Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明
目录
[Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明](#Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明)
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
二、处理文本数据
在前面的文章中,我们讨论过表示数据属性的两种类型的特征:连续特征与分类特征,前者用于描述数量,后者是固定列表中的元素。在许多应用中还可以见到第三种类型的特征:文本。
举个例子,如果我们想要判断一封电子邮件是合法邮件还是垃圾邮件,那么邮件内容一定会包含对这个分类任务非常重要的信息。或者,我们可能想要了解一位政治家对移民问题的看法。这个人的演讲或推文可能会提供有用的信息。在客户服务中,我们通常想知道一条消息是投诉还是咨询。我们可以利用消息的主题和内容来自动判断客户的目的,从而将消息发送给相关部门,甚至可以发送一封全自动回复。
文本数据通常被表示为由字符组成的字符串。在上面给出的所有例子中,文本数据的长度都不相同。这个特征显然与前面讨论过的数值特征有很大不同,我们需要先处理数据,然后才能对其应用机器学习算法。
在机器学习中,处理文本数据是一个重要的任务,尤其在自然语言处理(NLP)领域。文本数据的处理通常涉及特征提取、模型训练和评估。以下是一些关键步骤和方法:
1. 文本预处理
在处理文本数据之前,通常需要进行一些预处理步骤,以确保数据的一致性和质量:
- 去除标点和特殊字符:删除不必要的标点符号和特殊字符。
- 小写转换:将所有文本转换为小写,以减少特征数量。
- 去除停用词:移除常见的无意义的词汇(如 "the", "is", "and" 等)。
- 词干化和词形还原:将单词还原到其原始或词干形式,例如 "running" 变成 "run"。
2. 特征提取
文本数据需要转换为数值特征,以便输入机器学习模型。常见的方法包括:
- 词袋模型 (Bag of Words, BoW):将文本转换为词频向量。
- TF-IDF (Term Frequency-Inverse Document Frequency):调整词频,以减少常见词的影响。
- 词嵌入 (Word Embeddings):将单词映射到低维向量空间,常用的有 Word2Vec、GloVe 和 FastText。
- 句子嵌入 (Sentence Embeddings):将整个句子或段落映射到向量空间,如使用 BERT、GPT 等预训练模型。
3. 模型训练和评估
将文本转换为数值特征后,可以使用常见的机器学习模型进行训练和评估,例如朴素贝叶斯、支持向量机、逻辑回归等。
4. 管道和交叉验证
为了更好地处理文本数据,可以使用管道和交叉验证来优化模型。管道可以将预处理步骤和模型训练连接在一起,简化工作流程。交叉验证则可以更可靠地评估模型性能。
5. 高级文本处理
对于更复杂的任务,可以使用高级的文本处理技术,例如:
- Word2Vec 和 GloVe:用于生成词向量的预训练模型。
- Transformer 模型:如 BERT、GPT-3 等,可以生成上下文相关的词向量或句子向量。
总结:
处理文本数据涉及多个步骤,从预处理、特征提取到模型训练和评估。使用合适的方法和工具,可以有效地将文本数据转换为数值特征,并训练出性能优异的模型。管道和交叉验证可以帮助简化流程和优化模型,而高级的文本处理技术则能进一步提升模型的表现。
三、用字符串表示的数据类型
在深入研究表示机器学习文本数据的处理步骤之前,我们希望简要讨论你可能会遇到的不同类型的文本数据。文本通常只是数据集中的字符串,但并非所有的字符串特征都应该被当作文本来处理。我们在之前的篇章讨论过,字符串特征有时可以表示分类变量。在查看数据之前,我们无法知道如何处理一个字符串特征。
你可能会遇到四种类型的字符串数据:
- 分类数据
- 可以在语义上映射为类别的自由字符串
- 结构化字符串数据
- 文本数据
分类数据 (categorical data)是来自固定列表的数据。
比如你通过调查人们最喜欢的颜色来收集数据,你向他们提供了一个下拉菜单,可以从"红色""绿色""蓝色""黄色""黑色""白色""紫色"和"粉色"中选择。这样会得到一个包含 8 个不同取值的数据集,这 8 个不同取值表示的显然是分类变量。你可以通过观察来判断你的数据是不是分类数据(如果你看到了许多不同的字符串,那么不太可能是分类变量),并通过计算数据集中的唯一值并绘制其出现次数的直方图来验证你的判断。你可能还希望检查每个变量是否实际对应于一个在应用中有意义的分类。调查过程进行到一半,有人可能发现调查问卷中将"black"(黑色)错拼为"blak",并随后对其进行了修改。因此,你的数据集中同时包含"black"和"blak",它们对应于相同的语义,所以应该将二者合并。
现在想象一下,你向用户提供的不是一个下拉菜单,而是一个文本框,让他们填写自己最喜欢的颜色。许多人的回答可能是像"黑色"或"蓝色"之类的颜色名称。其他人可能会出现笔误,使用不同的单词拼写(比如"gray"和"grey"(两个词的意思都是"灰色") ),或使用更加形象的具体名称(比如"午夜蓝色")。你还会得到一些非常奇怪的条目。xkcd 颜色调查(Color Survey Results -- xkcd )中有一些很好的例子,其中有人为颜色命名,给出了如"迅猛龙泄殖腔"和"我牙医办公室的橙色。我仍然记得他的头皮屑慢慢地漂落到我张开的下巴"之类的名称,很难将这些名称与颜色自动对应(或者根本就无法对应)。
