使用缓存时,先操作数据库 or 先操作缓存?谈谈你的见解。
如何上面是一道面试题,你要如何回答,一个去团团面试的同学回来告诉我,一个问题带出一串问题,回答不好,直接作废,换句话说,刷面试题的同学要注意了,要一串一串的刷,把相关连的问题串起来,如果只是单个问题,你会很快暴露。
在使用缓存的场景中,先操作数据库还是先操作缓存取决于具体的业务需求和性能目标。以下是两种常见的策略:
- 先操作数据库,再操作缓存:
- 优点:确保数据的一致性和准确性。当数据更新时,首先更新数据库,然后更新缓存,这样可以保证缓存中的数据总是与数据库同步。
- 缺点:在高并发场景下,可能会因为缓存更新操作的延迟导致短暂的数据不一致问题。
- 适用场景:对数据一致性要求较高的场景,如金融交易、订单处理等。
- 先操作缓存,再操作数据库:
- 优点:提高系统性能和响应速度。当数据读取时,首先从缓存中获取数据,这样可以减少对数据库的直接访问,降低数据库的压力。
- 缺点:如果操作缓存成功但数据库操作失败,会导致缓存与数据库的数据不一致。
- 适用场景:对性能要求较高,可以容忍短暂的数据不一致的业务场景,如内容展示、用户信息展示等。
两种方法各有优缺点,V 哥来具体分析一下(部分内容来自网络):
先操作数据库
假如有两个并发的请求,一个写请求,一个读请求,流程如下:
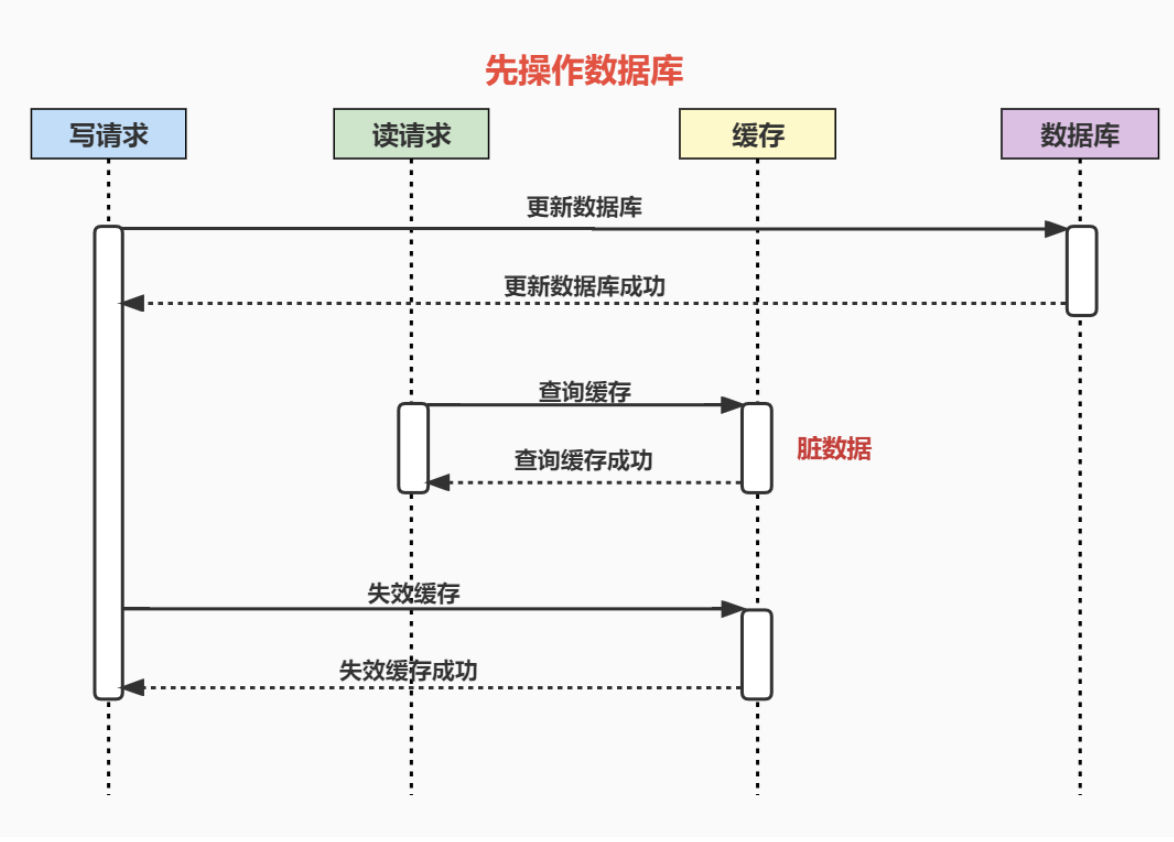
