Study by:
作用
如果你把数据库类比为一本书,那书的具体内容是数据,书的目录就是索引,所以索引的目的和作用,就是为了提高数据的查询效率。
和关系型数据库类似,MongoDB 中也有索引。如果没有索引的话,MongoDB 必须执行集合扫描 ,即扫描集合中的每个文档,以选择与查询语句匹配的文档。
如果查询存在合适的索引,MongoDB 可以使用该索引来限制它必须检查的文档数量。并且,MongoDB 可以使用索引中的排序返回排序后的结果。
虽然索引可以显著缩短查询时间,但是使用索引、维护索引是有代价的。在执行写入操作时,除了要更新文档之外,还必须更新索引,这必然会影响写入的性能。因此,当有大量写操作而读操作少时,或者不考虑读操作的性能时,都不推荐建立索引。
索引类型
MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
- 单字段索引: 建立在单个字段上的索引,索引创建的排序顺序无所谓,MongoDB 可以头/尾开始遍历。
- 复合索引: 建立在多个字段上的索引,也可以称之为组合索引、联合索引。
- 多键索引:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
- 哈希索引:按数据的哈希值索引,用在哈希分片集群上。
- 文本索引: 支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合只能有一个文本搜索索引,但该索引可以覆盖多个字段。MongoDB 虽然支持全文索引,但是性能低下,暂时不建议使用。
- 地理位置索引: 基于经纬度的索引,适合 2D 和 3D 的位置查询。
- 唯一索引:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
- TTL 索引:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
索引示例
MongoDB 使用 createIndex() 方法来创建索引。
createIndex() 方法基本语法格式如下所示:
db.collection.createIndex( keys, options )db:数据库的引用。 collection:集合的名称。 keys:一个对象,指定了字段名和索引的排序方向(1 表示升序,-1 表示降序)。
options:一个可选参数,可以包含索引的额外选项。 options 参数是一个对象,可以包含多种配置选项,以下是一些常用的选项:
unique:如果设置为 true,则创建唯一索引,确保索引字段的值在集合中是唯一的。 background:如果设置为
true,则索引创建过程在后台运行,不影响其他数据库操作。 name:指定索引的名称,如果不指定,MongoDB
会根据索引的字段自动生成一个名称。 sparse:如果设置为 true,创建稀疏索引,只索引那些包含索引字段的文档。
expireAfterSeconds:设置索引字段的过期时间,MongoDB 将自动删除过期的文档。 v:索引版本,通常不需要手动设置。
weights:为文本索引指定权重。
// 创建 age 字段的升序索引
db.myCollection.createIndex({ age: 1 });
// 创建 name 字段的文本索引
db.myCollection.createIndex({ name: "text" });-
索引创建:
// 创建唯一索引
db.collection.createIndex( { field: 1 }, { unique: true } )// 创建后台运行的索引
db.collection.createIndex( { field: 1 }, { background: true } )// 创建稀疏索引
db.collection.createIndex( { field: 1 }, { sparse: true } )// 创建文本索引并指定权重
db.collection.createIndex( { field: "text" }, { weights: { field: 10 } } )
创建地理空间索引
对于存储地理位置数据的字段,可以使用 2dsphere 或 2d 索引类型来创建地理空间索引。// 2dsphere 索引,适用于球形地理数据
db.collection.createIndex( { location: "2dsphere" } )// 2d 索引,适用于平面地理数据
db.collection.createIndex( { location: "2d" } ) -
创建哈希索引
从 MongoDB 3.2 版本开始,可以使用哈希索引对字段进行哈希,以支持大范围的数值查找。db.collection.createIndex( { field: "hashed" } )
-
查看索引
使用 getIndexes() 方法可以查看集合中的所有索引:db.collection.getIndexes()
-
删除索引
使用 dropIndex() 或 dropIndexes() 方法可以删除索引:// 删除指定的索引
db.collection.dropIndex( "indexName" )// 删除所有索引
