文章目录
-
- [1. 案例场景](#1. 案例场景)
- [2. 3主3从redis集群扩缩容配置案例架构说明](#2. 3主3从redis集群扩缩容配置案例架构说明)
- [3. 3主3从redis集群扩缩容配置案例搭建](#3. 3主3从redis集群扩缩容配置案例搭建)
- [4. 主从容错切换迁移案例](#4. 主从容错切换迁移案例)
- [5. 主从扩容](#5. 主从扩容)
- [6. 主从缩容](#6. 主从缩容)
1. 案例场景
1~2亿条数据需要缓存,如何设计这个存储案例?这种情况下单机存储100%是不可能的,肯定是分布式存储,那么用redis如何落地?
- 哈希取余分区

2亿条记录就是2亿个k-v对,我们单机不行必须要用分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:hash(key)%N台机器数,计算出hash值,用来决定映射到哪一个节点上。这样做的优点是,简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落在一台服务器上,这样每台服务器固定处理一部分请求,起到负载均衡+分而治之的作用。但这个方法缺点也是很明显的,原来规划好的节点,进行扩容或者缩容就比较麻烦,每次数据变动导致节点有变动,映射关系需要重新计算,在服务器个数不变时,哈希取余分区方法是很高效的,如果需要弹性扩容或者故障停机的情况下,原来的取模公式就会发生变化。此时,如果某个节点宕机了,那么导致整个hash取余就会重新洗牌,根据公式获取数据失效。
- 一致性哈希算法
一致性hash算法是在1997年由麻省理工学院提出来的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量就会改变了,自然取余失效的情况。(当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系),该方法步骤如下:
- 使用一致性算法构建哈希环
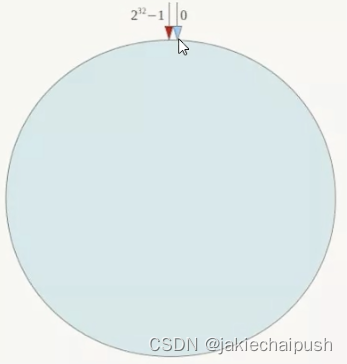
