文章目录
- [1. SVD奇异值分解](#1. SVD奇异值分解)
- [2. Eckart-Young](#2. Eckart-Young)
-
- [2.1 范数](#2.1 范数)
- [3. Q A = Q U Σ V T QA=QU\Sigma V^T QA=QUΣVT](#3. Q A = Q U Σ V T QA=QU\Sigma V^T QA=QUΣVT)
- [4. 主成分分析图像表示](#4. 主成分分析图像表示)
1. SVD奇异值分解
我们知道,对于任意矩阵A来说,我们可以将其通过SVD奇异值分解得到 A = U Σ V T A=U\Sigma V^T A=UΣVT,通过 Σ \Sigma Σ中可以看到只有r个非零的特征值,所以通过矩阵A奇异值分解可得如下表达式:
A = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ n u n v n T , σ 1 ≥ σ 2 ≥ ⋯ ≥ σ r \begin{equation} A=\sigma_1u_1v_1^T+\sigma_2u_2v_2^T+\cdots+\sigma_nu_nv_n^T,\sigma_1\geq \sigma_2\geq\cdots\geq\sigma_r \end{equation} A=σ1u1v1T+σ2u2v2T+⋯+σnunvnT,σ1≥σ2≥⋯≥σr
A k = σ 1 u 1 v 1 T + σ 2 u 2 v 2 T + ⋯ + σ k u k v k T , σ 1 ≥ σ 2 ≥ ⋯ ≥ σ k \begin{equation} A_k=\sigma_1u_1v_1^T+\sigma_2u_2v_2^T+\cdots+\sigma_ku_kv_k^T,\sigma_1\geq \sigma_2\geq\cdots\geq\sigma_k \end{equation} Ak=σ1u1v1T+σ2u2v2T+⋯+σkukvkT,σ1≥σ2≥⋯≥σk
A ∼ A k \begin{equation} A\sim A_k \end{equation} A∼Ak
- 上面的等式里面,我们希望通过前面k项的和来近似矩阵A,这就是
主成分分析PCA
2. Eckart-Young
如果矩阵B的秩为 k ,对于矩阵A和B的距离来说,矩阵A与子矩阵 A k A_k Ak(秩为k)的距离小于等于矩阵A与矩阵B之间的距离

- 假设我们有如下矩阵
A = 4 0 0 0 0 3 0 0 0 0 2 0 0 0 0 1 ; A 2 = 4 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 ; B = 3.5 3.5 0 0 3.5 3.5 0 0 0 0 1.5 1.5 0 0 1.5 1.5 \begin{equation} A=\begin{bmatrix} 4&0&0&0\\\\ 0&3&0&0\\\\ 0&0&2&0\\\\ 0&0&0&1 \end{bmatrix};A_2=\begin{bmatrix} 4&0&0&0\\\\ 0&3&0&0\\\\ 0&0&0&0\\\\ 0&0&0&0 \end{bmatrix};B=\begin{bmatrix} 3.5&3.5&0&0\\\\ 3.5&3.5&0&0\\\\ 0&0&1.5&1.5\\\\ 0&0&1.5&1.5 \end{bmatrix} \end{equation} A= 4000030000200001 ;A2= 4000030000000000 ;B= 3.53.5003.53.500001.51.5001.51.5 - 用python计算 ∣ ∣ A − B ∣ ∣ ≥ ∣ ∣ A − A k ∣ ∣ ||A-B||\geq ||A-A_k|| ∣∣A−B∣∣≥∣∣A−Ak∣∣