从文本框中得到的回答属于上述列表中的第二类,可以在语义上映射为类别的自由字符串 (free strings that can be semantically mapped to categories)。可能最好将这种数据编码为分类变量,你可以利用最常见的条目来选择类别,也可以自定义类别,使用户回答对应用有意义。这样你可能会有一些标准颜色的类别,可能还有一个"多色"类别(对于像"绿色与红色条纹"之类的回答)和"其他"类别(对于无法归类的回答)。这种字符串预处理过程可能需要大量的人力,并且不容易自动化。如果你能够改变数据的收集方式,那么我们强烈建议,对于分类变量能够更好表示的概念,不要使用手动输入值。
通常来说,手动输入值不与固定的类别对应,但仍有一些内在的结构 (structure),比如地址、人名或地名、日期、电话号码或其他标识符。这种类型的字符串通常难以解析,其处理方法也强烈依赖于上下文和具体领域。对这种情况的系统处理方法超出了本书的范围。
最后一类字符串数据是自由格式的文本数据 (text data),由短语或句子组成。例子包括推文、聊天记录和酒店评论,还包括莎士比亚文集、维基百科的内容或古腾堡计划收集的 50 000 本电子书。所有这些集合包含的信息大多是由单词组成的句子(推文中链接网站的内容所包含的信息可能比推文本身还要多)。 为了简单起见,我们假设所有的文档都只使用一种语言:英语(接下来的绝大部分内容也适用于其他使用罗马字母的语言,部分适用于具有单词定界符的其他语言。例如,中文没有词边界,还有其他方面的挑战,所以难以应用本章介绍的技术)。 在文本分析的语境中,数据集通常被称为语料库 (corpus),每个由单个文本表示的数据点被称为文档 (document)。这些术语来自于信息检索 (information retrieval,IR)和自然语言处理 (natural language processing,NLP)的社区,它们主要针对文本数据。
四、示例应用:电影评论的情感分析
作为本章的一个运行示例,我们将使用由斯坦福研究员 Andrew Maas 收集的 IMDb(Internet Movie Database,互联网电影数据库)网站的电影评论数据集(你可以在 Sentiment Analysis 下载这个数据集)。 这个数据集包含评论文本,还有一个标签,用于表示该评论是"正面的"(positive)还是"负面的"(negative)。IMDb 网站本身包含从 1 到 10 的打分。为了简化建模,这些评论打分被归纳为一个二分类数据集,评分大于等于 7 的评论被标记为"正面的",评分小于等于 4 的评论被标记为"负面的",中性评论没有包含在数据集中。我们不讨论这种方法是否是一种好的数据表示,而只是使用 Andrew Maas 提供的数据。
将数据解压之后,数据集包括两个独立文件夹中的文本文件,一个是训练数据,一个是测试数据。每个文件夹又都有两个子文件夹,一个叫作 pos,一个叫作 neg:
python
!tree data/aclImdb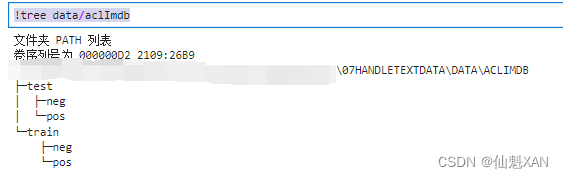
pos 文件夹包含所有正面的评论,每条评论都是一个单独的文本文件,neg 文件夹与之类似。scikit-learn 中有一个辅助函数可以加载用这种文件夹结构保存的文件,其中每个子文件夹对应于一个标签,这个函数叫作 load_files 。我们首先将 load_files 函数应用于训练数据(由于数据比较多,这里比较耗时):
python
from sklearn.datasets import load_files
reviews_train = load_files("data/aclImdb/train/")
# load_files返回一个Bunch对象,其中包含训练文本和训练标签
text_train, y_train = reviews_train.data, reviews_train.target
print("type of text_train: {}".format(type(text_train)))
print("length of text_train: {}".format(len(text_train)))
print("text_train[1]:\n{}".format(text_train[1]))type of text_train: <class 'list'>
length of text_train: 25000
text_train[1]:
b'Words can\'t describe how bad this movie is. I can\'t explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clich\xc3\xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won\'t list them here, but just mention the coloring of the plane. They didn\'t even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys\' side all the time in the movie, because the good guys were so stupid. "Executive Decision" should without a doubt be you\'re choice over this one, even the "Turbulence"-movies are better. In fact, every other movie in the world is better than this one.'