✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。
🍎个人主页:Meteors.的博客
💞当前专栏:知识分享、知识备份
✨特色专栏: 知识分享
🥭本文内容:MyBatisPlus------入门到进阶
📚 ** ps ** : 阅读文章如果有问题或者疑惑,欢迎在评论区提问或指出。
目录
[01. 入门](#01. 入门)
[1. 添加依赖](#1. 添加依赖)
[2. Mapper继承BaseMapper接口](#2. Mapper继承BaseMapper接口)
[02. 常见注解](#02. 常见注解)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
[03. 常见配置](#03. 常见配置)
[03. 常见配置](#03. 常见配置)
[04. 核心功能-条件构造器](#04. 核心功能-条件构造器)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
[05. 核心功能-自定义SQL](#05. 核心功能-自定义SQL)
[1. 说明](#1. 说明)
[2. 步骤](#2. 步骤)
[a. 基于Wrapper构建where条件](#a. 基于Wrapper构建where条件)
[b. 在mapper方法中用Param注解声明wrapper变量名称,必须是ew](#b. 在mapper方法中用Param注解声明wrapper变量名称,必须是ew)
[06. 核心功能-Service接口](#06. 核心功能-Service接口)
[1. 说明](#1. 说明)
[2. 步骤](#2. 步骤)
[a. Service层继承IService接口](#a. Service层继承IService接口)
[b. Service实现类继承(Impl)继承ServiceImpl](#b. Service实现类继承(Impl)继承ServiceImpl)
[c. 调用方法(以save为例,更多例子点击这里)](#c. 调用方法(以save为例,更多例子点击这里))
[3. 补充](#3. 补充)
[07. 扩展功能-代码生成](#07. 扩展功能-代码生成)
方式二:使用MybatisX进行代码生成(这个会少一个controller)
方式三:使用应用商店的MybatisPlus插件进行代码生成
[08. 扩展功能-静态工具](#08. 扩展功能-静态工具)
[2. 例子](#2. 例子)
[09. 扩展功能-逻辑删除](#09. 扩展功能-逻辑删除)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
[3. 补充(引用自黑马视频)](#3. 补充(引用自黑马视频))
[10. 扩展功能-枚举处理器](#10. 扩展功能-枚举处理器)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
[11. 扩展功能-JSON处理器](#11. 扩展功能-JSON处理器)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
[12. 插件功能-分页插件](#12. 插件功能-分页插件)
[1. 说明](#1. 说明)
[2. 例子](#2. 例子)
01. 入门
1. 添加依赖
java
<!-- <dependency>-->
<!-- <groupId>org.mybatis.spring.boot</groupId>-->
<!-- <artifactId>mybatis-spring-boot-starter</artifactId>-->
<!-- <version>2.3.1</version>-->
<!-- </dependency>-->
<!-- MyBatisPlus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.6</version>
</dependency>2. Mapper继承BaseMapper接口
java
// 类似于
public interface UserMapper extend BaeMapper<User>{
}02. 常见注解
1. 说明
mp通过扫描实体类,并基于反射获取实体类信息作为数据库表信息,比较常用的注解如下:
- **@TableName:**指定表名
- @TableId: 用来指定表中的主键字段信息
