文章目录
深度学习Week16------数据增强
一、前言
二、我的环境
三、前期工作
1、配置环境
2、导入数据
2.1 加载数据
2.2 配置数据集
2.3 数据可视化
四、数据增强
五、增强方式
1、将其嵌入model中
2、在Dataset数据集中进行数据增强
六、训练模型
七、自定义增强函数
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
本篇内容分为两个部分,前面部分是学习K同学给的算法知识点以及复现,后半部分是自己的拓展与未解决的问题
本期学习了数据增强函数并自己实现一个增强函数,使用的数据集仍然是猫狗数据集。
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.0
- 编译器:Pycharm2023.2.3
深度学习环境:TensorFlow
显卡及显存:RTX 3060 8G
三、前期工作
1、配置环境
python
import matplotlib.pyplot as plt
import numpy as np
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
from tensorflow.keras import layers
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]这一步与pytorch第一步类似,我们在写神经网络程序前无论是选择pytorch还是tensorflow都应该配置好gpu环境(如果有gpu的话)
2、 导入数据
导入所有猫狗图片数据,依次分别为训练集图片(train_images)、训练集标签(train_labels)、测试集图片(test_images)、测试集标签(test_labels),数据集来源于K同学啊
2.1 加载数据
py
data_dir = "/home/mw/input/dogcat3675/365-7-data"
img_height = 224
img_width = 224
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.3,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)使用
image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
tf.keras.preprocessing.image_dataset_from_directory()会将文件夹中的数据加载到tf.data.Dataset中,且加载的同时会打乱数据。
- class_names
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证。
- subset: training或validation之一。仅在设置validation_split时使用。
- seed: 用于shuffle和转换的可选随机种子。
- batch_size: 数据批次的大小。默认值:32
- image_size: 从磁盘读取数据后将其重新调整大小。默认:(256,256)。由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供。
输出:
Found 3400 files belonging to 2 classes.
Using 2380 files for training.由于原始的数据集里不包含测试集,所以我们需要自己创建一个
py
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(val_ds))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_ds))Number of validation batches: 60
Number of test batches: 15我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
py
class_names = train_ds.class_names
print(class_names)'cat', 'dog'
2.2 配置数据集
py
AUTOTUNE = tf.data.AUTOTUNE
def preprocess_image(image,label):
return (image/255.0,label)
# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)2.3 数据可视化
py
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")
四 、数据增强
使用下面两个函数来进行数据增强:
tf.keras.layers.experimental.preprocessing.RandomFlip:水平和垂直随机翻转每个图像。tf.keras.layers.experimental.preprocessing.RandomRotation:随机旋转每个图像
py
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.3),
])第一个层表示进行随机的水平和垂直翻转,而第二个层表示按照0.3的弧度值进行随机旋转。
py
# Add the image to a batch.
image = tf.expand_dims(images[i], 0)
plt.figure(figsize=(8, 8))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")五、增强方式
1. 将其嵌入model中
py
model = tf.keras.Sequential([
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names))
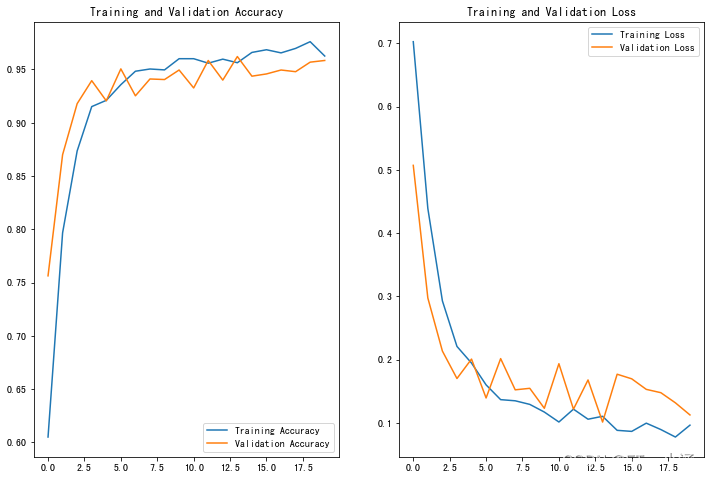
])Epoch 1/20
43/43 [==============================] - 18s 103ms/step - loss: 1.2824 - accuracy: 0.5495 - val_loss: 0.4272 - val_accuracy: 0.8941
Epoch 2/20
43/43 [==============================] - 3s 55ms/step - loss: 0.3326 - accuracy: 0.8815 - val_loss: 0.1882 - val_accuracy: 0.9309
Epoch 3/20
43/43 [==============================] - 3s 54ms/step - loss: 0.1614 - accuracy: 0.9488 - val_loss: 0.1493 - val_accuracy: 0.9412
Epoch 4/20
43/43 [==============================] - 2s 54ms/step - loss: 0.1215 - accuracy: 0.9557 - val_loss: 0.0950 - val_accuracy: 0.9721
Epoch 5/20
43/43 [==============================] - 3s 54ms/step - loss: 0.0906 - accuracy: 0.9666 - val_loss: 0.0791 - val_accuracy: 0.9691
