参考自李宏毅课程-人类语言处理
三、BERT和它的家族-ELMo,BERT,GPT,XLNet,MASS,BART,UniLM,ELECTRA等
1. How to pre-train
上一部分是介绍怎么用pre-trained model做一些NLP相关的任务,那么怎样得到这个pre-trained model。
最早的一种pre-train的方法就是利用翻译的任务去train一个encoder和decoder,这个encoder就是我们想要的pre-trained model。用翻译的任务来做是因为翻译的时候需要考虑上下文信息,因此每个token对应的输出也是考虑上下文的,然后用这些输出输入到decoder可以得到正确的翻译说明,这些输出包含了每个token的语义。但是这样做的话,就表示需要去训练这个翻译任务的encoder,需要很多成对的翻译数据,成本非常大。

因此,不需要标注数据的方法进行pre-train,称作self-supervised learning提出,这就是unsupervised learning,LeCun希望人们改口称为self-supervised learning。因为它的本质是用输入的一部分去预测输入的一部分,是自监督的。下图是有监督和自监督的区别:

2. Predict next token
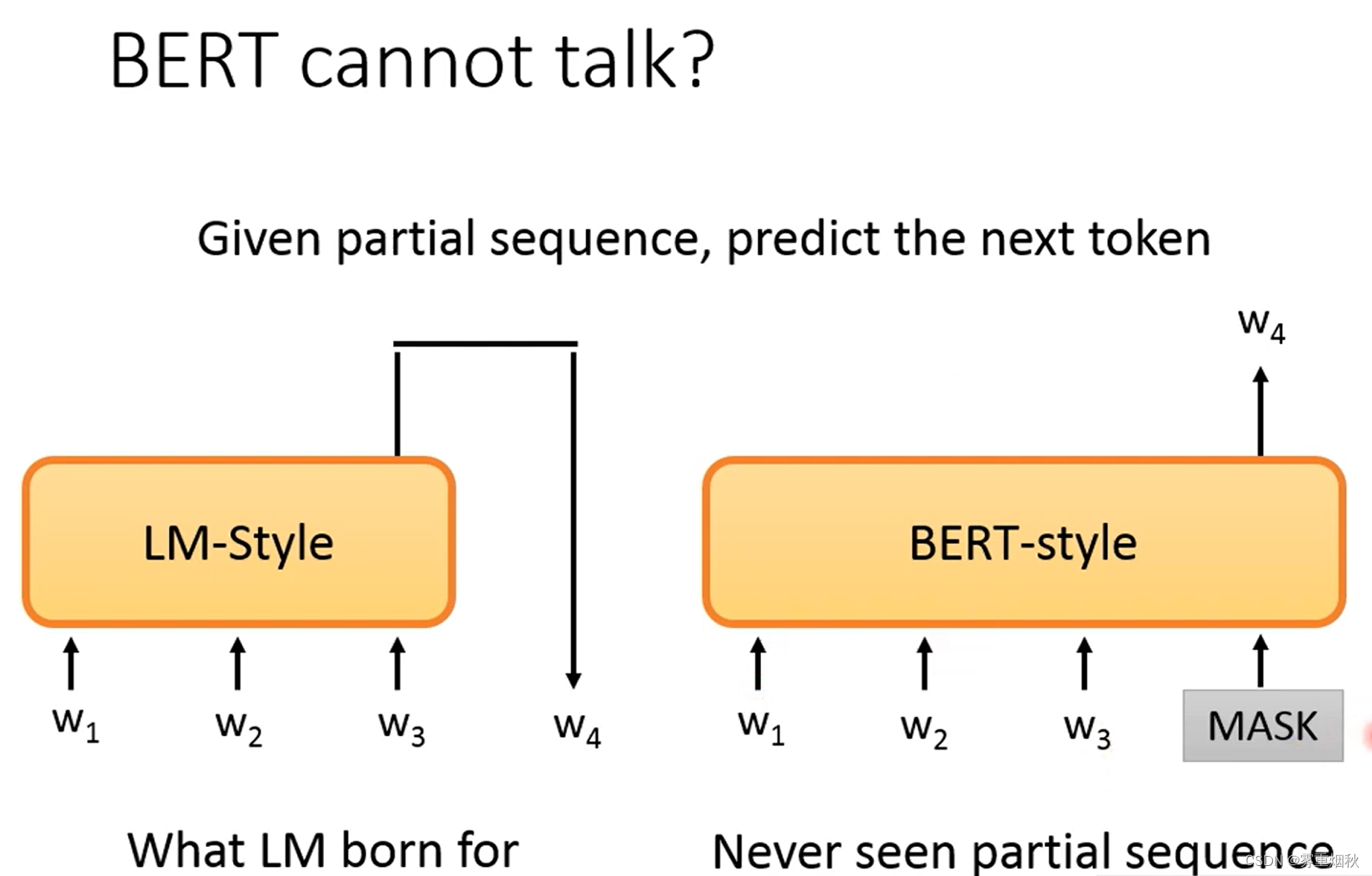
那么怎么做能提取到输入序列的特征,最常见的一种做法是predict next token。输入w1希望模型预测出w2,再输入w2希望模型预测出w3,以此类推。但是设计模型的时候,不要让模型看到答案,否则模型直接copy输入,学不到任何东西。把这个输入 w i w_i wi,输出 h i h_i hi的模型基于LSTM去设计,就是ELMo。如果是基于self-attention去做,就有GPT,Megatron和Turing NLG。这个模型也就是Language model。

