目录
[🚩#{}和{}](#{}和{})
[🎈#{} 和 {}区别](#{} 和 {}区别)
[🎈{}使用场景](#🎈{}使用场景)
[📝like 查询](#📝like 查询)
🚩#{}和${}
MyBatis 参数赋值有两种⽅式, 咱们前⾯使⽤了 #{} 进⾏赋值, 接下来我们看下⼆者的区别
1、我们先看Interger类型的参数
<select id="selectById"> select * from userinfo where id=#{id}; </select> @Test void selectById() { UserInfo userInfo=userInfoXmlMapper2.selectById(1); System.out.println(userInfo); }发现我们输出的SQL语句:
Preparing: select * from userinfo where id=?;
我们输⼊的参数并没有在后⾯拼接, id的值是使⽤ ? 进⾏占位. 这种SQL 我们称之为"预编译SQL"
MySQL 课程 JDBC编程使⽤的就是预编译SQL, 此处不再多说
我们把 #{} 改成 ${} 再观察打印的⽇志:
<select id="selectById"> select * from userinfo where id=${id}; </select>


我们看到,参数直接拼接到语句中去了。而不是像#{}这种先用?占位,然后传参的时候给1给?。
2、 接下来我们再看String类型的参数
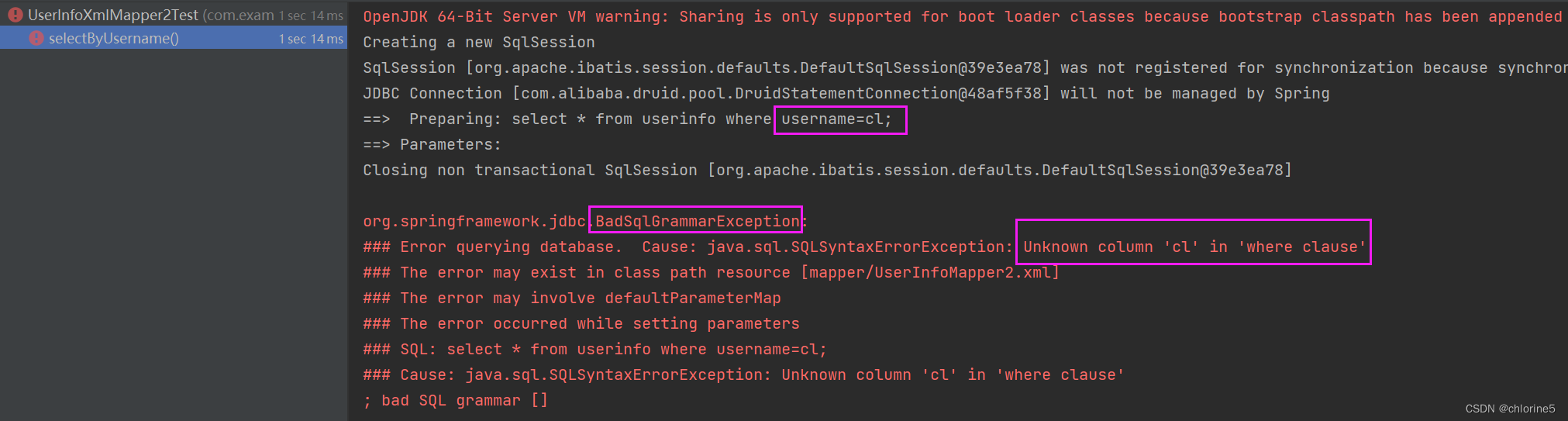
<select id="selectByUsername"> select * from userinfo where username=#{username}; </select> @Test void selectByUsername() { List<UserInfo> userInfos=userInfoXmlMapper2.selectByUsername("cl"); System.out.println(userInfos); }此时用?号进行占位,然后传参数cl(string)并标注了string类型的字符串。
我们把 #{} 改成 ${} 再观察打印的⽇志
<select id="selectByUsername"> select * from userinfo where username=${username}; </select>
可以看到, 这次的参数依然是直接拼接在SQL语句中了, 但是 字符串作为参数时, 需要添加引号 '' , 使⽤ {} 不会拼接引号 '' , 导致程序报错 这时候我们就可以在 **{username}外加引号** ,因为${}是拼接,在string类型中不会自动加入引号,需要我们手动加入引号
<select id="selectByUsername"> select * from userinfo where username='${username}'; </select>此时运行成功。
从上⾯两个例⼦可以看出:
- #{} 使⽤的是预编译SQL, 通过 ? 占位的⽅式, 提前对SQL进⾏编译, 然后把参数填充到SQL语句中. #{} 会根据参数类型, ⾃动拼接引号 '' .
- ${} 会直接进⾏字符替换, ⼀起对SQL进⾏编译. 如果参数为字符串, 需要加上引号 '' .