Epoch 6/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0614 - accuracy: 0.9768 - val_loss: 0.1131 - val_accuracy: 0.9559
Epoch 7/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0603 - accuracy: 0.9807 - val_loss: 0.0692 - val_accuracy: 0.9794
Epoch 8/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0577 - accuracy: 0.9793 - val_loss: 0.0609 - val_accuracy: 0.9779
Epoch 9/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0511 - accuracy: 0.9825 - val_loss: 0.0546 - val_accuracy: 0.9779
Epoch 10/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0462 - accuracy: 0.9871 - val_loss: 0.0628 - val_accuracy: 0.9765
Epoch 11/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0327 - accuracy: 0.9895 - val_loss: 0.0790 - val_accuracy: 0.9721
Epoch 12/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0242 - accuracy: 0.9938 - val_loss: 0.0580 - val_accuracy: 0.9794
Epoch 13/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0354 - accuracy: 0.9907 - val_loss: 0.0797 - val_accuracy: 0.9735
Epoch 14/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0276 - accuracy: 0.9900 - val_loss: 0.0810 - val_accuracy: 0.9691
Epoch 15/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0243 - accuracy: 0.9931 - val_loss: 0.1063 - val_accuracy: 0.9676
Epoch 16/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0253 - accuracy: 0.9914 - val_loss: 0.1142 - val_accuracy: 0.9721
Epoch 17/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0205 - accuracy: 0.9937 - val_loss: 0.0726 - val_accuracy: 0.9706
Epoch 18/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0154 - accuracy: 0.9948 - val_loss: 0.0741 - val_accuracy: 0.9765
Epoch 19/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0155 - accuracy: 0.9966 - val_loss: 0.0870 - val_accuracy: 0.9721
Epoch 20/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0259 - accuracy: 0.9907 - val_loss: 0.1194 - val_accuracy: 0.9721这样做的好处是:
数据增强这块的工作可以得到GPU的加速(如果你使用了GPU训练的话)
注意:只有在模型训练时(Model.fit)才会进行增强,在模型评估(Model.evaluate)以及预测(Model.predict)时并不会进行增强操作。
2. 在Dataset数据集中进行数据增强
py
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds):
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)
return ds
py
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(len(class_names))
])Epoch 1/20
75/75 [==============================] - 11s 133ms/step - loss: 0.8828 - accuracy: 0.7113 - val_loss: 0.1488 - val_accuracy: 0.9447
Epoch 2/20
75/75 [==============================] - 2s 33ms/step - loss: 0.1796 - accuracy: 0.9317 - val_loss: 0.0969 - val_accuracy: 0.9658
Epoch 3/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0999 - accuracy: 0.9655 - val_loss: 0.0362 - val_accuracy: 0.9879
Epoch 4/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0566 - accuracy: 0.9810 - val_loss: 0.0448 - val_accuracy: 0.9853
Epoch 5/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0426 - accuracy: 0.9807 - val_loss: 0.0142 - val_accuracy: 0.9937
Epoch 6/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0149 - accuracy: 0.9944 - val_loss: 0.0052 - val_accuracy: 0.9989
Epoch 7/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0068 - accuracy: 0.9974 - val_loss: 7.9693e-04 - val_accuracy: 1.0000
Epoch 8/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 4.8532e-04 - val_accuracy: 1.0000
Epoch 9/20
