学习信息表示对于组织病理学图像的分类和预测任务至关重要。由于图像大小巨大,通常使用多实例学习(MIL)方案来处理整张组织病理学图像(whole-slide histopathological image)。然而,MIL的弱监督性质导致了学习有效的whole-slide-level表示的挑战。为了解决这个问题,作者提出了一种基于可变形Transformer(DT)架构和卷积层的新型MIL模型,称为DT-MIL。DT架构使MIL模型能够通过同时全局聚合bag中的实例特征并在bag表示学习期间编码实例的位置上下文信息来更新每个实例特征。与其他最先进的MIL模型相比,DT-MIL具有以下优点:(1)以完全可训练的方式生成bag表示,(2)用所有实例的高级非线性组合来表示bag,而不是基于fixed pooling的方法(如最大池化和平均池化)或简单的基于注意力的线性聚合,以及(3)在bag嵌入阶段对位置关系和上下文信息进行编码。除了提出的DT-MIL,作者还开发了其他可能的基于Transformer的MIL进行比较。大量实验表明,DT-MIL在组织病理学图像分类和预测任务中优于最先进的方法和其他基于Transformer的MIL架构。
来自:DT-MIL: Deformable Transformer for Multi-instance Learning on Histopathological Image, MICCAI 2021
目录
背景概述
组织病理学图像分析在现代医学中起着至关重要的作用,尤其是在癌症治疗中,它已被用作诊断的金标准。随着扫描仪的发展,这些图像可以数字化为whole slide image(WSI),这为计算机辅助分析铺平了道路。由于WSI的巨大规模,组织病理学图像的分析通常形式化为多实例学习(MIL)任务,其中WSI被视为一个bag,并被拼接成数百或数千个patch,这些patch被视为实例。随着人工智能(AI)在组织病理学图像分析中的应用不断深入,它已逐渐进入转移预测和疾病预后等应用,我们需要全面考虑整个WSI上的肿瘤微环境,包括成纤维细胞、免疫细胞和血管等。
现有的MIL方法由三个主要范式组成:袋空间-bag space(BS)、实例空间-instance space(IS)和嵌入空间-embedded space(ES)MIL。BS范式将每个bag视为一个单独的实体(entity),并利用bag-to-bag的距离进行分类,由于图像大小巨大,这在组织病理学图像分析中并不常见。在IS范式中,学习过程主要在实例级别,而bag级别的预测是通过简单地聚合instance预测来获得的。IS范式方法通常是两阶段方法,通常表现出不如其他范式的性能。另一方面,ES范式首先将所有实例嵌入到低维表示中,然后将它们集成以生成bag级表示,这有可能全面嵌入整个WSI的信息,用于处理特定的分析任务。因此,设计一个有效的embedding模块是提高ES MIL方法性能的关键。
bag embedding的第一次尝试是基于fixed pooling的方法,如最大池化、平均池化,或基于参数化池化的方式,如动态池化和自适应池化。这些方法要么是固定的,要么是部分可训练的,灵活性有限。后来,注意力机制被引入MIL的bag embedding中,这是完全可训练的。Shi等人通过将注意力机制与损失函数连接起来,并添加特定的规则来提高注意力机制的分配权重,进一步改进了基于注意力的MIL。然而,这些基于单一注意力的方法将bag作为实例特征的加权和,这只是线性组合。
此外,上述所有方法都未能对WSI(bag)中的patch(instance)的位置和上下文信息进行编码。Campanella等人采用递归神经网络(RNN)作为bag embedding模块,并在bag表示学习过程中将提取的patch特征视为一维序列,对位置和上下文信息进行编码。然而,一维sequence不能完全表示WSI内patch的2D位置,并且RNN模型顺序而不是并行地处理instance嵌入。此外,RNN捕获远程信息的能力有限。作为最先进的seq2seq体系结构之一,Transformer正在自然语言处理任务中迅速取代RNN。Transformer中的自注意力层允许它通过同时聚合序列中的所有元素来更新序列中的每个元素,并且位置编码过程允许模型利用位置信息。