参数为数字类型时, 也可以加上, 查询结果不变, 但是可能会导致索引失效, 性能下降
🎈#{} 和 ${}区别
#{} 和 ${} 的区别就是预编译SQL和即时SQL 的区别:
深层区别:
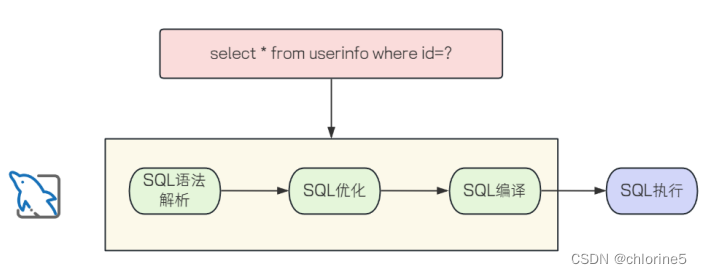
当客⼾发送⼀条SQL语句给服务器后, ⼤致流程如下:
- 解析语法和语义, 校验SQL语句是否正确
- 优化SQL语句, 制定执⾏计划
- 执⾏并返回结果
⼀条 SQL如果⾛上述流程处理, 我们称之为 Immediate Statements(即时 SQL)
📝#{}性能更⾼
绝⼤多数情况下, 某⼀条 SQL 语句可能会被反复调⽤执⾏, 或者每次执⾏的时候只有个别的值不同(⽐如 select 的 where ⼦句值不同, update 的 set ⼦句值不同, insert 的 values 值不同). 如果每次都需要经过上⾯的语法解析, SQL优化、SQL编译等,则效率就明显不⾏了
预编译SQL,编译⼀次之后会将编译后的SQL语句缓存起来,后⾯再次执⾏这条语句时,不会再次编译 (只是输⼊的参数不同), 省去了解析优化等过程, 以此来提⾼效率
📝#{}更安全(防⽌SQL注⼊)
SQL注⼊:是通过操作输⼊的数据来修改事先定义好的SQL语句,以达到执⾏代码对服务器进⾏攻击的⽅法。
由于没有对⽤⼾输⼊进⾏充分检查,⽽ 即时SQL⼜是拼接⽽成 ,在⽤⼾输⼊参数时,在参数中添加⼀些SQL关键字,达到改变SQL运⾏结果的⽬的,也可以完成恶意攻击。
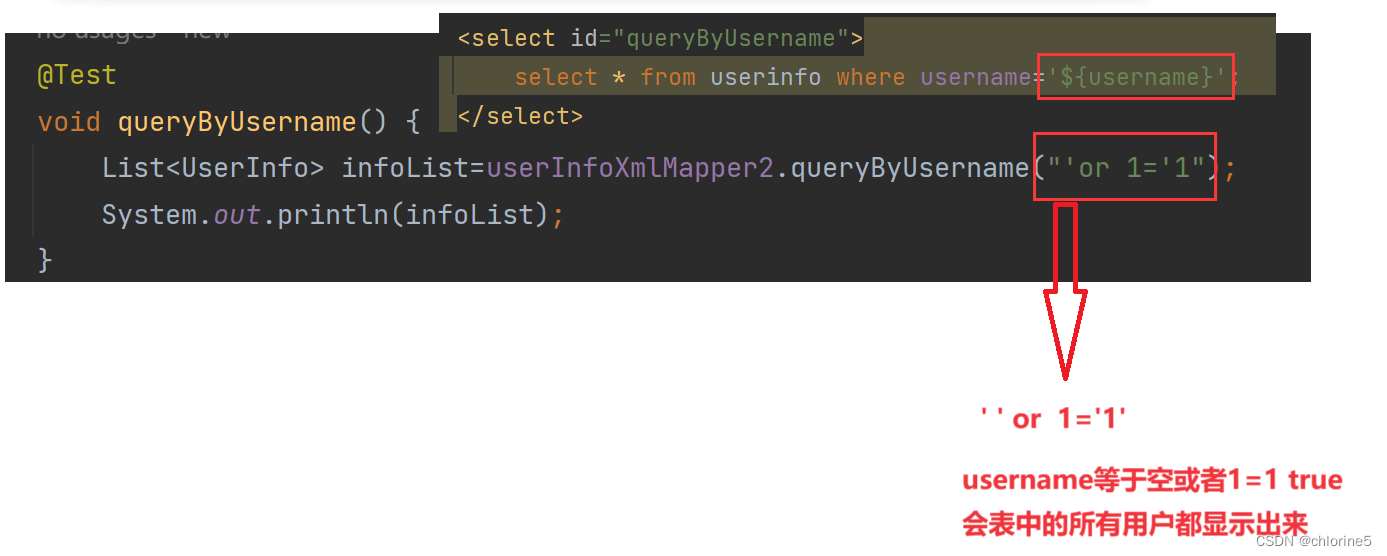
sql 注⼊代码: ' or 1='1
先来看看SQL注⼊的例⼦
正常${username}拼接
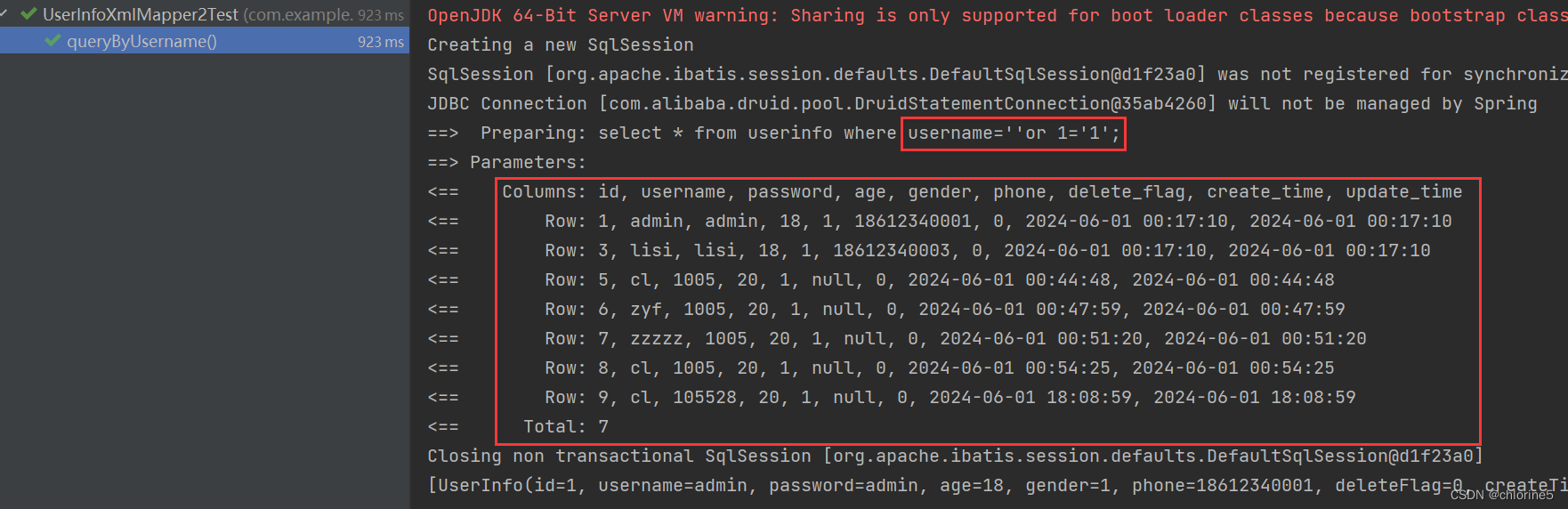
<select id="queryByUsername"> select * from userinfo where username='${username}'; </select> @Test void queryByUsername() { List<UserInfo> infoList=userInfoXmlMapper2.queryByUsername("admin"); System.out.println(infoList); }SQL注⼊场景:
结果依然被正确查询出来了, 其中参数 or被当做了SQL语句的⼀部分
可以看出来, 查询的数据并不是⾃⼰想要的数据. 所以⽤于查询的字段,尽量使⽤ #{} 预查询的⽅式
SQL注⼊是⼀种⾮常常⻅的数据库攻击⼿段, SQL注⼊漏洞也是⽹络世界中最普遍的漏洞之⼀. 如果发⽣在⽤⼾登录的场景中, 密码输⼊为 ' or 1='1 , 就可能完成登录(不是⼀定会发⽣的场景, 需要看登录代码如何写)
- #{}:预编译处理, ${}:字符直接替换
- #{} 可以防⽌SQL注⼊, ${}存在SQL注⼊的⻛险, 查询语句中, 可以使⽤ #{} ,推荐使⽤ #{}
- 但是⼀些场景, #{} 不能完成, ⽐如 排序功能, 表名, 字段名作为参数时, 这些情况需要使⽤${}
- 模糊查询虽然${}可以完成, 但因为存在SQL注⼊的问题,所以通常使⽤mysql内置函数concat来完成