db.collection.dropIndexes()
默认索引
在创建集合期间,MongoDB会在_id字段上创建唯一索引,用来防止客户端插入两个具有相同值的文档,我们也不能删除该默认索引,而通常我们在插入文档时,应该忽略该字段,让ObjectId对象来自动生成。
单例索引
MongoDB支持在文档的单个字段上创建自定义的升序/降序索引,称为------单列索引(Single Field Index),也可以称之为单字段索引。
-
在单列索引中,升序/降序并不影响查询性能。
// 为 age 字段创建索引
db.s1.createIndex({"age": 1})// 如下的查询将会走索引
db.s1.find({"age": {"$gt": 10}})
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea77"), "name" : "zhangkai", "age" : 18 }
{ "_id" : ObjectId("600fe7e79ab2f8c54a73ea78"), "name" : "likai", "age" : 20 }// 从执行计划中,查看是否走了索引
db.s1.find({"age": {"$gt": 10}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引扫描
"keyPattern" : {
"age" : 1
},
"indexName" : "age_1", // 使用的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"(10.0, inf.0]"
]
}
}
}
在嵌入式字段上创建单列索引
// 准备一个新的集合并插入数据
db.s1.drop()
db.s1.insertMany([
{"name": "zhangkai", "age": 18, "info": {"address": "beijing", "tel": "13011304424"}},
{"name": "likai", "age": 20, "info": {"address": "shanghai", "tel": "15011304424"}}
])
// 创建索引
db.s1.createIndex({"info.address": 1})
// 查询
db.s1.find({"info.address": "beijing"})
{ "_id" : ObjectId("600fec019ab2f8c54a73ea79"), "name" : "zhangkai", "age" : 18, "info" : [ { "address" : "beijing" }, { "tel" : "13011304424" } ] }
db.s1.find({"info.address": "beijing"}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引查询
"keyPattern" : {
"info.address" : 1
},
"indexName" : "info.address_1", // 使用的索引
"isMultiKey" : false,
"multiKeyPaths" : {
"info.address" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"info.address" : [
"[\"beijing\", \"beijing\"]"
]
}
}
}注意,当对嵌入式文档执行相等匹配时,字段顺序很重要,嵌入式文档必须完全匹配,才能返回结果。
另外,在嵌入式文档和嵌入式字段创建的索引不能混为一谈:
- 在嵌入式文档 上创建的索引,会对整个嵌入的文档进行索引,它是一个整体,查询时,要进行完全匹配。
- 在嵌入式字段 上创建的索引,只是对嵌入文档的指定字段进行索引,索引部分只包含嵌入文档的指定字段。
复合索引
MongoDB还支持多字段自定义索引,即复合索引(Compound Indexes),也可以称之为组合索引、联合索引。MongoDB中的复合索引在某些方面跟关系型数据库的组合索引是一样的,比如同样支持索引前缀。
复合索引中字段的顺序非常重要。
例如下图中的复合索引由{userid:1, score:-1}组成,则该复合索引首先按照userid升序排序;然后再每个userid的值内,再按照score降序排序。
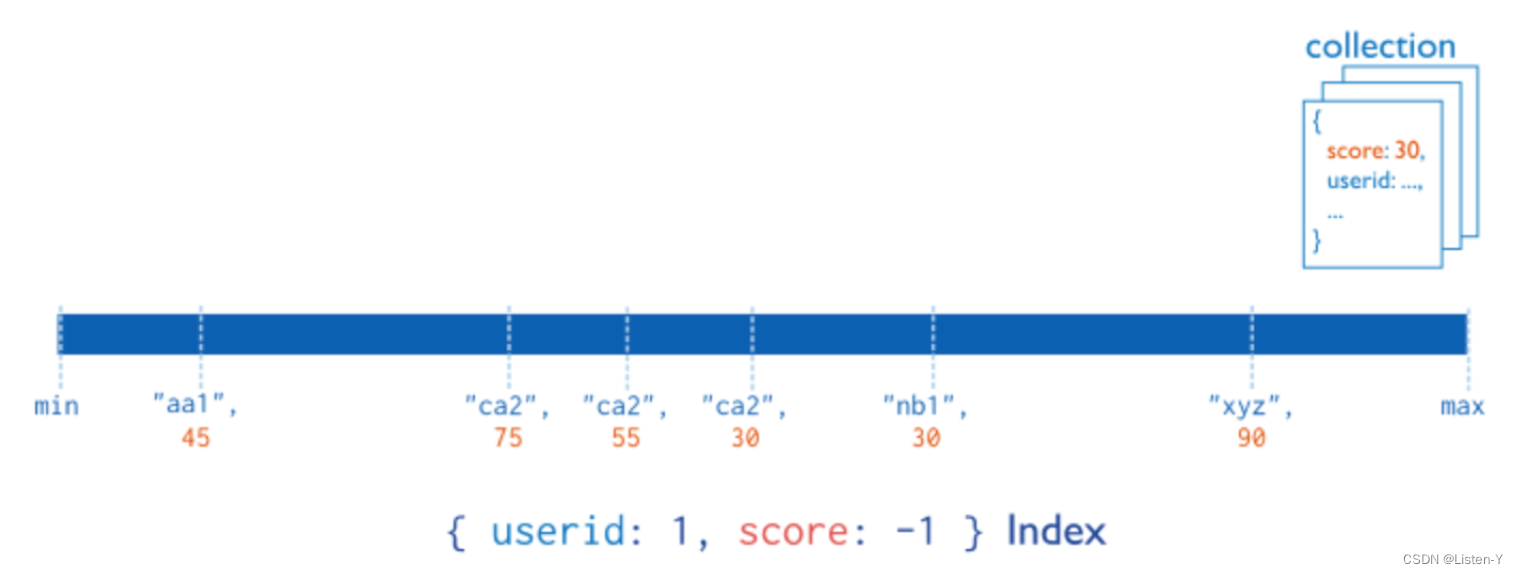
在复合索引中,按照何种方式排序,决定了该索引在查询中是否能被应用到。
-
走复合索引的排序:
db.s2.find().sort({"userid": 1, "score": -1})
db.s2.find().sort({"userid": -1, "score": 1}) -
不走复合索引的排序:
db.s2.find().sort({"userid": 1, "score": 1})
db.s2.find().sort({"userid": -1, "score": -1})
db.s2.find().sort({"score": 1, "userid": -1})