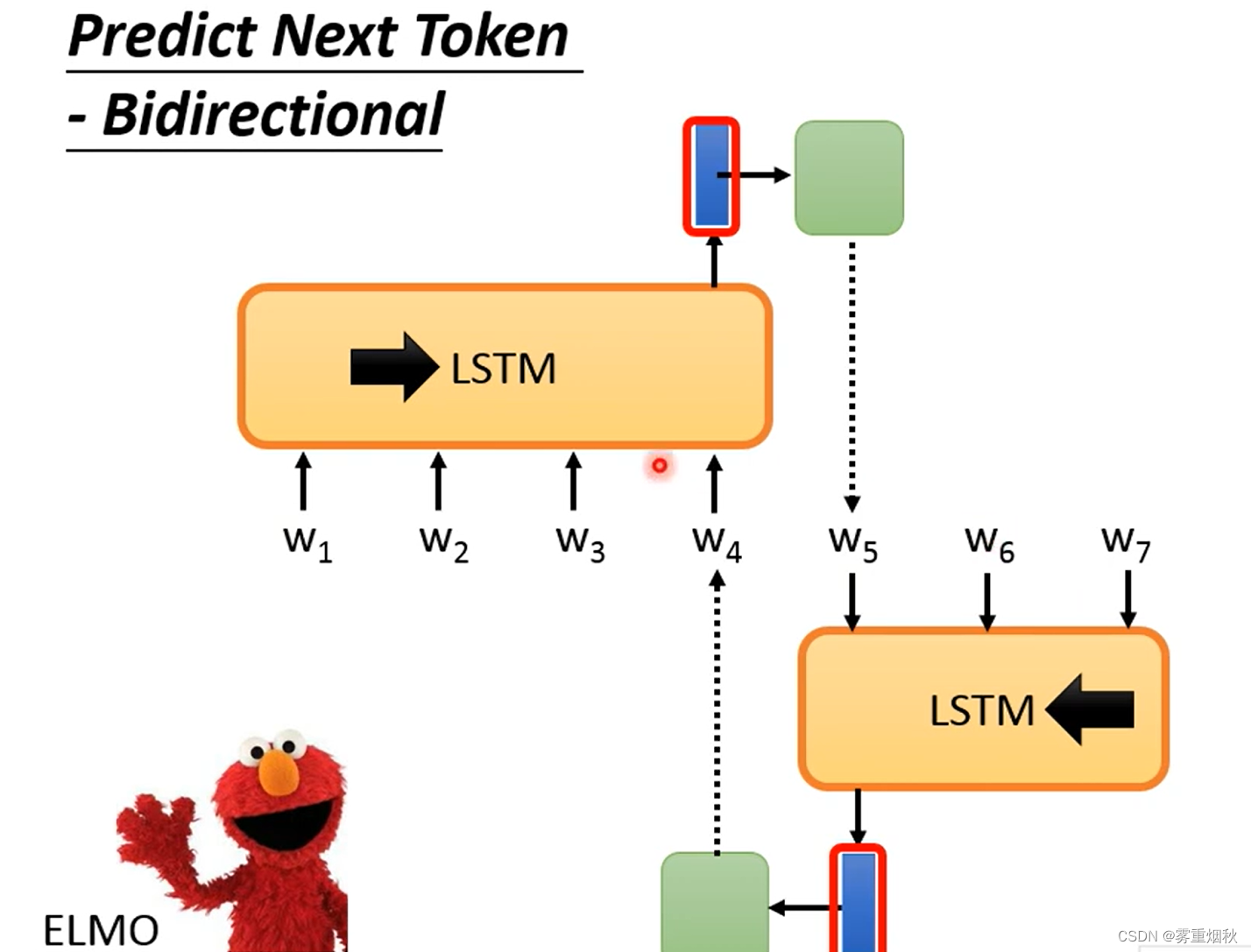
那么上面说的预测w2的时候只看了w1,那么为什么不能也看一下w3和w4呢,所以ELMo就用了两个LSTM分别从头开始看和从尾开始看,比如看w1-w4去预测w5,然后看w5-w7去预测w4,最后把这两个的feature去concat得到最终的w4对应的feature。