- idType枚举说明:
- **ATUO:**数据库自增
- **INPUT:**通过set方法自行输入
- **ASSUGN_ID:**分配ID(接口IdentifierGenerator的方法nextId来生成id,默认实现类为DefaultIdentifierGenerator雪花算法)
- @TableField: 用来指定表中的普通字段信息
- 使用场景:
- 成员变量名宇数据库字段名不一致
- 成员变量名以is开头,且是布尔值
- 成员变量名宇数据库关键字冲突
- 成员变量不是数据库字段
2. 例子
java
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@TableName("tb_user")
public class User {
/**
* 用户id
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 用户名
*/
@TableField("`username`")
private String username;
/**
* 密码
*/
@TableField(exist = false)
private String password;
/**
* 注册手机号
*/
private String phone;
/**
* 详细信息
*/
private String info;
/**
* 使用状态(1正常 2冻结)
*/
private Integer status;
/**
* 账户余额
*/
private Integer balance;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
}03. 常见配置
03. 常见配置
java
mybatis-plus:
configuration:
# MyBatis 配置
map-underscore-to-camel-case: true
# 扫描包
global-config:
# 全局配置
db-config:
# 数据库配置
id-type: auto
# 包的位置
type-aliases-package: com.itmeteors.mp.domain.po04. 核心功能-条件构造器
1. 说明
mp为我们提供了的条件构造器方法,以便与我们进行查询操作:

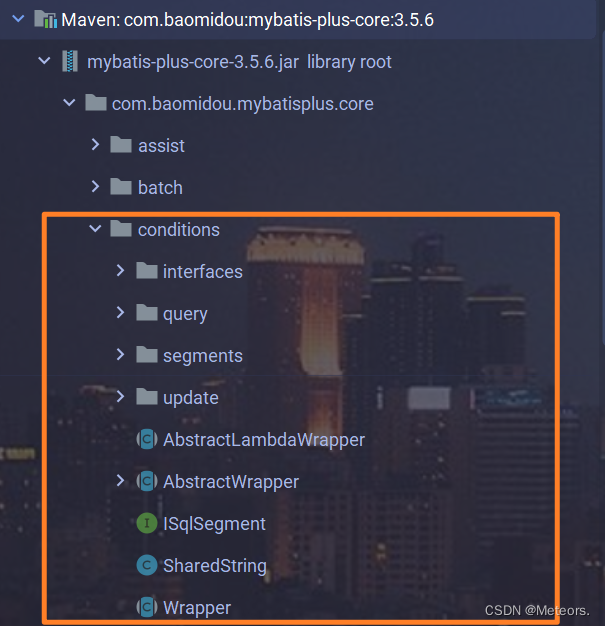
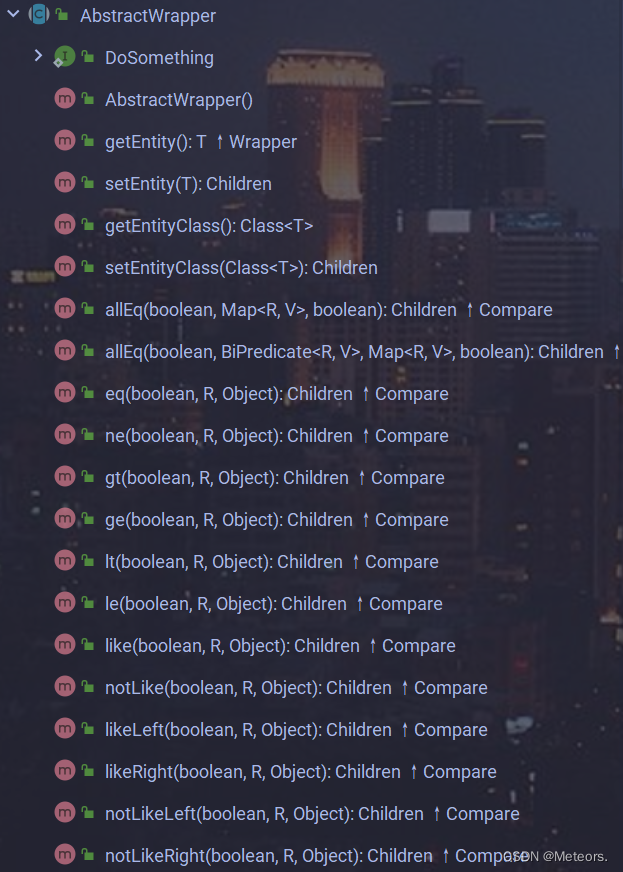
2. 例子
java
// 01. 查询出名字中带o的,存款大于1000元人的id、userName、info、balance
@Test
void testQueryWrapper(){
// 1. 构建查询条件
QueryWrapper<User> wrapper = new QueryWrapper<User>()
.select("id", "username", "info", "balance")
.like("username", "o")
.ge("balance", 1000);
// 2. 查询
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
// 02. 更新用户名为jack的用户的余额为2000
@Test
void testUpdateByQueryWrapper(){
// 1. 要更新的数据
User user = new User;
user.setBalance(2000);
// 2. 更新要的条件
QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "jack");
// 3. 执行更新
userMapper.update(user,wrapper);
}
// 03. 更新id为1,2,4的用户的余额,扣200
@Test
void testUpdateWrapper(){
List<Long> ids = List.of(1L,2L,4L);
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
.setSql("balance = balance - 200")
.in("id",ids);
userMapper.update(null,wrapper);
}
// 04. 使用lambada方式更新id为1,2,4的用户的余额,扣200