db.s2.find().sort({"score": 1, "userid": 1})
db.s2.find().sort({"score": -1, "userid": -1})
db.s2.find().sort({"score": -1, "userid": 1}) -
我们可以通过 explain 进行分析:
db.s2.find().sort({"score": -1, "userid": 1}).explain()
复合索引与索引前缀
复合索引同样支持对索引前缀的查询,例如,考虑以下复合索引:
// 三个字段的复合索引
{"userid": 1, "socore": 1, "age": 1}
// 上面的复合索引有以下索引前缀
{"userid": 1}
{"userid": 1, "score": 1}在以下情况的查询走索引:
-
userid
-
userid + score
-
userid + score + age。
-
userid + age,尽管索引被使用,但效率不高。
// 为了避免混淆,先清空索引
db.s2.dropIndexes()
// 创建索引
db.s2.createIndex({"userid": 1, "socore": 1, "age": 1}, {"name": "compoundIndex2"})// userid 走索引
db.s2.find({"userid": {"$lt": 3}}).explain()// userid + score 走索引
db.s2.find({"userid": {"lt": 3}, "score": {"lt": 98}}).explain()// userid + score + age 走索引
db.s2.find({"userid": {"lt": 3}, "score": {"lt": 98}, "age": {"$lt": 30}}).explain()// userid + age 走索引
db.s2.find({"userid": {"lt": 3}, "age": {"lt": 30}}).explain()
以下情况不走索引:
-
score。
-
age。
-
score + age。
// score 不走索引
db.s2.find({"score": {"$lt": 98}}).explain()// age 不走索引
db.s2.find({"age": {"$lt": 30}}).explain()// score + age 不走索引
db.s2.find({"score": {"lt": 98}, "age": {"lt": 30}}).explain()
多键索引
对于包含数组的文档,我们可以使用MongoDB提供了多键索引,为数组中的每个元素创建一个索引键,这些多键索引支持对数组字段的有效查询。
// 准备集合并插入数据
db.s3.drop()
db.s3.insertMany([
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ]},
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ]},
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ]},
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] },
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ]}
])
// 基于ratings字段创建多键索引
db.s3.createIndex({ratings:1})基于一个数组创建索引,MongoDB会自动创建为多键索引,无需刻意指定,另外,多键索引不等于复合索引。
地理空间索引
为了支持对于地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:
- 返回结果时使用平面几何的二维索引。
- 返回结果时使用球面几何的二维索引。
文本索引
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。
这些文本索引不存储特定语言的停用词(例如the、a、or),而是将集合中的词作为词干,只存储词根。
哈希索引
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引,这些索引在其范围内的值分布更加随机,但支持相等匹配,不支持基于范围的查询。
唯一索引
唯一索引(Unique Indexes)可确保索引字段不会存储重复值;即对索引字段实施唯一性。默认情况下,MongoDB 在创建集合时会在_id字段上创建唯一索引。
-
创建唯一索引
// 创建单列唯一索引
// unipue:true声明普通单列索引为唯一索引
db.userinfo.createIndex({"user": 1}, {"unique": true})// 复合索引中的添加唯一属性
db.userinfo.createIndex({"user": 1, "tel": 1}, {"unique": true})// 多键索引中添加唯一属性
