一、正则表达式
1.正则表达式基础
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串,将匹配的子串替换或者从某个串中取出符号某个条件的子串等,在linux中代表自定义的模式模板,linux工具可以用正则表达式过滤文本。linux工具能够在处理数据时使用正则表达式对数据进行模式匹配,如果数据符号匹配的要求,那么就会进入下一步处理,如果数据不符合匹配的要求,就会被过滤掉。
正则表达式(正规表达式、常规表达式):
1.使用字符串来描述、匹配一系列符号某个规则的字符串
2.普通字符包括大小写字母、数字、标点符号及一些其他符号组成,元字符是指在正则表示式中具有特殊意义的专用字符
2.元字符
基础正则表达式支持的工具:grep、egrep、sed、awk
|-------------|--------------------------------------------------------|
| 字符 | 功能 |
| \ | 转义,把一些特殊的符号转换成普通的符号字符,还可以把一些普通字符转换成特殊功能,例:\!、\n、\等 |
| \^ | 表示匹配字符串开始的位置,匹配行首 |
| | 表示匹配字符串末尾的位置,匹配行尾 |
| . | 匹配任意的单个字符 |
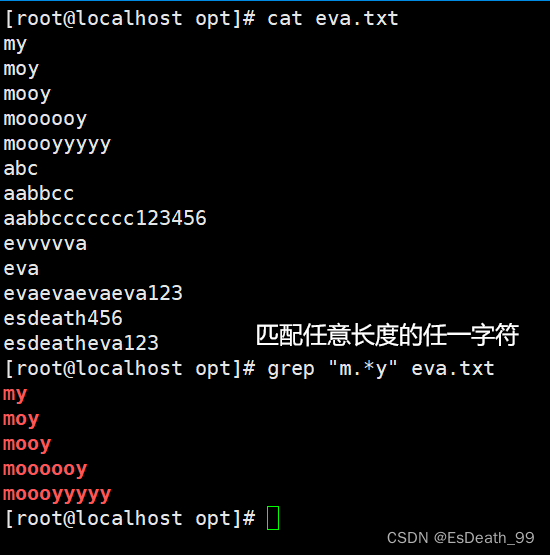
| * | 匹配前面子表达式0次或多次,贪婪模式尽可能长 |
| .* | 表示任意长度的任一字符,不包括0次 |
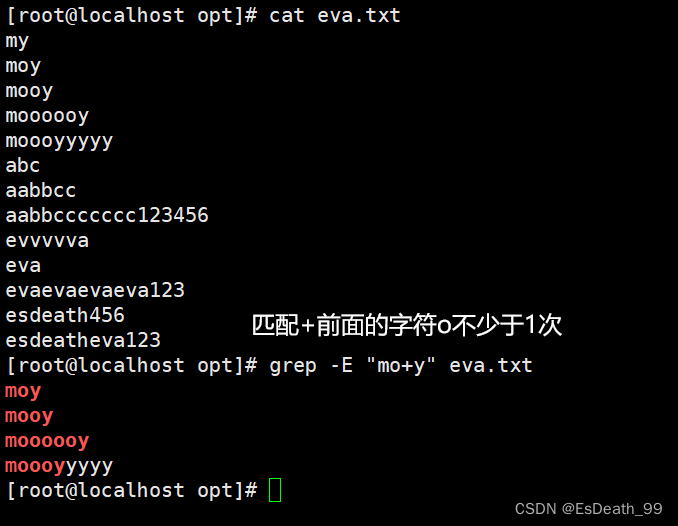
| \? | 匹配其前面的字符0或1次,可有可无 |
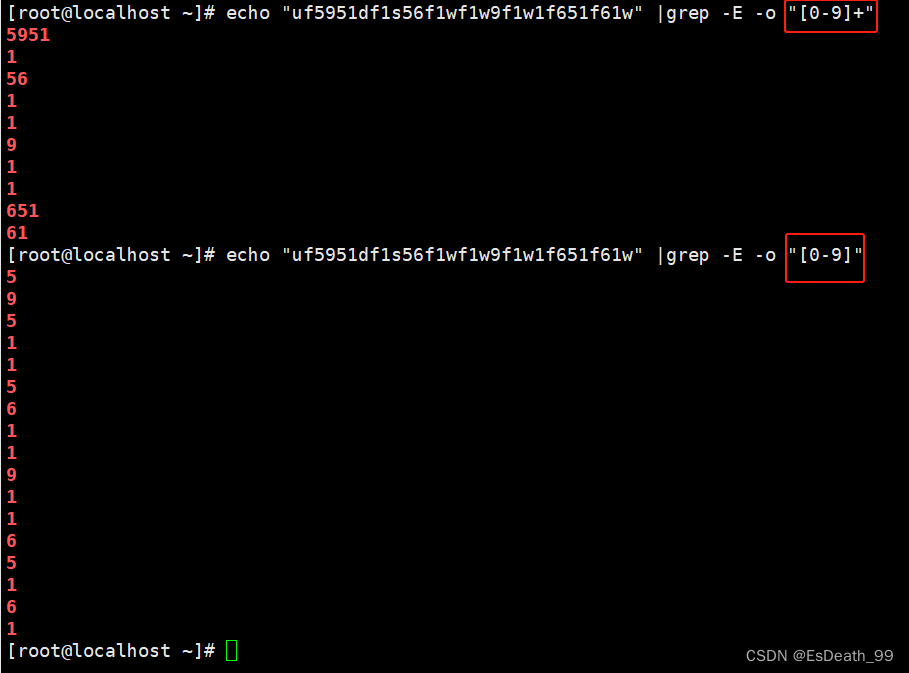
| \+ | 匹配其前面字符最少1次,有且大于等于1次 |
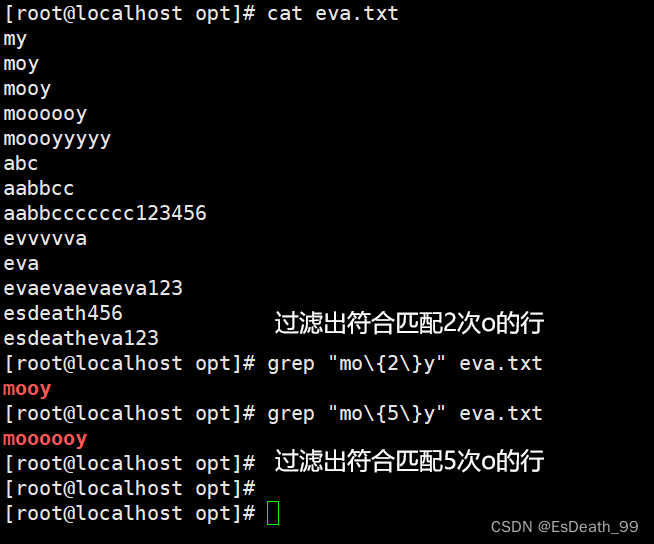
| \{n\} | 匹配前面的子表达式n次 |
| \{n,\} | 匹配前面的子表达式不少于n次 |
| \{,n\} | 匹配前面的子表达式不多于n次 |
| \{n,m\} | 匹配前面的子表达式n到m次(m>=n) |
| \w | 匹配包括下划线的任何单词字符 |
| \W | 匹配任何非单词字符。等价于"\^A-Za-z0-9_"。 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符。等价于\^0-9。 |
| \s | 空白符 |
| :alpha: | 字母,即A-Z,a-z |
| :alnum: | 字母和数字 |
| :lower: | 小写字母,即a-z |
| :upper: | 大写字母,即A-Z |
| :blank: | 空白字符(空格和制表符) |
| :space: | 包括空格、制表符、换行符、回车符等各类型空白 |
| :print: | 可打印字符 |
| :punct: | 标点符号 |
3.扩展正则表达式元字符
支持的工具:egrep、awk、grep -E、sed -r
|----|------------------|
| 字符 | 功能 |
| + | 表示匹配前面的子表达式1次以上 |
| ? | 表示匹配前面的子表达式0次或1次 |
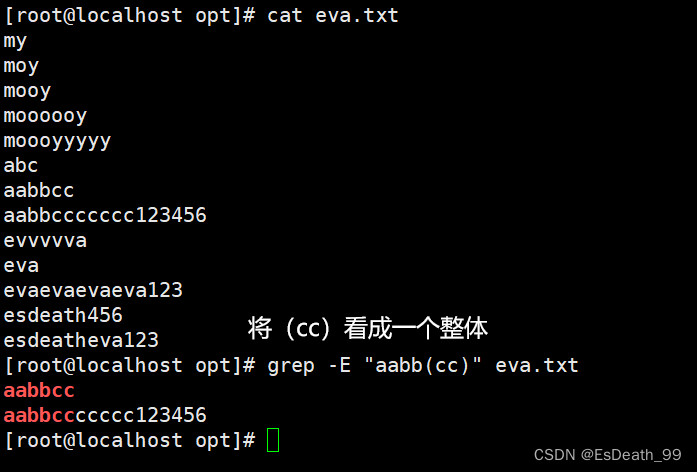
| () | 将括号里的内容看成一个整体 |
| | | 以或的方式匹配字符串 |
+:表示匹配前面的子表达式1次以上
?:表示匹配前面的子表达式0或1次
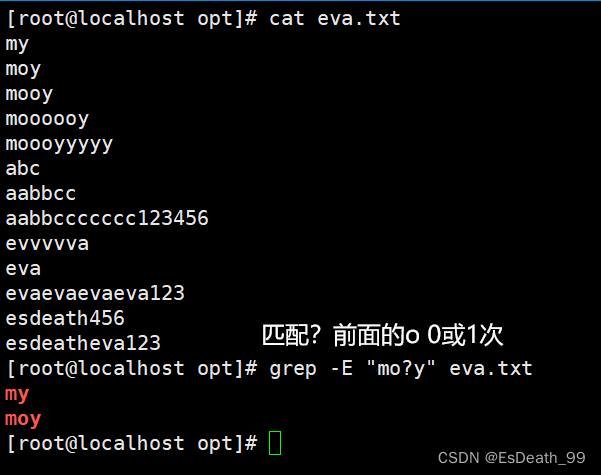
():将括号里的内容看成一个整体
|:以或的方式匹配字符串
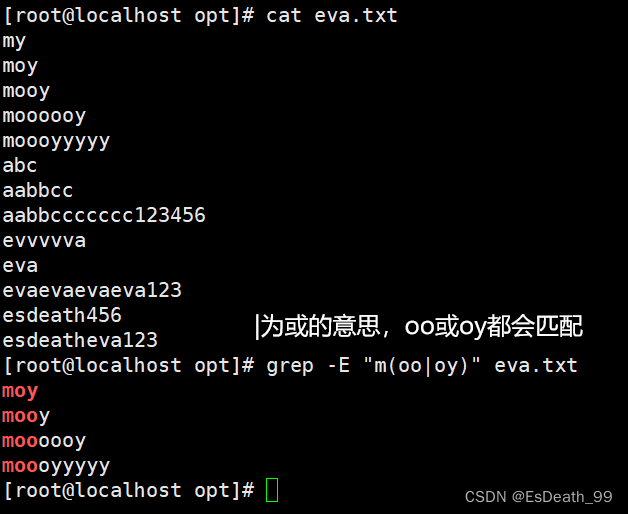
二、grep命令
grep(Global Regular Expression Print):表示全局正则表达式,使用权限是所有用户,grep命令是文本搜索工具,能使用正则表达式搜索文本,并把匹配的行打印出来
|----|--------------------------|
| 选项 | 功能 |
| -m | 匹配几次后停止 |
| -v | 反选 |
| -i | 忽略字符大小写 |
| -n | 显示匹配行号 |
| -c | 统计匹配行数 |
| -o | 仅显示匹配到的字符串 |
| -q | 静默模式 |
| -A | 后几行 |
| -B | 前几行 |
| -C | 前后各几行 |
| -e | 多个选项之间"或者"关系 |
| -w | 匹配整个单词 |
| -E | 启用扩展正则表达式=egrep |
| -F | 不支持正则表达式=fgrep |
| -f | 处理两个文件的相同内容,以第一个文件作为匹配条件 |
| -r | 递归,但不处理软链接 |
| -R | 递归,处理软链接 |
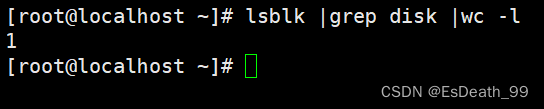
统计lsblk命令显示中磁盘总个数:
在大量文件中快速过滤/etc文件夹下包含root单词的所有文件:

