torch.optim - PyTorch中文文档 (pytorch-cn.readthedocs.io)
torch.optim --- PyTorch 2.3 documentation
反向传播 可以求出神经网路中每个需要调节参数的梯度(grad ),优化器 可以根据梯度进行调整,达到降低整体误差的作用。下面我们对优化器进行介绍。
构造优化器
python
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)- 选择优化器的算法
optim.SGD - 之后在优化器中放入模型参数
model.parameters(),这一步是必备的 - 还可在函数中设置一些参数,如学习速率
lr=0.01(这是每个优化器中几乎都会有的参数)
调用优化器中的step方法
step()方法就是利用我们之前获得的梯度,对神经网络中的参数进行更新。
python
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()-
步骤
optimizer.zero_grad()是必选的。对每个参数的梯度进行清零 -
我们的输入经过了模型,并得到了输出
output -
之后计算输出和target之间的误差
loss -
调用误差的反向传播
loss.backwrd,更新每个参数对应的梯度。 -
调用
optimizer.step()对卷积核中的参数进行优化调整。 -
之后继续进入
for循环,使用函数optimizer.zero_grad()对每个参数的梯度进行清零,防止上一轮循环中计算出来的梯度影响下一轮循环。
优化器的使用
优化器中算法共有的参数(其他参数因优化器的算法而异):
-
params: 传入优化器模型中的参数
-
lr: learning rate,即学习速率
关于学习速率:
-
一般来说,学习速率设置得太大 ,模型运行起来会不稳定
-
学习速率设置得太小 ,模型训练起来会过慢
-
建议在最开始 训练模型的时候,选择设置一个较大 的学习速率;训练到后面 的时候,再选择一个较小的学习速率
代码实战:
选择CIFAR10
python
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential, Flatten
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(64 * 4 * 4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
result_loss = loss(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
# print(result_loss)
running_loss = running_loss + result_loss
print(running_loss)输出:
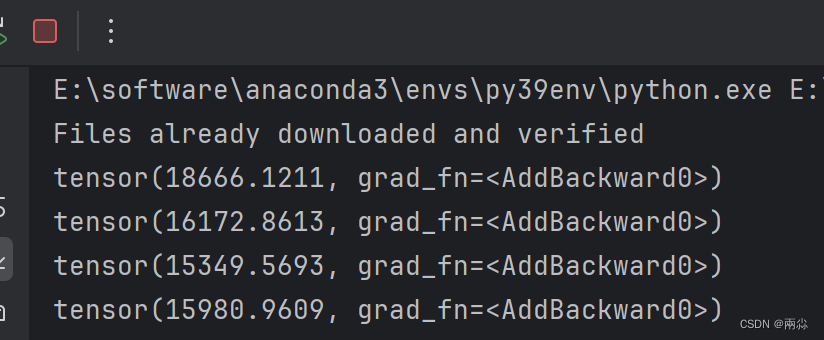
总结 (使用优化器训练的训练套路):
-
设置损失函数loss function
-
定义优化器optim
-
从使用循环dataloader中的数据:for data in dataloder
-
取出图片imgs,标签targets:imgs,targets=data
-
将图片放入神经网络,并得到一个输出:output=model(imgs)
-
计算误差:loss_result=loss(output,targets)
-
使用优化器,初始化参数的梯度为0:optim.zero_grad()
-
使用反向传播求出梯度:loss_result.backward()
-
根据梯度,对每一个参数进行更新:optim.step()
-
-
进入下一个循环,直到完成训练所需的循环次数