db.userinfo.createIndex({"info.address": 1, "info.tel": 1}, {"unique": true})
唯一索引的一些限制
-
对于那些已经存在的非唯一的列,在其上面创建唯一索引将失败
-
对于数组类型的key,相同的值只能插入一次:
// 插入数据
db.s10.insert({"info": [{"tel": 13011303330}]})// 创建唯一索引
db.s10.createIndex({"info.tel": 1}, {"unique": true})// 再次插入相同的值,就报错了
db.s10.insert({"info": [{"tel": 13011303330}]})
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: t1.s10 index: info.tel_1 dup key: { : 13011303330.0 }"
}
}) -
MongoDB只允许一篇文档缺少索引字段
// 插入数据,成功
db.s10.insert({"name": "zhangkai"})// 创建唯一索引,成功
db.s10.createIndex({"name": 1}, {"unique": true})// 插入重复则报错,符合预期
db.s10.insert({"name": "zhangkai"}) // "errmsg" : "E11000 duplicate key error collection: t1.s10 index: name_1 dup key: { : "zhangkai" }"// 插入一个缺少 name 字段的文档,可以成功
db.s10.insert({"age": 18}) // mongodb会默认为 name 字段设置为null// 再次插入缺少 name 字段的文档,就会失败,因为mongodb只允许一篇文档缺少索引字段
db.s10.insert({"age": 20}) // "errmsg" : "E11000 duplicate key error collection: t1.s10 index: name_1 dup key: { : null }" -
不能对哈希索引指定唯一约束
稀疏索引
稀疏索引也叫做间隙索引,它只包含含有索引字段的文档,如果某个文档的不存在索引键,则跳过,所以,这种索引被称之为稀疏索引。
创建稀疏索引
// 准备数据
db.s11.insertMany([
{"name": "zhangkai"},
{"name": "likai", "score": 95},
{"name": "wangkai", "score": 92},
])
// 在创建索引时,指定 sparse:true 将普通索引标记为稀疏索引
db.s11.createIndex({"score": 1}, {"sparse": true})
// 通过查询语句的执行计划,查看稀疏索引的应用情况
db.s11.find({"score": {"$lt": 95}})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
db.s11.find({"score": {"$lt": 95}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH", // 根据索引检索指定的文档
"inputStage" : {
"stage" : "IXSCAN", // 使用了索引扫描
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1", // 索引名称
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : true, // 索引类型是稀疏索引
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[-inf.0, 95.0)"
]
}
}
}再来看稀疏索引无法使用的示例:
db.s11.find().sort({"score": 1})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f2"), "name" : "zhangkai" }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().sort({"score": 1}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "SORT",
"sortPattern" : {
"score" : 1
},
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
"inputStage" : {
"stage" : "COLLSCAN", // 全集合扫描
"direction" : "forward"
}
}
}我们也可以强制使用稀疏索引:
// hint 明确指定索引
db.s11.find().sort({"score": 1}).hint({"score": 1})