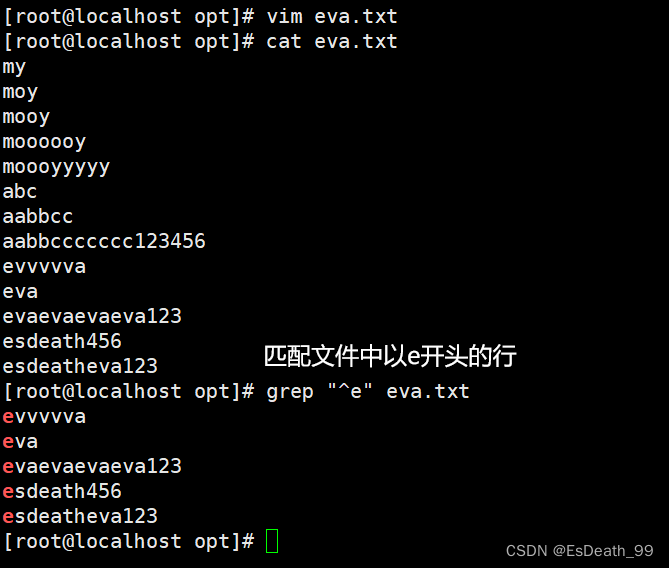
1.^:表示匹配字符串开始的位置,匹配行首
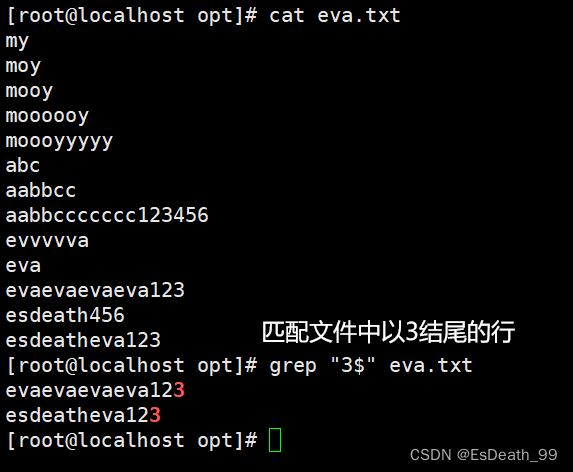
2.$:表示匹配字符串末尾的位置,匹配行尾
3.*:匹配前面子表达式0次或多次,贪婪模式尽可能长
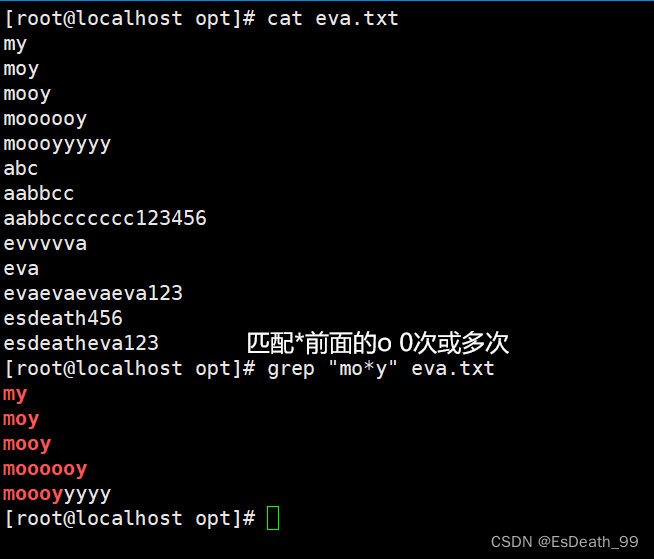
4..:匹配除\n之外的任意的一个字符
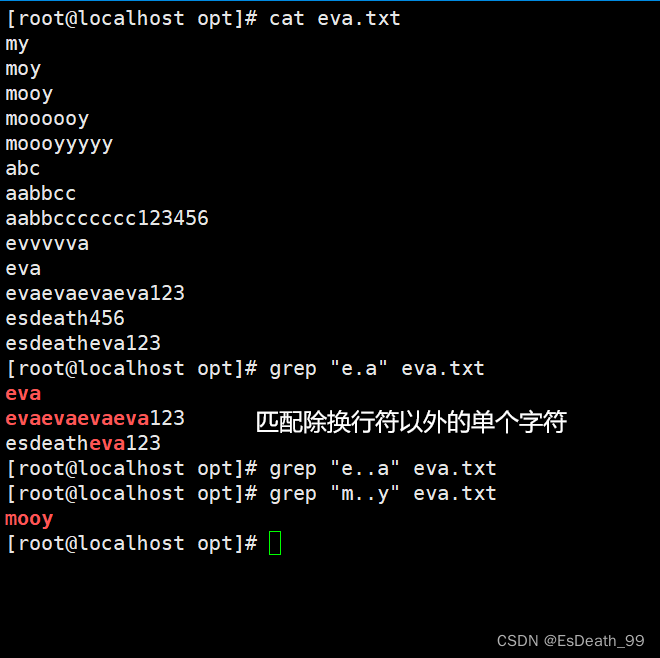
5..*:表示任意长度的任一字符,不包括0次
6.\{n\} 匹配前面的子表达式n次
三、sed命令
1.sed基础
1.sed编辑器是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流
2.sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要存储在一个命令文本文件中
2.sed编辑器的工作流程
sed的工作流程主要包括读取、执行和显示三个过程:
1.读取:sed从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)
2.执行:默认情况下,所有的sed命令都在模式空间中顺序地执行,除非指定了行的地址,否则sed命令将会在所有的行上依次执行
3.显示:发送修改后的内容到屏幕,在发送数据后,模式空间将会被清空,在所有的文件内容都被处理完成之前,上述过程将重复执行,直到被全部处理完成
注:默认情况下所有sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,
除非是用重定向存储输出或者sed -i
3.sed命令选项
|-------|---------------------------|
| 选项 | 功能 |
| -n | 不输出模式空间内容,即不自动打印,加p恢复自动打印 |
| -e | 多点编辑 |
| -f | 从指定文件中读取编辑脚本 |
| -r -E | 使用扩展正则表达式 |
| -i | 备份文件并原处编辑 |
4.sed命令操作
|----|------------------------------------------------------------------------|
| 操作 | 功能 |
| s | 替换,替换指定字符 |
| d | 删除,删除选定的行 |
| a | 增加,在当前行下面增加一行指定内容 |
| i | 插入,在选定行上面插入一行指定内容 |
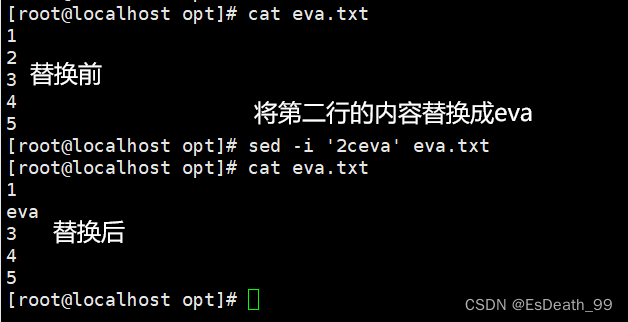
| c | 替换,将选定行替换为指定内容 |
| Y | 字符转换,转换前后的字符长度必须相同 |
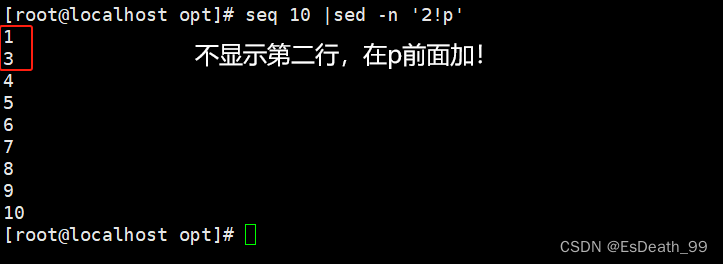
| p | 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII码输出。其通常与"-n"选项一起使用 |
| = | 打印行号 |
| l | 打印数据流中的文本和不可打印的ASCII字符(比如结束符$、制表符\t) |
5.sed打印内容
1.打印输入的全部内容

