大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。

位置编码
在自然语音处理器中,输入的单词或者Token序列的顺序及其在句子中的位置非常重要。毕竟若单词重排序,整个句子含义会改变。
在实现 NLP的解决方案时,RNN具有处理序列顺序的内置机制。然而,基于Transformer的大模型不使用递归或卷积,而是将每个数据视为独立于其他的数据。因此,位置信息需要被显式添加到模型中,以保留有关句子中单词顺序的信息,而位置编码则是其中的解决方案。
位置编码描述序列中实体的位置或位置,以便为每个位置分配唯一的表示形式。在Transformer模型中,不使用单个数字(例如索引值)来表示项目的位置的原因有很多。对于长序列,索引的数值会变大。若将索引值归一化为介于 0 和 1 之间,则可能会对可变长度序列产生问题。
Transformer使用智能位置编码方案,其中每个位置/索引都映射到一个向量。因此每个输入经过位置编码层的输出是一个向量。整个序列就组成了一个矩阵,其中矩阵的每一行表示序列的一个编码对象。下图显示了仅对位置信息进行编码的矩阵示例。

上面的例子序列长度为4,模型的编码的维度为d维
在继续往下之前,先帮助大家温习下正弦函数和余弦函数,两者的取值范围是 -1,+1。该波形的频率是一秒钟内完成的周期数。波长是波形重复的距离。不同波形的波长和频率如下图所示。

Transformer中的位置编码算法如下。这里假设有一个长度为L的输入序列,并且需要求出kth对象在此序列中的位置编码。偶数位置对应于正弦函数,奇数位置对应于余弦函数。

这里k代表某个对象在序列中的位置 0≤k<L/2;d代表单词嵌入(embedding)之后的向量维度;P(k,j)代表位置函数;n代表超参数,最初的设置为10000;i为映射使用的索引,0≤i<d/2。
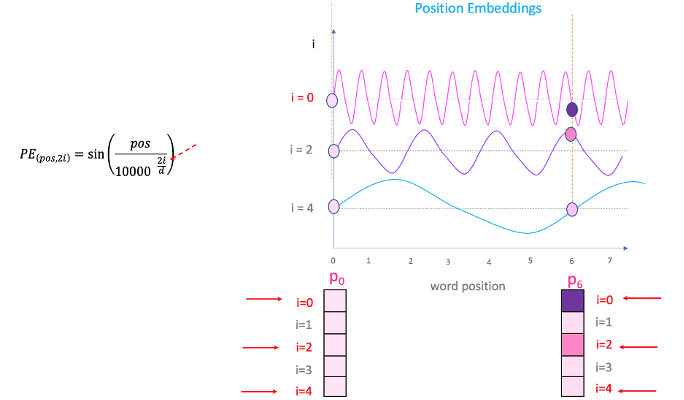
上图是从侧面来理解这种编码。还是刚才的例子,通过上面的公式可以求出每个位置的数值,每一行即为某个单词的位置编码。

其实这个位置编码是固定的,在已经知道L,n和d的前提下。因此可以画出可视化的位置编码矩阵图。

这里假定n=10000,L=100,d=512,颜色代表着1到-1的取值
下面为不同模型的位置编码矩阵图,当然最新的还出现了一种CoPE:


位置编码真的有用?
有篇论文做了一些实验,试图搞清楚位置嵌入到底学到了什么。

研究小组的目的在于搞清楚预训练的 Transformer 位置嵌入的隐含含义。Transformer 编码器在类似掩码语言建模(Bert)中能有效的学习到局部的位置信息。用于自回归语言建模的 Transformer 解码器实际上学习的是绝对位置。对预训练位置嵌入的实证实验验证了上面的假设。
研究还表明具有不同模型架构和不同训练目标的NLP任务以不同的方式利用位置信息。因此根据目标NLP任务中选择合适的编码函数将成为后续需要持续关注的地方。