1.启动Hadoop集群
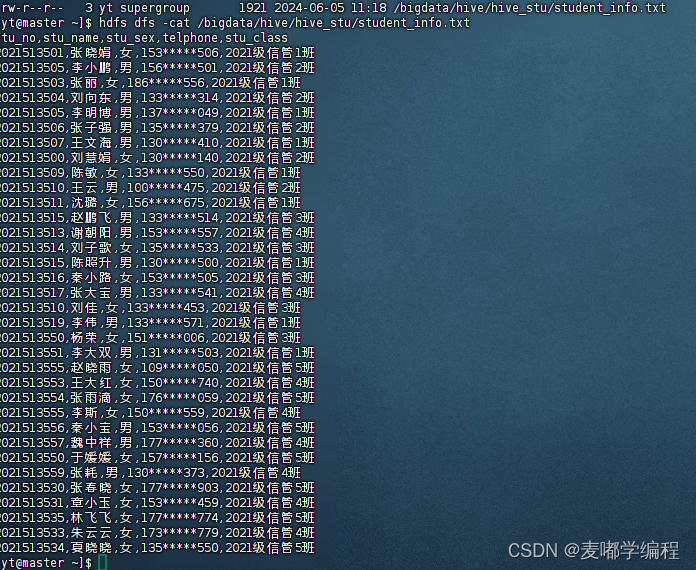
2.将学生信息上传到/bigdata/hive/hive_stu目录下
查看测试数据
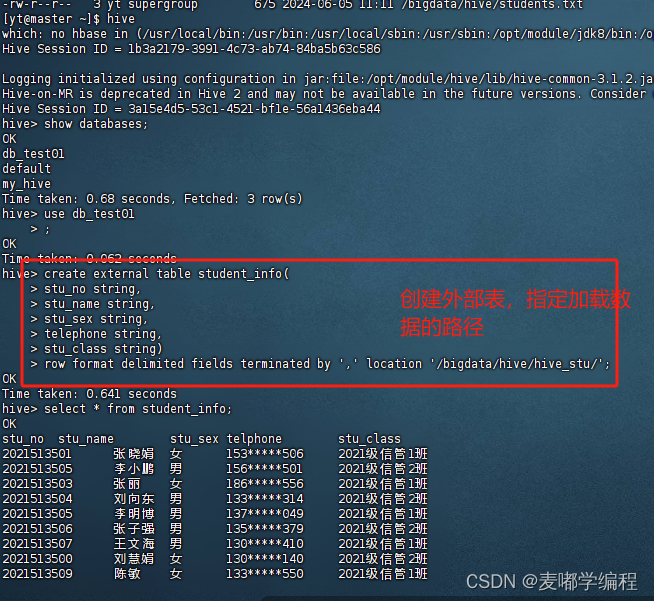
3.进入hive,切换到db_test库(如没有,可以先创建 create database db_test)