一致性hash算法必然有个hash函数,并按照算法产生hash值,这个算法所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间 0 , 2 32 − 1 0,2\^{32}-1 0,232−1,这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首位相连,这样让它逻辑上形成一个环形空间。一致性哈希算法也是按照使用取模的方法,不不同hash不同的是,一致性hash算法取模对象不是服务器数量,而是对 2 32 2^{32} 232取模,简单来说,一致性hash算法将整个hash空间组织成了一个虚拟的环,如果设某hash函数H的值空间为 0 , 2 32 − 1 0,2\^{32}-1 0,232−1,整个hahs环如下图:整个空间按顺时针方向组织,圆的正上方的点代表0,0右侧的第一个点代表1,以此类推,2、3、4...直到 2 32 − 1 2^{32}-1 232−1,也就是说0点左侧的第一个点代表 2 32 − 1 2^{32}-1 232−1,0和 2 32 − 1 2^{32}-1 232−1在0点中方向重合,我们把这个由 2 32 2^{32} 232个点组成的圆称为hash环。
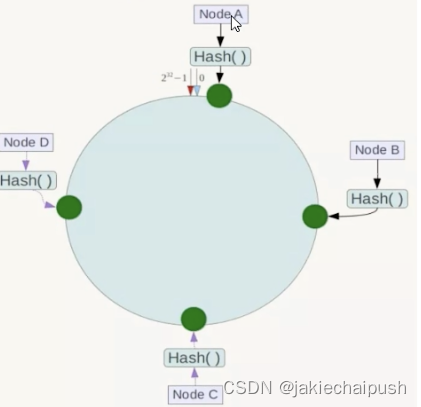
- 服务器IP节点映射
将集群中某个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行hash,这样每台机器就能确定其在hash环上的位置,假如4个节点Node A、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后的环空间位置如下:
- key落到服务器的落键规则
当我们需要存储一个k-v时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出hash值并确定此数据在环上的位置,从次位置沿环顺时针行走,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
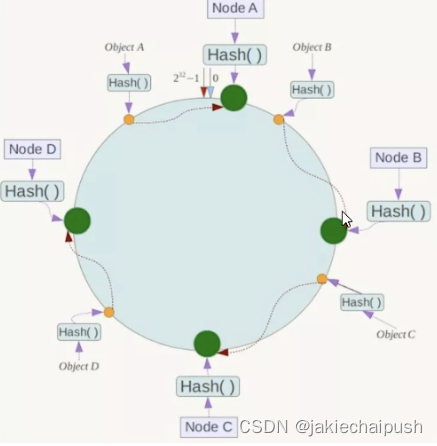
一致性hash算法有很多优点,首先它具有容错性,假设上图的Node C节点宕机了,此时Object C的数据就会放到Node D中,也就是说在一执行hash算法中,如果一台服务器不可用,则受影响的数据仅仅是次服务器到其环空间中前一台服务器的数据,其它不会收到影响。此外,一致性hash算法还具有扩展性,假如上图中Node A和Node B中加入了一个Node X,此时受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