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().hint({"score": 1}) // 跟上一条语句的返回结果一致
{ "_id" : ObjectId("600fb8d164bc3da87653e9f4"), "name" : "wangkai", "score" : 92 }
{ "_id" : ObjectId("600fb8d164bc3da87653e9f3"), "name" : "likai", "score" : 95 }
db.s11.find().hint({"score": 1}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : true,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[MinKey, MaxKey]"
]
}
}
}
// 当然,如果你要对文档进行计数时,不要使用 hint 和稀疏索引
db.s11.count()
->3
db.s11.find().hint({"score": 1}).count()
->2部分索引
部分索引(Partial Indexes)是MongoDB3.2版本中的新功能,也叫做局部索引。
部分索引仅索引集合中符合指定过滤器表达式的文档,且由于部分索引是集合的子集,所以部分索引具有较低的存储需求,并降低了索引创建和维护的性能成本。部分索引通过指定过滤条件来创建,可以为MongoDB支持的所有索引类型使用部分索引。
部分索引中常用的过滤器表达式
- 等式表达式,$eq
- $exists
- 大于小于等于系列
- $type
- and
创建部分索引
// 准备数据
db.s12.insertMany([
{"name": "zhangkai", "score": 85},
{"name": "likai", "score": 95},
{"name": "wangkai", "score": 92},
{"name": "zhangkai1", "score": 87},
{"name": "likai1", "score": 97},
{"name": "wangkai1", "score": 99},
{"name": "zhangkai2", "score": 25},
{"name": "likai2", "score": 45},
{"name": "wangkai2", "score": 32},
])
// 创建部分索引
db.s12.createIndex(
{"score": 1},
{
"partialFilterExpression": {
"score":{
"$gte": 60
}
}
})
// 只有当查询条件大于等于60的时候,才走部分索引
db.s12.find({"score": {"$gte": 60}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN", // 走了索引
"keyPattern" : {
"score" : 1
},
"indexName" : "score_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"score" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"score" : [
"[60.0, inf.0]"
]
}
}
}
// 下面示例,不会走部分索引
db.s12.find({"score": {"$gt": 59}}).explain()["queryPlanner"]["winningPlan"]
{
"stage" : "COLLSCAN", // 全集合扫描
"filter" : {
"score" : {
"$gt" : 59
}
},
"direction" : "forward"
}再来看部分索引和唯一索引同时使用时的一些现象:
db.s12.remove({})
db.s12.insertMany([
{"name": "zhangkai", "score": 85},
{"name": "likai", "score": 95}
])
db.s12.createIndex(
{"name": 1},
{
"unique": true,
"partialFilterExpression": {
"score": {
"$gt": 60
}
}
}
)
// 插入 name 值相同的文档, 报错,不允许插入
db.s12.insert({"name": "zhangkai", "score": 77}) // "errmsg" : "E11000 duplicate key error collection: t1.s12 index: name_1 dup key: { : \"zhangkai\" }"
// 以下几种情况允许插入
db.s12.insertMany([
{"name": "zhangkai", "score": 30}, // name 值重复,score 值小于部分索引限制
{"name": "zhangkai", "score": null}, // name 值重复,score 值为 null