可能存在的脏数据时间范围:更新数据库后,失效缓存前。这个时间范围很小,通常不会超过几毫秒。
先操作缓存
假如有两个并发的请求,一个写请求,一个读请求,流程如下:
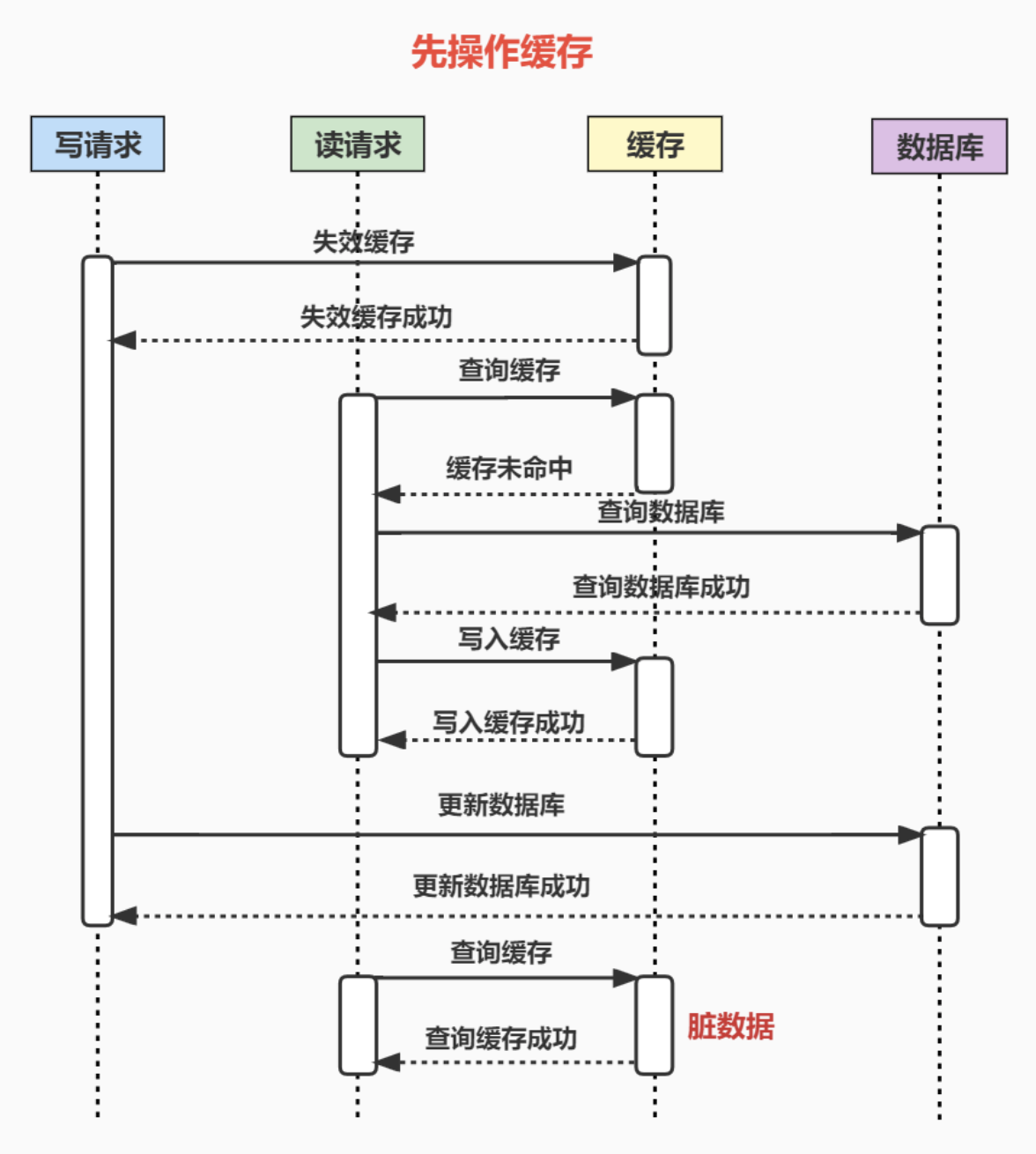
可能存在的脏数据时间范围:更新数据库后,下一次对该数据的更新前。这个时间范围不确定性很大,情况如下:
- 如果下一次对该数据的更新马上就到来,那么会失效缓存,脏数据的时间就很短。
- 如果下一次对该数据的更新要很久才到来,那这期间缓存保存的一直是脏数据,时间范围很长。
结论:通过上述案例可以看出,先操作数据库和先操作缓存都会存在脏数据的情况。但是相比之下,先操作数据库,再操作缓存是更优的方式,即使在并发极端情况下,也只会出现很小量的脏数据。