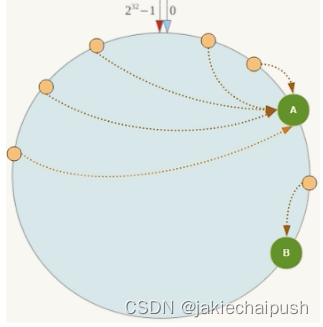
当然一致性hash算法也有一定的局限性,一致性hash算法有数据倾斜问题,一致性hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如下图系统只有两个服务器:
- hash槽分区(用的比较广泛)
为了解决一致性hash算法的数据倾斜问题提出了hash槽分区的概念。哈希槽实质上就是一个数组,数组 0 , 2 14 − 1 0,2\^{14}-1 0,214−1形成hash slot空间。哈希槽能解决均匀分配的问题,在数据节点之间又加入了一层,把这层称为哈希槽,用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。

槽解决的事粒度问题,相当于把粒度变大了,这样便于数据移动。hash解决的事映射问题,使用key的hash值来计算所在的槽,用于数据分配。
一个redis集群只能有16384个槽,编号0-16383。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号分配给哪个主节点,集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求hash值,然后对16384取余,余数是几key就落入对应的槽中。以槽为单位移动数据,因为槽的数量是固定的,处理起来比较容器,这样数据移动的问题就解决了。
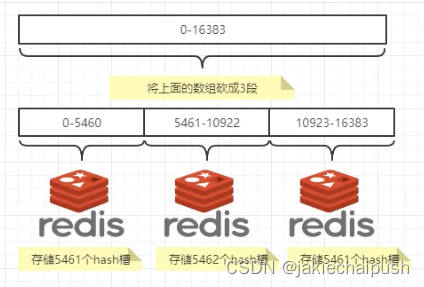
2. 3主3从redis集群扩缩容配置案例架构说明
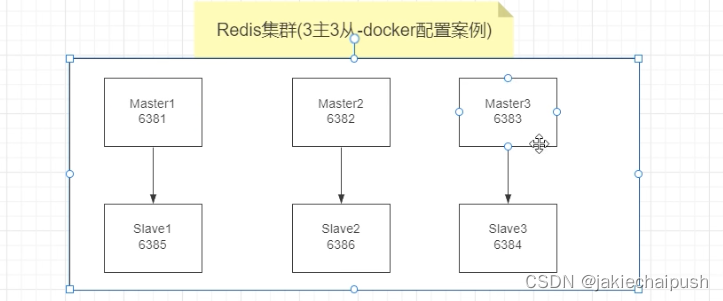
- redis集群(3主3从-docker配置案例说明)
3. 3主3从redis集群扩缩容配置案例搭建
- 3主3从redis集群配置
新6个docker实例
bash
docker run -d --name redis-node-1 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381 --daemonize no --protected-mode no