python
import numpy as np
if __name__=="__main__":
A=np.array([ [4,0,0,0],
[0,3,0,0],
[0,0,2,0],
[0,0,0,1]],dtype='int16')
A2=np.array([ [4,0,0,0],
[0,3,0,0],
[0,0,0,0],
[0,0,0,0]],dtype='int16')
B=np.array([ [3.5,3.5,0,0],
[3.5,3.5,0,0],
[0,0,1.5,1.5],
[0,0,1.5,1.5]],dtype='int16')
Aa2norm =A-A2
AB2norm =A-B
print(f"A={A}")
print(f"A2={A2}")
print(f"B={B}")
print(f"Aa2norm={np.linalg.norm(Aa2norm,ord=2)}")
print(f"AB2norm={np.linalg.norm(AB2norm,ord=2)}")
#A=[[4 0 0 0]
# [0 3 0 0]
# [0 0 2 0]
# [0 0 0 1]]
#A2=[[4 0 0 0]
# [0 3 0 0]
# [0 0 0 0]
# [0 0 0 0]]
#B=[[3 3 0 0]
# [3 3 0 0]
# [0 0 1 1]
# [0 0 1 1]]
#Aa2norm=2.0
#AB2norm=3.54138126514911- 结果: ∣ ∣ A − B ∣ ∣ 2 = 3.54 , ∣ ∣ A − A 2 ∣ ∣ = 2.0 → ∣ ∣ A − B ∣ ∣ ≥ ∣ ∣ A − A 2 ∣ ∣ ||A-B||_2=3.54,||A-A_2||=2.0\rightarrow ||A-B||\geq||A-A_2|| ∣∣A−B∣∣2=3.54,∣∣A−A2∣∣=2.0→∣∣A−B∣∣≥∣∣A−A2∣∣
- 向量x乘以正交单位矩阵Q后长度不变,正交矩阵相当于将向量旋转,所以长度不变。
∣ ∣ x ∣ ∣ 2 = x T x = x T Q T Q x = ( Q x ) T Q x = ∣ ∣ Q x ∣ ∣ 2 \begin{equation} ||x||_2=x^Tx=x^TQ^TQx=(Qx)^TQx=||Qx||_2 \end{equation} ∣∣x∣∣2=xTx=xTQTQx=(Qx)TQx=∣∣Qx∣∣2
这就是主成分分析的原理,因为矩阵A里面有很多无用信息,用 A k A_k Ak 来代替 A
2.1 范数
-
向量 L 1 L_1 L1范数
∣ ∣ V ∣ ∣ 1 = ∣ v 1 ∣ + ∣ v 2 ∣ + ⋯ + ∣ v n ∣ \begin{equation} ||V||_1=|v_1|+|v_2|+\cdots+|v_n| \end{equation} ∣∣V∣∣1=∣v1∣+∣v2∣+⋯+∣vn∣ -
向量 L 2 L_2 L2范数
∣ ∣ V ∣ ∣ 2 = v 1 2 + v 2 2 + ⋯ + v n 2 \begin{equation} ||V||_2=\sqrt{v_1^2+v_2^2+\cdots+v_n^2} \end{equation} ∣∣V∣∣2=v12+v22+⋯+vn2 -
向量 L ∞ L_{\infty} L∞范数
∣ ∣ V ∣ ∣ ∞ = m a x ∣ v i ∣ \begin{equation} ||V||_{\infty}=\mathrm{max}|v_i| \end{equation} ∣∣V∣∣∞=max∣vi∣ -