🎈${}使用场景
📝排序功能
我们看到sql注入的风险之后,我们尽量是使用#{},但是有些场景就得需要使用拼接形式
比如以下语句
- select * from userinfo order by id {sort} 使⽤ {sort} 可以实现排序查询, ⽽使⽤ #{sort} 就不能实现排序查询了.
这些都是不用加上单引号的 ,而我们的#{}方式虽然是预处理,但是都是会自动增加''形式。而{}形式则是以拼接的形式进行。 **注意:** 此处 sort 参数为String类型, 但是SQL语句中, 排序规则是不需要加引号 '' 的, 所以此时的 {sort} 也不加引号
<select id="queryAllUserBySort">
select * from userinfo order by id ${sort};
</select>
@Test
void queryAllUserBySort() {
List<UserInfo>infoList=userInfoXmlMapper2.queryAllUserBySort("asc");
System.out.println(infoList);
}让id以升序来排序。

使用${}自动拼接。
我们把 ${} 改成 #{}
<select id="queryAllUserBySort">
select * from userinfo order by id #{sort};
</select>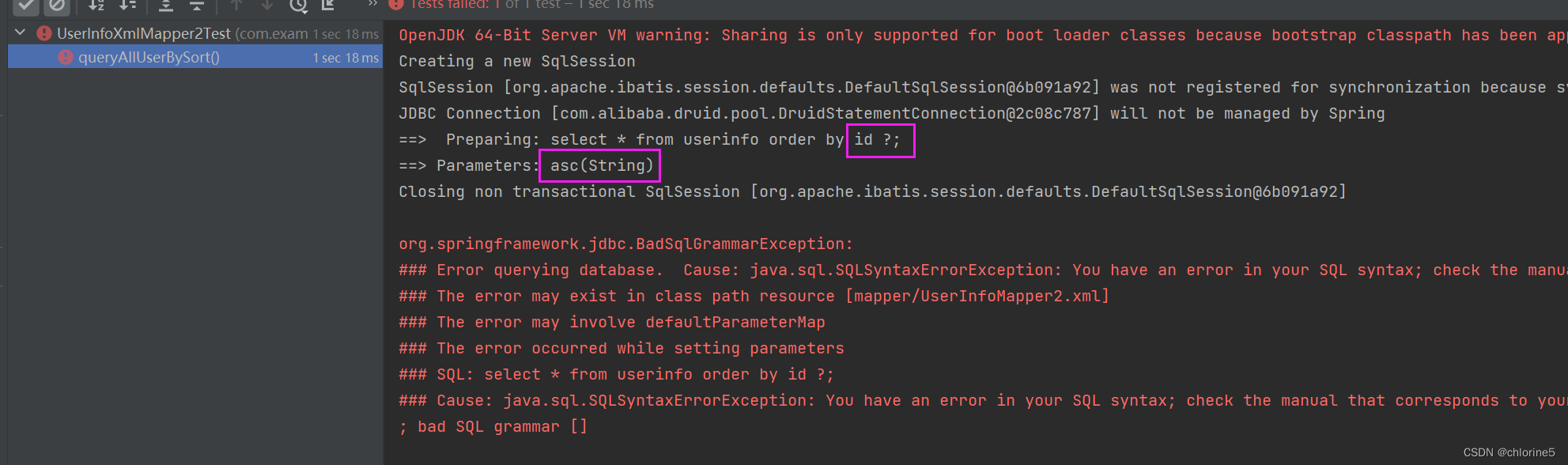

可以发现, 当使⽤ #{sort} 查询时, asc 前后⾃动给加了引号, 导致 sql 错误
#{} 会根据参数类型判断是否拼接引号 '' ,如果参数类型为String, 就会加上 引号.
除此之外, 还有表名作为参数时, 也只能使⽤ ${}
📝like 查询
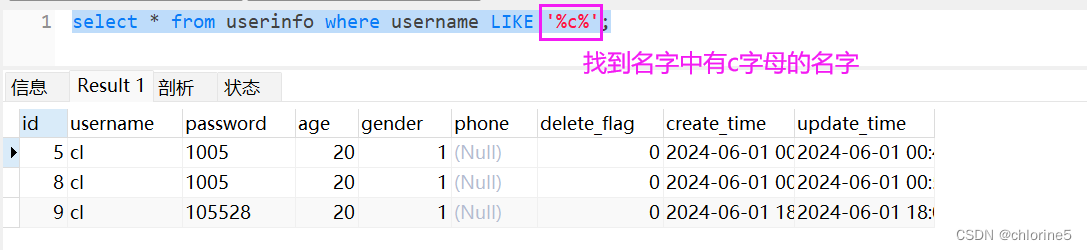
我们回顾以下,like的语句是什么,我们在mysql中实验一波~
'%#{username}%'
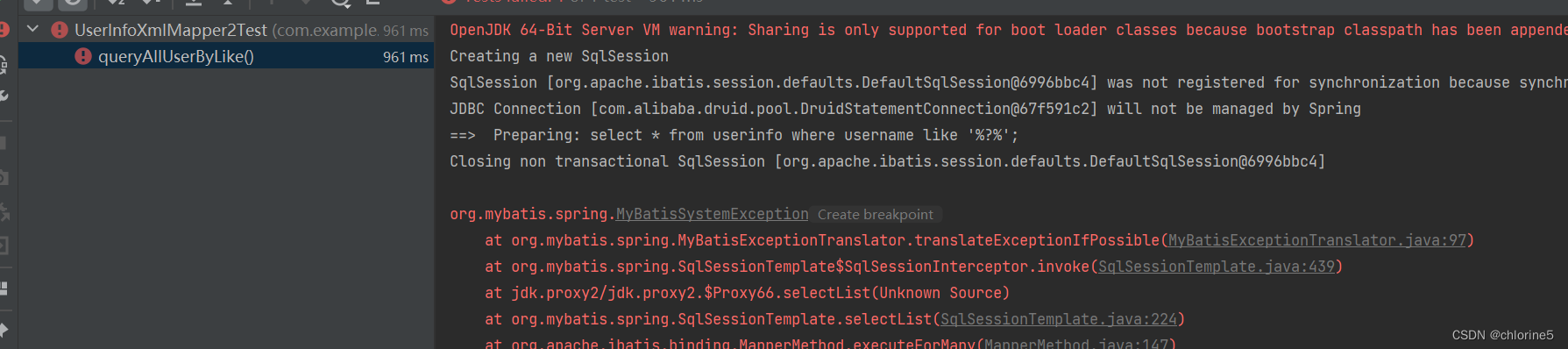
<select id="queryAllUserByLike"> select * from userinfo where username like '%#{key}%'; </select>'%#{key}%' ------ '%?%' ------ '%'zhangsan'%' 解析都无法完成
@Test void queryAllUserByLike() { List<UserInfo> infoList=userInfoXmlMapper2.queryAllUserByLike("c"); System.out.println(infoList); }
这是我实验的三种方式,都是不行。
把 #{} 改成 {} 可以正确查出来, 但 **是{}存在SQL注⼊的问题, 所以不能直接使⽤ ${}.**
解决办法: 使⽤ mysql 的内置函数 concat() 来处理 ,实现代码如下
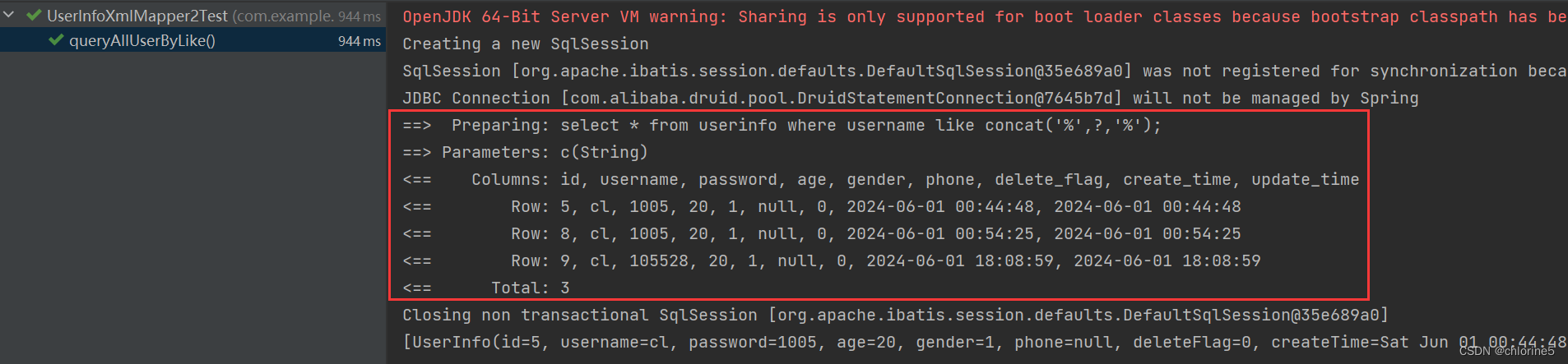
<select id="queryAllUserByLike"> select * from userinfo where username like concat('%',#{key},'%'); </select>