docker run -d --name redis-node-2 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382 --daemonize no --protected-mode no
docker run -d --name redis-node-3 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383 --daemonize no --protected-mode no
docker run -d --name redis-node-4 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384 --daemonize no --protected-mode no
docker run -d --name redis-node-5 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385 --daemonize no --protected-mode no
docker run -d --name redis-node-6 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386 --daemonize no --protected-mode no--net host:使用宿主机的IP和端口
--privileged=true:获取宿主机root用户权限
--cluster-enabled yes :开启redis集群
--appendonly yes:开启redis持久化


进入容器内部构建集群关系
首先进入redis-node-1
bash
docker exec -it redis-node-1 /bin/bash然后构建主从关系:
bash
redis-cli -p 6381 --cluster create 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386 --cluster-replicas 1-cluster-replicas 1表示为每个master创建一个slave节点

可以上面图片中表示hash槽被分配到了三个redis节点中,可以发现节点之间的主从关系也分配好了
然后登陆6381号机器查看集群的状态:
bash
redis-cli -p 6381
cluster info
bash
cluster nodes
从上面可以知道,集群关系如下表所示:
| master | slave |
|---|---|
| 6381 | 6385 |
| 6382 | 6386 |
| 6383 | 6384 |
4. 主从容错切换迁移案例
- 数据读写存储
我们进入6381机器,然后插入一条数据。出现(error) MOVED 12706 127.0.0.1:4381
这是因为k1转换后的hash值不属于这个6381分配到的hash槽位,所以插入不进去,所以我们redis-cli不能连接具体的节点,而是整个redis集群,要使用-c参数

bash
redis-cli -p 6381 -c
现在就重定向插入成功了
bash
#这个也可以看集群的信息
redis-cli --cluster check 127.0.0.1:6381
- redis集群的主从切换
我们让master 6381宕机:

然后进入6382查看集群情况:

可以发现原来6381的从节点6385切换成了主节点
如果6381恢复了,分析现在的主从关系:

可以发现6381成为了6385的master了,实验完毕后恢复原来的架构图(6381再次成为master,手动恢复)
5. 主从扩容
现在我们再加入一个主从节点,成为四主四从架构。
- 新增主机6387和6388
bash
docker run -d --name redis-node-7 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387 --daemonize no --protected-mode no
docker run -d --name redis-node-8 --net host --privileged=true -v /Users/jackchai/Desktop/lottory_docker/learndocker/redis/r8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388 --daemonize no --protected-mode no
- 进入6387中,将新增的6387节点(空槽号)作为master节点加入到原集群
bash