我们假设在二维平面上,我们就三个范数进行图形形象表达:


-
小结,随着范数越大,图形由原来的菱形膨胀到了正方形,这个正方形就是极限了。这个思路真神奇!!!
-
L 1 L_1 L1函数范数跟向量 L 1 L_1 L1范数一样,通过 L 1 L_1 L1函数可以知道一个函数在指定区间内的体量 L 1 L_1 L1函数范数
L = ∑ i = 1 n ∣ y i − f ( x i ) ∣ \begin{equation} L=\sum_{i=1}^n|y_i-f(x_i)| \end{equation} L=i=1∑n∣yi−f(xi)∣ -
L 2 L_2 L2函数范数
L 2 L_2 L2损失函数表示测量和真实值之差的平方,就是我们之前一直用的最小二乘法。真神奇,居然都对上了,同一个问题,不同的角度。
L = ∑ i = 1 n ( y i − f ( x i ) ) 2 \begin{equation} L=\sum_{i=1}^n(y_i-f(x_i))^2 \end{equation} L=i=1∑n(yi−f(xi))2矩阵 L 1 L_1 L1范数定义为每一列元素绝对值之和的最大值。具体步骤是:
-
对矩阵A的每一列,求每个元素的绝对值之和
-
找出所有列和中最大值
-
-
L 2 L_2 L2矩阵范数定义为矩阵A的最大奇异值,计算步骤:
-
计算矩阵A的共轭转置,记为 A H A^H AH,得到 A H A , A A H A^HA,AA^H AHA,AAH
-
计算矩阵 A A H , A H A AA^H,A^HA AAH,AHA的特征值,求出平方根后求得最大特征值为 L 2 L_2 L2范数
-
-
Frobenius-norm
∣ ∣ A ∣ ∣ F = σ 1 2 + σ 2 2 + ⋯ + σ r 2 \begin{equation} ||A||_F=\sqrt{\sigma_1^2+\sigma_2^2+\cdots+\sigma_r^2} \end{equation} ∣∣A∣∣F=σ12+σ22+⋯+σr2 -
Nuclear-norm
∣ ∣ A ∣ ∣ N = σ 1 + σ 2 + ⋯ + σ r \begin{equation} ||A||_N=\sigma_1+\sigma_2+\cdots+\sigma_r \end{equation} ∣∣A∣∣N=σ1+σ2+⋯+σr
3. Q A = Q U Σ V T QA=QU\Sigma V^T QA=QUΣVT
对于矩阵A来说,我们可以左乘以一个正交单位矩阵A,其特征值不变
Q A = ( Q U ) Σ V T \begin{equation} QA=(QU)\Sigma V^T \end{equation} QA=(QU)ΣVT
4. 主成分分析图像表示
我们来看看最小二乘法的图像,通过求y方向的最小值和来拟合曲线
L = ∑ i = 1 n ∣ y i − f ( x i ) ∣ → A T A x ^ = A T b → x ^ = ( A T A ) − 1 A T b \begin{equation} L=\sum_{i=1}^n|y_i-f(x_i)|\rightarrow A^TA\hat{x}=A^Tb\rightarrow \hat{x}=(A^TA)^{-1}A^Tb \end{equation} L=i=1∑n∣yi−f(xi)∣→ATAx^=ATb→x^=(ATA)−1ATb
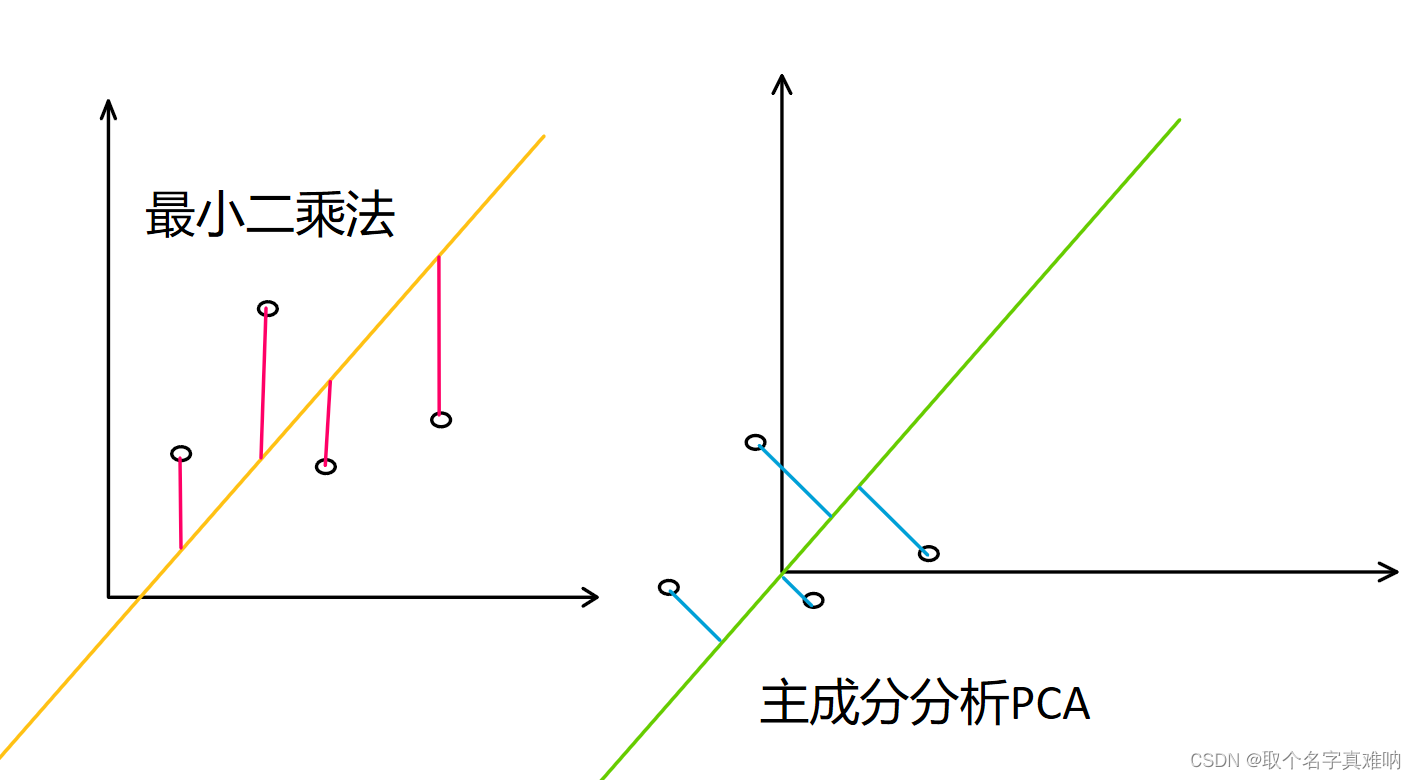
- 主成分分析PCA 是通过先减去样本的均值后,根据点到直线的垂直距离来拟合直线。