2.查看文件,打印文件中全部内容
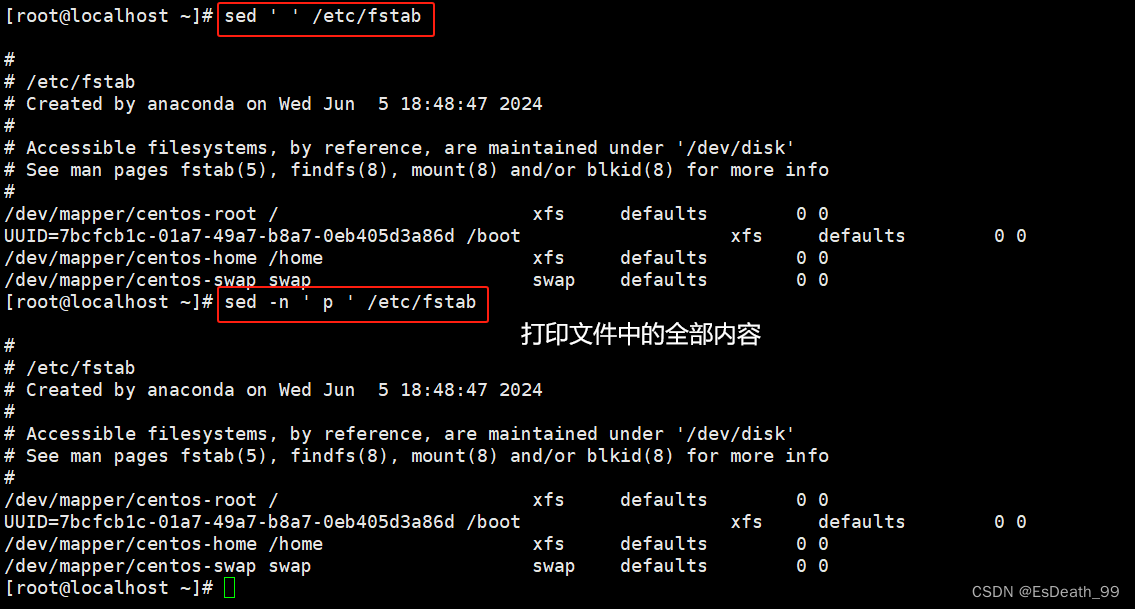
3.打印指定行内容

4.打印指定多行内容
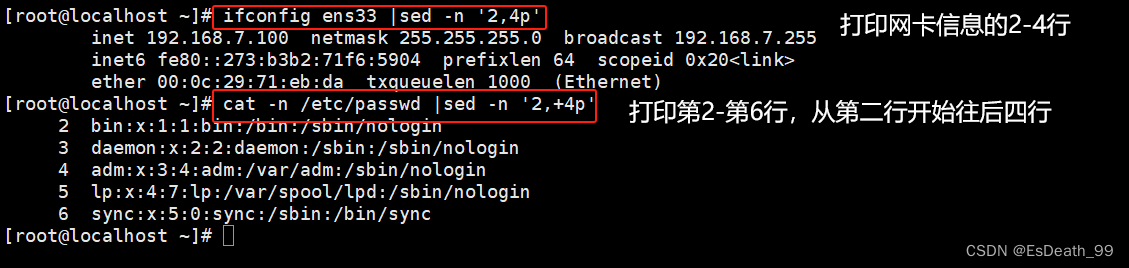
5.打印多(3)行后退出

6.打印最后一行,使用通配符$(最后)