让缓存失效,而不是更新缓存
先来看更新缓存的案例:
有两个并发的写请求,流程如下:
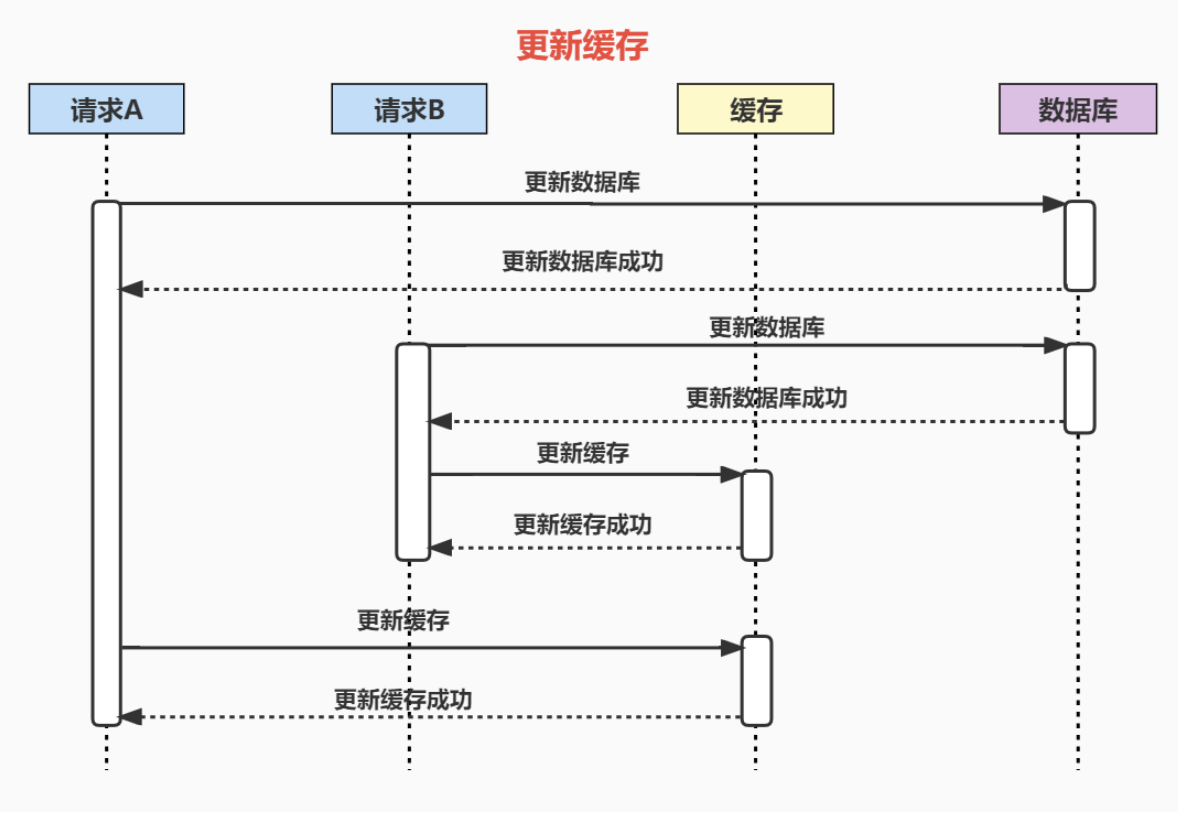
分析:数据库中的数据是请求B的,缓存中的数据是请求A的,数据库和缓存存在数据不一致。
再来看失效(删除)缓存的案例:
有两个并发的写请求,流程如下:
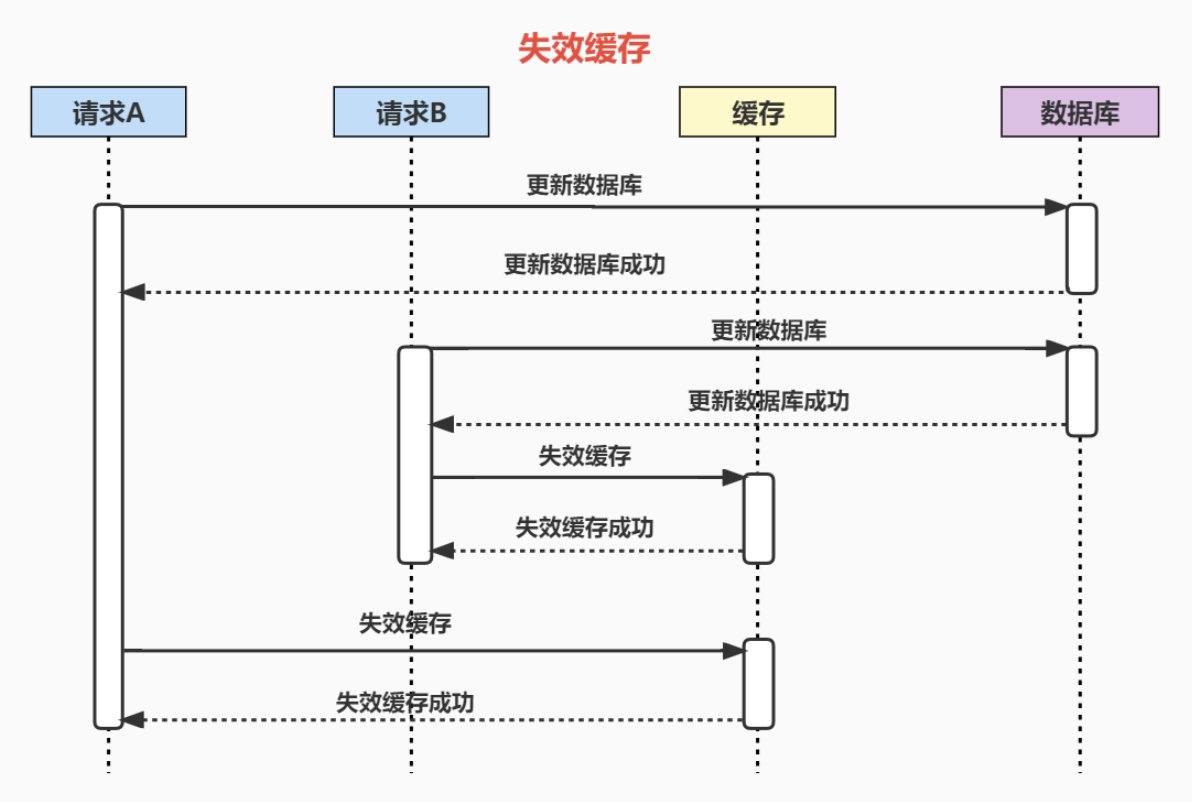
分析:由于是删除缓存,所以不存在数据不一致的情况。
结论:通过上述案例,可以很明显的看出,失效缓存是更优的方式。
如何保证数据库和缓存的数据一致性?
