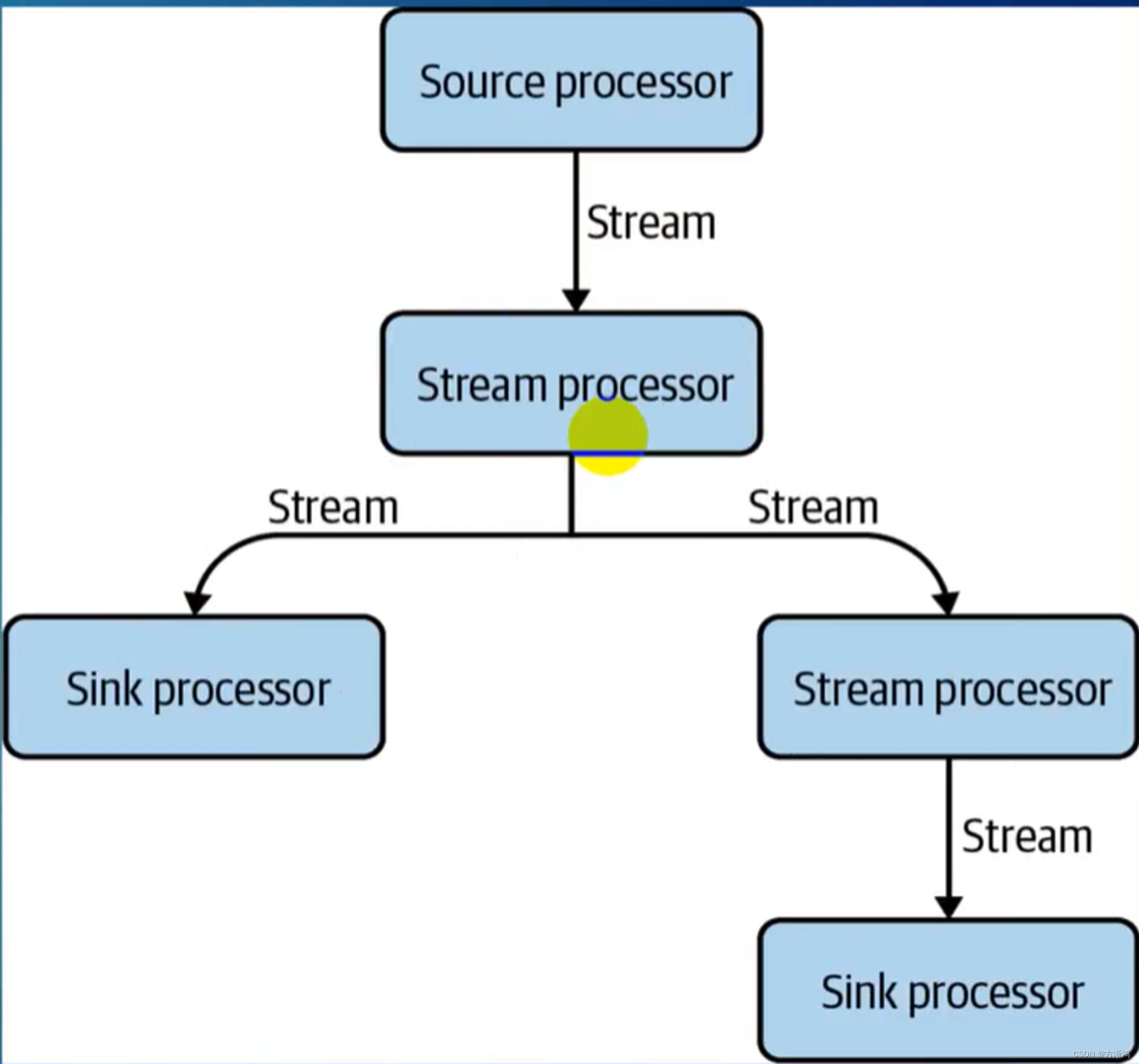
Source Processor:源头读的Processor
-
Stream Processors:进行流式处理的中间的Processors
-
Sink Processors:流中最后的一个Processors,用于pull到本地或者另外一个新的Topic
-
Topology:多个Processors就构成了一个Topology的环形图
-