7.支持正则表达式,打印范围内容

8.过滤关键字

9.从第n行开始匹配
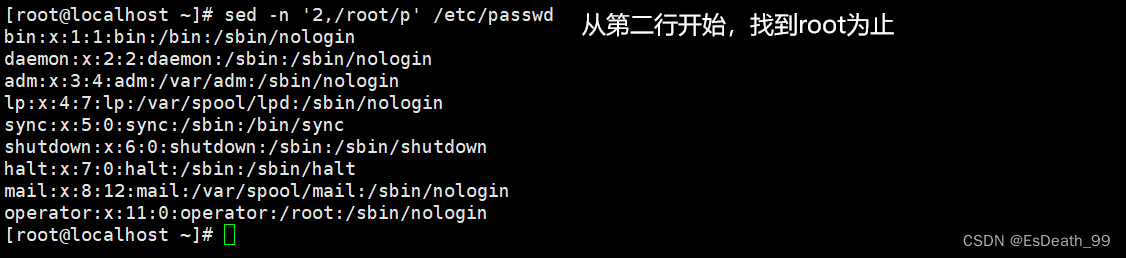
10.找到第n个关键字为止

11.打印文本的奇数行和偶数行

6.sed删除内容
1.删除指定行

2.删除指定的多行
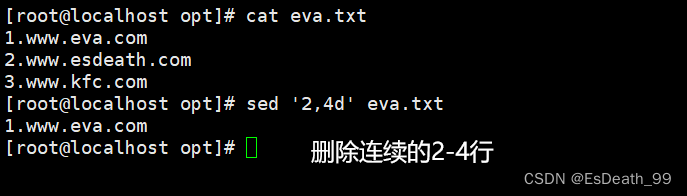
3.删除文本中的空行
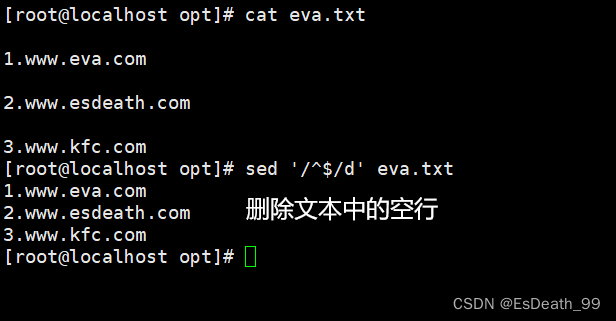
4.删除以指定字符结尾的行及取反
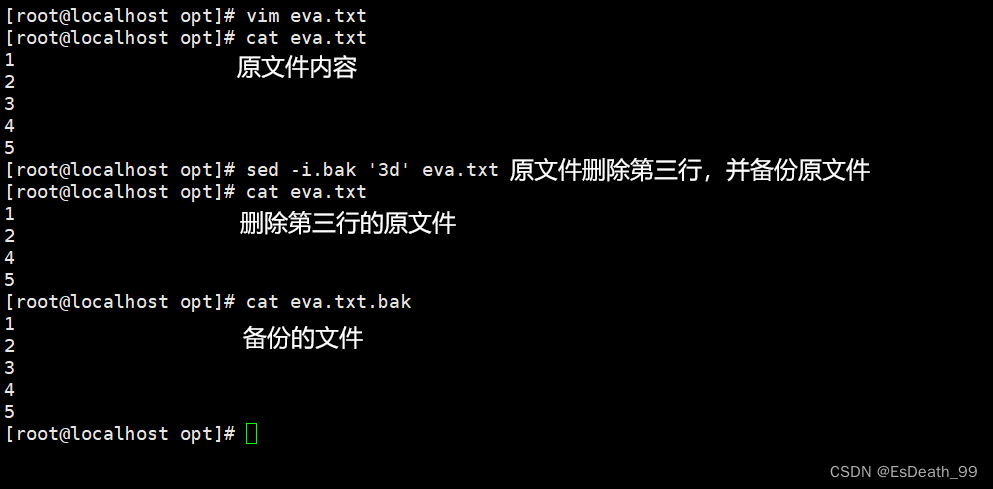
5.先备份内容再删除
7.插入内容
1.在指定行后插入
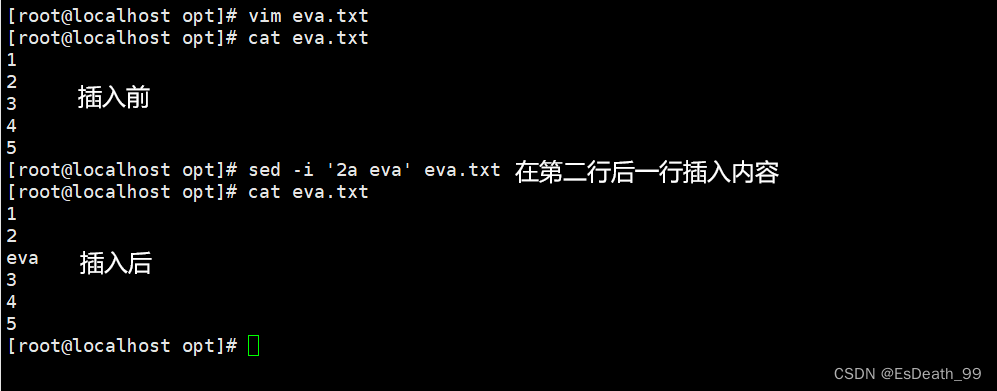
2.插入空行,修改文件的换行,要多加一个\
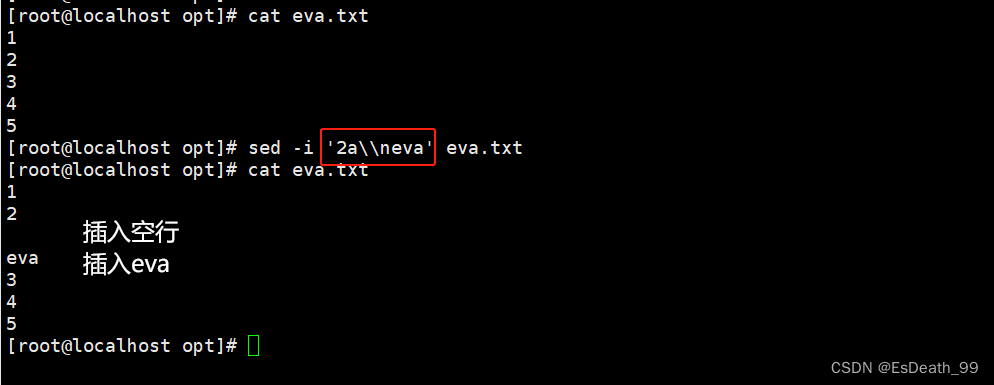
8.替换行内容
9.取反(使用!)
10.搜索替代
|------|---------------------|
| 替换标记 | 作用 |
| 数字 | 表明新字符串将替换第几处匹配的地方 |
| g | 表明新字符串将会替换所有匹配的地方 |
| p | 打印与替换命令匹配的行,与-n一起使用 |
| w文件 | 将替换的结果写到文件中 |
1.修改selinux开机不自启配置文件
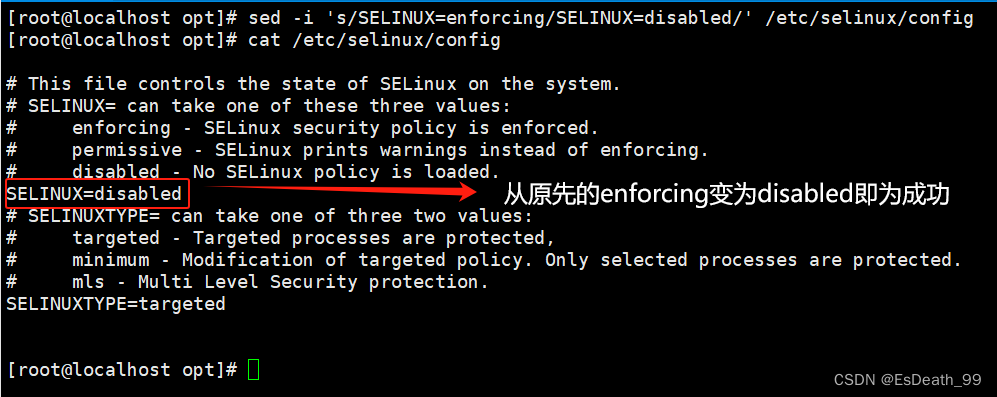
2.修改多行,使用r以及-e
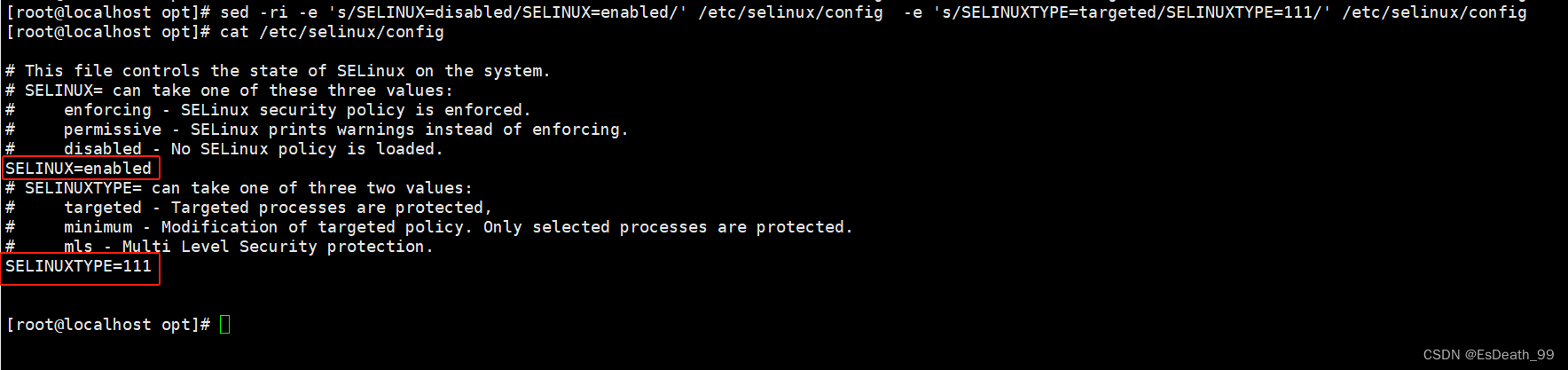
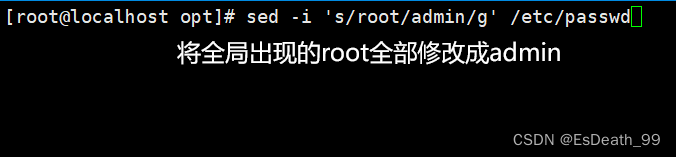
3.修改全局,后面加g
4.查找几点到几点之间的日志