🚩数据库连接池
在上⾯Mybatis的讲解中, 我们使⽤了数据库连接池技术, 避免频繁的创建连接, 销毁连接
下⾯我们来了解下数据库连接池
数据库连接池负责分配、管理和释放数据库连接,它允许应⽤程序重复使⽤⼀个现有的数据库连接,⽽不是再重新建⽴⼀个.
我们在之前学习jdbc,我们都是没创建一个类都要进行创建连接和销毁连接。
在管理博客列表和用户列表的时候,都是需要先建立连接,然后销毁连接
我们现在用的就是数据库连接池,我们在配置文件中, 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾ 请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把 Connection归还给连接池
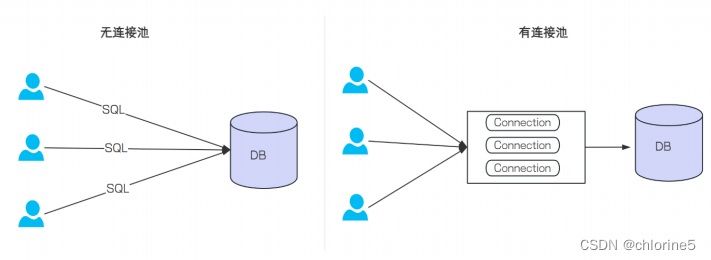
- 没有使⽤数据库连接池的情况: 每次执⾏SQL语句, 要先创建⼀个新的连接对象, 然后执⾏SQL语句, SQL 语句执⾏完, 再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接⽐较消耗资源。
- 使⽤数据库连接池的情况: 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾ 请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把 Connection归还给连接池
优点:
- 减少了⽹络开销
- 资源重⽤

- 提升了系统的性能
🎈数据库连接池使⽤
常⻅的数据库连接池:
- • C3P0
- • DBCP
- • Druid
- • Hikari
⽬前⽐较流⾏的是 Hikari, Druid
1. Hikari : SpringBoot默认使⽤的数据库连接池
Hikari 是⽇语"光"的意思(ひかり), Hikari也是以追求性能极致为⽬标
2. Druid
如果我们想把默认的数据库连接池切换为Druid数据库连接池, 只需要引⼊相关依赖即可
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-3-starter</artifactId> <version>1.2.21</version> </dependency>


🚩MySQL开发企业规范
- 表名, 字段名使⽤⼩写字⺟或数字, 单词之间以下划线分割. 尽量避免出现数字开头或者两个下划线 中间只出现数字. 数据库字段名的修改代价很⼤, 所以字段名称需要慎重考虑。
MySQL 在 Windows 下不区分⼤⼩写, 但在 Linux 下默认是区分⼤⼩写. 因此, 数据库名, 表名, 字段名都不允许出现任何⼤写字⺟, 避免节外⽣枝
正例: aliyun_admin, rdc_config, level3_name
反例: AliyunAdmin, rdcConfig, level_3_name
- 表必备三字段: id, create_time, update_time
id 必为主键, 类型为 bigint unsigned, 单表时⾃增, 步⻓为 1
create_time, update_time 的类型均为 datetime 类型, create_time表⽰创建时间, update_time表⽰更新时间
有同等含义的字段即可, 字段名不做强制要求
- 在表查询中, 避免使⽤ * 作为查询的字段列表, 标明需要哪些字段
- 增加查询分析器解析成本
- 增减字段容易与 resultMap 配置不⼀致
- ⽆⽤字段增加⽹络消耗, 尤其是 text 类型的字段
🚩动态sql
动态 SQL 是Mybatis的强⼤特性之⼀,能够完成不同条件下不同的 sql 拼接
🎈<if>标签
在注册⽤⼾的时候,可能会有这样⼀个问题,如下图所⽰:

注册分为两种字段:必填字段和⾮必填字段,那如果在添加⽤⼾的时候有不确定的字段传⼊,程序应该如何实现呢? 这个时候就需要使⽤动态标签 来判断了。
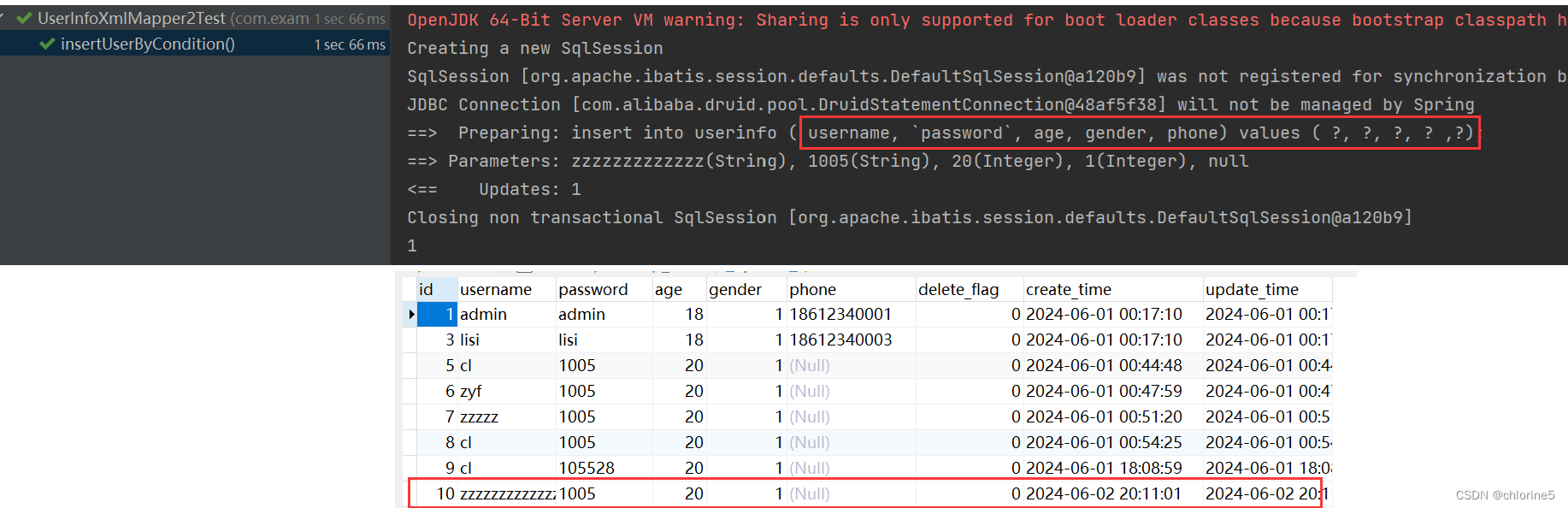
一开始我们insert语句都是这样的,我给除了id字段,其实都设置成了可空情况,就是这些字段可是是空,但是实际情况下,上面四个字段都是不能为空的的,为了方便给大家展示。

⽐如添加的时候性别 gender 为⾮必填字段,具体实现如下:
<insert id="insertUserByCondition"> insert into userinfo ( username, `password`, age, <if test="gender!=null"> gender, </if> phone) values ( #{username}, #{password}, #{age}, <if test="gender!=null"> #{gender}, </if> #{phone}); </insert>
gender不为空的情况下:
gender为空的情况下:
没有gender字段。
比如gender,phone都为不必要不填写的情况
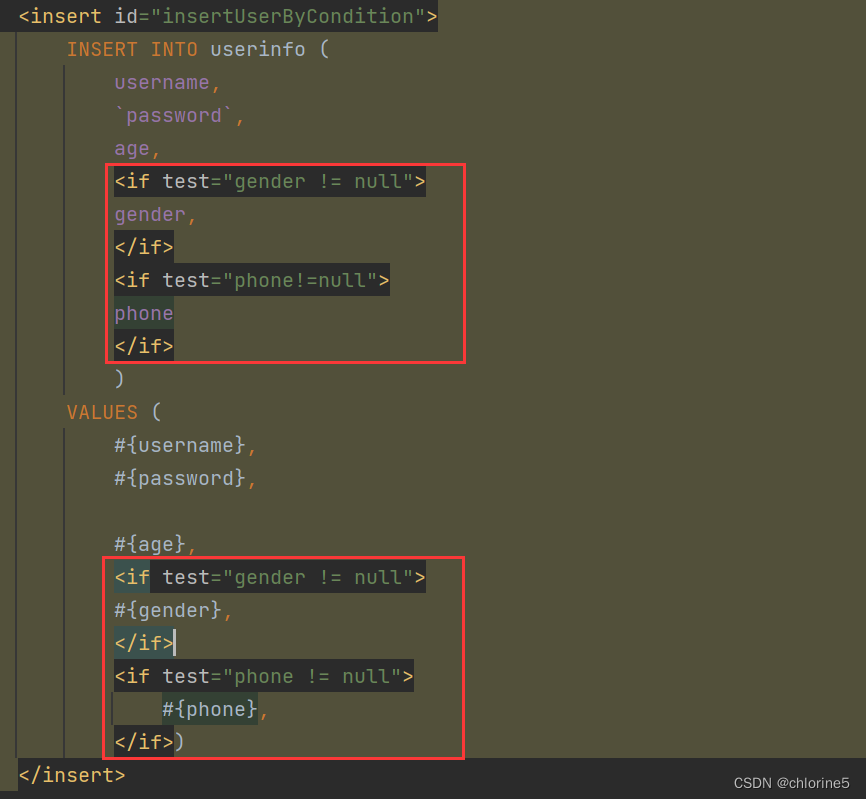
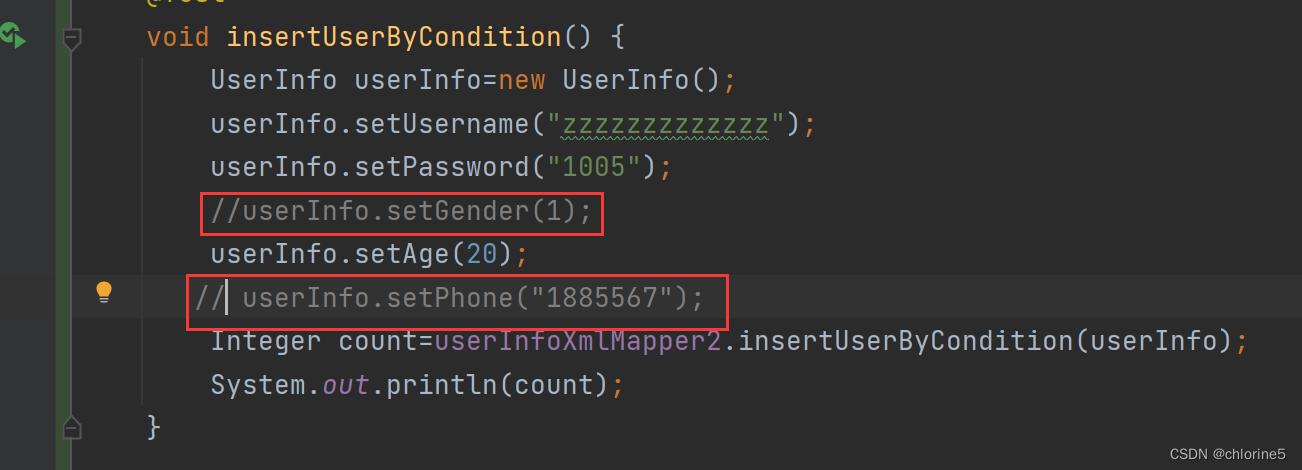
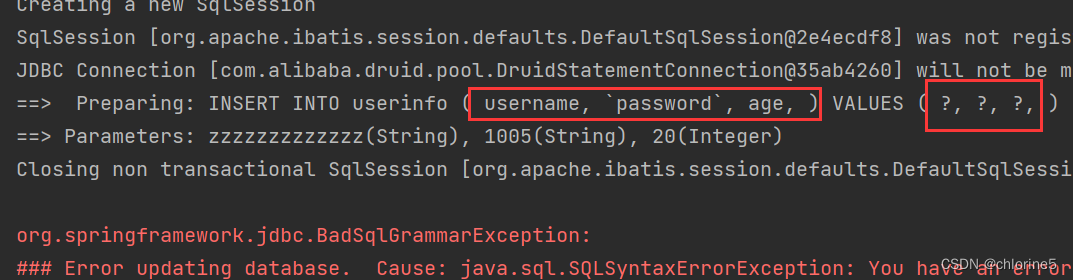
此时会让整个语句多了个逗号。
为了防止多加了前面逗号或者前面逗号,此时引入了<trim>标签形式。
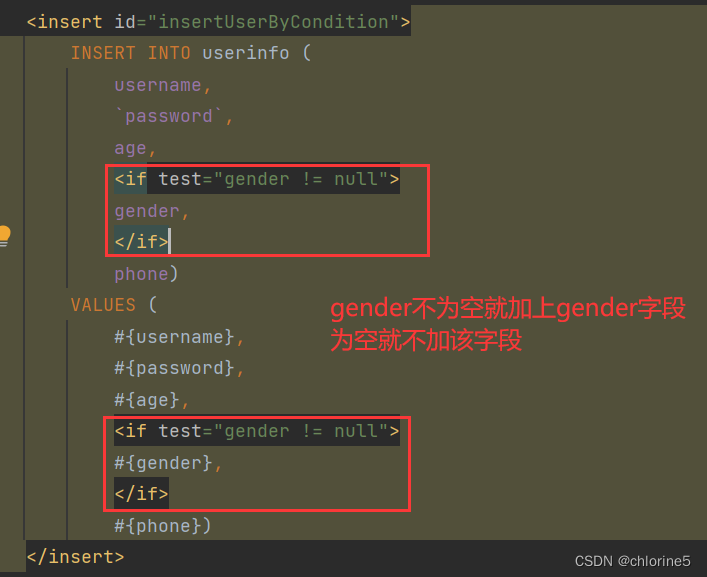



