这边整理下Kafka三大主要组件Producer原理。
目录
一、Producer发送消息源码流程
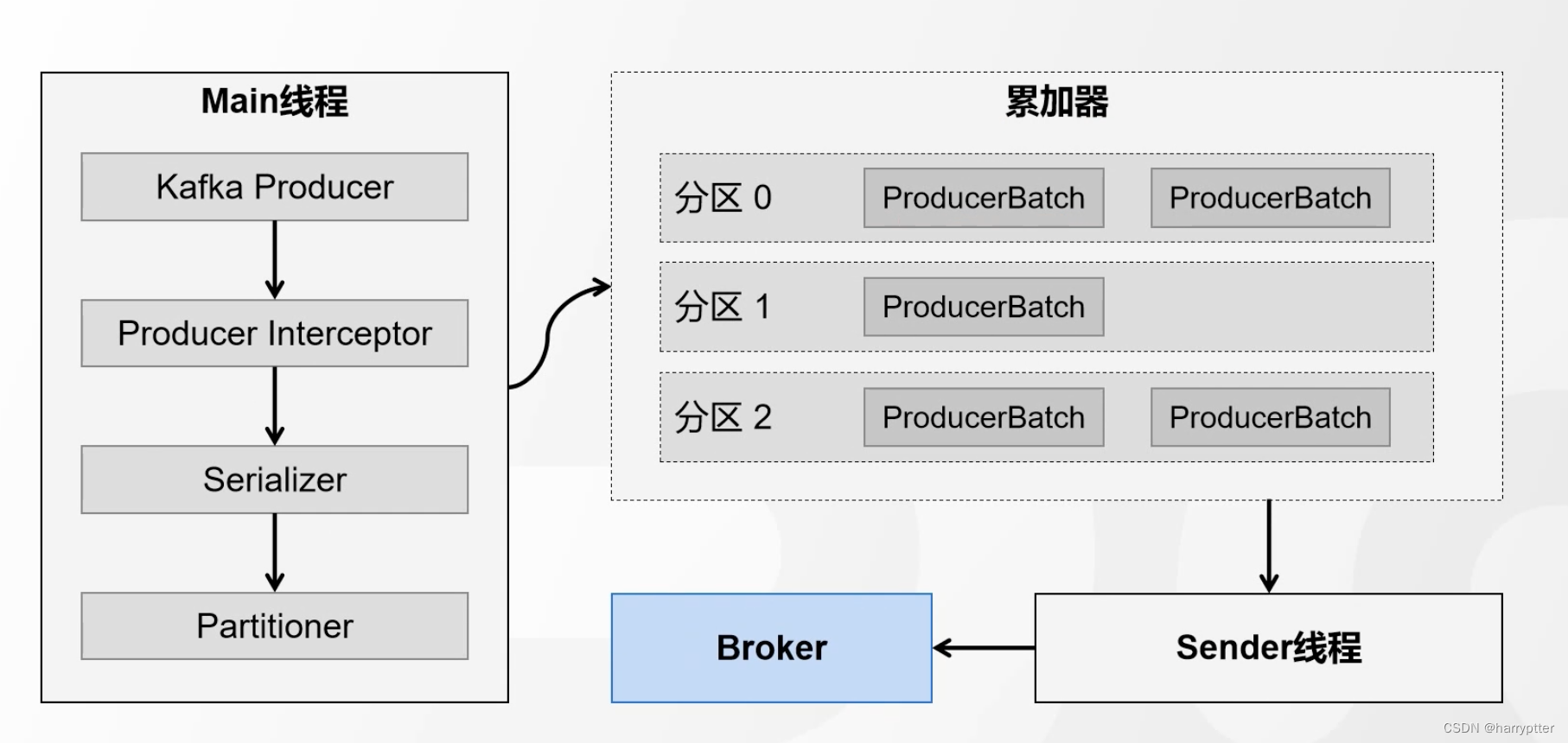
Producer发送消息流程如上图。主要是用了两个线程,主线程中生成消息经过拦截器之后,在序列化器中将消息的K,V序列化,在到分区器中分配对应的分区之后放入累加器。
当消息在累加器中批次满了,或者创建了新的累加batch就会唤起Sender线程将消息发送到Broker中。