11.分组调用
1.调用分组段

2.提取IP地址
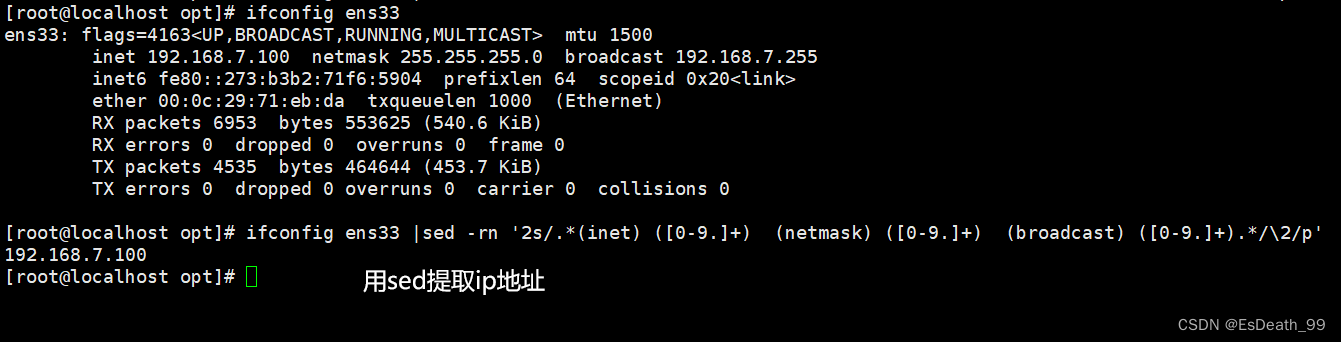
四、awk命令
1.awk基础
awk是一种处理文本文件的语言,是一个强大的文本分析工具,可以在无交互的模式下实现复杂的文本操作,相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据
2.awk格式及原理
awk命令逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理,awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示
命令格式:
awk 选项 '模式条件{操作}' 文件1 文件2
awk -f |-v 脚本文件 文件1 文件2
3.awk常见内建变量
|----------|---------------------------------------------------------------------|
| 变量 | 功能 |
| FS | 列分隔符,指定每行文本的字段分隔符,默认为空格或制表位,与-F作用相同 |
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序数) |
| 0 | 当前处理的行的整行内容 |
| n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是'\n' |
| NF | 最后一段 |
| (NF-1) | 倒数第二段 |
4.awk打印文本内容:
awk可以自动将多个空格压缩成一个空格
打印字符串需要加双引号
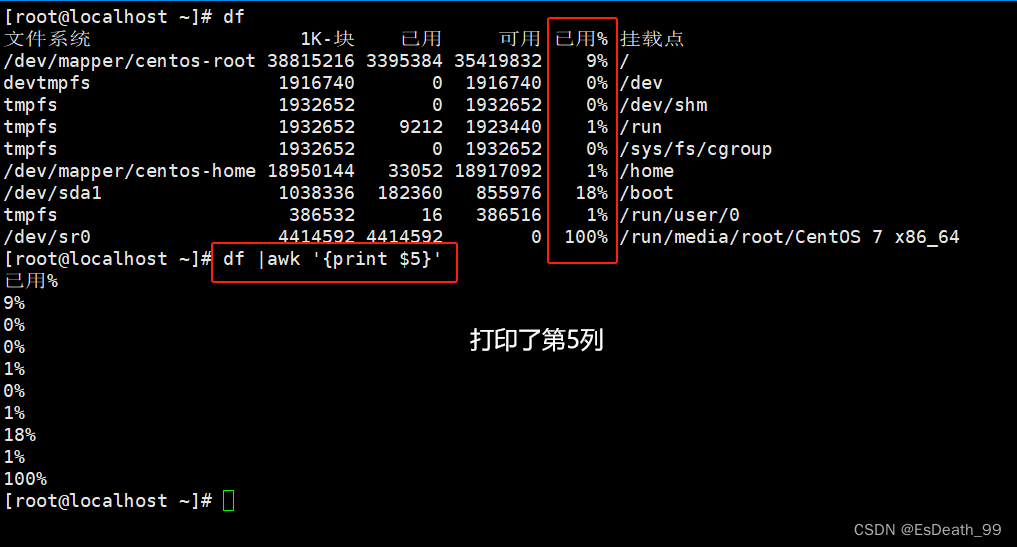
2.打印磁盘已经使用情况
df |awk '{print $5}'
3.打印字符串
awk '{print "hello eva"}'
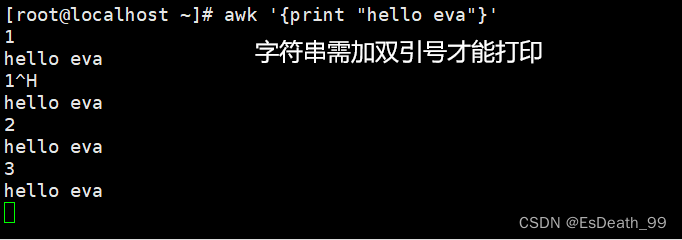
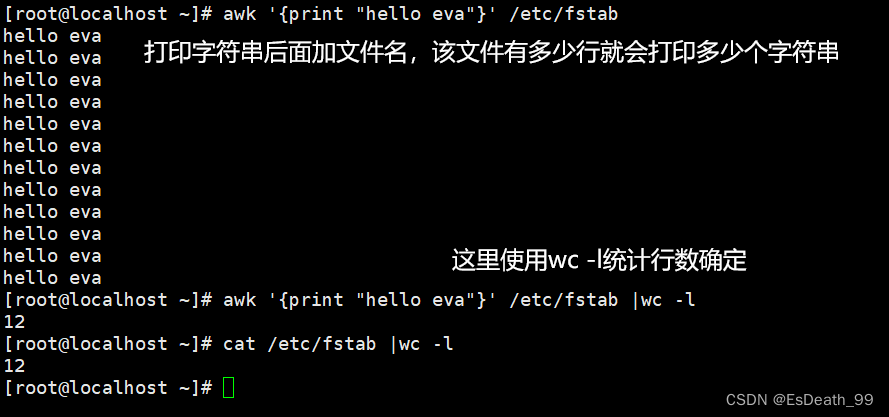
