一、JDK不兼容:
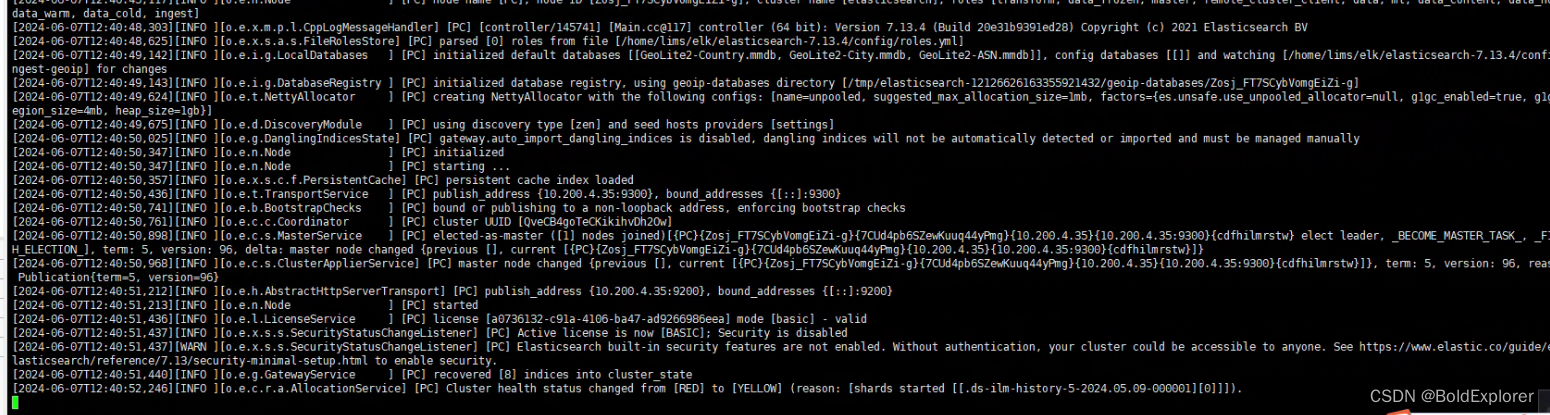
es和jdk是一个强依赖的关系,所以当我们在新版本的ElasticSearch压缩包中包含有自带的jdk,但是当我们的Linux中已经安装了jdk之后,就会发现启动es的时候优先去找的是Linux中已经装好的jdk,此时如果jdk的版本不一致,就会造成jdk不能正常运行,报错如下

如果Linux服务本来没有配置jdk,则会直接使用es目录下默认的jdk,反而不会报错。
解决方法:
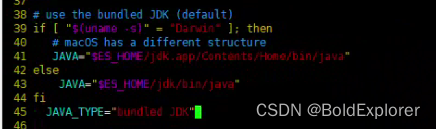
进入bin目录,修改elasticsearch-env配置
修改前:

修改为:
启动:

二、系统虚拟内容不足
原因: 系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
启动报错如下:

编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=262144
保存后,执行:
sysctl -p
重新启动,成功。