这其中在分区器中配置分区的规则有以下四个逻辑:
1.消息定义了分区,就用消息指定的分区
2.消息没有定义分区,但是使用了自定义分区器,那么就走自定义分区器里面的选择分区的逻辑
3.消息没有定义分区,也没有使用自定义分区器,key不为空,那么就会走hash取模算法,会用key的hash值和分区器数量进行取模计算得到对应的分区器
4.以上都不符合的话,就走粘连策略得到最终的分区。
二、ACK应答机制和ISR机制
1)ACK应答机制
生产者Producer向Broker发送消息,明显是需要有个应答ACK来知道Broker是否收到消息的。所以Kafka提供了三种等级的Ack应答机制。可以根据可靠性和延迟的要求进行选择
1.acks=0 :broker一收到消息,就返回Ack应答
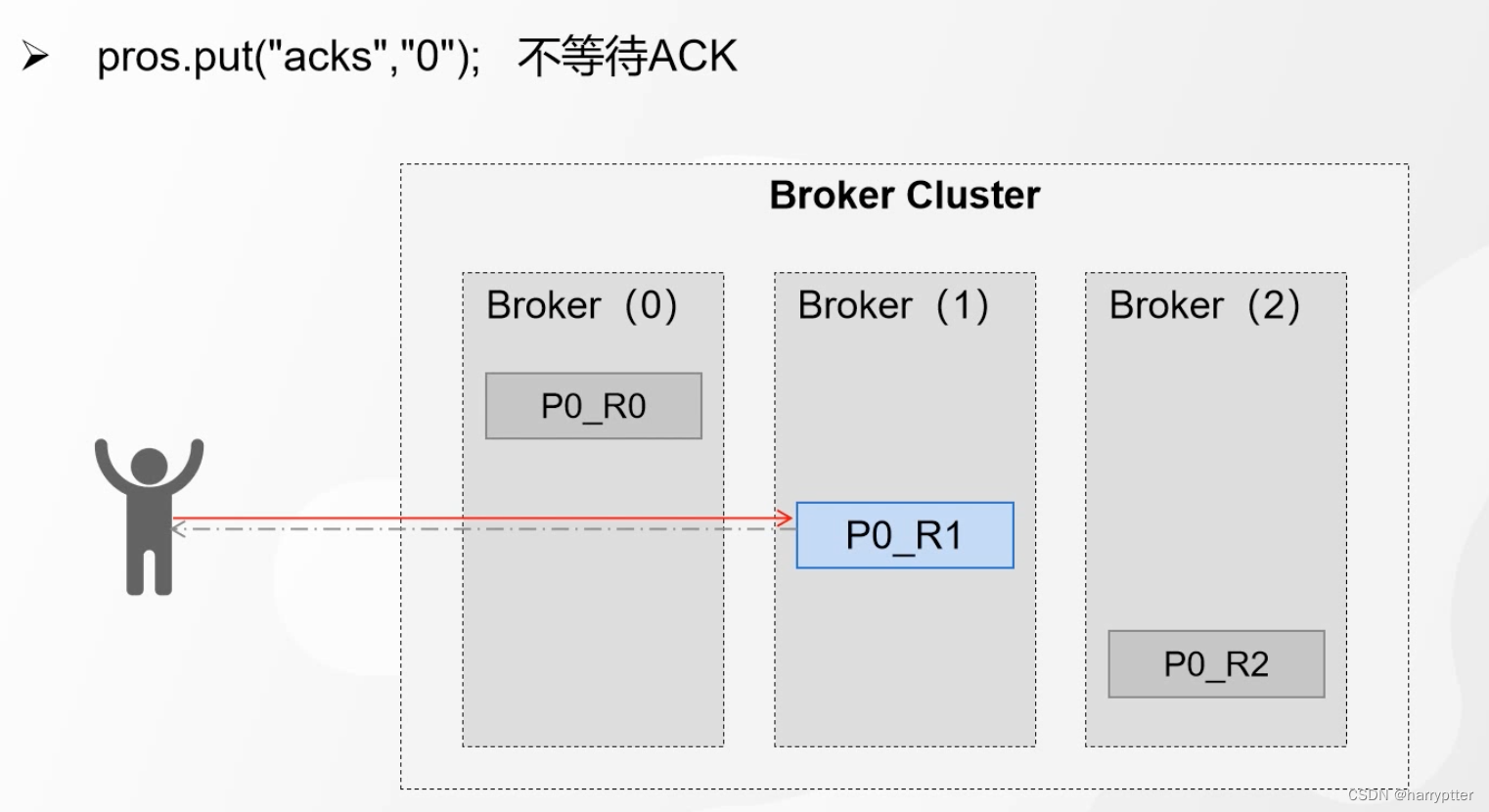
