1 废话不多说,直接上代码
opencv方式
python
import time
import subprocess
import cv2, os
from math import ceil
def extract_frames_opencv(video_path, output_folder, frame_rate=1):
"""
使用 OpenCV 从视频中抽取每秒指定帧数的帧,并保存到指定文件夹。
如果视频长度不是整数秒,则会在最后一帧时补充空白图像。
参数:
video_path (str): 输入视频文件的路径。
output_folder (str): 输出帧图像文件的文件夹路径。
frame_rate (int): 每秒抽取的帧数,默认为 1。
返回:
None
"""
start_time = time.time()
# 创建输出文件夹
os.makedirs(output_folder, exist_ok=True)
# 打开视频文件
cap = cv2.VideoCapture(video_path)
# 获取视频长度和帧率
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
duration = total_frames / fps
# 计算需要抽取的总帧数
target_frames = int(duration * frame_rate)
# 逐帧抽取图像
frame_idx = 0
for i in range(target_frames):
cap.set(cv2.CAP_PROP_POS_FRAMES, int(i * fps / frame_rate))
ret, frame = cap.read()
if ret:
cv2.imwrite(os.path.join(output_folder, f"frame_{frame_idx:06d}.jpg"), frame)
frame_idx += 1
else:
break
# 如果最后一帧不是完整的一帧,则补充空白图像
if frame_idx < target_frames:
for i in range(frame_idx, target_frames):
blank_image = 255 * np.ones((int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), 3), dtype=np.uint8)
cv2.imwrite(os.path.join(output_folder, f"frame_{i:06d}.jpg"), blank_image)
# 释放视频捕获对象
cap.release()
print(f"成功从视频中抽取了 {target_frames} 帧, 一共耗时{time.time() - start_time}s")ffmpeg方式
python
def extract_frames_ffmpeg(video_path, output_folder, frame_rate=1):
"""
使用 FFmpeg 从视频中抽取每秒指定帧数的帧,并保存到指定文件夹。
如果视频长度不是整数秒,则会抛出异常。
参数:
video_path (str): 输入视频文件的路径。
output_folder (str): 输出帧图像文件的文件夹路径。
frame_rate (int): 每秒抽取的帧数,默认为 1。
返回:
None
"""
start_time = time.time()
# 创建输出文件夹
os.makedirs(output_folder, exist_ok=True)
# 获取视频长度
command = ["ffprobe", "-v", "error", "-show_entries", "format=duration", "-of",
"default=nokey=1:noprint_wrappers=1", video_path]
result = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if result.returncode != 0:
raise ValueError("Failed to get video duration.")
duration = float(result.stdout.decode().strip())
# 四舍五入视频长度到最接近的整数秒
duration = round(duration)
# 构建 FFmpeg 命令
command = [
"ffmpeg",
"-i", video_path,
"-vf", f"fps={frame_rate}",
"-frames:v", "%d" % (ceil(duration * frame_rate)),
os.path.join(output_folder, "frame_%06d.jpg")
]
# 执行 FFmpeg 命令
subprocess.run(command, check=True)
print(f"成功从视频中抽取了 {ceil(duration * frame_rate)} 帧, 一共耗时{time.time() - start_time}s")2 测试实验对比
测试一个56s的mp4文件
extract_frames_opencv(video_path, output_folder, 1) # 成功从视频中抽取了 55 帧, 一共耗时10.131151914596558s extract_frames_ffmpeg(video_path, output_folder, 1) # 成功从视频中抽取了 56 帧, 一共耗时8.075150966644287s
1帧/s时,ffmpeg稍快2s
extract_frames_opencv(video_path, output_folder1, 5) # 成功从视频中抽取了 278 帧, 一共耗时54.822526931762695s extract_frames_ffmpeg(video_path, output_folder2, 5) # 成功从视频中抽取了 280 帧, 一共耗时8.546468019485474s
5帧/s时,ffmpeg方式只增加0.5s,opencv增加了5倍时长。
在大文件抽帧、或者抽帧频率较高时,ffmpeg效率更高。
3 ffmpeg抽帧图片更小?
对比了下抽帧图片,分辨率一致,但是ffmpeg抽帧图片好像小很多,为什么呢?