🎈<trim>标签
之前的插⼊⽤⼾功能,只是有⼀个 gender 字段可能是选填项,如果有多个字段,⼀般考虑使⽤标签结合标签,对多个字段都采取动态⽣成的⽅式。
标签中有如下属性:
- • prefix:表⽰整个语句块,以prefix的值作为前缀
- • suffix:表⽰整个语句块,以suffix的值作为后缀
- • prefixOverrides:表⽰整个语句块要去除掉的前缀
-
• suffixOverrides:表⽰整个语句块要去除掉的后缀
调整 Mapper.xml 的插⼊语句为:
prefix在前面插入( , suffix在后面插入) , suffixOverrides如果多余就删除后缀,<insert id="insertUserByCondition"> INSERT INTO userinfo <trim prefix="(" suffix=")" suffixOverrides=","> <if test="username != null"> username, </if> <if test="password != null"> `password`, </if> <if test="age != null"> age, </if> <if test="gender != null"> gender, </if> <if test="phone!=null"> phone </if> </trim> VALUES <trim prefix="(" suffix=")" suffixOverrides=","> <if test="username != null"> #{username}, </if> <if test="password != null"> #{password}, </if> <if test="age != null"> #{age}, </if> <if test="gender != null"> #{gender}, </if> <if test="phone!=null"> #{phone} </if> </trim> </insert>
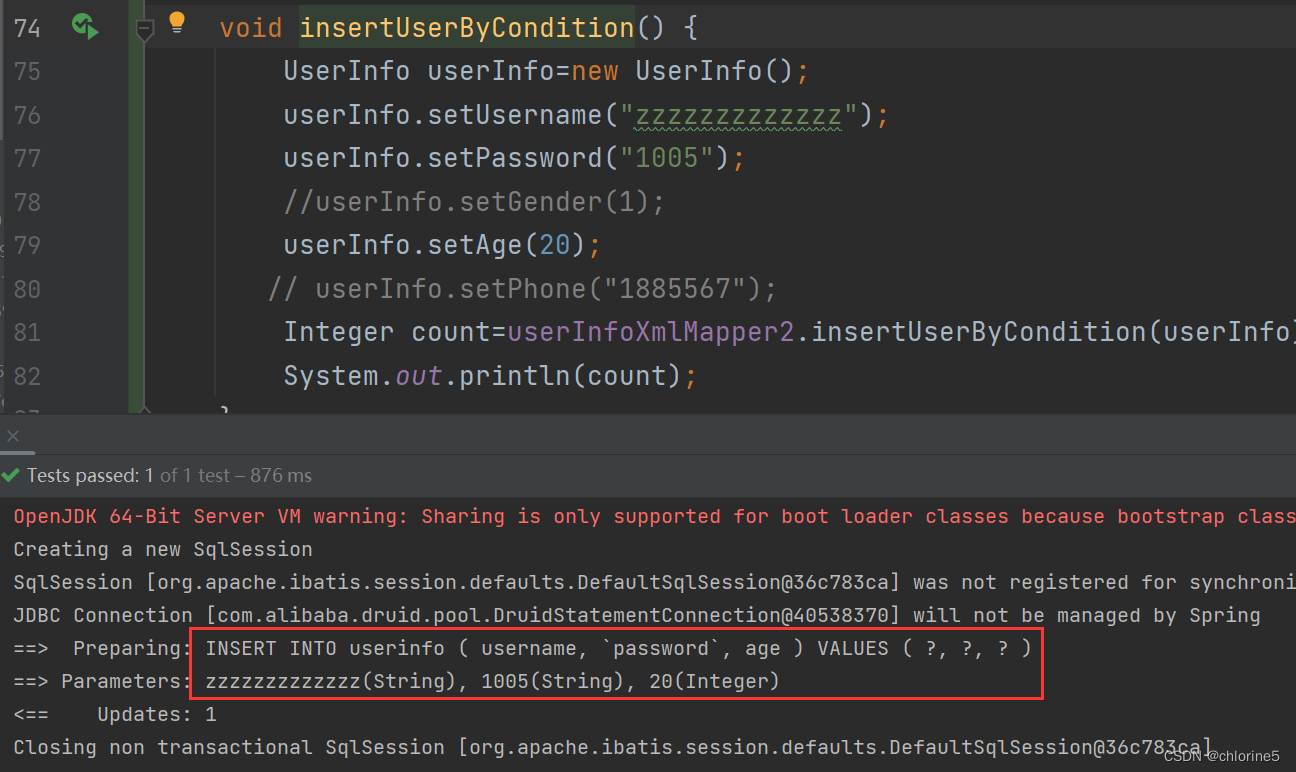
在以上 sql 动态解析时,会将第⼀个 部分做如下处理:
- • 基于 prefix 配置,开始部分加上 (
- • 基于 suffix 配置,结束部分加上 )
- • 多个 组织的语句都以 , 结尾,在最后拼接好的字符串还会以 , 结尾,会基于 suffixOverrides 配置去掉最后⼀个 ,
- • 注意 <if test="username !=null"> 中的 username 是传⼊对象的属性
🎈<where>标签
需求: 传⼊的⽤⼾对象,根据属性做where条件查询,⽤⼾对象中属性不为 null 的,都为查询条件. 如 username 为 "a",则查询条件为 where username="a"
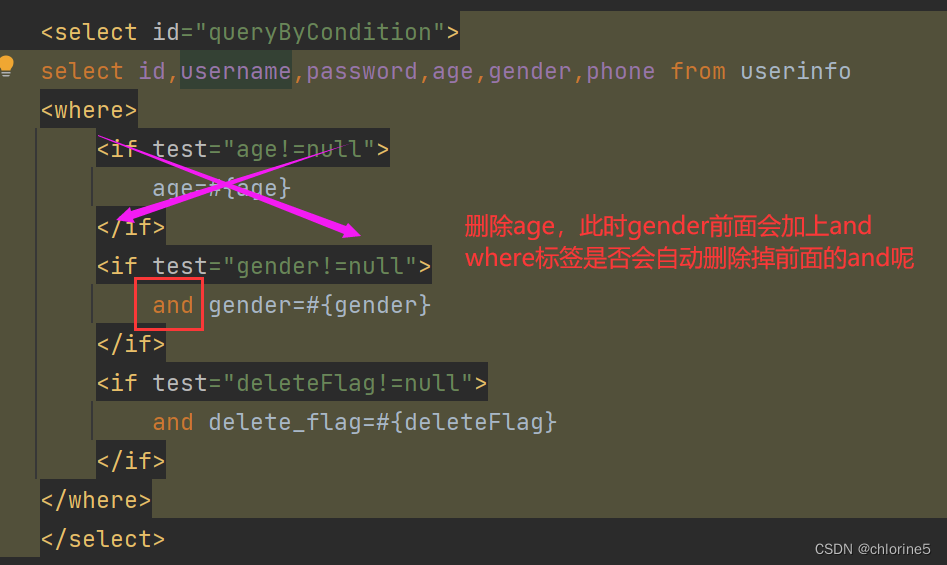
原有sql
select * from where age=18 and gender=1 and delete_flag=0;
Mapper.xml实现
<select id="queryByCondition">
select id,username,password,age,gender,phone from userinfo
<where>
<if test="age!=null">
age=#{age}
</if>
<if test="gender!=null">
and gender=#{gender}
</if>
<if test="deleteFlag!=null">
and delete_flag=#{deleteFlag}
</if>
</where>
</select>
@Test
void queryByCondition() {
UserInfo userInfo=new UserInfo();
userInfo.setAge(18);
userInfo.setGender(1);
userInfo.setDeleteFlag(0);
List<UserInfo>infoList=userInfoXmlMapper2.queryByCondition(userInfo);
System.out.println(infoList);
}在三个字段都没填时运行成功。