@Test
void testLambadaUpdateWrapper(){
List<Long> ids = List.of(1L,2L,4L);
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<User>()
.setSql("balance = balance - 200")
.in(User::getId,ids);
userMapper.update(null,wrapper);
}05. 核心功能-自定义SQL
1. 说明
利用mp来构建复杂的Where条件,然后自己定义SQL语句中剩下的部分。
2. 步骤
a. 基于Wrapper构建where条件
java
@Test
void testUpdateWrapper2(){
// 1. 更新条件
List<Long> ids = List.of(1L, 2L, 4L);
int amount = 200;
// 2. 定义条件
QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids);
// 3. 调用自定义SQL方法
userMapper.updateBalanceByIds(wrapper,amount);
}b. 在mapper方法中用Param注解声明wrapper变量名称,++必须是ew++
java
void updateBalanceByIds(@Param(Constants.WRAPPER) QueryWrapper<User> wrapper,@Param("amount") int amount);c.定义SQL,并使用Wrapper条件
java
<update id="updateBalanceByIds">
UPDATE tb_user SET balance = balance - #{amount} ${ew.customSqlSegment}
</update>06. 核心功能-Service接口
1. 说明
mp的service接口为我们定义了很多增删改查的方法,减少了在service层的代码书写量
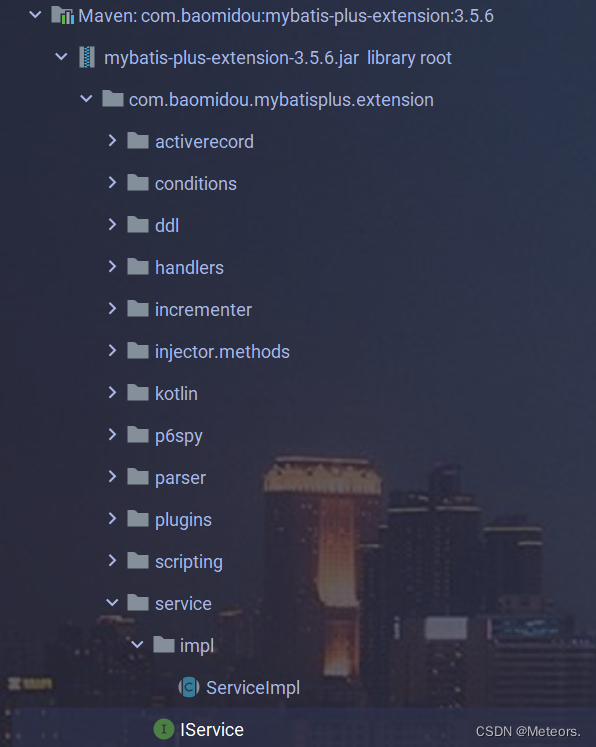
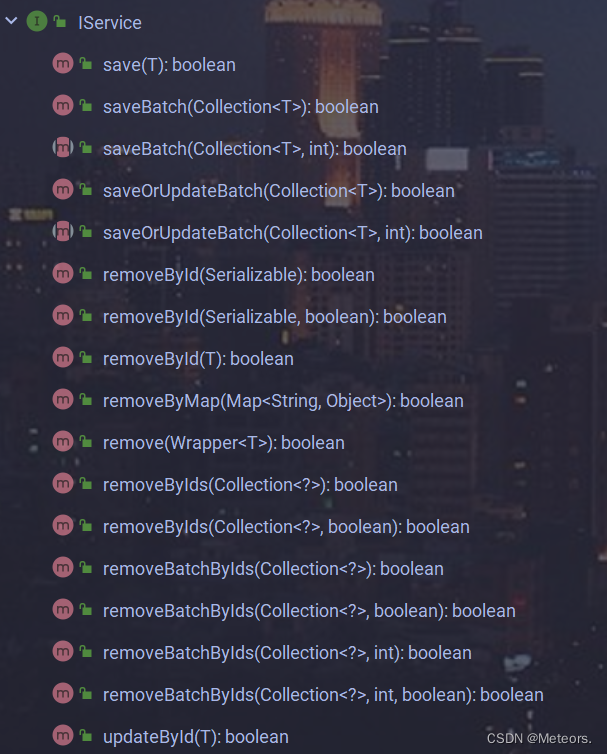
2. 步骤
a. Service层继承IService接口
java
public interface IUserService extends IService<User> {
}b. Service实现类继承(Impl)继承ServiceImpl
java
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
}c. 调用方法(以save为例,更多例子点击这里)
java
@SpringBootTest
class IUserServiceTest {
@Autowired
private IUserService userService;
@Test
void testSaveUser(){
User user = new User();
user.setUsername("tesst");
user.setPassword("123");
user.setPhone("15966666666");
user.setBalance(200);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(LocalDateTime.now());
userService.save(user);
}
}3. 补充
使用 saveBatch()方法默认不生效:
**原因:**虽然执行了批量插入方法,但是语句未被合并并优化,然后还是多个请求单独发送给MySQL服务器,网络往返次数和服务器解析SQL语句的开销未减少
解决方法: 在yml的数据库连接url最后加上: ++rewriteBatchedStatements=true,++允许驱动程序重写批处理语句为单个字符串,并发送给服务器,从而提高插入、更新和删除操作的速度。
当然,这样可能也会有缺点:
- SQL注入风险:因为语句被重写,所以可能会增加SQL注入的风险。务必确保你使用的SQL语句是安全的,避免直接拼接用户输入。
- 不支持所有SQL语法:某些复杂的SQL语法可能不支持重写。
- 调试困难:由于语句被重写,所以在调试时可能更难以确定问题所在。
07. 扩展功能-代码生成
方式一:使用代码生成器代码进行生成