4.打印字符串确定文件有多少行
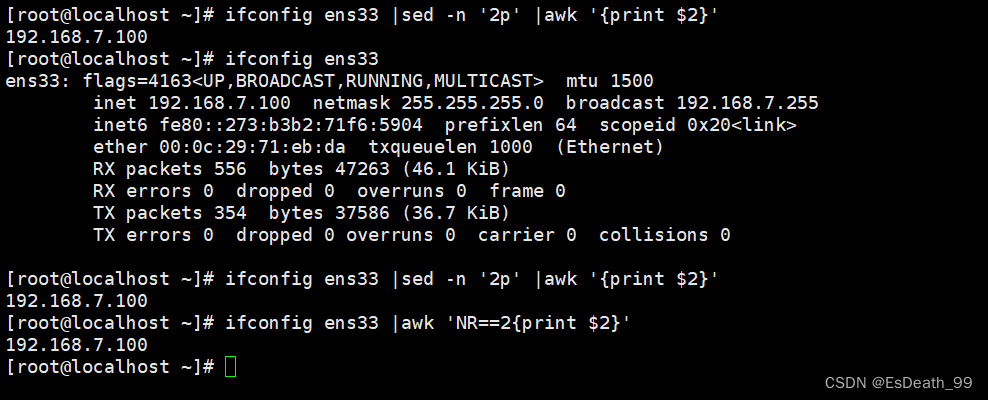
5.awk根据$n已经NR提取字段
$n代表提取第几列
1.提取ip地址
ifconfig ens33 |sed -n '2p' |awk '{print $2}'
ifconfig ens33 |awk 'NR==2{print $2}'
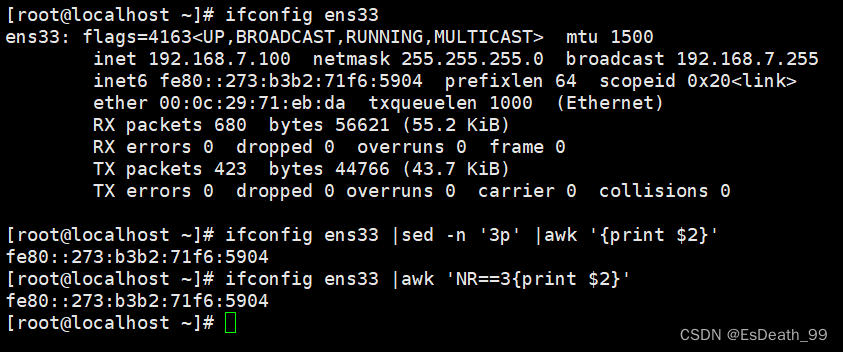
2.提取ipv6地址
ifconfig ens33 |sed -n '3p' |awk '{print $2}'
ifconfig ens33 |awk 'NR==3{print $2}'
6.awk根据选项-F指定分隔符
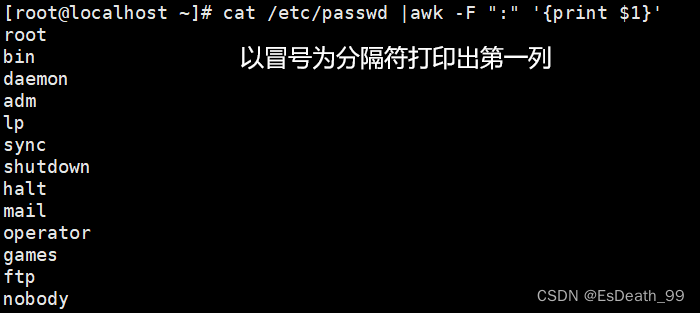
1.打印/etc/passwd所有用户名
cat /etc/passwd |awk -F ":" '{print $1}'
cat /etc/passwd |awk -F: '{print $1}'
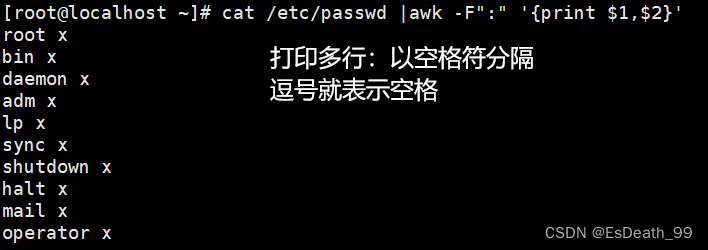
2.打印多列内容
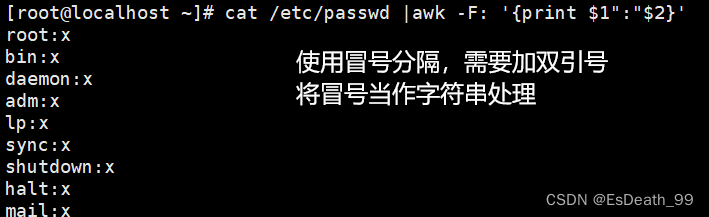
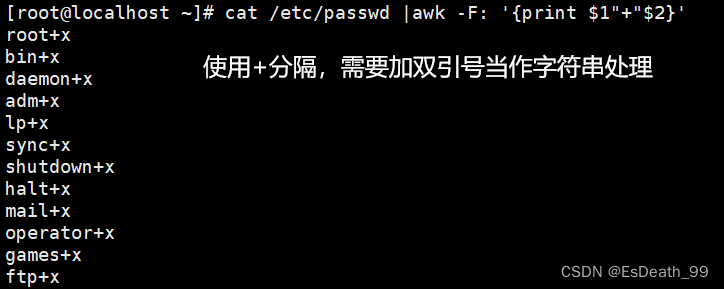
打印时逗号可以表示空格,如果使用:或+,需要将特殊符号加上双引号当成字符串打印
cat /etc/passwd |awk -F":" '{print 1,2}'
cat /etc/passwd |awk -F: '{print 1":"2}'
cat /etc/passwd |awk -F: '{print 1"+"2}'
3.awk打印磁盘已经使用情况,去掉%
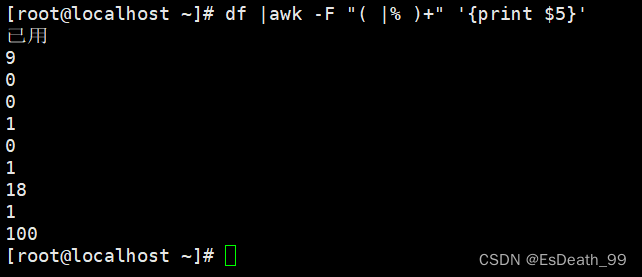
df |awk '{print 5}' \|awk -F% '{print 1}'
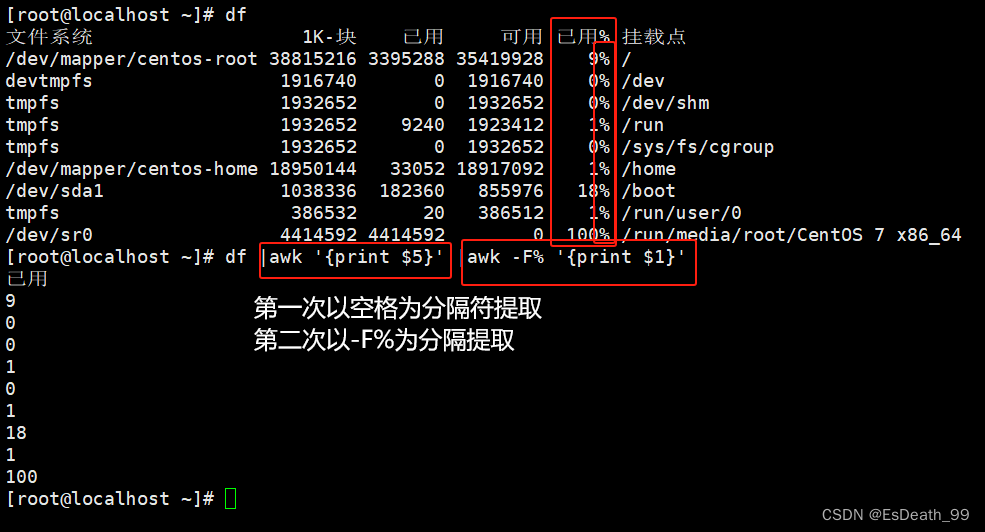
df |awk -F " % +" '{print $5}'