75/75 [==============================] - 2s 33ms/step - loss: 4.5804e-04 - accuracy: 1.0000 - val_loss: 1.9160e-04 - val_accuracy: 1.0000
Epoch 10/20
75/75 [==============================] - 2s 33ms/step - loss: 1.7624e-04 - accuracy: 1.0000 - val_loss: 1.1390e-04 - val_accuracy: 1.0000
Epoch 11/20
75/75 [==============================] - 2s 33ms/step - loss: 1.1646e-04 - accuracy: 1.0000 - val_loss: 8.7005e-05 - val_accuracy: 1.0000
Epoch 12/20
75/75 [==============================] - 2s 33ms/step - loss: 9.0645e-05 - accuracy: 1.0000 - val_loss: 7.1111e-05 - val_accuracy: 1.0000
Epoch 13/20
75/75 [==============================] - 2s 33ms/step - loss: 7.4695e-05 - accuracy: 1.0000 - val_loss: 5.9888e-05 - val_accuracy: 1.0000
Epoch 14/20
75/75 [==============================] - 2s 33ms/step - loss: 6.3227e-05 - accuracy: 1.0000 - val_loss: 5.1448e-05 - val_accuracy: 1.0000
Epoch 15/20
75/75 [==============================] - 2s 33ms/step - loss: 5.4484e-05 - accuracy: 1.0000 - val_loss: 4.4721e-05 - val_accuracy: 1.0000
Epoch 16/20
75/75 [==============================] - 2s 33ms/step - loss: 4.7525e-05 - accuracy: 1.0000 - val_loss: 3.9201e-05 - val_accuracy: 1.0000
Epoch 17/20
75/75 [==============================] - 2s 33ms/step - loss: 4.1816e-05 - accuracy: 1.0000 - val_loss: 3.4528e-05 - val_accuracy: 1.0000
Epoch 18/20
75/75 [==============================] - 2s 33ms/step - loss: 3.7006e-05 - accuracy: 1.0000 - val_loss: 3.0541e-05 - val_accuracy: 1.0000
Epoch 19/20
75/75 [==============================] - 2s 33ms/step - loss: 3.2878e-05 - accuracy: 1.0000 - val_loss: 2.7116e-05 - val_accuracy: 1.0000
Epoch 20/20
75/75 [==============================] - 2s 33ms/step - loss: 2.9274e-05 - accuracy: 1.0000 - val_loss: 2.4160e-05 - val_accuracy: 1.0000六、训练模型
py
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
epochs=20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
py
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)使用方法一:
15/15 [==============================] - 1s 58ms/step - loss: 0.0984 - accuracy: 0.9646
Accuracy 0.9645833373069763使用方法二:
15/15 [==============================] - 1s 58ms/step - loss: 2.7453e-05 - accuracy: 1.0000
Accuracy 1.0七、自定义增强函数
py
import random
def aug_img(image):
seed = random.randint(0, 10000) # 随机种子
# 随机亮度
image = tf.image.stateless_random_brightness(image, max_delta=0.2, seed=[seed, 0])
# 随机对比度
image = tf.image.stateless_random_contrast(image, lower=0.8, upper=1.2, seed=[seed, 1])
# 随机饱和度
image = tf.image.stateless_random_saturation(image, lower=0.8, upper=1.2, seed=[seed, 2])
# 随机色调
image = tf.image.stateless_random_hue(image, max_delta=0.2, seed=[seed, 3])
# 随机翻转水平和垂直
image = tf.image.stateless_random_flip_left_right(image, seed=[seed, 4])
image = tf.image.stateless_random_flip_up_down(image, seed=[seed, 5])
# 随机旋转
image = tf.image.rot90(image, k=random.randint(0, 3)) # 旋转0, 90, 180, 270度
return image
py
image = tf.expand_dims(images[3]*255, 0)
print("Min and max pixel values:", image.numpy().min(), image.numpy().max())Min and max pixel values: 2.4591687 241.47968
py
plt.figure(figsize=(8, 8))
for i in range(9):
augmented_image = aug_img(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
然后我们使用了第二种增强方法,以下为他的结果:
15/15 [==============================] - 1s 57ms/step - loss: 0.1294 - accuracy: 0.9604
Accuracy 0.9604166746139526