你可以看到,text_train 是一个长度为 75 000(对于 v1.0 版数据,其训练集大小是 75 000,而不是 25 000,因为其中还包含 50 000 个用于无监督学习的无标签文档(data\aclImdb\train\unsup )。在进行后续操作之前,建议先将这 50 000 个无标签文档从训练集中剔除,同时可能会影响数据结果) 的列表 ,其中每个元素是包含一条评论的字符串。我们打印出索引编号为 1 的评论。你还可以看到,评论中包含一些 HTML 换行符(<br /> )。虽然这些符号不太可能对机器学习模型产生很大影响,但最好在继续下一步之前清洗数据并删除这种格式:
python
text_train = [doc.replace(b"<br />", b" ") for doc in text_train]text_train 的元素类型与你所使用的 Python 版本有关。在 Python 3 中,它们是 bytes 类型,是表示字符串数据的二进制编码。在 Python 2 中,text_train 包含的是字符串。这里不会深入讲解 Python 中不同的字符串类型,但我们推荐阅读 Python 2(Unicode HOWTO --- Python 2.7.18 documentation )和 Python 3(Unicode HOWTO --- Python 3.12.3 documentation )的文档中关于字符串和 Unicode 的内容。
收集数据集时保持正类和反类的平衡,这样所有正面字符串和负面字符串的数量相等:
python
import numpy as np
print("Samples per class (training): {}".format(np.bincount(y_train)))Samples per class (training): [12500 12500]我们用同样的方式加载测试数据集:
python
reviews_test = load_files("data/aclImdb/test/")
text_test, y_test = reviews_test.data, reviews_test.target
print("Number of documents in test data: {}".format(len(text_test)))
print("Samples per class (test): {}".format(np.bincount(y_test)))
text_test = [doc.replace(b"<br />", b" ") for doc in text_test]Number of documents in test data: 25000
Samples per class (test): [12500 12500]我们要解决的任务如下:给定一条评论,我们希望根据该评论的文本内容对其分配一个"正面的"或"负面的"标签。这是一项标准的二分类任务。但是,文本数据并不是机器学习模型可以处理的格式。我们需要将文本的字符串表示转换为数值表示,从而可以对其应用机器学习算法。
五、将文本数据表示为词袋
用于机器学习的文本表示有一种最简单的方法,也是最有效且最常用的方法,就是使用词袋 (bag-of-words)表示。使用这种表示方式时,我们舍弃了输入文本中的大部分结构,如章节、段落、句子和格式,只计算语料库中每个单词在每个文本中的出现频次 。舍弃结构并仅计算单词出现次数,这会让脑海中出现将文本表示为"袋"的画面。
对于文档语料库,计算词袋表示包括以下三个步骤。
(1) 分词 (tokenization)。将每个文档划分为出现在其中的单词 称为词例(token),比如按空格和标点划分。
(2) 构建词表 (vocabulary building)。收集一个词表,里面包含出现在任意文档中的所有词,并对它们进行编号(比如按字母顺序排序)。
(3) 编码 (encoding)。对于每个文档,计算词表中每个单词在该文档中的出现频次。
在步骤 1 和步骤 2 中涉及一些细微之处,我们将在本章后面进一步深入讨论。目前,我们来看一下如何利用 scikit-learn 来应用词袋处理过程。图 7-1 展示了对字符串 "This is how you get ants." 的处理过程。其输出是包含每个文档中单词计数的一个向量。对于词表中的每个单词,我们都有它在每个文档中的出现次数。也就是说,整个数据集中的每个唯一单词都对应于这种数值表示的一个特征。请注意,原始字符串中的单词顺序与词袋特征表示完全无关。
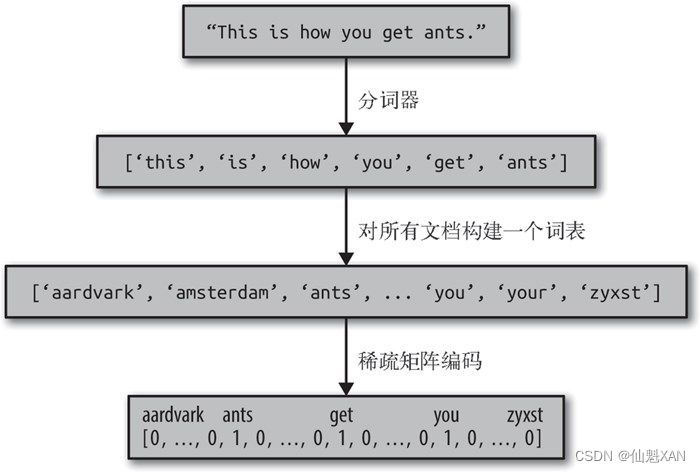 图 7-1:词袋处理过程
图 7-1:词袋处理过程
1、将词袋应用于玩具数据集
词袋表示是在 CountVectorizer 中实现的,它是一个变换器(transformer)。我们首先将它应用于一个包含两个样本的玩具数据集,来看一下它的工作原理:
python
bards_words =["The fool doth think he is wise,",
"but the wise man knows himself to be a fool"]我们导入 CountVectorizer 并将其实例化,然后对玩具数据进行拟合,如下所示:
python
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
vect.fit(bards_words)拟合 CountVectorizer 包括训练数据的分词与词表的构建,我们可以通过 vocabulary_ 属性来访问词表:
python
print("Vocabulary size: {}".format(len(vect.vocabulary_)))
print("Vocabulary content:\n {}".format(vect.vocabulary_))Vocabulary size: 13
Vocabulary content:
{'the': 9, 'fool': 3, 'doth': 2, 'think': 10, 'he': 4, 'is': 6, 'wise': 12, 'but': 1, 'man': 8, 'knows': 7, 'himself': 5, 'to': 11, 'be': 0}词表共包含 13 个词,从 "be" 到 "wise"。
我们可以调用 transform 方法来创建训练数据的词袋表示:
python
bag_of_words = vect.transform(bards_words)
print("bag_of_words: {}".format(repr(bag_of_words)))bag_of_words: <2x13 sparse matrix of type '<class 'numpy.int64'>'
with 16 stored elements in Compressed Sparse Row format>词袋表示保存在一个 SciPy 稀疏矩阵中,这种数据格式只保存非零元素)。这个矩阵的形状为 2×13,每行对应于两个数据点之一,每个特征对应于词表中的一个单词。这里使用稀疏矩阵,是因为大多数文档都只包含词表中的一小部分单词,也就是说,特征数组中的大部分元素都为 0。想想看,与所有英语单词(这是词表的建模对象)相比,一篇电影评论中可能出现多少个不同的单词。保存所有 0 的代价很高,也浪费内存。要想查看稀疏矩阵的实际内容,可以使用 toarray 方法将其转换为"密集的"NumPy 数组(保存所有 0 元素)(这么做之所以是可行的,是因为我们使用的是仅包含 13 个单词的小型玩具数据集。对于任何真实数据集来说,这将会导致 MemoryError (内存错误)):
python
print("Dense representation of bag_of_words:\n{}".format(
bag_of_words.toarray()))Dense representation of bag_of_words:
[[0 0 1 1 1 0 1 0 0 1 1 0 1]
[1 1 0 1 0 1 0 1 1 1 0 1 1]]我们可以看到,每个单词的计数都是 0 或 1。bards_words 中的两个字符串都没有包含相同的单词。我们来看一下如何阅读这些特征向量。第一个字符串("The fool doth think he is wise," )被表示为第一行,对于词表中的第一个单词 "be" ,出现 0 次。对于词表中的第二个单词 "but" ,出现 0 次。对于词表中的第三个单词 "doth" ,出现 1 次,以此类推。通过观察这两行可以看出,第 4 个单词 "fool" 、第 10 个单词 "the" 与第 13 个单词 "wise" 同时出现在两个字符串中。
2、将词袋应用于电影评论
上一节我们详细介绍了词袋处理过程,下面我们将其应用于电影评论情感分析的任务。前面我们将 IMDb 评论的训练数据和测试数据加载为字符串列表(text_train 和 text_test ),现在我们将处理它们:
python
vect = CountVectorizer().fit(text_train)
X_train = vect.transform(text_train)
print("X_train:\n{}".format(repr(X_train)))X_train:
<25000x74849 sparse matrix of type '<class 'numpy.int64'>'
with 3431196 stored elements in Compressed Sparse Row format>X_train 是训练数据的词袋表示,其形状为 25 000×74 849,这表示词表中包含 74 849 个元素。数据同样被保存为 SciPy 稀疏矩阵。我们来更详细地看一下这个词表。访问词表的另一种方法是使用向量器(vectorizer)的 get_feature_name 方法,它将返回一个列表,每个元素对应于一个特征:
python
feature_names = vect.get_feature_names_out()
print("Number of features: {}".format(len(feature_names)))
print("First 20 features:\n{}".format(feature_names[:20]))
print("Features 20010 to 20030:\n{}".format(feature_names[20010:20030]))
print("Every 2000th feature:\n{}".format(feature_names[::2000]))Number of features: 74849
