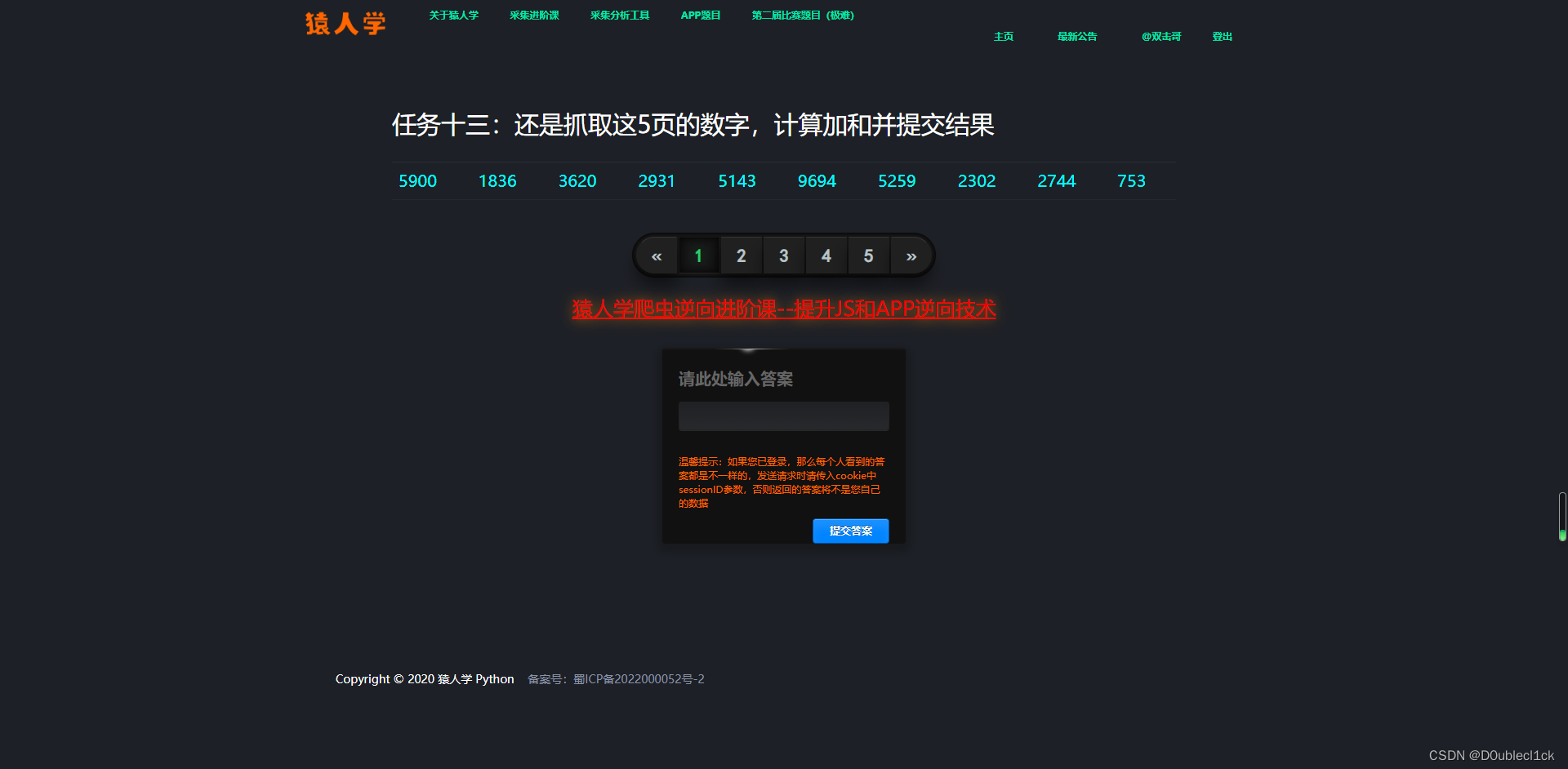
抓包分析
抓包分析发现加密参数是cookie中有一个yuanrenxue_cookie
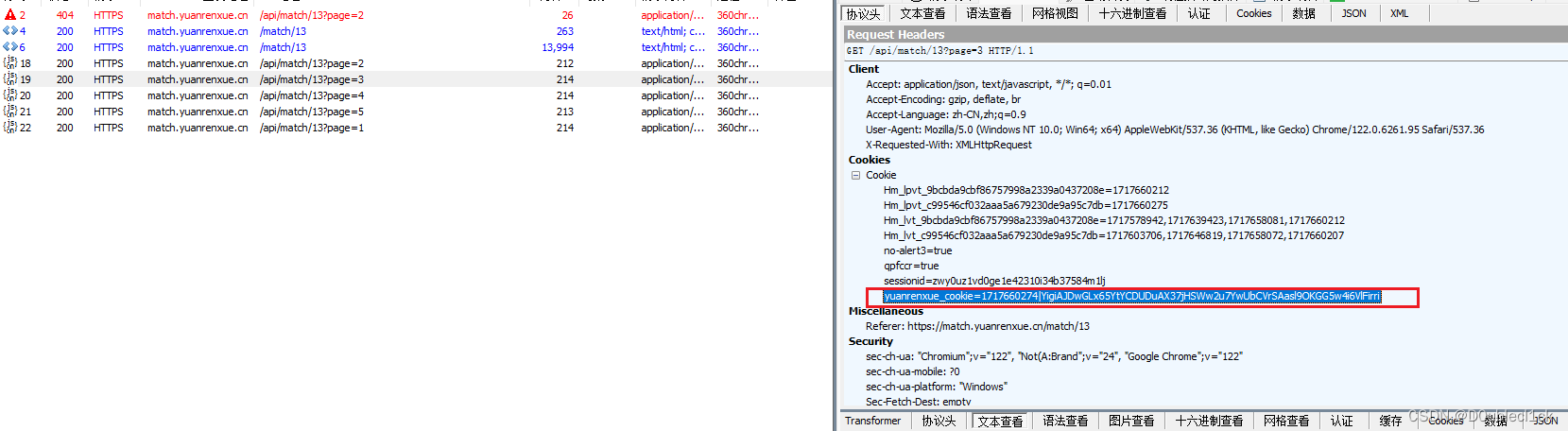
当cookie过期的时候,就会重新给match/13发包,这个包返回一段js代码,应该是生成cookie的

javascript
<script>document.cookie=('y')+('u')+('a')+('n')+('r')+('e')+('n')+('x')+('u')+('e')+('_')+('c')+('o')+('o')+('k')+('i')+('e')+('=')+('1')+('7')+('1')+('7')+('6')+('6')+('0')+('2')+('7')+('4')+('|')+('Y')+('i')+('g')+('i')+('A')+('J')+('D')+('w')+('G')+('L')+('x')+('6')+('5')+('Y')+('t')+('Y')+('C')+('D')+('U')+('D')+('u')+('A')+('X')+('3')+('7')+('j')+('H')+('S')+('W')+('w')+('2')+('u')+('7')+('Y')+('w')+('U')+('b')+('C')+('V')+('r')+('S')+('A')+('a')+('s')+('l')+('9')+('O')+('K')+('G')+('G')+('5')+('w')+('4')+('i')+('6')+('V')+('l')+('F')+('i')+('r')+('r')+('i')+';path=/';location.href=location.pathname+location.search</script>这么看来还不是纯算,而是要发包单独获取。
构建Python代码获取cookie
javascript
import re
import execjs
import requests
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36"
}
cookies = {
}
url = "https://match.yuanrenxue.cn/match/13"
response = requests.get(url, headers=headers, cookies=cookies)