在这项工作中,作者首次将Transformer引入组织病理学图像分析。提出了一种新的ES范式下的模型,该模型使用可变形Transformer编码器-解码器和卷积层来构建用于生成高级表示的完全可训练的bag embedding模块。
方法
DT-MIL的框架如图1所示。它由三个主要组成部分组成,包括位置保持降维(PPDR)、基于Transformer的bag嵌入(TBBE)和分类(classification)。在PPDR组件中,涉及卷积神经网络(CNN)编码器来将WSI下采样为小特征图像(small feature image),其中原始WSI中的每个patch被嵌入为位于相应位置的超像素(提取的实例级特征)。然后是bag嵌入模块,它由一个用于自动实例级特征选择的1×1卷积层和一个用于生成高级bag表示的可变形Transformer编码器-解码器组成,该高级bag表示全面包含所有实例特征以及对应的2D位置信息。Transformer中的自注意力机制在bag嵌入过程中为不同的实例特征分配权重,实现自适应的实例选择。可变形Transformer编码器中的可变形注意力模块可以进一步降低模型复杂性,并允许bag嵌入模块更多地关注关键实例。最后,在获得信息丰富的高级bag表示后,跟随分类头进行最终预测。
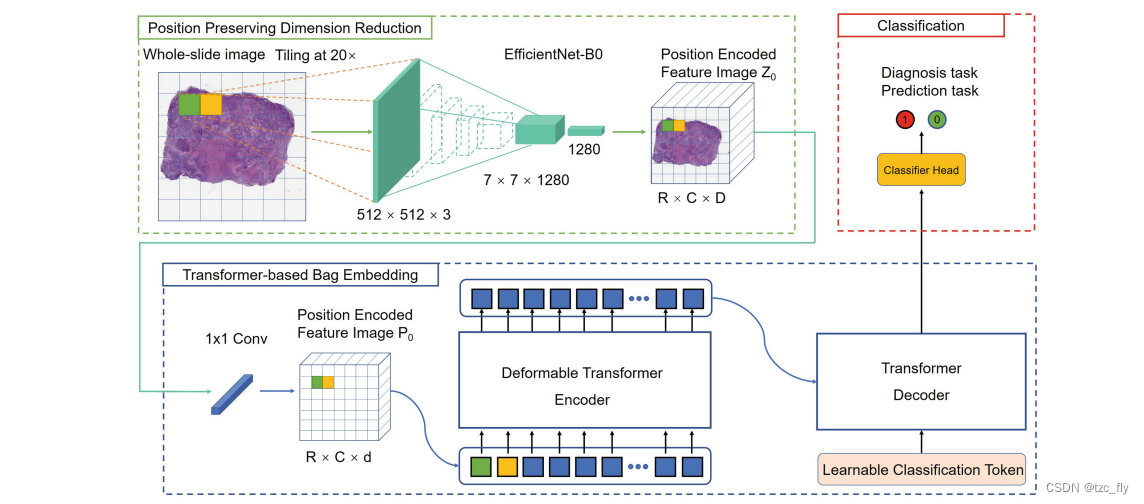
- 图1:概述了所提出的可变形Transformer多实例学习模型(DT-MIL),该模型由三部分组成,即位置保持降维(PPDR)、基于Transformer的bag嵌入(TBBE)和分类。分类token类似于BERT中的classtoken,它是一种可学习的嵌入,用于执行分类。
WSI降维和实例级特征选择
要处理千兆像素的WSI,DT-MIL的第一步是缩小其规模。为此,使用预先训练的EfficientNet B0(在ImageNet上)从WSI内的感兴趣区域(ROI,如果有的话)的patch中提取特征。这些特征被视为超像素,然后缝合在一起形成带位置编码的特征图像。具体的,假设来自WSI I I I的patches是 { x 1 , x 2 , . . . , x N } \left\{x_{1},x_{2},...,x_{N}\right\} {x1,x2,...,xN},其中 x i ∈ R W × H × 3 x_{i}\in R^{W\times H\times 3} xi∈RW×H×3, W W W和 H H H为patch的width和height。对应的embedded特征记为 { e 1 , e 2 , . . . , e N } \left\{e_{1},e_{2},...,e_{N}\right\} {e1,e2,...,eN},其中 e i ∈ R D e_{i}\in R^{D} ei∈RD。假设WSI由 R R R行和 C C C列的patches组成,那么缩小的位置编码特征图像表示为 Z 0 ∈ R R × C × D Z_{0}\in R^{R\times C\times D} Z0∈RR×C×D。然后,一个1×1的卷积用于实例级特征选择,将位置编码特征图像的通道维数从 D D D降低到更小的维数 d d d,生成新的位置编码特征图 P 0 ∈ R R × C × d P_0∈R^{R×C×d} P0∈RR×C×d( W , H = 512 W,H=512 W,H=512, D = 1280 , d = 512 D=1280,d=512 D=1280,d=512)。
可变形Transformer Encoder