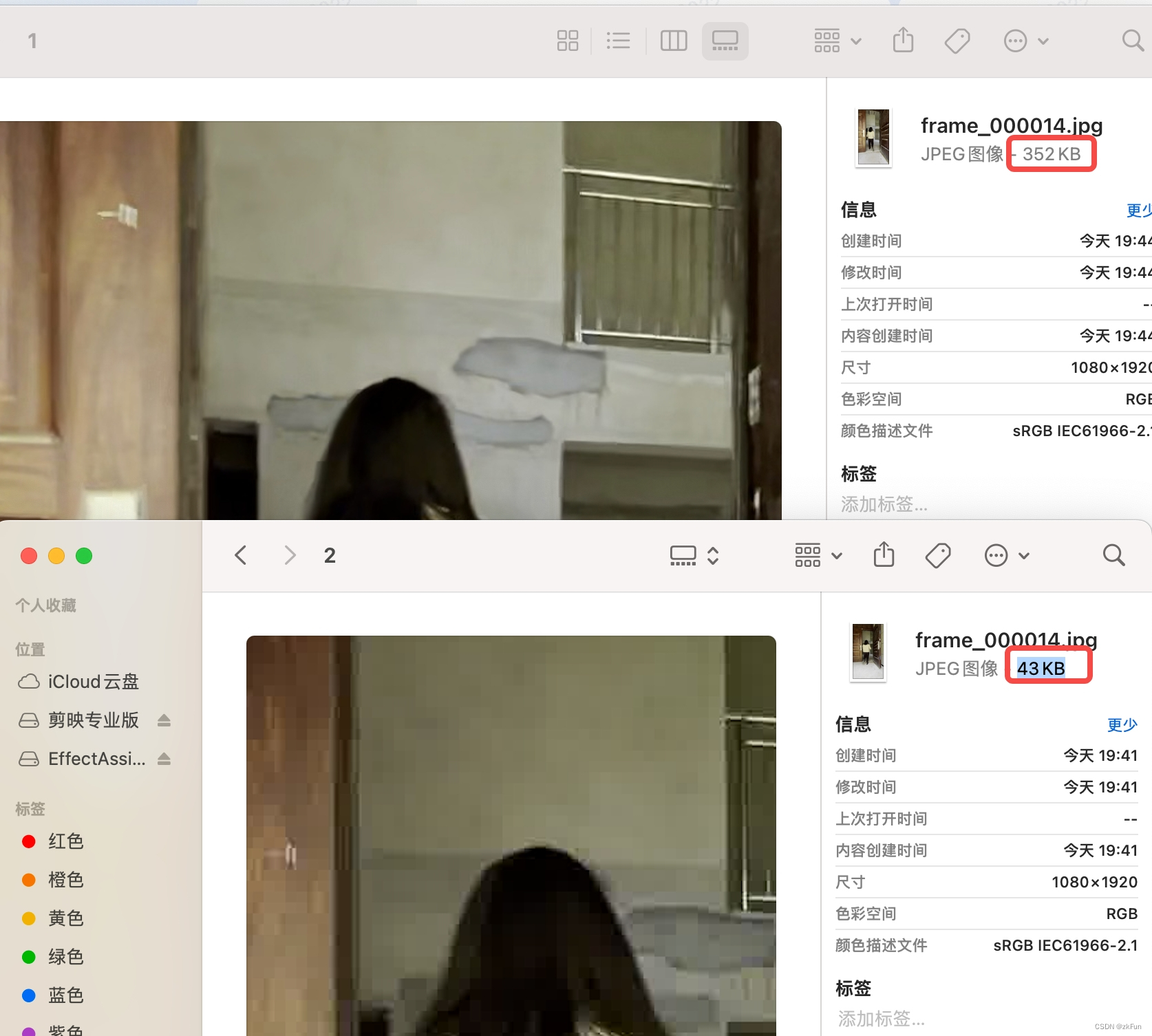
搜了下官方解释:
FFmpeg 和 OpenCV 在抽取视频帧并保存图像时,可能会产生不同的结果,包括文件大小和图像质量等。出现这种差异的原因主要有以下几点:
-
编码器选择 :
- FFmpeg 默认使用 JPEG 编码器,这种编码方式通常可以生成较小的文件大小,但可能会略有些图像质量损失。
- OpenCV 默认使用无损的 PNG 编码器,生成的文件通常会更大,但图像质量更好。
-
色彩空间转换 :
- FFmpeg 在抽取帧时,可能会将视频的色彩空间转换为更适合 JPEG 编码的格式,例如 YUV 420。这种转换可以进一步减小文件大小。
- OpenCV 则可能会保留视频原有的色彩空间,如 RGB,在保存为 PNG 时不进行额外的转换。
-
图像缩放和重采样 :
- FFmpeg 在抽取帧时,可能会根据输出分辨率对图像进行缩放和重采样,从而进一步优化文件大小。
- OpenCV 则可能会直接保存原始分辨率的图像,不进行任何缩放处理。
综上所述,FFmpeg 在抽取视频帧并保存为图像时,通常会采取一些优化措施,如使用 JPEG 编码、色彩空间转换和图像缩放等,从而生成相对较小的文件大小。而 OpenCV 则更倾向于保留原始的视觉质量,因此生成的图像文件会相对更大。