上面的案例中,无论是先操作数据库,还是先操作缓存,都会存在脏数据的情况,有办法避免吗?
答案是有的,由于数据库和缓存是两个不同的数据源,要保证其数据一致性,其实就是典型的分布式事务场景,可以引入分布式事务来解决,常见的有:2PC、TCC、MQ事务消息等。
但是引入分布式事务必然会带来性能上的影响,这与我们当初引入缓存来提升性能的目的是相违背的。
所以在实际使用中,通常不会去保证缓存和数据库的强一致性,而是做出一定的牺牲,保证两者数据的最终一致性。
如果是实在无法接受脏数据的场景,则比较合理的方式是放弃使用缓存,直接走数据库。
保证数据库和缓存数据最终一致性的常用方案如下:
- 更新数据库,数据库产生 binlog。
- 监听和消费 binlog,执行失效缓存操作。
- 如果步骤2失效缓存失败,则引入重试机制,将失败的数据通过MQ方式进行重试,同时考虑是否需要引入幂等机制。
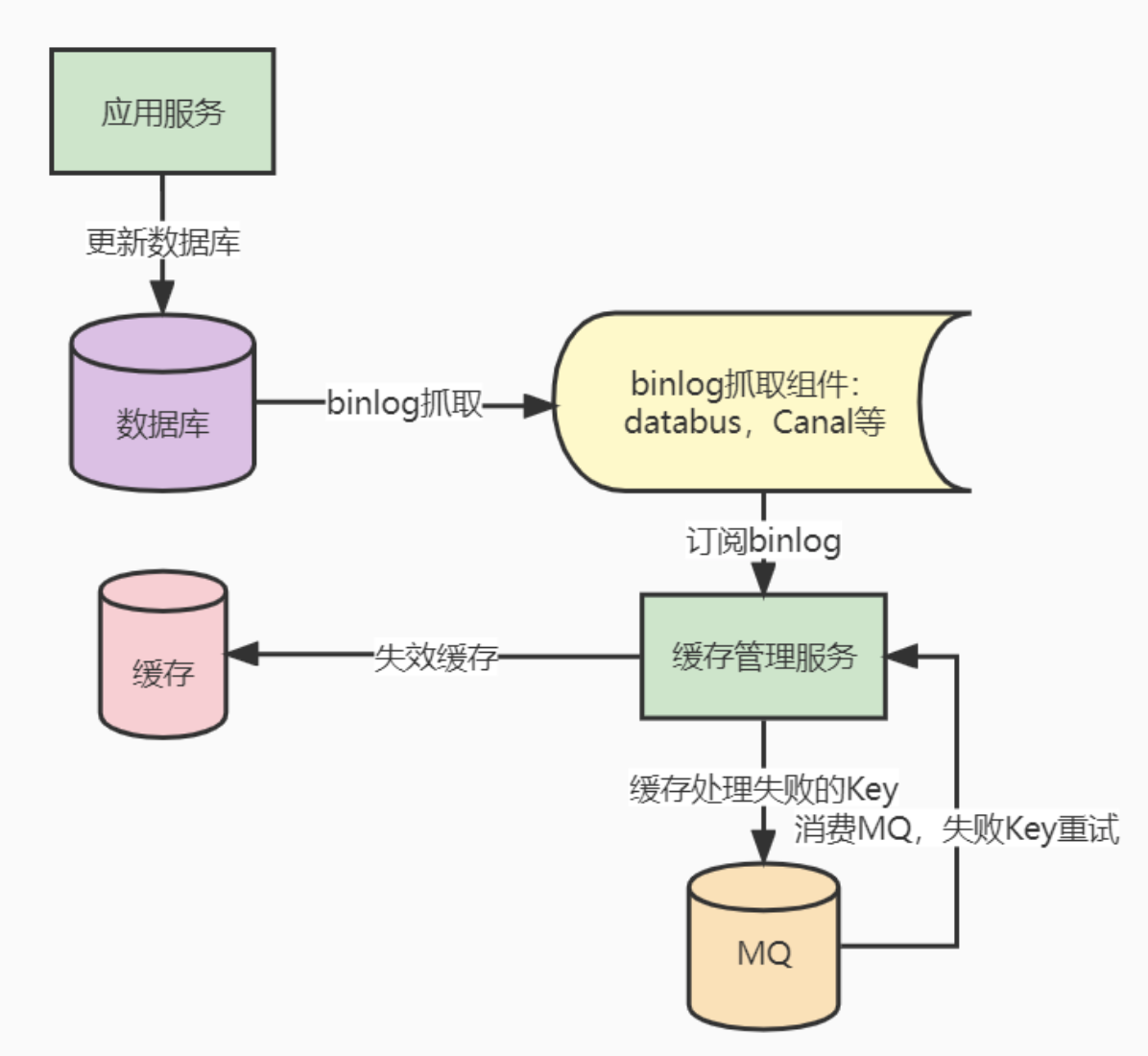
兜底:当出现未知的问题时,及时告警通知,人为介入处理。
人为介入是终极大法,那些外表看着光鲜艳丽的应用,其背后大多有一群苦逼的程序员,在不断的修复各种脏数据和bug。
小结一下
在某些情况下,让缓存失效而不是更新缓存是一种常见的做法,主要基于以下几个原因:
-
复杂性:更新缓存可能涉及到复杂的逻辑,特别是当缓存的数据结构和数据库中的数据结构不一致时。让缓存失效则简单得多,只需删除缓存项。 -
