基础概念
定义
树形结构模型:从根节点 开始,通过特征选择分支路径,最终到达叶子节点(决策结果)。
功能:适用于分类与回归任务。
组成结构
| 组件 | 作用 | 示例 |
|---|---|---|
| 根节点 | 首个特征选择点 | 数据集的初始划分特征 |
| 非叶子节点/分支 | 中间决策过程 | 根据特征值继续分支 |
| 叶子节点 | 最终决策结果 | 分类标签/回归值 |
训练与测试流程
训练阶段 :从训练集构造树结构(核心:特征选择与切分)。
测试阶段:新样本从根节点遍历至叶子节点,直接输出结果。
核心问题
关键难点 :如何选择每个节点的特征及切分方式?
解决思路 :通过量化指标衡量特征对分类结果的贡献,选择最优特征(如根节点选分类能力最强的特征)。
熵与信息增益
熵(Entropy)
定义:衡量随机变量的不确定性(数据混乱程度)。
公式:H(X)=−i=1∑npilog2pi
pi:第 i类样本在数据集中的占比。
熵的特性:
熵值越大 → 数据越混乱(不确定性高)。
熵值越小 → 数据越纯净(确定性高)。
示例:
集合 A [1,1,1,1,1,1,1,1,2,2]:熵值低(主要类别为1)。确定性高
集合 B [1,2,3,4,5,6,7,8,9,1]:熵值高(类别分散)。
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性
当p=0.5时,H(p)=1,此时随机变量的不确定性最大
信息增益
定义:特征 X使得类别 Y的不确定性减少的程度(提升分类"专一性")。
公式:Gain(D,A)=H(D)−H(D∣A)
H(D):划分前数据集的熵。
H(D∣A):按特征 A划分后的条件熵(加权平均子集熵)。
计算