redis-cli --cluster add-node 127.0.0.1:6387 127.0.0.1:6381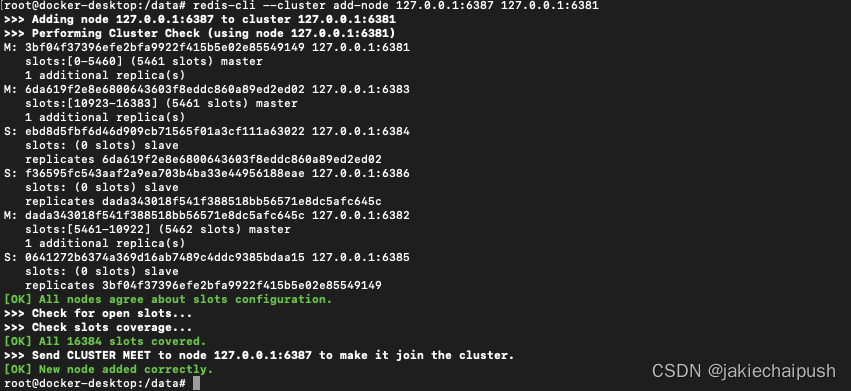
6387成功加入,但是没有分配任何hash槽
bash
redis-cli --cluster check 127.0.0.1:6381
现在确实是4主4从
然后我们需要现在需要重新分配槽位(重点关注是如何分配槽位的)
bash
redis-cli --cluster reshard 127.0.0.1:6381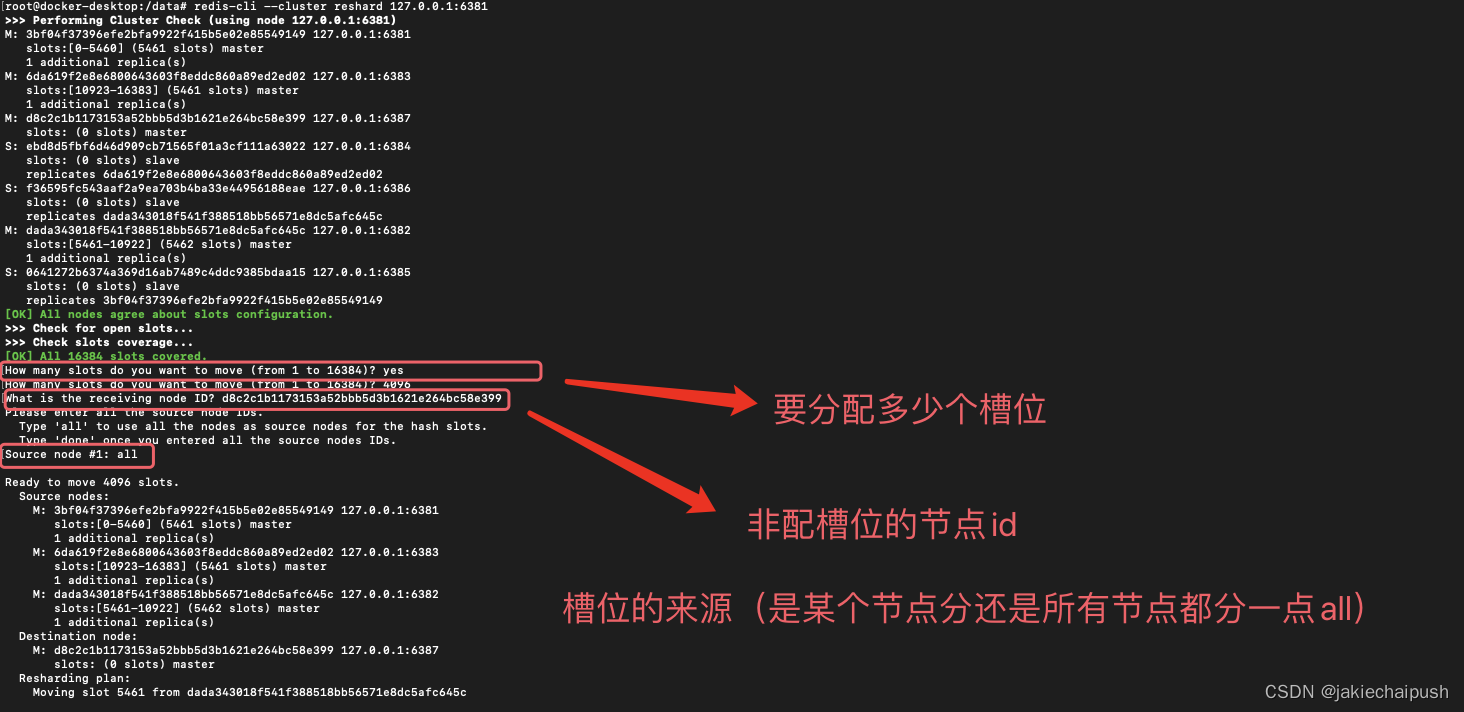
槽位分配完后,看看集群现在情况:
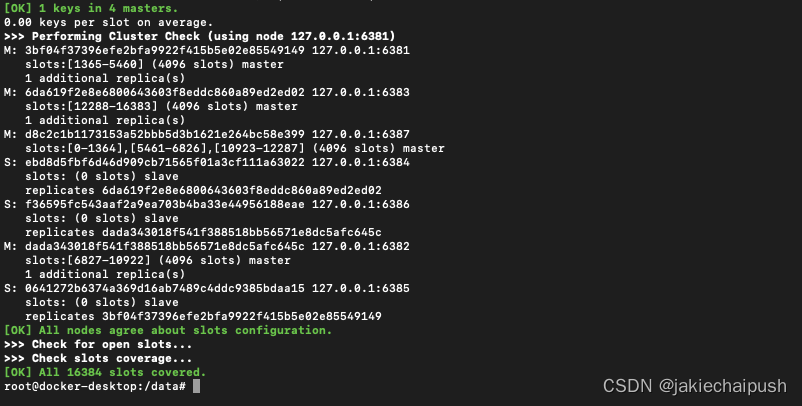
最后将6388加入为6387的从节点
bash
redis-cli --cluster add-node 127.0.0.1:6388 127.0.0.1:6387 --cluster-slave --cluster-master-id d8c2c1b1173153a52bbb5d3b1621e264bc58e399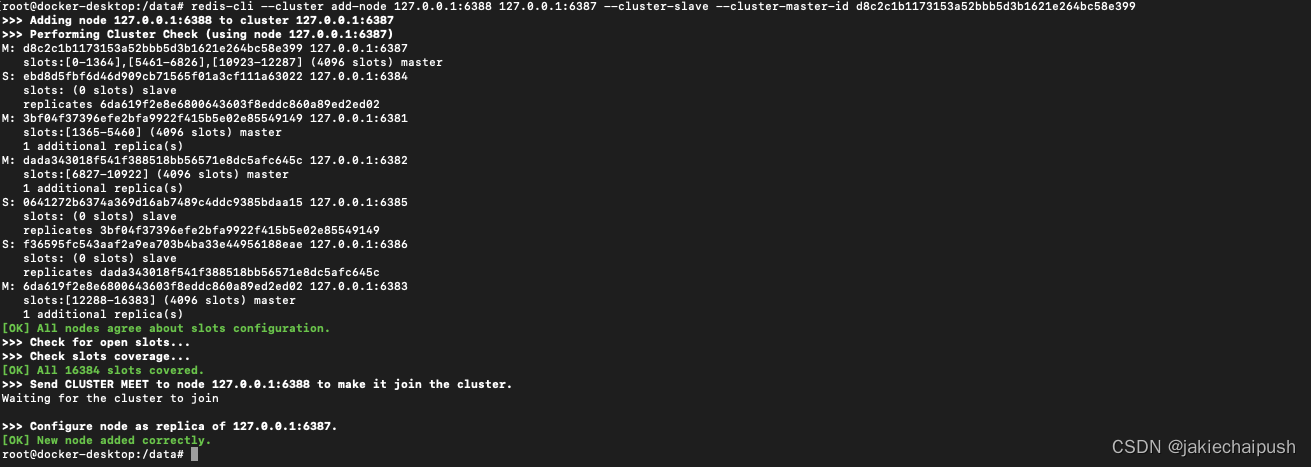
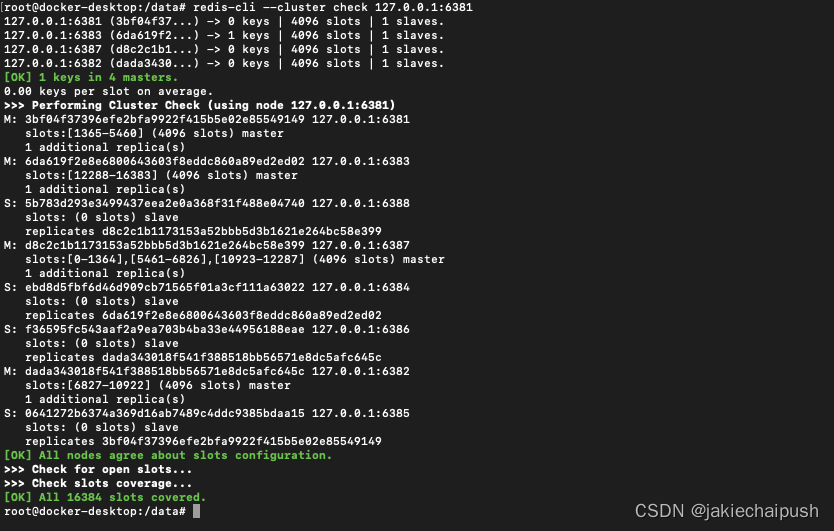
6. 主从缩容
现在我们删除上面增加的6387和6388恢复3主3从架构。
- 先清除掉从节点6388
bash
redis-cli --cluster del-node 127.0.0.1:6388 5b783d293e3499437eea2e0a368f31f488e04740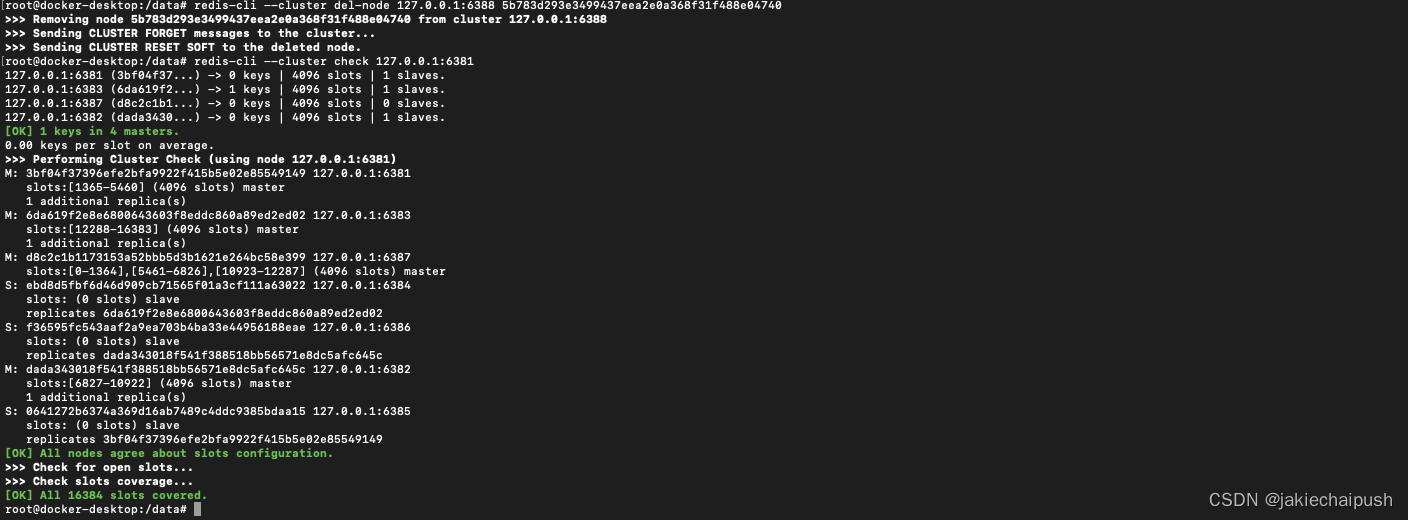
可以发现现在只有3个从节点了
- 将6387的槽号清空,本例将清出来的槽号都给6381
bash
redis-cli --cluster reshard 127.0.0.1:6381
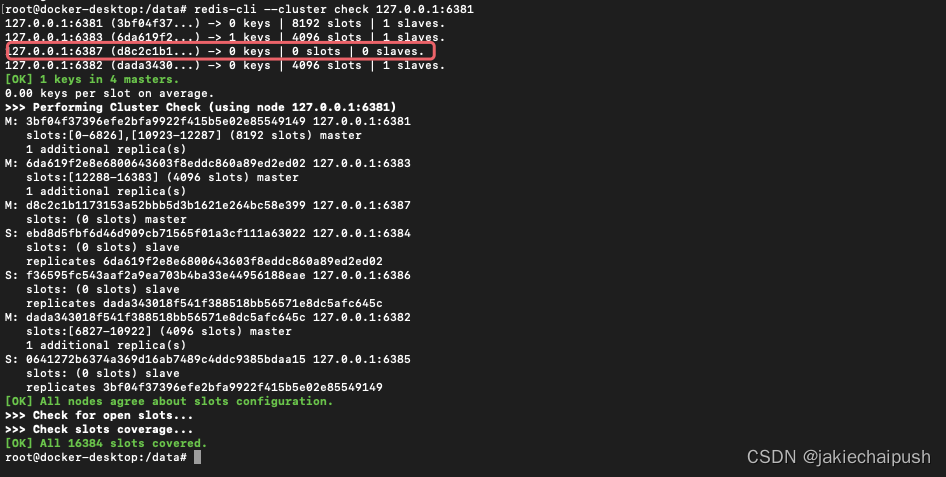
最后删除6387节点:
bash
redis-cli --cluster del-node 127.0.0.1:6387 d8c2c1b1173153a52bbb5d3b1621e264bc58e399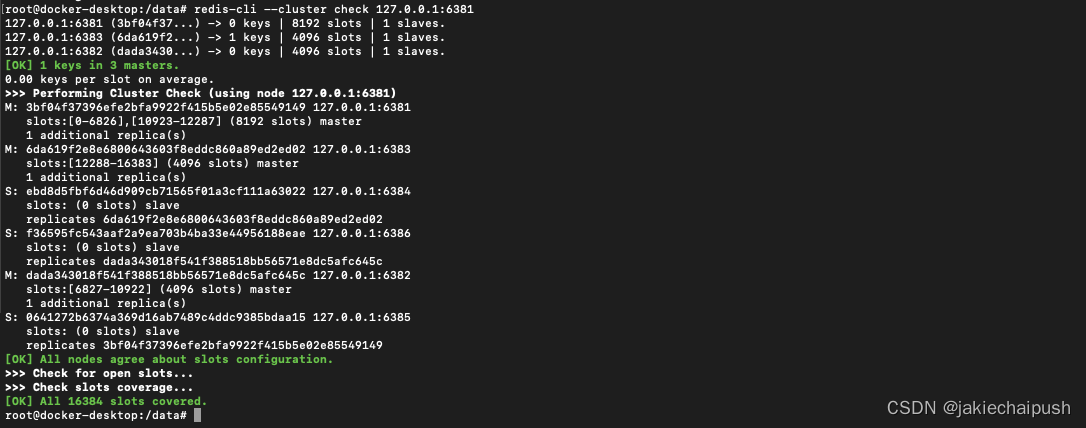
又恢复到3主3从架构了