如果我们没有给age赋值,此时gender不为空,前面有个and,此时where标签是否会自动删除掉前面的and呢?
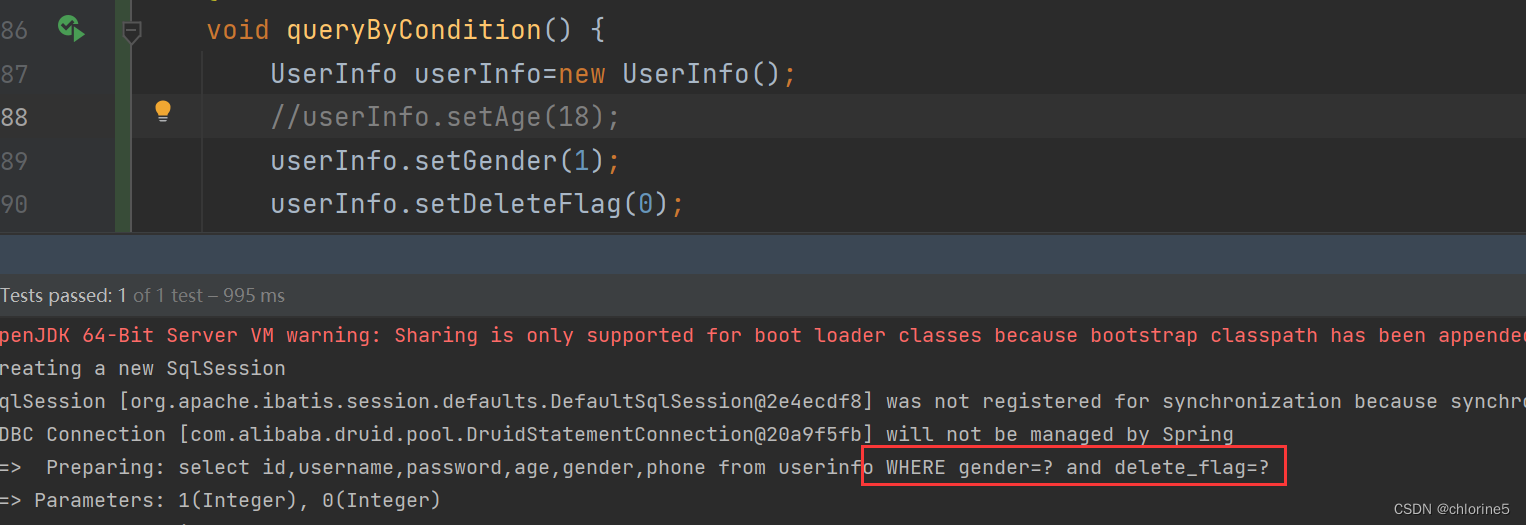
此时代码运行成功,我们看到用where标签会自动去除子句开头的and。
<where> 只会在⼦元素有内容的情况下才插⼊where⼦句,⽽且会⾃动去除⼦句的开头的AND或 OR 以上标签也可以使⽤ <trim prefix="where" prefixOverrides="and"> 替换, 但是此种 情况下, 当⼦元素都没有内容时, where关键字也会保留。
🎈<set>标签
set一般用于更新操作。
需求: 根据传⼊的⽤⼾对象属性来更新⽤⼾数据,可以使⽤标签来指定动态内容.
接⼝定义: 根据传⼊的⽤⼾ id 属性,修改其他不为 null 的属性
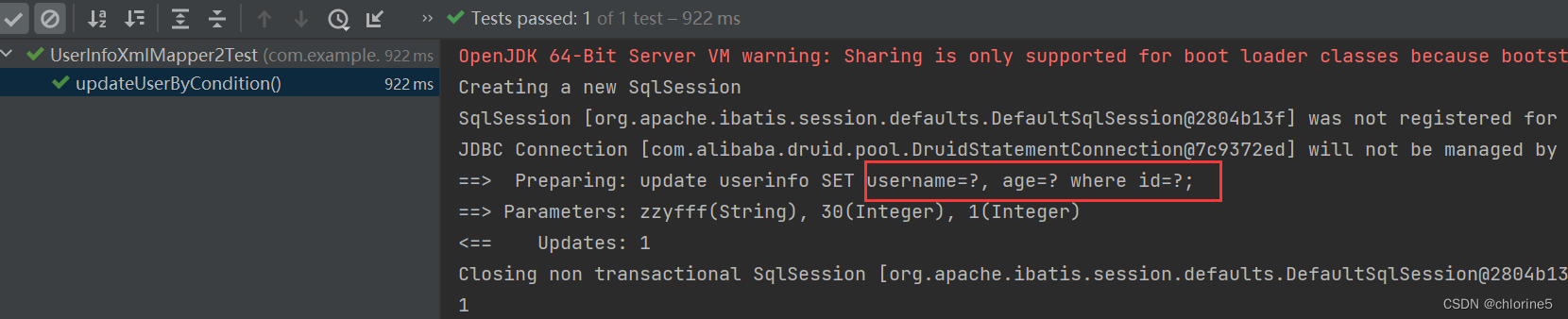
<update id="updateUserByCondition">
update userinfo
<set>
<if test="username!=null">
username=#{username},
</if>
<if test="age!=null">
age=#{age},
</if>
<if test="deleteFlag!=null">
delete_flag=#{deleteFlag}
</if>
</set>
where id=#{id};
</update>
如果我们不设置deleteFlag,此时age不为空的情况下,后面的,是多余的,set标签会进行去除掉嘛?
此时set标签会自动删除额外的逗号。
<set> :动态的在SQL语句中插⼊set关键字,并会删掉额外的逗号. (⽤于update语句中) 以上标签也可以使⽤ <trim prefix="set" suffixOverrides=","> 替换
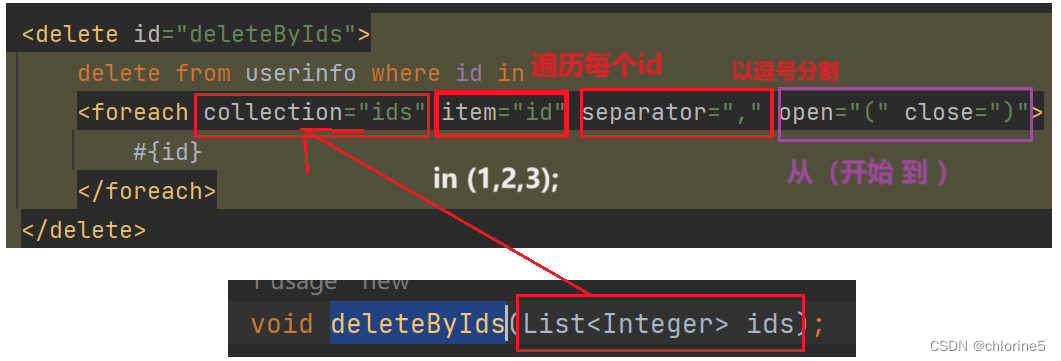
🎈<foreach>标签
对集合进⾏遍历时可以使⽤该标签。标签有如下属性:
• collection:绑定⽅法参数中的集合,如 List,Set,Map或数组对象
• item:遍历时的每⼀个对象
• open:语句块开头的字符串
• close:语句块结束的字符串
• separator:每次遍历之间间隔的字符串
需求: 根据多个userid, 删除⽤⼾数据。
delete from userinfo where id in (1,2,3);
接⼝⽅法:
ArticleMapper.xml 中新增删除 sql:
<delete id="deleteByIds"> delete from userinfo where id in <foreach collection="ids" item="id" separator="," open="(" close=")"> #{id} </foreach> </delete>
测试
@Test void deleteByIds() { List<Integer>integerList=new ArrayList<>(); integerList.add(1); integerList.add(2); integerList.add(3); userInfoXmlMapper2.deleteByIds(integerList); }