特征:4种环境变化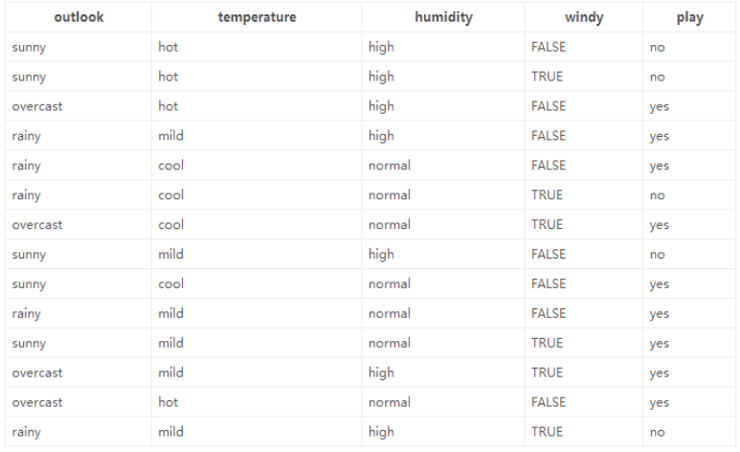
计算 信息增益最大的**假设为大当家(**与标签相关性最大的数据)其次为二当家,以此类推。
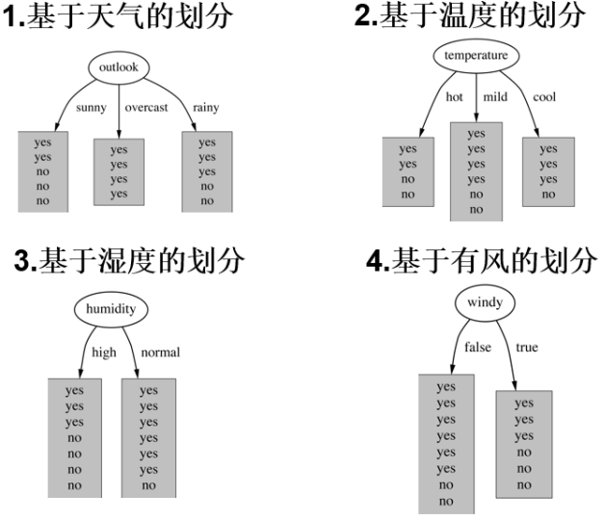
play混杂程度是最大的因此我们需要先计算play的熵值
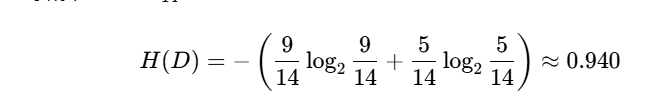
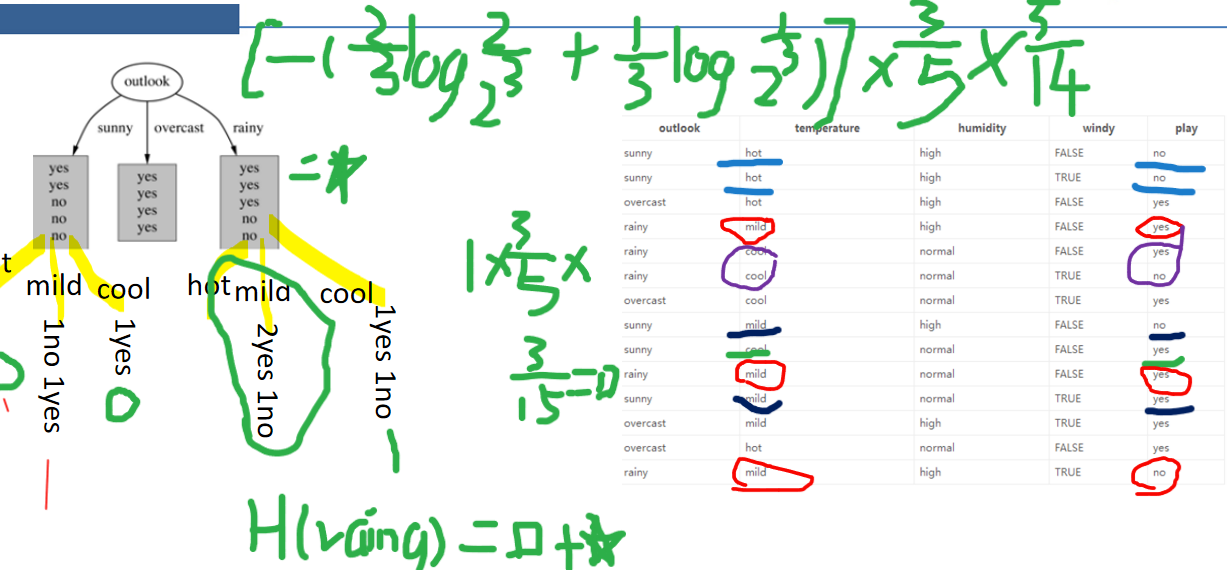
第一步:假设outlook为大当家,面有三种情况,为sunny,overcast,rainy
sunny:有5天其中两天是yes,3天是no(yes与no是看play中的之后的情况相同)
overcast:4天yes
rainy:3天yes2天no
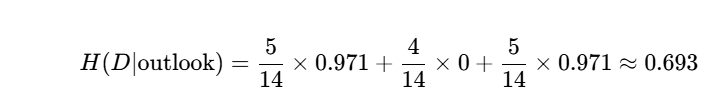
5/14是指sunny总天气在play中占的比例
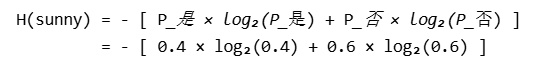
其中H(sunny)算出来就是0.971
以此类推算其它三个值用H(D)-H(其它三个算出的熵值),这就计算出来了它们各自的信息增益。
比较大小最大的为大当家。
第二步:算二当家的,是在算大当家的分类基础上在分类,比如outlook是大当家,我们计算temperature
这是我们的H(D)就为H(outlook)
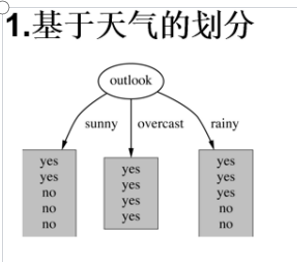
我们在已经分好的这个类中继续划分天气为sunny时temperature有三种情况hot、cool、mild
hot在有2no ; mild有1no、1yes ; cool有1yes