目录
[二、GPT-OSS 模型简介](#二、GPT-OSS 模型简介)
[1. 版本与定位](#1. 版本与定位)
[2. 架构设计与技术亮点](#2. 架构设计与技术亮点)
[2.1 Mixture-of-Experts(MoE)架构](#2.1 Mixture-of-Experts(MoE)架构)
[2.2 高效推理机制与优化技术](#2.2 高效推理机制与优化技术)
[2.3 模型对比](#2.3 模型对比)
[1. 安装相关依赖](#1. 安装相关依赖)
[1.1 uv 安装](#1.1 uv 安装)
[1.2 conda 安装](#1.2 conda 安装)
[1.3 Transformers 运行 gpt-oss](#1.3 Transformers 运行 gpt-oss)
一、引言
2025 年 8 月,OpenAI 推出了自 GPT-2(2019 年) 以来首个开源权重的大型语言模型系列------GPT-OSS (Generative Pre-trained Transformer -- Open-Source Series)。此次发布包含两款模型:gpt-oss-120b (117B 参数)和 gpt-oss-20b(21B 参数),均采用开放的 Apache 2.0 许可协议,标志着 OpenAI 向开源社区迈出了重要一步。
二、GPT-OSS 模型简介
1. 版本与定位
-
gpt-oss-120b:约 117B 总参数,适用于强推理需求,能在一张 80 GB GPU 上运行。
-
gpt-oss-20b:约 21B 参数,适用于边缘设备与轻量级部署,仅需 16 GB 显存。
两者都支持强链式思维(Chain-of-Thought)、工具调用与结构化输出格式,专为复杂推理和开发者定制场景设计。
2. 架构设计与技术亮点
2.1 Mixture-of-Experts(MoE)架构
GPT-OSS 延续 Transformer 模型框架,但每层引入 MoE 设计:
-
gpt-oss-120b :每层包含 128 个专家网络;每个 token 激活 4 个专家,活跃参数约为 5.1 B 。
-
gpt-oss-20b:每层 32 个专家,激活 4 个专家,活跃参数约为 3.6 B 。
这样能在保持模型表达能力的同时,大幅降低每次推理的计算与内存成本。
2.2 高效推理机制与优化技术
-
MXFP4 量化:MoE 权重采用4位量化,显存占用显著下降,使 gpt-oss-120b 能在 80GB GPU 上运行,gpt-oss-20b 可在 16 GB 内存设备上本地运行。
-
长上下文支持:通过 Rotary Position Embeddings 与 YaRN 技术,将上下文长度扩展至 131,072 tokens,适合长文档理解与复杂推理。
-
Attention 机制优化:混合局部稠密和带稀疏带的 Attention,组查询 Attention(Grouped Query Attention)减少延迟与内存占用。
-
Harmony 响应格式:采用统一响应格式并开源 o200k_harmony tokenizer,方便开发者统一接入 behavior 和规范。
gpt-oss系列不仅在标准任务中表现出色,其推理能力的优化也让它在多个实际应用中成为首选。两个模型的参数调整可以根据具体需求灵活设置,支持低、中、高三种推理力度,满足不同延迟需求的应用场景。开发者还可以根据具体需求,进行模型微调,以进一步优化其在特定任务中的表现。
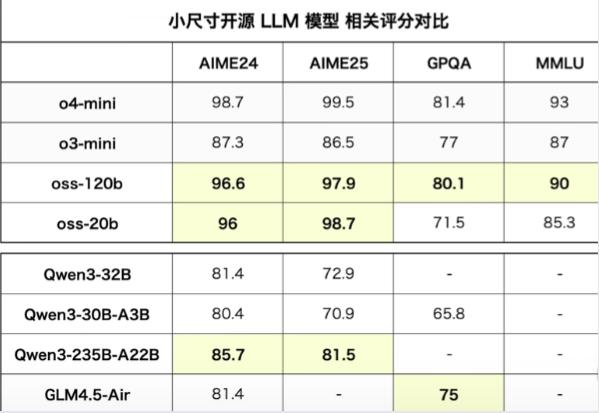
2.3 模型对比
在多个标准化测试中,gpt-oss系列的表现相当突出,尤其是在MMLU、GPQA、以及竞赛数学等领域。以下是gpt-oss-120b和gpt-oss-20b与gpt-o3和o4-mini的对比数据:
三、模型部署
参考文档:How to run gpt-oss with vLLM
1. 安装相关依赖
1.1 uv 安装
bash
# 安装vllm
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
# 启动服务器并下载模型
# For 20B
vllm serve openai/gpt-oss-20b
# For 120B
vllm serve openai/gpt-oss-120b1.2 conda 安装
bash
# 创建虚拟环境
conda create -n gpt_oss_vllm python=3.12
conda activate gpt_oss_vllm
# 安装vllm
# 安装 PyTorch-nightly 和 vLLM
pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128
# 安装 FlashInfer
pip install flashinfer-python==0.2.10
# 安装 evalscope(评测工具,可选)
pip install evalscope[perf] -U启动服务并下载模型
使用ModelScope下载模型(推荐):
bash
VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 VLLM_USE_MODELSCOPE=true vllm serve openai-mirror/gpt-oss-20b --served-model-name gpt-oss-20b --trust_remote_code --port 8801使用HuggingFace下载模型:
bash
VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1 vllm serve openai/gpt-oss-20b --served-model-name gpt-oss-20b --trust_remote_code --port 88011.3 Transformers 运行 gpt-oss
官方文档:https://cookbook.openai.com/articles/gpt-oss/run-transformers
四、模型调用示例
vLLM 公开了与聊天完成兼容的 API 和与**响应兼容的 API,**因此无需进行太多更改即可使用 OpenAI SDK。这是一个 Python 示例:
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"
)
result = client.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain what MXFP4 quantization is."}
]
)
print(result.choices[0].message.content)
response = client.responses.create(
model="openai/gpt-oss-120b",
instructions="You are a helfpul assistant.",
input="Explain what MXFP4 quantization is."
)
print(response.output_text)五、Debug
如果使用vllm部署模型时出现错误:AssertionError: Sinks are only supported in FlashAttention 3
解决方法:部署服务时添加:VLLM_ATTENTION_BACKEND=TRITON_ATTN_VLLM_V1
总结
OpenAI的gpt-oss系列模型凭借其强大的推理能力和广泛的应用场景,成为了开发者手中的有力工具。其开源特性、强大的定制能力和优化的推理性能,使其在AI开发和应用中具有巨大的潜力。随着AI技术的不断发展,gpt-oss系列无疑为更多的开发者提供了探索、创新和实现突破的可能。