步骤:
导入依赖
java<dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.5.6</version> </dependency>配置生成器类
javapublic class CodeGenerator { public static void main(String[] args) { FastAutoGenerator.create("jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true" , "root" , "****") .globalConfig(builder -> { builder.author("Meteors") // 设置作者 .enableSwagger() // 开启 swagger 模式 .outputDir("C:\\Users\\Meteors\\Desktop\\SpringCloud微服务---资料\\day01-MybatisPlus\\资料\\mp-demo\\src\\main\\java"); // 指定输出目录 }) .dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> { int typeCode = metaInfo.getJdbcType().TYPE_CODE; if (typeCode == Types.SMALLINT) { // 自定义类型转换 return DbColumnType.INTEGER; } return typeRegistry.getColumnType(metaInfo); }) ) .packageConfig(builder -> builder.parent("com.itheima.mp") // 设置父包名 .entity("domain.po") // 设置实体类包名 .pathInfo(Collections.singletonMap(OutputFile.xml , "C:\\Users\\Meteors\\Desktop\\SpringCloud微服务---资料\\day01-MybatisPlus\\资料\\mp-demo\\src\\main\\resources\\mapper")) // 设置mapperXml生成路径 ) .strategyConfig(builder -> builder.addInclude("address") // 设置需要生成的表名 .addTablePrefix("t_", "c_") // 设置过滤表前缀 .entityBuilder() .enableLombok() // 启用 Lombok .enableTableFieldAnnotation() // 启用字段注解 .controllerBuilder() .enableRestStyle() // 启用 REST 风格 ) .templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板 .execute(); } }运行代码


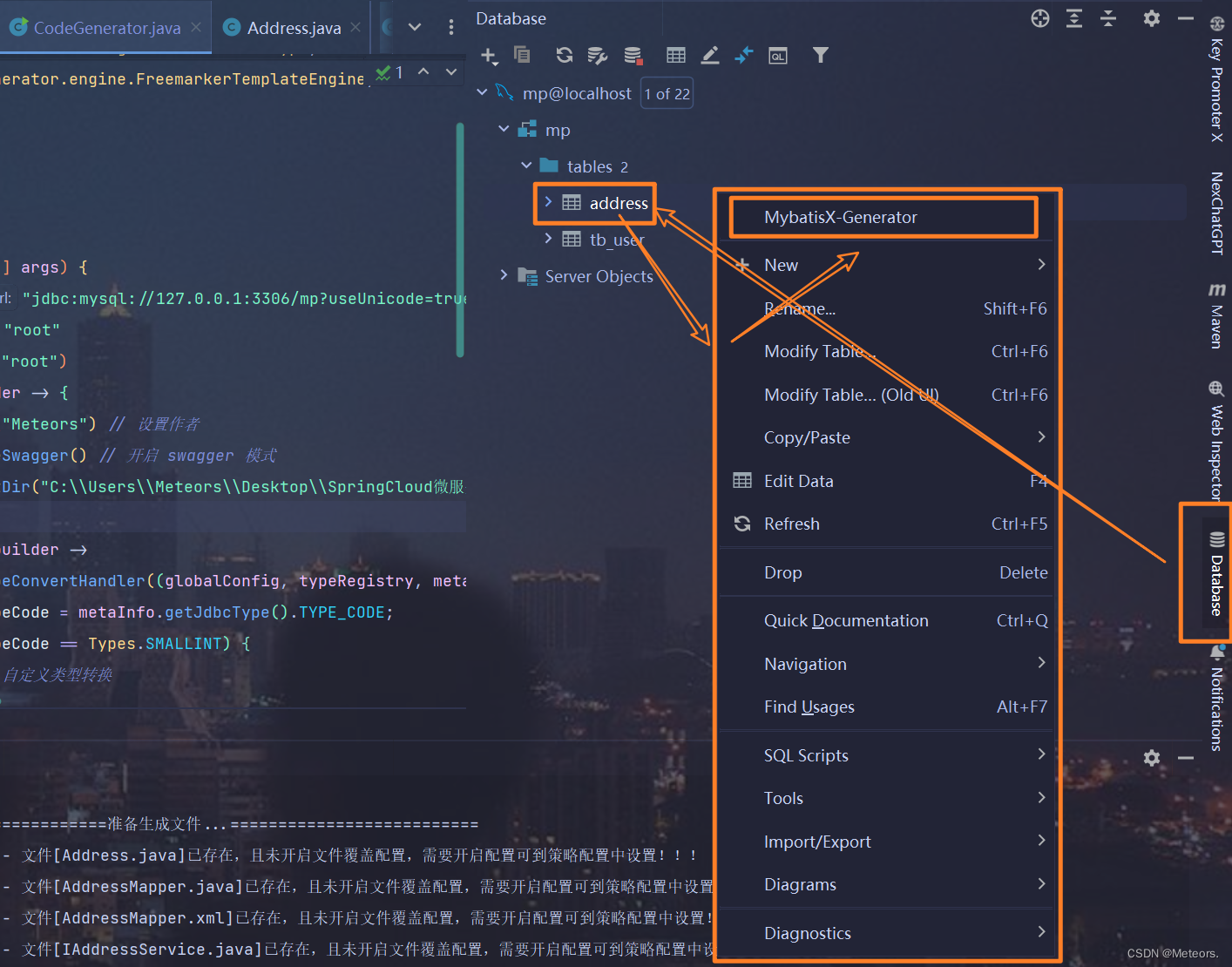
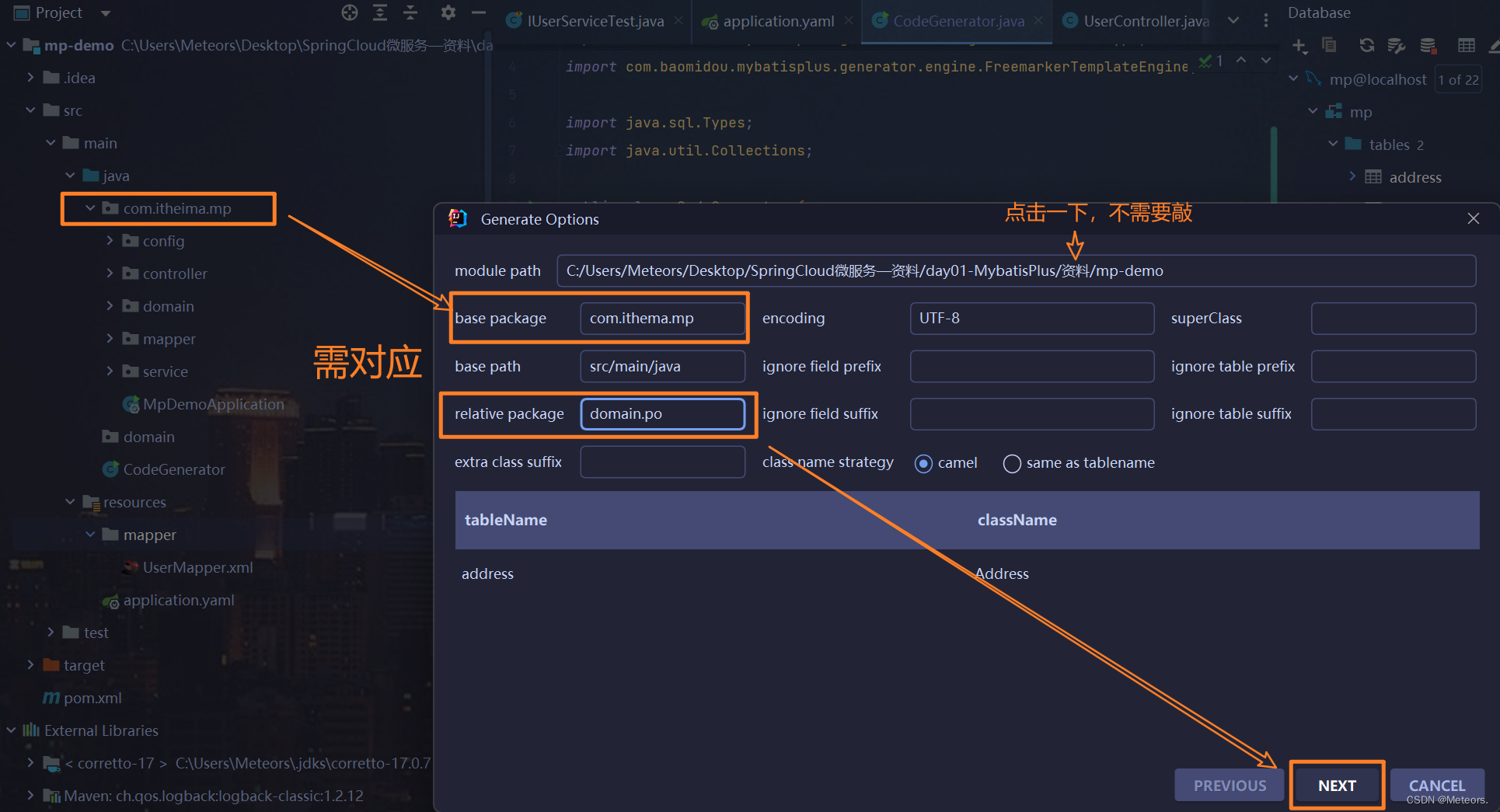
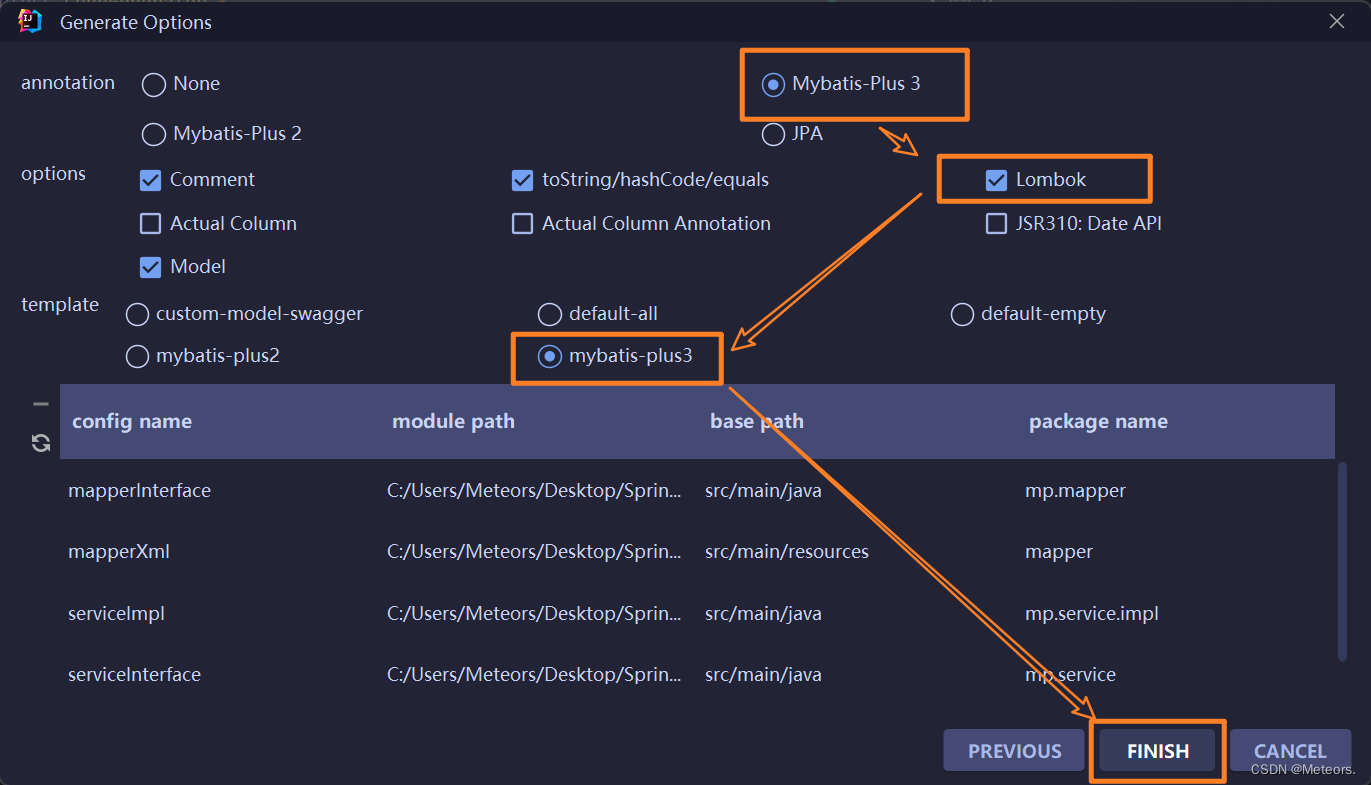
方式二:使用MybatisX进行代码生成(这个会少一个controller)
步骤:
- 选择MybatisX:
- 选择
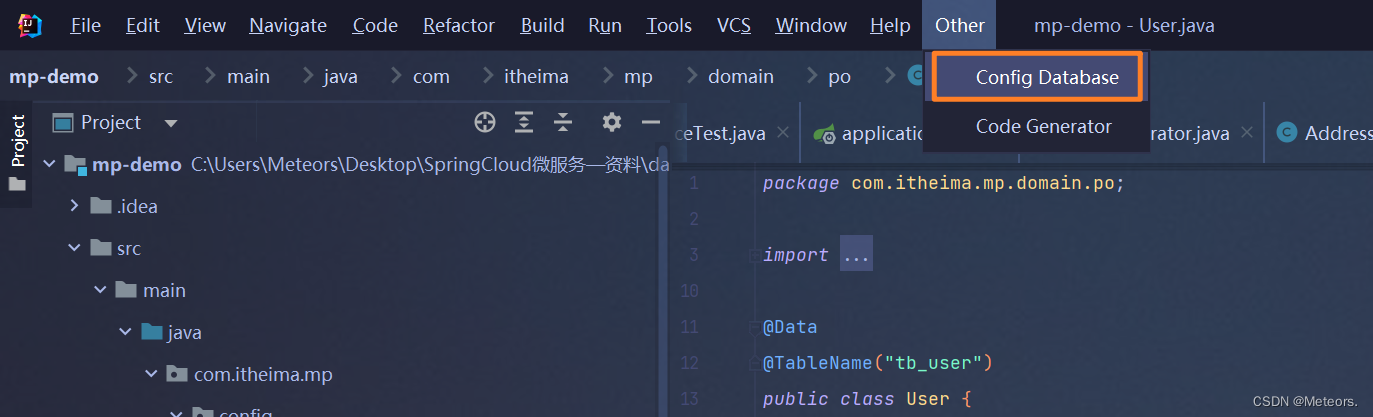
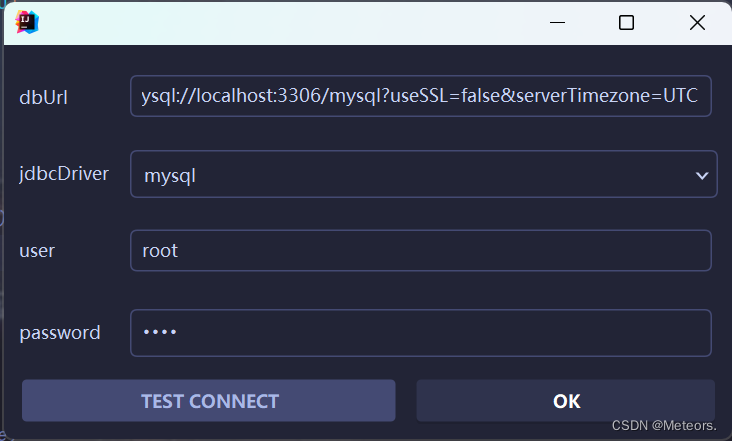
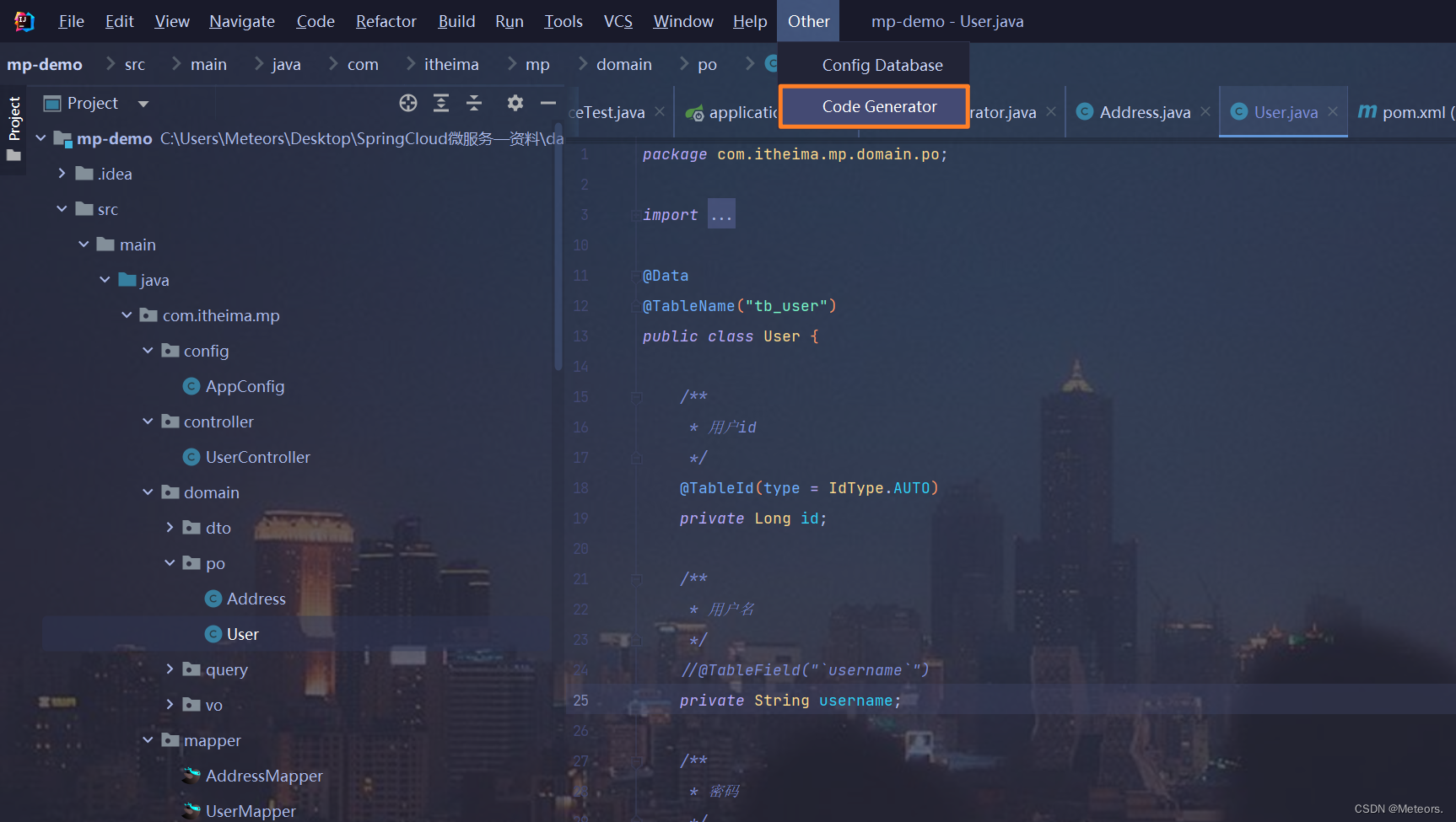
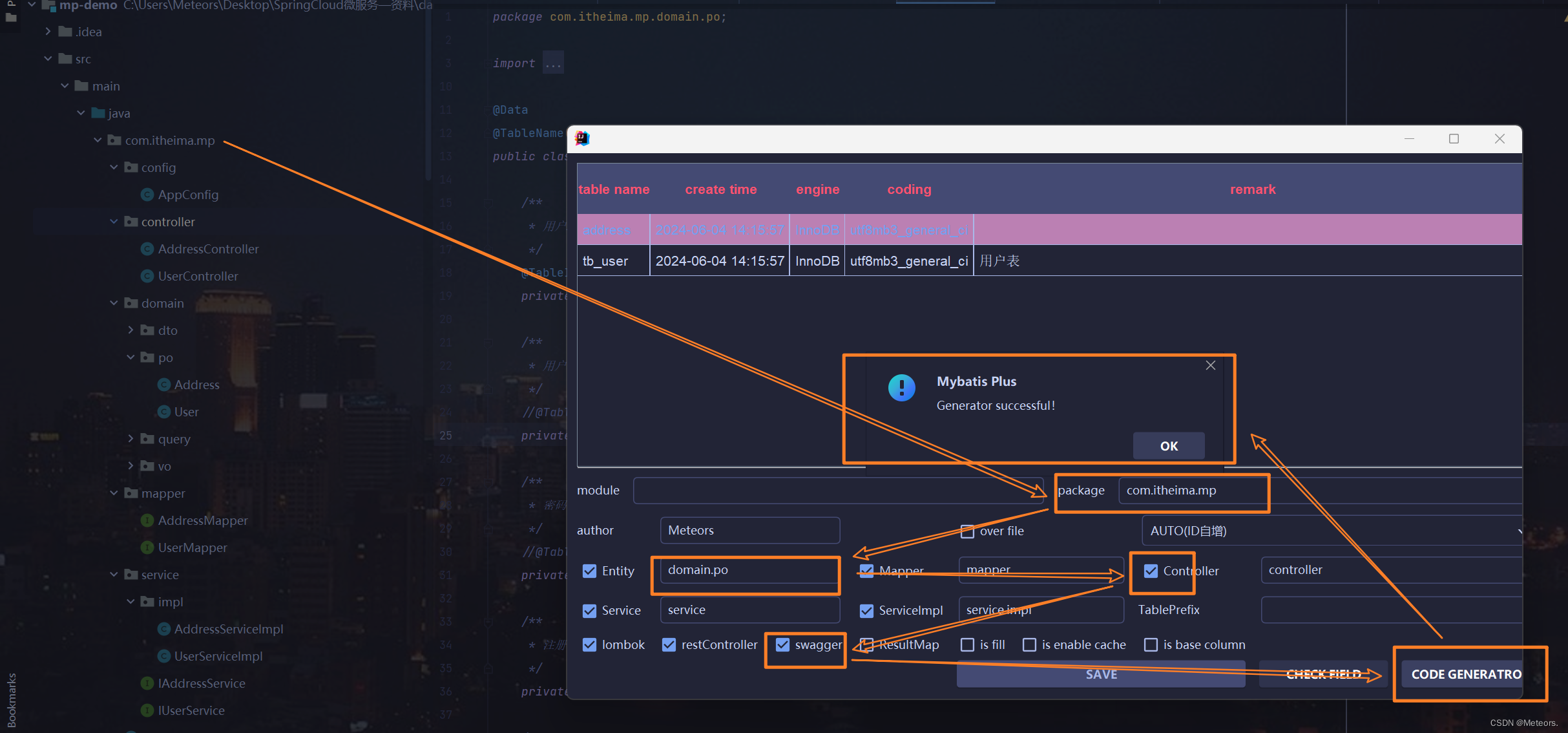
方式三:使用应用商店的MybatisPlus插件进行代码生成
步骤:
- 下载插件
- 重启idea,并配置数据库
- 进行代码生成

08. 扩展功能-静态工具
1.说明
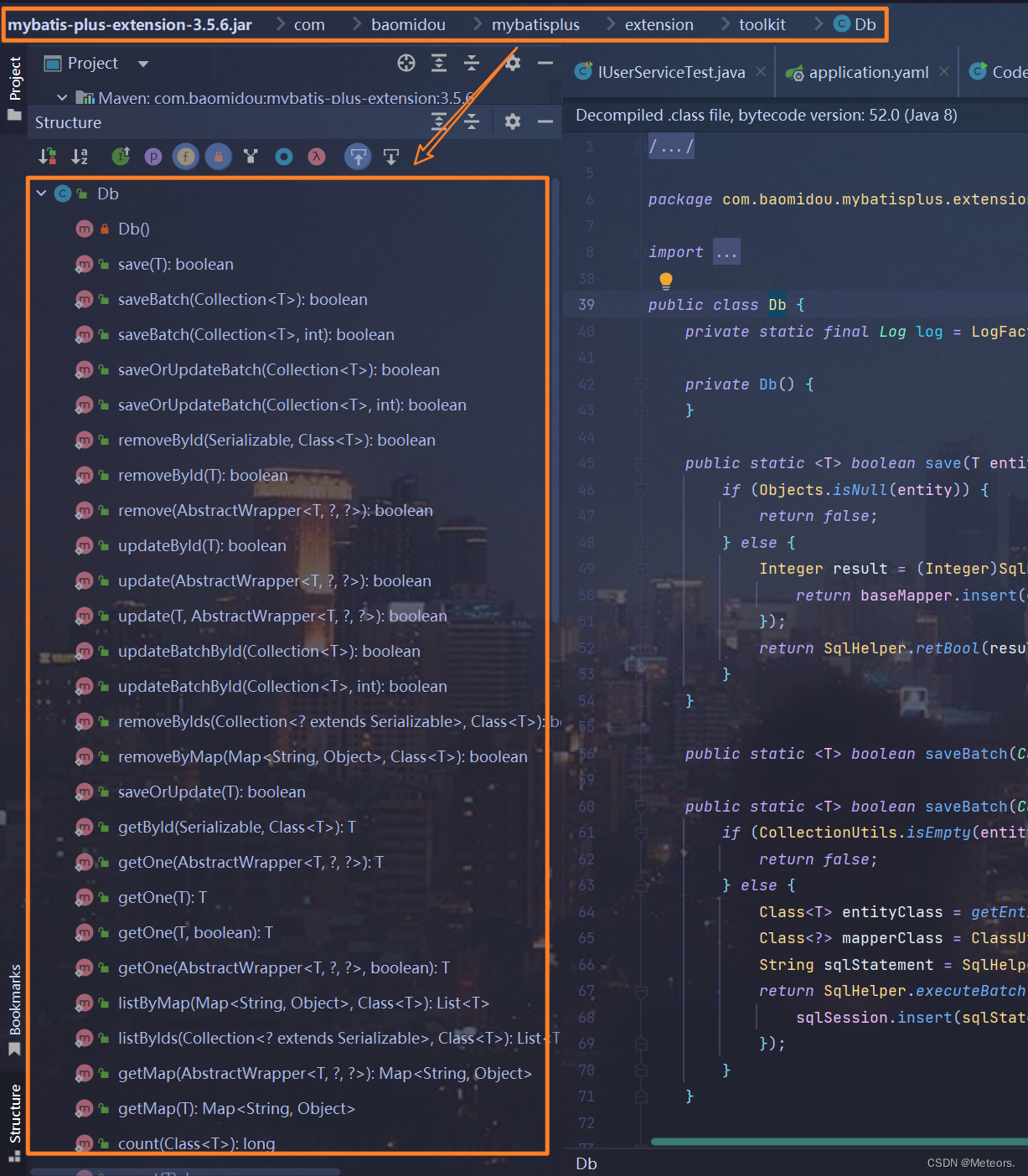
使用静态工具可以避免循环依赖问题。
2. 例子
需求++(如果普通方式进行实现,下面两个需求可能会造成循环依赖)++:
改造更具id查询用户的接口,查询用户的同时,查询出用户对应的所有地址