一致性:在分布式系统中,保持缓存和数据库之间的一致性可能非常复杂。如果系统中有多个缓存节点,更新所有节点的缓存以保证一致性可能代价很高。让缓存失效可以确保所有节点在下一次请求时从数据库获取最新的数据。 -
性能:更新缓存可能涉及到多个步骤,如读取旧值、计算新值、写入新值等,这可能会增加系统的延迟。让缓存失效后,直接从数据库读取数据,虽然可能会增加数据库的负载,但可以减少缓存更新的复杂性和潜在的延迟。 -
容错性:在某些情况下,更新缓存可能会失败,导致缓存中的数据不一致。让缓存失效是一种更安全的策略,因为它减少了失败的可能性。 -
缓存穿透:如果一个不存在的数据被频繁查询,更新缓存意味着每次查询都会去数据库查找,这可能导致数据库的负载增加。让缓存失效可以避免这种情况,通过设置一个短暂的过期时间,可以减少对数据库的压力。 -
数据变更频率:如果数据变更非常频繁,频繁更新缓存可能导致缓存命中率降低,从而降低缓存的效率。在这种情况下,让缓存失效可以提高缓存的效率。 -
缓存过期策略:许多缓存系统已经内置了过期策略,这意味着缓存项会在一定时间后自动失效。利用这一特性,可以让缓存失效成为一种自然而有效的更新机制。 -
简化设计:让缓存失效可以简化系统设计,因为开发者不需要考虑缓存数据的更新逻辑,只需要处理缓存失效后的逻辑即可。
所以让缓存失效是一种简单、有效且安全的策略,尤其适用于那些对数据一致性要求不是特别高、数据变更频繁或者系统设计需要简化的场景。然而,这并不意味着更新缓存没有用武之地,在某些需要保证数据实时性和一致性的场景下,更新缓存仍然是必要的。