- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
🏡我的环境:
- 语言环境:Python3.11.4
- 编译器:Jupyter Notebook
- torcch版本:2.0.1
python
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, hid_dim, n_heads, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads
# hid_dim必须整除
assert hid_dim % n_heads == 0
# 定义wq
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定义wk
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定义wv
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim//n_heads]))
def forward(self, query, key, value, mask=None):
# Q与KV在句子长度这一个维度上数值可以不一样
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 将QKV拆成多组,方案是将向量直接拆开了
# (64, 12, 300) -> (64, 12, 6, 50) -> (64, 6, 12, 50)
# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)
# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)
# 第1步,Q x K / scale
# (64, 6, 12, 50) x (64, 6, 50, 10) -> (64, 6, 12, 10)
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# 需要mask掉的地方,attention设置的很小很小
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
# 第2步,做softmax 再dropout得到attention
attention = self.do(torch.softmax(attention, dim=-1))
# 第3步,attention结果与k相乘,得到多头注意力的结果
# (64, 6, 12, 10) x (64, 6, 10, 50) -> (64, 6, 12, 50)
x = torch.matmul(attention, V)
# 把结果转回去
# (64, 6, 12, 50) -> (64, 12, 6, 50)
x = x.permute(0, 2, 1, 3).contiguous()
# 把结果合并
# (64, 12, 6, 50) -> (64, 12, 300)
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x
query = torch.rand(64, 12, 300)
key = torch.rand(64, 10, 300)
value = torch.rand(64, 10, 300)
attention = MultiHeadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
print(output.shape)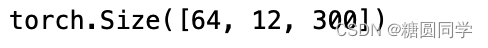
多头注意力机制拓展了模型关注不同位置的能力,赋予Attention层多个"子表示空间"。