df |awk -F "( |% )+" '{print $5}'
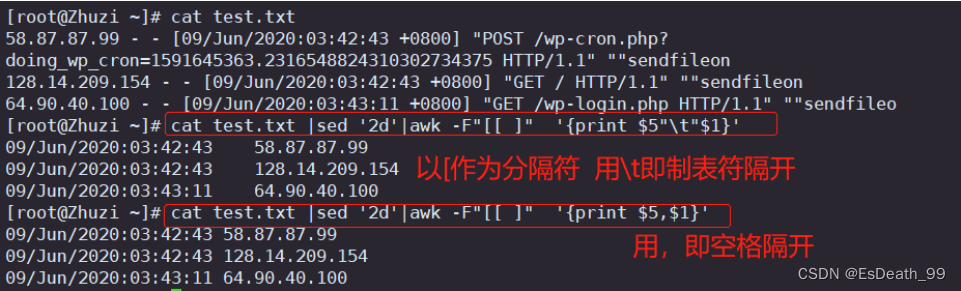
4.取出文本中的ip地址及时间
cat test.txt |sed '2d' |awk -F"\[ " '{print 5"\\t"1}'
cat test.txt |sed '2d' |awk -F"\[ " '{print 5,1}'
5.取出文本中的主机并放回
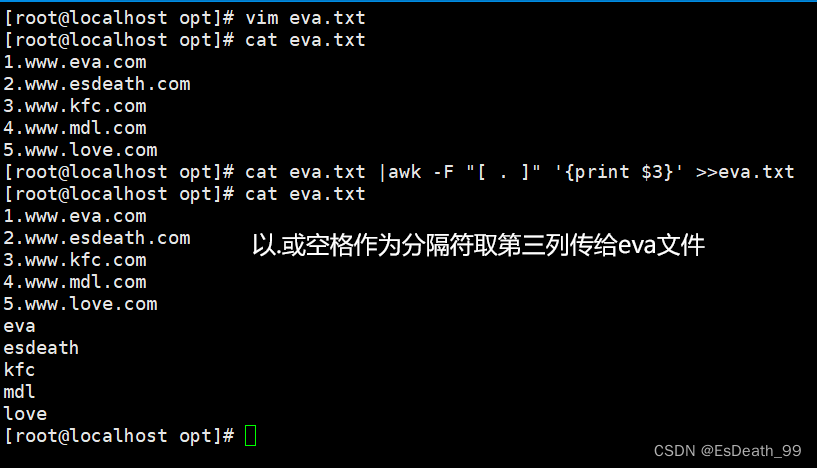
7.awk根据关键字提取所在行
1.提取/etc/passwd以root开头的行
cat /etc/passwd |awk -F":" '/^root/{print}'
.提取/etc/passwd root所在的行
cat /etc/passwd |awk -F: '/root/{print}'