3. Mask Input
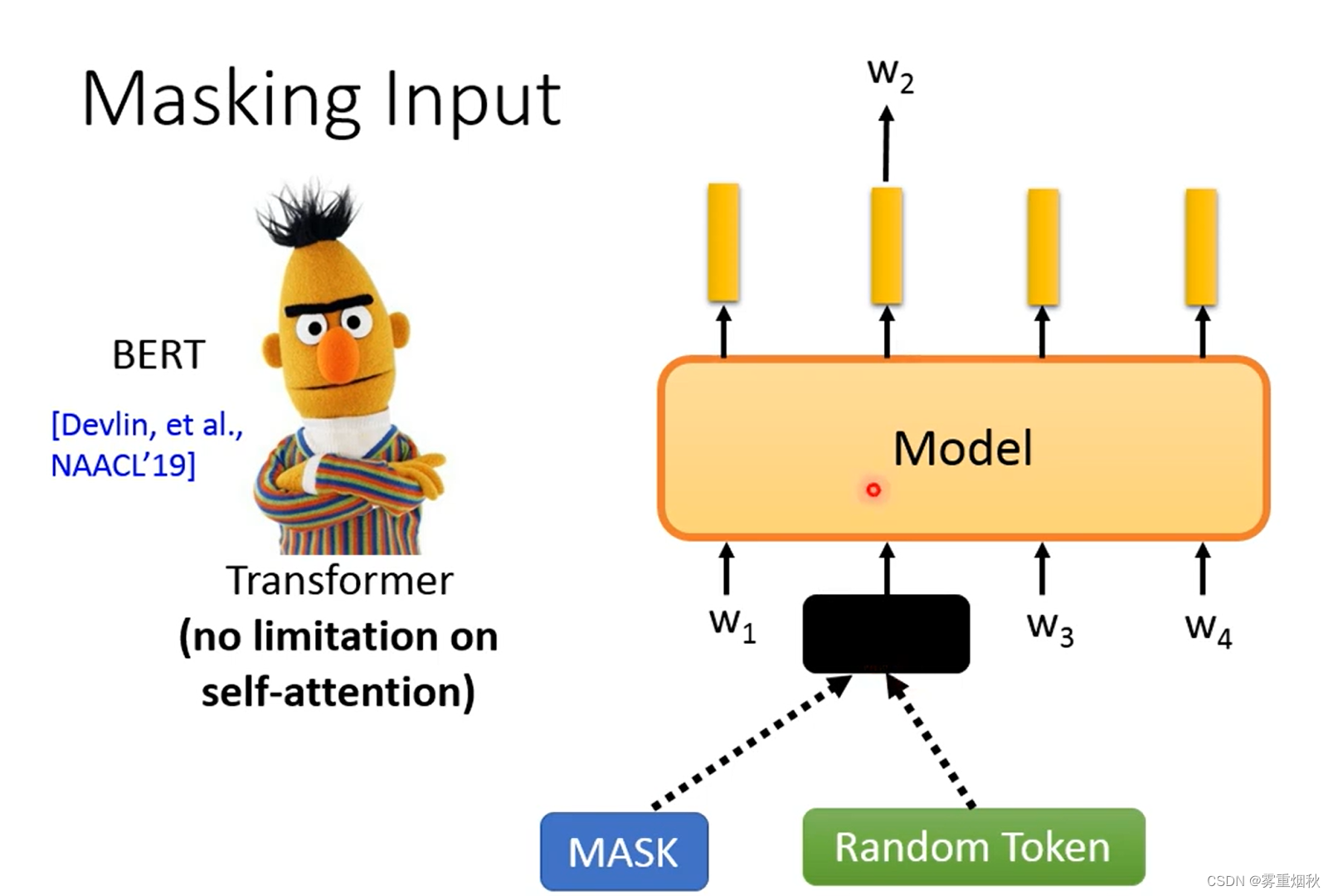
ELMo的两个LSTM是相互独立的,它们之间没有信息的交流。BERT解决了这个问题,BERT只要设计好一个MASK,然后盖住模型要预测的那个token就可以,这样self-attention就可以看到除了答案的所有的部分,这个思路和CBOW是非常像的。