bag嵌入模块中的可变形Transformer编码器用于通过同时全局聚合 P 0 P_0 P0中的实例表示并参考位置上下文信息来更新每个实例的表示。编码器是重复块的堆叠,其中每个块由多头可变形自注意模块(MDSA)和前馈网络(FFN)以及残差连接和层归一化(LN)组成,即: E B ( P i ) = L N ( H + F F N ( H ) ) H = L N ( P i − 1 + M D S A ( P i − 1 ) ) EB(P_{i})=LN(H+FFN(H))\\ H=LN(P_{i-1}+MDSA(P_{i-1})) EB(Pi)=LN(H+FFN(H))H=LN(Pi−1+MDSA(Pi−1))其中, P i P_{i} Pi是第 i i i个encoder block的feature maps。与transformer中的传统自注意模型不同,该模型在更新其中一个实例时全局聚合所有实例表示,可变形自注意模块只关注一小部分关键实例。给定一个输入 P i ∈ R R × C × d P_{i}\in R^{R\times C\times d} Pi∈RR×C×d,令 q q q索引一个query元素 f q f_{q} fq和2D参考点 r q r_{q} rq,MDSA被定义为: M D S A ( f q , r q , P i ) = ∑ m = 1 M W m ∑ k = 1 K A m q k ⋅ W m ′ P i ( r q + Δ r m q k ) MDSA(f_{q},r_{q},P_{i})=\sum_{m=1}^{M}W_{m}\\sum_{k=1}\^{K}A_{mqk}\\cdot W'_{m}P_{i}(r_{q}+\\Delta r_{mqk}) MDSA(fq,rq,Pi)=m=1∑MWmk=1∑KAmqk⋅Wm′Pi(rq+Δrmqk)其中 m m m对注意力head进行索引, k k k对采样的keys进行索引, K K K是所有采样keys的总数( K < R C K<RC K<RC)。 W m ′ ∈ R C v × d W'{m}\in R^{C{v}\times d} Wm′∈RCv×d和 W m ∈ R C v × d W_{m}\in R^{C_{v}\times d} Wm∈RCv×d,其中 C v = d / M C_{v}=d/M Cv=d/M是可学习的权重。 A m q k ∈ ( 0 , 1 ) A_{mqk}\in(0,1) Amqk∈(0,1)以及 Δ r m q k ∈ R 2 \Delta r_{mqk}\in R^{2} Δrmqk∈R2表示第 m m m个注意力头的第 k k k个采样点的attention weight和sampling offset。
在Transformer编码器中,位置信息嵌入了位置编码模块。在这里,作者将Transformer中的原始模块扩展到2D情况。对于每个维度的坐标,作者分别使用sin和cos函数。
解码器
在解码器部分,作者遵循Transformer的标准架构。解码器由具有级联的多头自注意力、FFN层以及残差连接和层归一化的重复块组成。与使用六个块作为解码器的原始Transformer不同,这里使用两个block来进一步降低模型的复杂性。为了进行分类,作者设置了一个可学习的嵌入作为cls token。解码器中的注意力机制是经典的key-value attention: A t t ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Att(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Att(Q,K,V)=softmax(dk QKT)V在多头自注意力中, V = K = Q V=K=Q V=K=Q,在多头编码器-解码器注意力中, K = V K=V K=V为encoder的输出,而 Q Q Q是decoder的输出。
分类头
分类头将bag级嵌入映射到最终预测,该预测由具有一个隐藏层的多层感知器(MLP)实现。
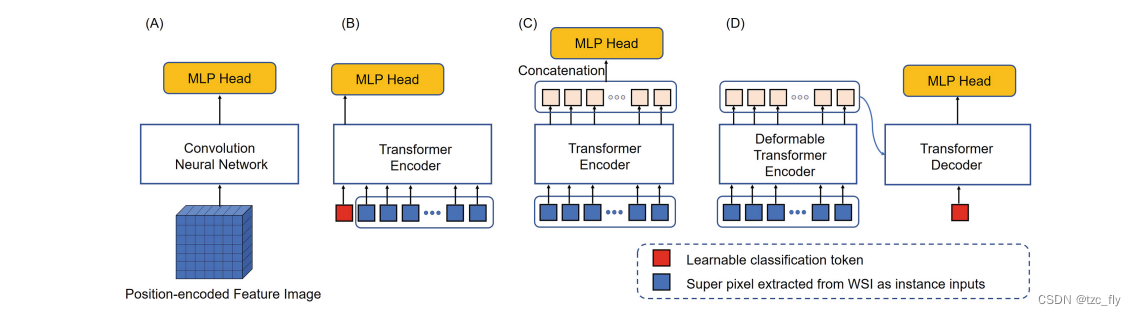
除了提出的DT-MIL,作者还开发了三种具有不同bag嵌入模块的ES-MIL方法,这些模块在位置编码的feature image的顶部工作,以生成bag表示。如图2所示,第一种方法利用卷积层来生成bag表示(CNNMIL,图2A)。第二种称为ViT-MIL,使用ViT中的分类变换器架构(图2B)。第三种方法,表示为DTEC-MIL,使用可变形Transformer编码器和用于bag嵌入的级联(图2C)。
总结
在WSI中,bag表示整张大图,大图中的patch为instance,注意这个patch是512×512的。MIL的作用是整合instance的表示。