java//Controller @ApiOperation("根据id查询用户接口") @GetMapping("{id}") public UserVO queryUserById(@ApiParam("用户id") @PathVariable("id") Long id) { return userService.queryUserAndAddressById(id); } //Service UserVO queryUserAndAddressById(Long id); //Impl @Override public UserVO queryUserAndAddressById(Long id) { // 1. 查询用户 User user = getById(id); if (user == null || user.getStatus() == 2) { throw new RuntimeException("用户状态异常!"); } // 2. 查询地址 List<Address> addressList = Db.lambdaQuery(Address.class).eq(Address::getUserId, id).list(); // 3. 封装VO UserVO userVO = BeanUtil.copyProperties(user, UserVO.class); if (CollUtil.isNotEmpty(addressList)){ userVO.setAddresses(BeanUtil.copyToList(addressList, AddressVO.class)); } return userVO; }改造根据id批量查询用户的接口,查询用户的同时,查询出用户对应的所有地址
java// Controller @ApiOperation("根据id批量查询用户接口") @GetMapping public List<UserVO> queryUserByIds(@ApiParam("用户id集合") @RequestParam("ids") List<Long> ids) { return userService.queryUserAndAddressByIds(ids); } // Service List<UserVO> queryUserAndAddressByIds(List<Long> ids); // Impl @Override public List<UserVO> queryUserAndAddressByIds(List<Long> ids) { // 1. 查询用户 List<User> users = listByIds(ids); if (CollUtil.isEmpty(users)) { return Collections.emptyList(); } // 2. 查询地址 // 2.1 获取用户id集合 List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList()); // 2.2 根据用户id查询地址 List<Address> addresses = Db.lambdaQuery(Address.class).in(Address::getUserId, userIds).list(); // 2.3 转换地址VO List<AddressVO> addressVOList = BeanUtil.copyToList(addresses, AddressVO.class); // 2.4 用户地址集合分组处理,相同用户的放入一个集合(组)中 Map<Long, List<AddressVO>> addressMap = new HashMap<>(0); if (CollUtil.isNotEmpty(addressVOList)) { addressMap = addressVOList.stream().collect(Collectors.groupingBy(AddressVO::getUserId)); } // 3. 转换VO返回 List<UserVO> list = new ArrayList<>(users.size()); for (User user : users) { // 3.1 转换User的PO为VO UserVO vo = BeanUtil.copyProperties(user, UserVO.class); // 3.2 转换地址VO vo.setAddresses(addressMap.get(user.getId())); // 3.3 添加到集合 list.add(vo); } return list; }