3.提取/etc/passwd nologin结尾的行
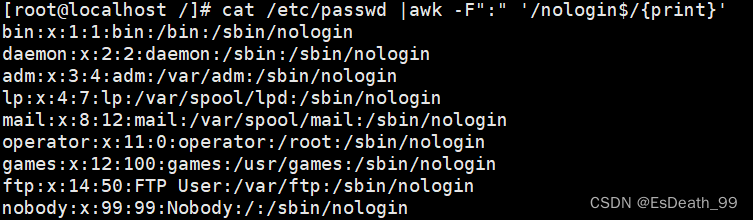
cat /etc/passwd |awk -F":" '/nologin$/{print}'
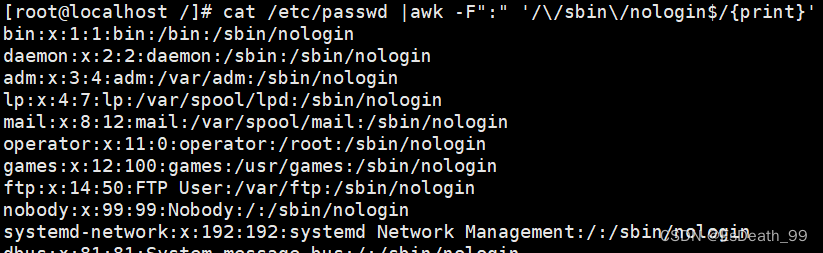
cat /etc/passwd |awk -F":" '/\/sbin\/nologin$/{print}'
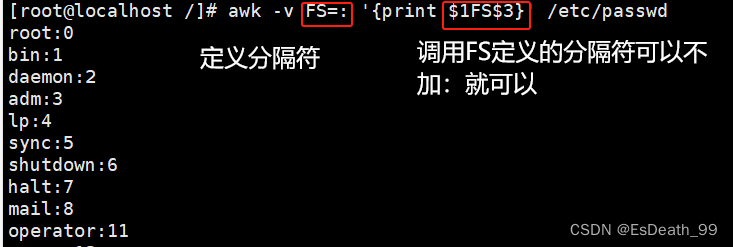
8.FS:指定每行文本的字段分隔符,默认为空格或制表符,与-F相同
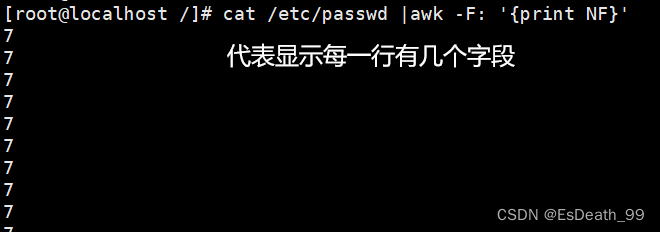
9.NF:当前处理行的整行内容
1.当前处理的行的字段个数
cat /etc/passwd |awk -F: '{print NF}'
2.打印出每行最后一个字段
cat /etc/passwd |awk -F: '{print $NF}'
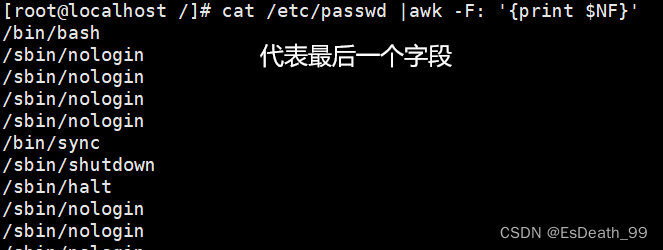
3.打印出每行倒数第二个字段
cat /etc/passwd |awk -F: '{print $(NF-1)}'
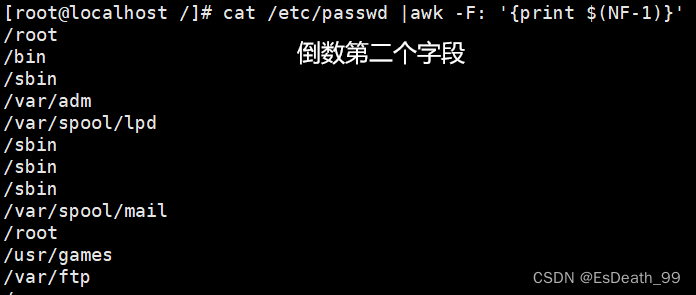
df|awk '{print $(NF-1)}'
10.NR:当前处理行的行号
1.当前处理的行的行号
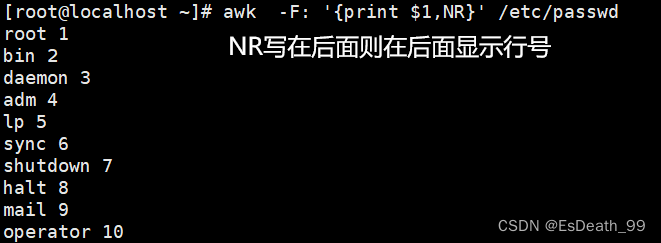
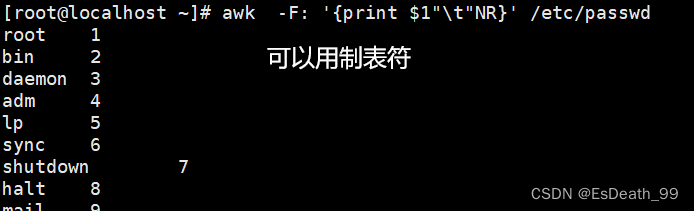
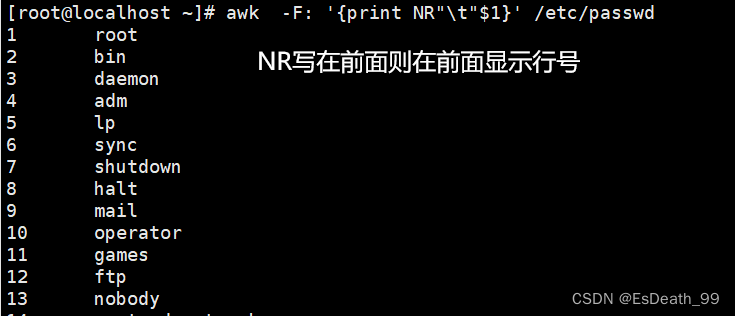
2.NR==n代表行号等于什么

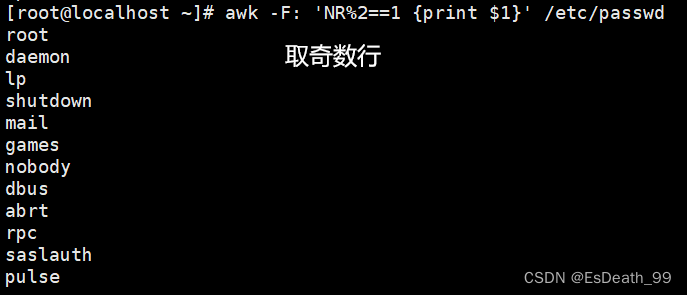
3.NR%2==0取偶数行

4.NR%2==1取奇数行
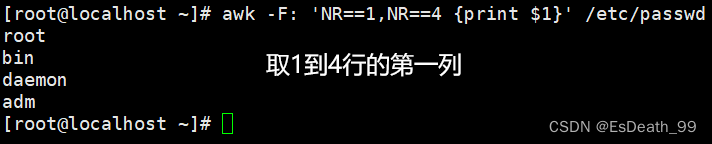
5.NR==1,NR==4取区间行
6.取UID数值范围$n>1000

11.例子
1.统计/etc/fstab文件中每个文件系统类型出现的次数

2.统计/etc/fstab文件中每个单词出现的次数
3.将某日志文件访问用户的IP地址,在第三列冒号隔开,统计出访问量前十的IP地址

4.提取出字符串uf5951df1s56f1wf1w9f1w1f651f61w中所有的数字