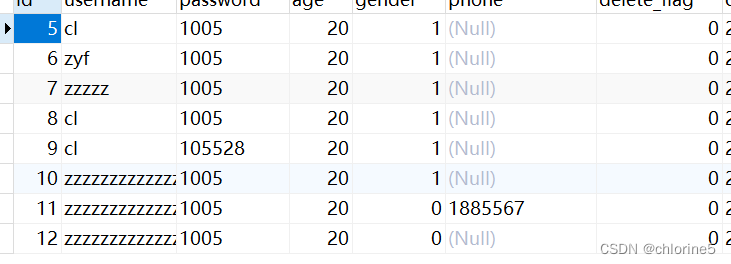
此时批量删除了id为1,2,3的数据。
🎈<include>标签
问题分析:
• 在xml映射⽂件中配置的SQL,有时可能会存在很多重复的⽚段,此时就会存在很多冗余的代码

我们可以对重复的代码⽚段进⾏抽取, 将其通过 <sql> 标签封装到⼀个SQL⽚段,然后再通过 <include> 标签进⾏引⽤。
- • <sql> :定义可重⽤的SQL⽚段
- • <include> :通过属性refid,指定包含的SQL⽚段

我们每次都只需要查询这几个字段即可(姓名,密码,年龄,性别,电话)即可。我们可以给这个片段抽取出来。
<sql id="allColumn">
username,`password`,age,gender,phone
</sql>通过 <include> 标签在原来抽取的地⽅进⾏引⽤。操作如下:
<sql id="allColumn">
username,`password`,age,gender,phone
</sql>
<select id="queryAllUser">
select
<include refid="allColumn"></include>
from userinfo
</select>
世界变化太快,我只想做个缓慢的行者。