09. 扩展功能-逻辑删除
1. 说明
逻辑删除解释基于代码逻辑模拟删除效果,但并不会真正删除数据。思路:
- 在表中添加一个字段标记数据是否被删除
- 当删除数据时把标记置为1
- 查询时值查询标记为0的数据
例如逻辑删除字段为deleted:
- 删除操作:UPDATE user SET deleted = 1 WHERE id = 1AND deleted = 0;
- 查询操作:SELECT * FROM user WHERE deleted = 0;
mp提供了逻辑删除功能,无需改变方法调用的方式,而是在底层帮我们自动修改CRUD的语句。我们要做的就是在application.yaml文件中配置逻辑删除的字段名称和值即可:
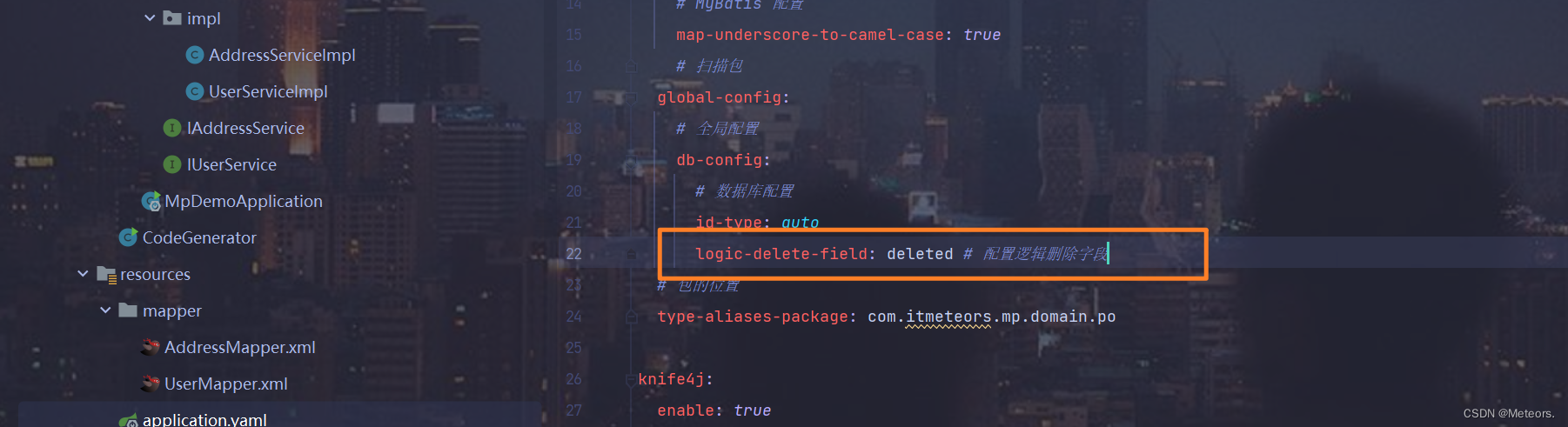
2. 例子
在使用mp的逻辑删除功能之后,原有的查询功能会默认在末尾添加查询条件,删除功能会自动变更为UPDATE,下面是具体的例子:
- 代码
java@SpringBootTest class IAddressServiceTest { @Autowired private IAddressService addressService; @Test void testLogicDelete(){ // 1. 删除 addressService.removeById(59L); // 2. 查询 Address address = addressService.getById(59L); System.out.println("address = " + address); } }
- 结果

3. 补充(引用自黑马视频)
逻辑删除本身也有自己的问题,比如:
- 会导致数据库表垃圾数据越来越多,影响查询效率
- SQL中全部需要对逻辑删除字段做判断,影响查询效率
因此,需要进行逻辑删除时,可以考虑把数据迁移到其它表的方法进行替代
10. 扩展功能-枚举处理器
1. 说明
用户状态字段如果用例如private Integer status的方式进行表示,用这种类型表示不直观且代码且属于硬编码,可维护性差、灵活性低、可扩展性差、可读性差、重用性受限、错误分险增加,而使用mp枚举处理器,可以避免这些缺点。
2. 例子
将原有的状态字段改为枚举类型:
-
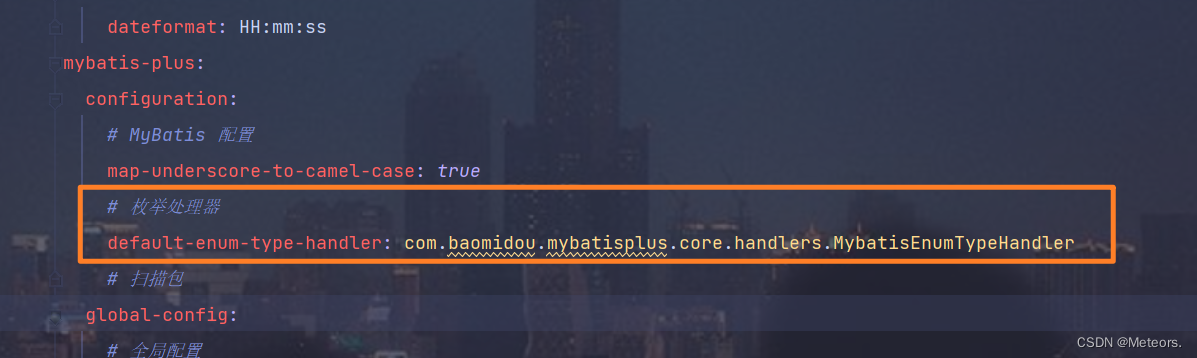
步骤1:在yaml文件中设置枚举处理器
-
步骤2:新建枚举类
java@Getter public enum UserStatus { NORMAL(1,"正常"), FROZEN(2,"冻结"), ; @EnumValue private final int value; @JsonValue private final String desc; UserStatus(int value, String desc) { this.value = value; this.desc = desc; } } -
步骤3:将字段类型替换为枚举类型
java/** * 使用状态(1正常 2冻结) */ private UserStatus status; -
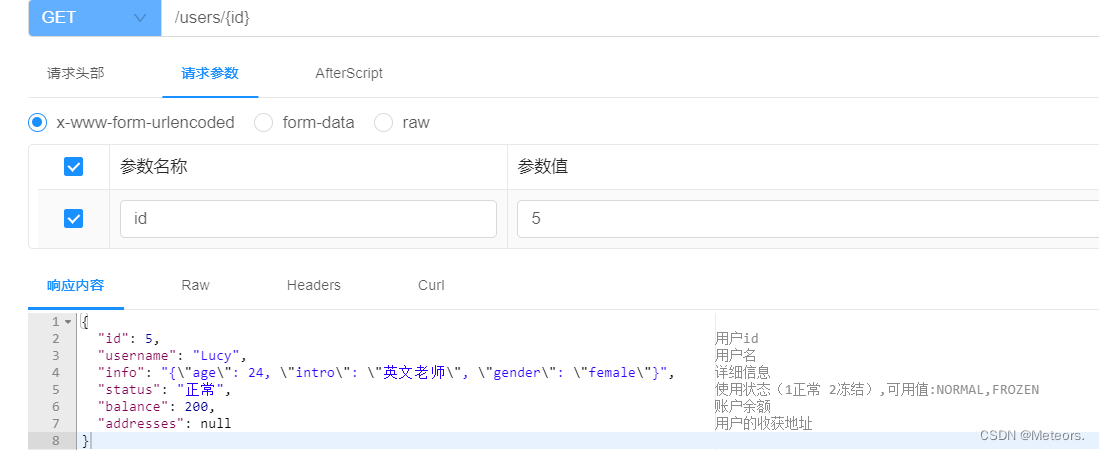
结果:
11. 扩展功能-JSON处理器
1. 说明
当数据中的表中含有json类型的字段时,如果自己实现Java代码实体类与之对应,比较麻烦,此时可以使用mp的json处理器进行实现,提高开发效率。
2. 例子
将一个数据库中使用json类型的info属性,使用 json处理让Java实体类与之对应,步骤:
-
新建那个属性的实体类
java@Data @NoArgsConstructor @AllArgsConstructor(staticName = "of") public class UserInfo { private Integer age; private String intro; private String gender; } -
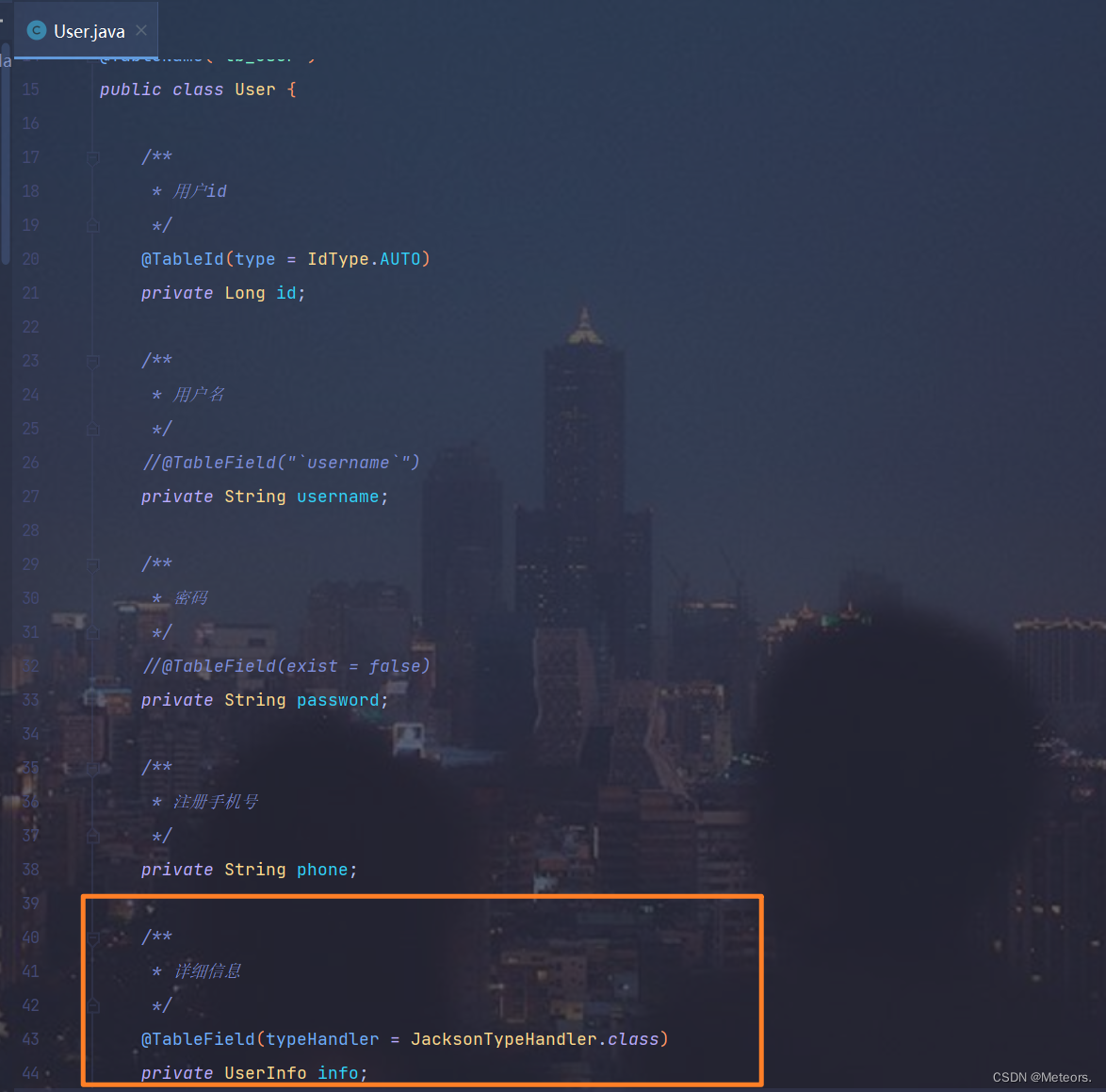
字段上定义处理器并在实体类上开启autoResultMap

ps:
- 赋值方式
java
//user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setInfo(UserInfo.of(24,"英语老师","female"));- 结果