{"name": "zhaokai"}, // 忽略 score 字段
])
// 文档已存在,再插入就报错
db.s12.insert({"name": "zhangkai", "score": 85}) // score值大于部分索引限制,校验 name 唯一性
// score 值小于部分索引,允许插入重复 name 值
db.s12.insert({"name": "zhaokai", "score": 30})
// name 值不重复,score值重复,允许插入
db.s12.insert({"name": "sunkai", "score": 70}) 由上例的测试结果可以发现,当对唯一索引添加部分索引时,插入时检查部分索引字段的唯一性,什么意思呢?如上例的索引,它只对于score值大于等于60的文档,才去校验name的唯一性,同时允许姓名不同,score值相同的文档插入。
部分索引和稀疏索对比
-
部分索引主要是针对那些满足条件的文档(非字段缺失)创建索引,比稀疏索引提供了更具有表现力。
-
稀疏索引是文档上某些字段的存在与否,存在则为其创建索引,否则该文档没有索引键。
TTL索引
TTL(Time To Live)索引是特殊的单列索引,通过在创建索引时指定expireAfterSeconds参数将普通的单列索引标记为TTL索引,实现为文档的自动过期删除功能。TTL 索引除了有 expireAfterSeconds 属性外,和普通索引一样。
- MongoDB会开启一个后台线程读取该TTL索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程每60秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间60秒以上的现象。
- 对于副本集而言,TTL索引的后台进程只会在primary节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的oplog来做同步。
- TTL索引除了有expireAfterSeconds属性外,和普通索引一样。
- 应用场景:为所有插入的文档指定一个统一的过期时间。指定具体的过期时间,后续插入的记录都会在expireAfterSeconds指定的时间(单位:秒)后自动删除
- TTL索引的使用限制
- TTL索引只支持单例索引,复合索引不支持TTL。
- _id字段不支持TTL索引。
- 无法在上限集合上创建TTL索引,因为MongoDB无法从上限集合中删除文档。
- 如果某个字段已经存在非TTL索引,那么在该字段上无法再创建TTL索引。
覆盖查询
覆盖查询是一种查询现象。
根据官方文档介绍,覆盖查询是以下的查询:
- 所有的查询字段是索引的一部分。
- 结果中返回的所有字段都在同一索引中。
- 查询中没有字段等于null。
当查询条件和查询的投影仅包含索引字段时,MongoDB会直接从索引中返回结果,而不扫描任何文档或者将文档带入内存,这样的查询性能非常高。

如上图,如果对score字段建立了索引,查询时只返回score字段,这就会触发覆盖索引,即查询结果来自于索引,而不走文档集。
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom",
"user_name": "hello"
}我们在 users 集合中创建联合索引,字段为 gender 和 user_name
db.users.ensureIndex({gender:1,user_name:1})现在,该索引会覆盖以下查询:
db.users.find({gender:"M"},{user_name:1,_id:0})为了让指定的索引覆盖查询,必须显式地指定 _id: 0 来从结果中排除 _id 字段,因为索引不包括 _id 字段。
策略与优化
索引虽然可以提高查询性能,但也会增加写操作的开销。因此,在创建索引时需要权衡查询性能和写入性能。
索引会占用额外的存储空间,特别是对于大型数据集,需要考虑索引的存储成本。通过合理地设计和使用索引,可以大大提高 MongoDB 数据库的查询性能和响应速度,从而更好地支持应用程序的需求。
而且MongoDB的索引是存储在运行内存(RAM)中的,所以必须确保索引的大小不超过内存的限制。如果索引的大小超过了运行内存的限制,MongoDB会删除一些索引,这将导致性能下降。
在创建索引时,需要考虑以下因素:
- 查询频率:优先考虑那些经常用于查询的字段。
- 字段基数:字段值的基数越高(即唯一值越多),索引的效果越好。
- 索引大小:索引的大小会影响数据库的内存占用和查询性能。
- 一个集合中索引数量不能超过64个。
- 索引名的长度不能超过128个字符。
- 一个复合索引最多可以有31个字段。
- MongoDB的索引在部分查询条件下是不会生效的。
- 正则表达式及非操作符,如 n i n , nin, nin,not , 等。
- 算术运算符,如 $mod, 等。
- $where自定义查询函数。
在对索引进行优化时,可以考虑以下方法:
- 选择合适的索引类型:根据查询需求选择合适的索引类型。
- 创建复合索引:对于经常一起使用的字段,考虑创建复合索引以提高查询效率。
- 监控索引性能:定期监控索引的使用情况,根据实际需求调整索引。