但是,如果只盖住一个token,模型可能无法学到一些long-term的东西,因为只需要依赖于附近几个token猜就行了。所以,有人提出了盖一个词,叫Whole Word Masking。也有人提出对句子做entity recoganition然后盖住entity或者phrase,这个就是ERNIE。
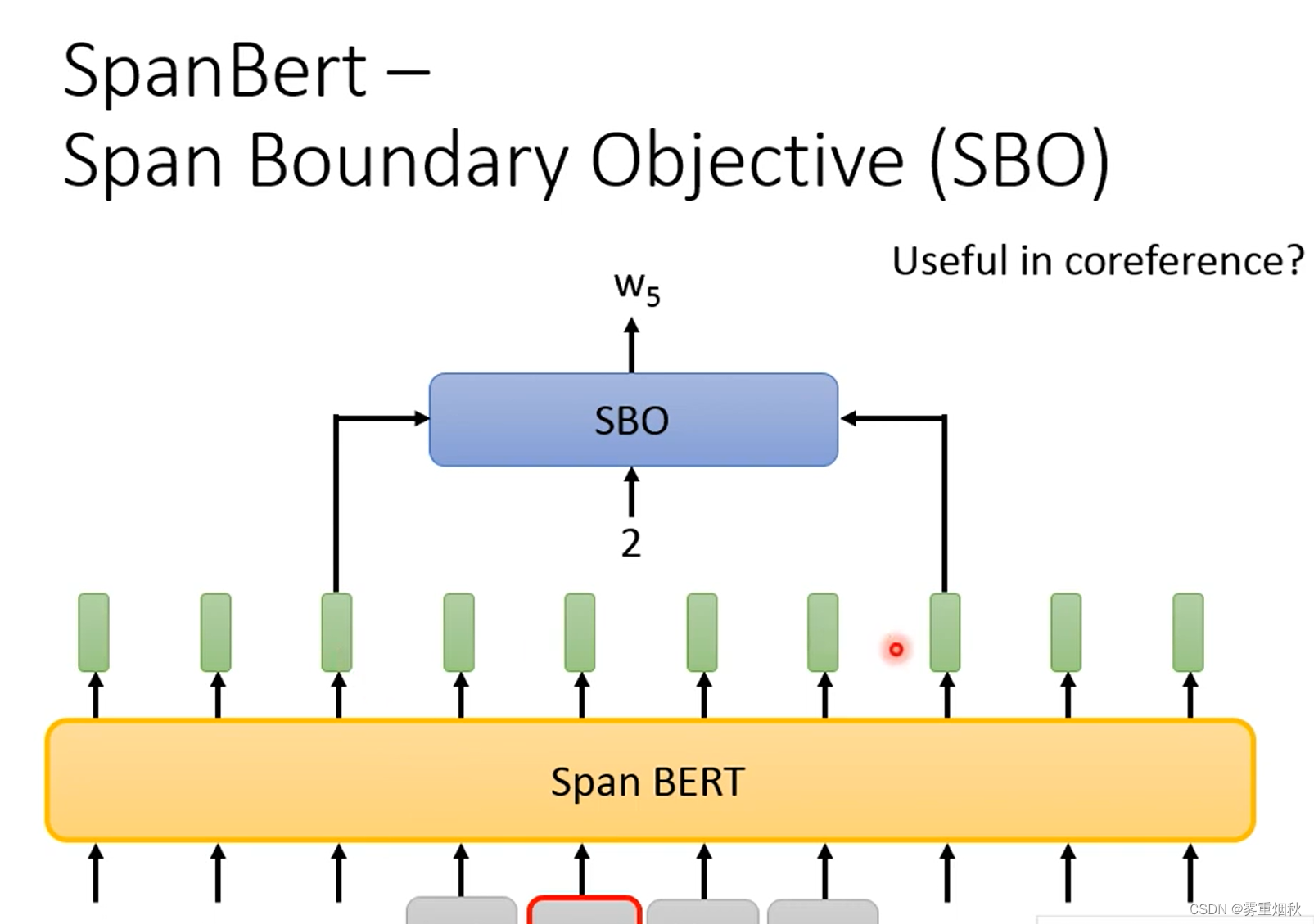
还有一种叫做SpanBert的方法,就是随机去盖一排token,盖住的token的length满足一个分布,这个分布是盖的越长概率越小的分布,SpanBert的训练方法和Bert有所不同,它用了一种叫做Span Boundary Objective的方法,利用被盖住部分两端最接近的两个embedding,然后再输入一个要预测被盖住的第几个token的数字,去预测最终的结果。(这个可能在指代消解中有好的效果?)
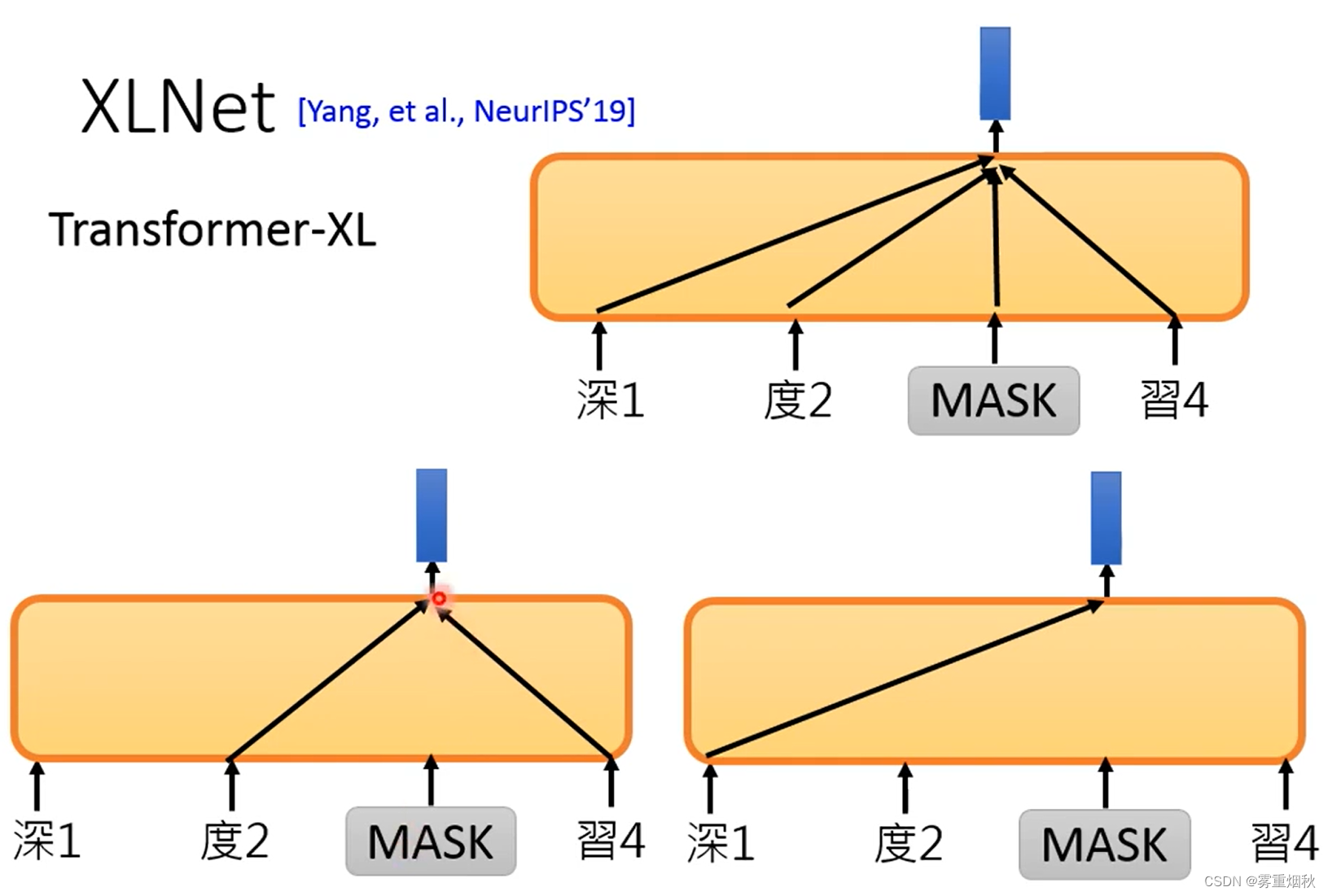
然后是一个叫XLNet的模型,它在预测被盖住token的时候,是随机取其他已有的embedding的信息去预测,也需要一个position encoding来告诉它去预测哪个位置的token,这里不知道为什么要这么做,仅仅是介绍。
4. seq2seq的pre-train model
BERT在训练的时候是看整个句子去预测的,因此不太适用于generation的任务。Language model在训练的时候符合句子生成的任务。这种从左往右进行预测叫做autoregressive model,但是今天,我们不一定要让模型从左往右生成文本,如果是non-autoregressive model的话,说不定BERT就适用了。
seq2seq的pre-train model是如下图一样的,输入一串tokens,经过encoder和decoder之后,希望得到同样的一串tokens。如果直接这么做的话太简单,模型学不到什么东西,所以,一般会对input的sequence做一些破坏。