12. 插件功能-分页插件
1. 说明
在mp3.4版本之后,mp已经默认集成了mp插件,但如果需要对分页的功能(例如溢出总页数后是否进行处理、单页条数限制、数据库类型设置、方言实现设置)等,仍需要新建分页插件进行实现。
2. 例子
以新建一个的分页插件和通过分页实体实现分页功能为例,步骤如下:
-
添加分页插件
javapackage com.itheima.mp.config; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MyBatisConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); // 1. 创建分页插件 PaginationInnerInterceptor paginationInnerInterceptor = new PaginationInnerInterceptor(DbType.MYSQL); paginationInnerInterceptor.setMaxLimit(1000L); // 2. 添加分页插件 interceptor.addInnerInterceptor(paginationInnerInterceptor); return interceptor; } } -
新建分页实体
java@Data public class PageQuery { private Integer pageNo; private Integer pageSize; private String sortBy; private Boolean isAsc; public <T> Page<T> toMpPage(OrderItem ... orders){ // 1.分页条件 Page<T> p = Page.of(pageNo, pageSize); // 2.排序条件 // 2.1.先看前端有没有传排序字段 if (sortBy != null) { p.addOrder(new OrderItem(sortBy, isAsc)); return p; } // 2.2.再看有没有手动指定排序字段 if(orders != null){ p.addOrder(orders); } return p; } public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){ return this.toMpPage(new OrderItem(defaultSortBy, isAsc)); } public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() { return toMpPage("create_time", false); } public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() { return toMpPage("update_time", false); } } -
新建分页返回实体
java@Data @NoArgsConstructor @AllArgsConstructor public class PageDTO<V> { private Long total; private Long pages; private List<V> list; /** * 返回空分页结果 * @param p MybatisPlus的分页结果 * @param <V> 目标VO类型 * @param <P> 原始PO类型 * @return VO的分页对象 */ public static <V, P> PageDTO<V> empty(Page<P> p){ return new PageDTO<>(p.getTotal(), p.getPages(), Collections.emptyList()); } /** * 将MybatisPlus分页结果转为 VO分页结果 * @param p MybatisPlus的分页结果 * @param voClass 目标VO类型的字节码 * @param <V> 目标VO类型 * @param <P> 原始PO类型 * @return VO的分页对象 */ public static <V, P> PageDTO<V> of(Page<P> p, Class<V> voClass) { // 1.