sub-Topologies:获取数据分子的Topology
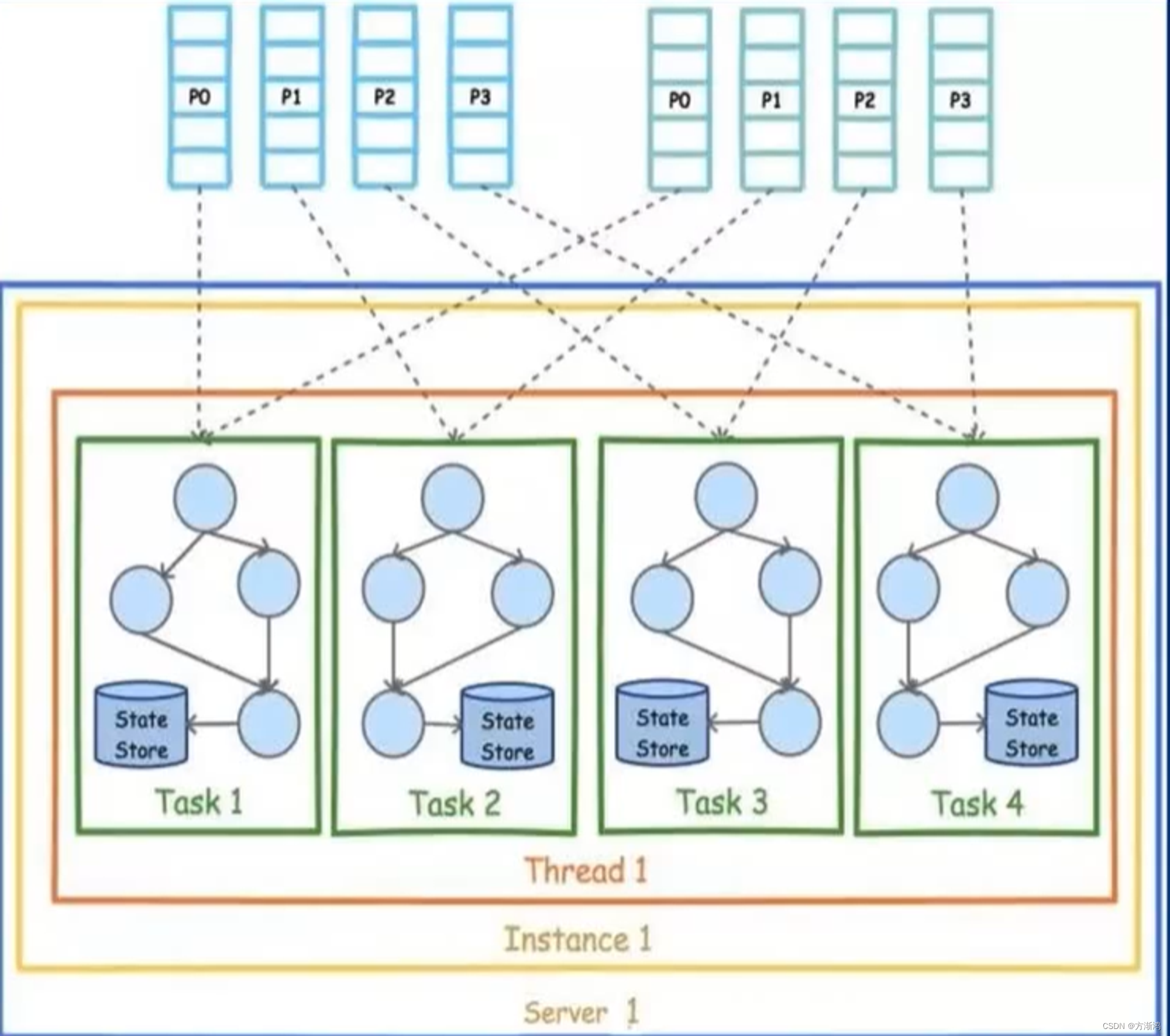
- Streams Task:Streams的最小单位,真正处理数据的
- Streams Thread:Streams 处理数据的线程,一般每个Streams Task会创建一个新的线程,提高并行
部署方式
- 在一个服务里面起一个Instance实例,这个实例里面创建两个线程,一个线程处理两个Task对象,这种方式先对并发最小