First 20 features:
['00' '000' '0000000000001' '00001' '00015' '000s' '001' '003830' '006'
'007' '0079' '0080' '0083' '0093638' '00am' '00pm' '00s' '01' '01pm' '02']
Features 20010 to 20030:
['dratted' 'draub' 'draught' 'draughts' 'draughtswoman' 'draw' 'drawback'
'drawbacks' 'drawer' 'drawers' 'drawing' 'drawings' 'drawl' 'drawled'
'drawling' 'drawn' 'draws' 'draza' 'dre' 'drea']
Every 2000th feature:
['00' 'aesir' 'aquarian' 'barking' 'blustering' 'bête' 'chicanery'
'condensing' 'cunning' 'detox' 'draper' 'enshrined' 'favorit' 'freezer'
'goldman' 'hasan' 'huitieme' 'intelligible' 'kantrowitz' 'lawful' 'maars'
'megalunged' 'mostey' 'norrland' 'padilla' 'pincher' 'promisingly'
'receptionist' 'rivals' 'schnaas' 'shunning' 'sparse' 'subset'
'temptations' 'treatises' 'unproven' 'walkman' 'xylophonist']如你所见,词表的前 10 个元素都是数字,这可能有些出人意料。所有这些数字都出现在评论中的某处,因此被提取为单词。大部分数字都没有一目了然的语义,除了 "007" ,在电影的特定语境中它可能指的是詹姆斯·邦德(James Bond)这个角色( 对数据的快速分析可以证实这一点。你可以自己尝试验证一下)。从无意义的"单词"中挑出有意义的有时很困难。进一步观察这个词表,我们发现许多以"dra"开头的英语单词。你可能注意到了,对于 "draught" 、"drawback" 和 "drawer" ,其单数和复数形式都包含在词表中,并且作为不同的单词。这些单词具有密切相关的语义,将它们作为不同的单词进行计数(对应于不同的特征)可能不太合适。
在尝试改进特征提取之前,我们先通过实际构建一个分类器来得到性能的量化度量。我们将训练标签保存在 y_train 中,训练数据的词袋表示保存在 X_train 中,因此我们可以在这个数据上训练一个分类器。对于这样的高维稀疏数据,类似 LogisticRegression 的线性模型通常效果最好。
我们首先使用交叉验证对 LogisticRegression 进行评估(细心的读者可能会注意到,我们这里违背了之前中关于交叉验证与预处理的内容。CountVectorizer 的默认设置实际上不会收集任何统计信息,所以我们的结果是有效的。对于应用而言,从一开始就使用 Pipeline 是更好的选择,但我们后面再这么做,这里是为了便于说明。):
python
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
scores = cross_val_score(LogisticRegression(), X_train, y_train, cv=5)
print("Mean cross-validation accuracy: {:.2f}".format(np.mean(scores)))Mean cross-validation accuracy: 0.88我们得到的交叉验证平均分数是 88%,这对于平衡的二分类任务来说是一个合理的性能。我们知道,LogisticRegression 有一个正则化参数 C ,我们可以通过交叉验证来调节它:
python
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10]}
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
print("Best parameters: ", grid.best_params_)Best cross-validation score: 0.89
Best parameters: {'C': 0.1}我们使用 C=0.01 得到的交叉验证分数是 89%。现在,我们可以在测试集上评估这个参数设置的泛化性能:
python
X_test = vect.transform(text_test)
print("{:.2f}".format(grid.score(X_test, y_test)))0.88下面我们来看一下能否改进单词提取。CountVectorizer 使用正则表达式提取词例。默认使用的正则表达式是 "\b\w\w+\b" 。如果你不熟悉正则表达式,它的含义是找到所有包含至少两个字母或数字(\w )且被词边界(\b )分隔的字符序列。它不会匹配只有一个字母的单词,还会将类似"doesn't"或"bit.ly"之类的缩写分开,但它会将"h8ter"匹配为一个单词。然后,CountVectorizer 将所有单词转换为小写字母,这样"soon""Soon"和"sOon"都对应于同一个词例(因此也对应于同一个特征)。这一简单机制在实践中的效果很好,但正如前面所见,我们得到了许多不包含信息量的特征(比如数字)。减少这种特征的一种方法是,仅使用至少在 2 个文档(或者至少 5 个,等等)中出现过的词例。仅在一个文档中出现的词例不太可能出现在测试集中,因此没什么用。我们可以用 min_df 参数来设置词例至少需要在多少个文档中出现过:
python
vect = CountVectorizer(min_df=5).fit(text_train)
X_train = vect.transform(text_train)
print("X_train with min_df: {}".format(repr(X_train)))X_train with min_df: <25000x27271 sparse matrix of type '<class 'numpy.int64'>'
with 3354014 stored elements in Compressed Sparse Row format>通过要求每个词例至少在 5 个文档中出现过,我们可以将特征数量减少到 27 271 个,正如上面的输出所示------只有原始特征的三分之一左右。我们再来查看一些词例:
python
feature_names = vect.get_feature_names_out()
print("First 50 features:\n{}".format(feature_names[:50]))
print("Features 20010 to 20030:\n{}".format(feature_names[20010:20030]))
print("Every 700th feature:\n{}".format(feature_names[::700]))First 50 features:
['00' '000' '007' '00s' '01' '02' '03' '04' '05' '06' '07' '08' '09' '10'
'100' '1000' '100th' '101' '102' '103' '104' '105' '107' '108' '10s'
'10th' '11' '110' '112' '116' '117' '11th' '12' '120' '12th' '13' '135'
'13th' '14' '140' '14th' '15' '150' '15th' '16' '160' '1600' '16mm' '16s'
'16th']
Features 20010 to 20030:
['repentance' 'repercussions' 'repertoire' 'repetition' 'repetitions'
'repetitious' 'repetitive' 'rephrase' 'replace' 'replaced' 'replacement'
'replaces' 'replacing' 'replay' 'replayable' 'replayed' 'replaying'
'replays' 'replete' 'replica']
Every 700th feature:
['00' 'affections' 'appropriately' 'barbra' 'blurbs' 'butchered' 'cheese'
'commitment' 'courts' 'deconstructed' 'disgraceful' 'dvds' 'eschews'
'fell' 'freezer' 'goriest' 'hauser' 'hungary' 'insinuate' 'juggle'
'leering' 'maelstrom' 'messiah' 'music' 'occasional' 'parking'
'pleasantville' 'pronunciation' 'recipient' 'reviews' 'sas' 'shea'
'sneers' 'steiger' 'swastika' 'thrusting' 'tvs' 'vampyre' 'westerns']数字的个数明显变少了,有些生僻词或拼写错误似乎也都消失了。我们再次运行网格搜索来看一下模型的性能如何:
python
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))Best cross-validation score: 0.89网格搜索的最佳验证精度还是 89%,这和前面一样。我们并没有改进模型,但减少要处理的特征数量可以加速处理过程,舍弃无用的特征也可能提高模型的可解释性。
如果一个文档中包含训练数据中没有包含的单词,并对其调用
CountVectorizer的transform方法,那么这些单词将被忽略,因为它们没有包含在字典中。这对分类来说不是一个问题,因为从不在训练数据中的单词中学不到任何内容。但对于某些应用而言(比如垃圾邮件检测),添加一个特征来表示特定文档中有多少个所谓"词表外"单词可能会有所帮助。为了实现这一点,你需要设置min_df,否则这个特征在训练期间永远不会被用到。
附录:
一、参考文献
参考文献:德 Andreas C. Müller 美 Sarah Guido 《Python Machine Learning Basics Tutorial》
二、网站的电影评论数据集数据下载界面
下载地址:Sentiment Analysis