Bart尝试了以下几种破坏方式,第一种是随机给一个token加mask;第二种是删除某些输入;第三种是对tokens做permutation;第四种是对tokens做rotation;第五中是在没有token的地方插入mask,然后盖住某些token,盖住的部分可能有两个token。其中效果最好的是最后的一种。第三和第四种效果最差。这样的结果其实也可以预期到,给模型看大量的打乱顺序的句子,模型就不知道什么是正常的句子了。

还有一种叫做UniLM,既可以像BERT那样训练(双向language model),又可以像GPT那样训练(left-to-right language model),还可以像BART那样训练(seq2seq language model)。
5. ELECTRA
ELECTRA模型用一个更简单的任务去预训练模型,它把输入中的某个token用另一个token替换后,输入模型,让模型去预测各个token有没有被替换过。这样一方面使得任务更为简单,另一方面也可以监督到每一个token的对应输出。

如果随意替换的话,很容易被模型找出来,所以这篇文章的作者用了一个额外的small BERT来生成这个要被替换掉的位置的token,这个small BERT不能太准,也不能太不准,这种做法有点像GAN,但是上下两个模型是各train各的,BERT被设定为要骗过上面的model。

ELECTRA可以用更少的FLOPS(Floating Point Operations Per Second,每秒浮点运算次数。这是衡量计算机性能的一个指标,特别是在科学计算和工程领域。在深度学习和人工智能领域,FLOPs常用来估计神经网络模型在执行过程中所需的计算量。)得到和大模型非常接近的结果。
6. Sentence Embedding
有些时候,我们希望得到的并不是每个token的embedding,而是一个可以表示整个句子的sentence embedding。

训练sentence embedding的模型有两种方法,一种叫做skip Thought,给定一个句子,让模型去预测它的下一句话是什么,这样的生成任务很难,另一种叫做Quick Thought,在encoder分别输入sentence1和sentence2,encoder会分别输出feature1和feature2,如果这两个句子是相邻的,那么我们希望feature1和feature2很相似。(常用于句子相似度计算,语义文本相似性,这两种方法捕捉句子在不同上下文的语义变化,而不仅仅是基于句子本身的内容,因为我们想得到sentence的embedding)

BERT的做法是NSP(Next sentence prediction),就是输入两个句子,在两个句子之间加一个"SEP"分隔符,然后用CLS这个token的输出来预测这两个句子是相邻的,还是不是相邻的。

NSP这种做法的实际效果并不好,于是就有人提出了SOP(Sentence order preditcion)。就是让两个句子来自于同一篇文章,如果这两个相邻的句子反过来,那么它输出No,只有在相邻且顺序对的情况才输出Yes。还有人提出了structBERT,结合了NSP和SOP。最后说了T5(Text-to-Text Transfer Transformer),由谷歌研究人员在2019年提出,它是一个预训练的Transformer模型,专门设计用于文本转换任务,如文本摘要、问题回答、翻译、文本生成等。