非空校验 List<P> records = p.getRecords(); if (records == null || records.size() <= 0) { // 无数据,返回空结果 return empty(p); } // 2.数据转换 List<V> vos = BeanUtil.copyToList(records, voClass); // 3.封装返回 return new PageDTO<>(p.getTotal(), p.getPages(), vos); } /** * 将MybatisPlus分页结果转为 VO分页结果,允许用户自定义PO到VO的转换方式 * @param p MybatisPlus的分页结果 * @param convertor PO到VO的转换函数 * @param <V> 目标VO类型 * @param <P> 原始PO类型 * @return VO的分页对象 */ public static <V, P> PageDTO<V> of(Page<P> p, Function<P, V> convertor) { // 1.非空校验 List<P> records = p.getRecords(); if (records == null || records.size() <= 0) { // 无数据,返回空结果 return empty(p); } // 2.数据转换 List<V> vos = records.stream().map(convertor).collect(Collectors.toList()); // 3.封装返回 return new PageDTO<>(p.getTotal(), p.getPages(), vos); } } -
查询类继承分页实体类
java@EqualsAndHashCode(callSuper = true) @Data @ApiModel(description = "用户查询条件实体") public class UserQuery extends PageQuery{ @ApiModelProperty("用户名关键字") private String name; @ApiModelProperty("用户状态:1-正常,2-冻结") private Integer status; @ApiModelProperty("余额最小值") private Integer minBalance; @ApiModelProperty("余额最大值") private Integer maxBalance; } -
实现查询接口
java// Controller @ApiOperation("根据条件分页查询用户接口") @GetMapping("/page") public PageDTO<UserVO> queryUserPage(UserQuery query){ return userService.queryUsersPage(query); } // Service PageDTO<UserVO> queryUsersPage(UserQuery query); // Impl @Override public PageDTO<UserVO> queryUsersPage(UserQuery query) { String name = query.getName(); Integer status = query.getStatus(); // 1. 构建查询条件 // 1.1 分页条件 Page<User> page = query.toMpPageDefaultSortByUpdateTimeDesc(); // 2. 分页查询 Page<User> p = lambdaQuery() .like(name!=null,User::getUsername,name) .eq(status!=null,User::getStatus,status) .page(page); // 3. 封装VO结果 return PageDTO.of(p,user -> { // 1. 拷贝基础属性 UserVO vo = BeanUtil.copyProperties(user, UserVO.class); // 2. 处理特殊逻辑 vo.setUsername(vo.getUsername() +"**"); return vo; }); }
最后,
希望文章对你有所帮助!