cookieGenerateCode = "(function f() { return " + re.search("\<script\>document\.cookie\=(.*?)\+\'\;path\=\/\'\;", response.text).group(1) + "})()"
yuanrenxue_cookie = execjs.eval(cookieGenerateCode)下面构建爬虫代码
javascript
import re
import execjs
import requests
headers = {
"authority": "match.yuanrenxue.cn",
"referer": "https://match.yuanrenxue.cn/match/13",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
}
cookies = {"sessionid": "zwy0uz1vd0ge1e42310i34b37584m1lj", }
url = "https://match.yuanrenxue.cn/match/13"
response = requests.get(url, cookies=cookies)
cookieGenerateCode = "(function f() { return " + re.search("\<script\>document\.cookie\=(.*?)\+\'\;path\=\/\'\;", response.text).group(1) + "})()"
yuanrenxue_cookie = execjs.eval(cookieGenerateCode).split('=')[-1]
cookies["yuanrenxue_cookie"] = yuanrenxue_cookie
ret = 0
for pageIndex in range(1, 6):
url = "https://match.yuanrenxue.cn/api/match/13"
params = {
"page": str(pageIndex)
}
response = requests.get(url, params=params, cookies=cookies, headers=headers)
for item in response.json()["data"]:
ret += item.get("value")
print(ret)这里有个易错点,很容易犯错!!
第一次请求cookie的时候一定要带上自己的
sessionid,否则拿到的cookie和自己sessionid不匹配,会显示page not found