- 在一个服务里面启动两个Instance实例,在每一个线程里面可以处理一个Task,这样在处理上可以有效的提高并发,避免一个实例出现问题有限其他的

- 起多个服务集群化部署去跑多个实例,可以有效利用多核CPU的性能

kafka streams的处理模式
- **Depth-First Processing(深度优先处理模式):**在处理拓扑中的节点时,首先处理完一个节点的所有分支,然后再处理下一个节点,这种处理模式可以确保数据再处理过程中的一致性和正确性。避免数据混乱
- Breadth-First Processing(广度优先处理):与深度优先先反,广度优先处理模式会优先处理一个节点的所以相邻节点,然后再处理下一个节点。
- Time Windowing(时间窗口处理):按照时间窗口进行分组,然后对每个窗口内的事件进行处理,这种模式适用于需要对一段时间内的事件进行聚合处理或计算
具体使用
1、准备工作
默认已经安装kafka了啊,如果还没通过我这篇文章去安装==>kafka安装
- 在使用的时候,首先,我们需要创建两个个topic,
powershell
#进入kafka容器
docker exec -it kafka-server1 /bin/bash
#创建主题topic-1
/opt/kafka/bin/kafka-topics.sh --create --topic input-topic --bootstrap-server localhost:9092 --partitions 2 --replication-factor 1
#创建主题topic-2
/opt/kafka/bin/kafka-topics.sh --create --topic out-topic --bootstrap-server localhost:9092 --partitions 2 --replication-factor 12、添加依赖
我用的kafka-streams是3.1.2的
- gradle
kotlin
implementation("org.apache.kafka:kafka-streams")
implementation("org.springframework.kafka:spring-kafka")- mavne
java
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>3、代码实现
java
/**
* 通过streams实现数据流处理,把字符串装为大写
*/
@Slf4j
public class KafkaStreamsYellingApp {
// appid
private final static String APPLICATION_ID = "yelling_app_id";
private final static String INPUT_TOPIC = "input-topic";
private final static String OUTPUT_TOPIC = "out-topic";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) throws InterruptedException {
// 配置kafka stream属性连接
Properties properties = new Properties();
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_ID);
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
StreamsConfig streamsConfig = new StreamsConfig(properties);
// 配置键值对的序列化/反序列化Serdes对象
Serde<String> stringSerde = Serdes.String();
// 构建流处理拓扑(用于输出)
StreamsBuilder builder = new StreamsBuilder();
// 数据源处理器:从指定的topic中取出数据
KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde));
//
KStream<String, String> upperStream = inputStream
.peek((key, value) -> {
log.info("[收集]key:{},value:{}", key, value);
})
.filter((key, value) -> value.length() > 5)
.mapValues(time -> time.toUpperCase())
.peek((key, value) -> log.info("[过滤结束]key:{},value:{}", key, value));
// 日志打印upperStream处理器的数据
upperStream.print(Printed.toSysOut());
// 把upperStream处理器的数据输出到指定的topic中
upperStream.to(OUTPUT_TOPIC, Produced.with(stringSerde, stringSerde));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig);
// jvm关闭时,把流也关闭
CountDownLatch downLatch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
kafkaStreams.close();
downLatch.countDown();
log.info("关闭流处理");
}));
kafkaStreams.start();
log.info("启动执行!");
}
}上面代码的重点具体步骤:
-
创建Source Processor源,去topic中读取消息
KStream<String, String> inputStream = builder.stream(INPUT_TOPIC, Consumed.with(stringSerde, stringSerde)); -
创建Stream Processors中间处理的流
javaKStream<String, String> upperStream = inputStream .peek((key, value) -> { log.info("[收集]key:{},value:{}", key, value); }) .filter((key, value) -> value.length() > 5) .mapValues(time -> time.toUpperCase()) .peek((key, value) -> log.info("[过滤结束]key:{},value:{}", key, value)); -
创建Sink Processor,流中最后的一个Processors,用于pull到本地或者另外一个新的Topic
upperStream.to(OUTPUT_TOPIC, Produced.with(stringSerde, stringSerde));
具体的含义后面会详细编写一篇,这里先介绍简单使用
3、测试
-
进入生产者topic(看发的最后三条)

-
进入消费topic

日志输出