但这种模式明显会有一个问题就是leader落盘失败的话,发送的消息就都没有用了,如下图
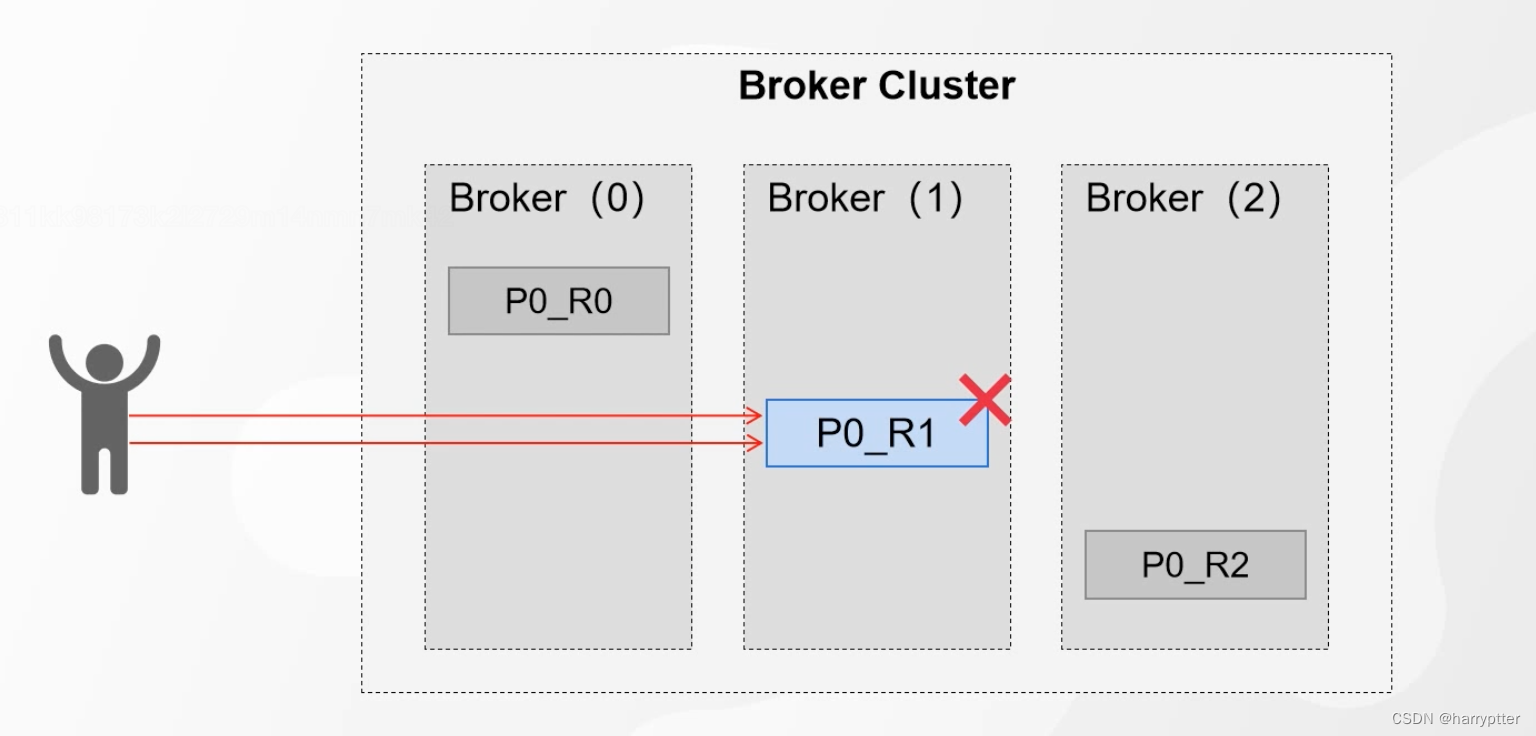
要保证可靠性就有了第二种模式。
2.acks=1 : broker收到消息,并且leader分区落盘之后,返回Ack应答。(Kafka默认应答机制级别)
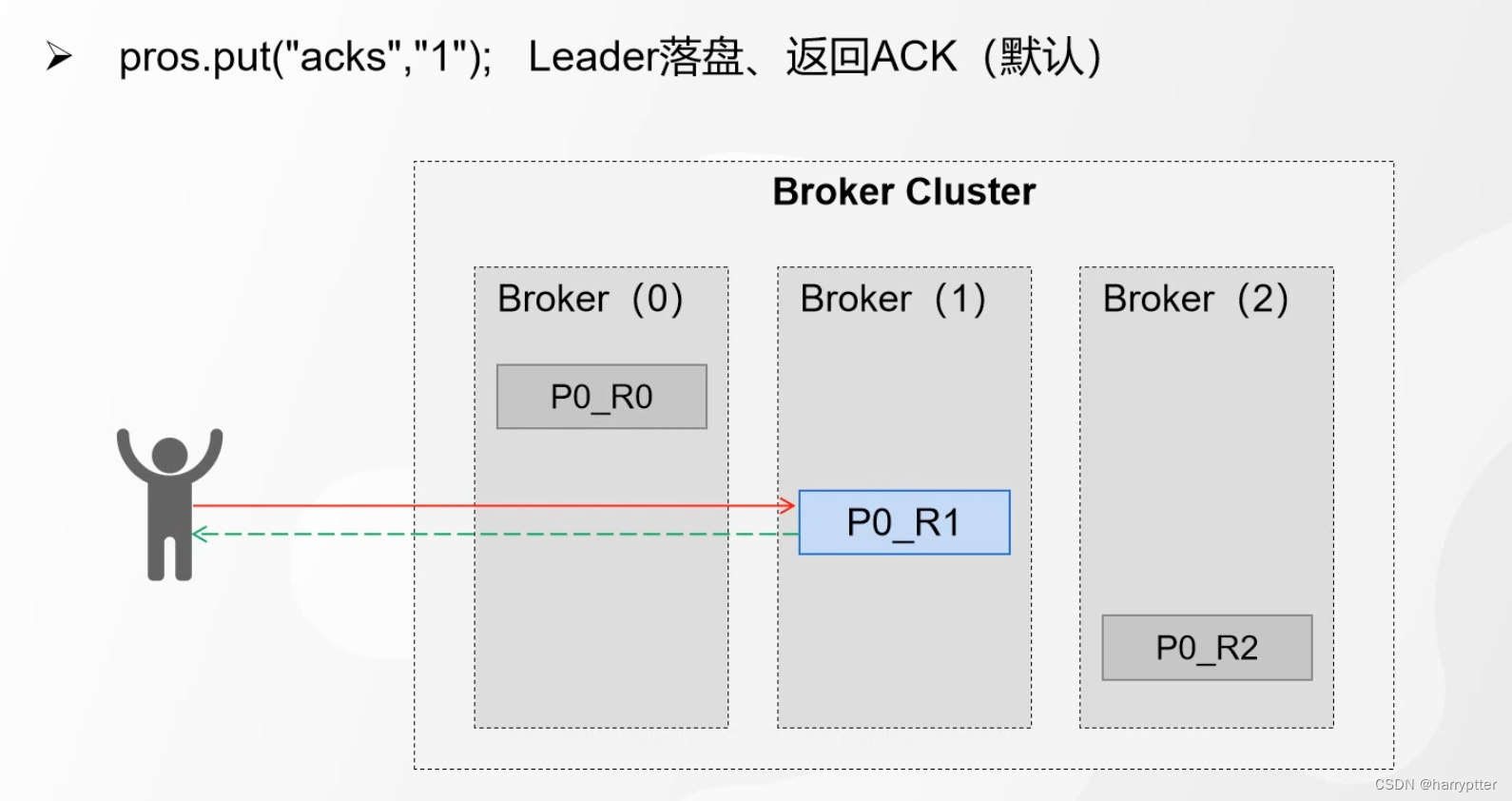
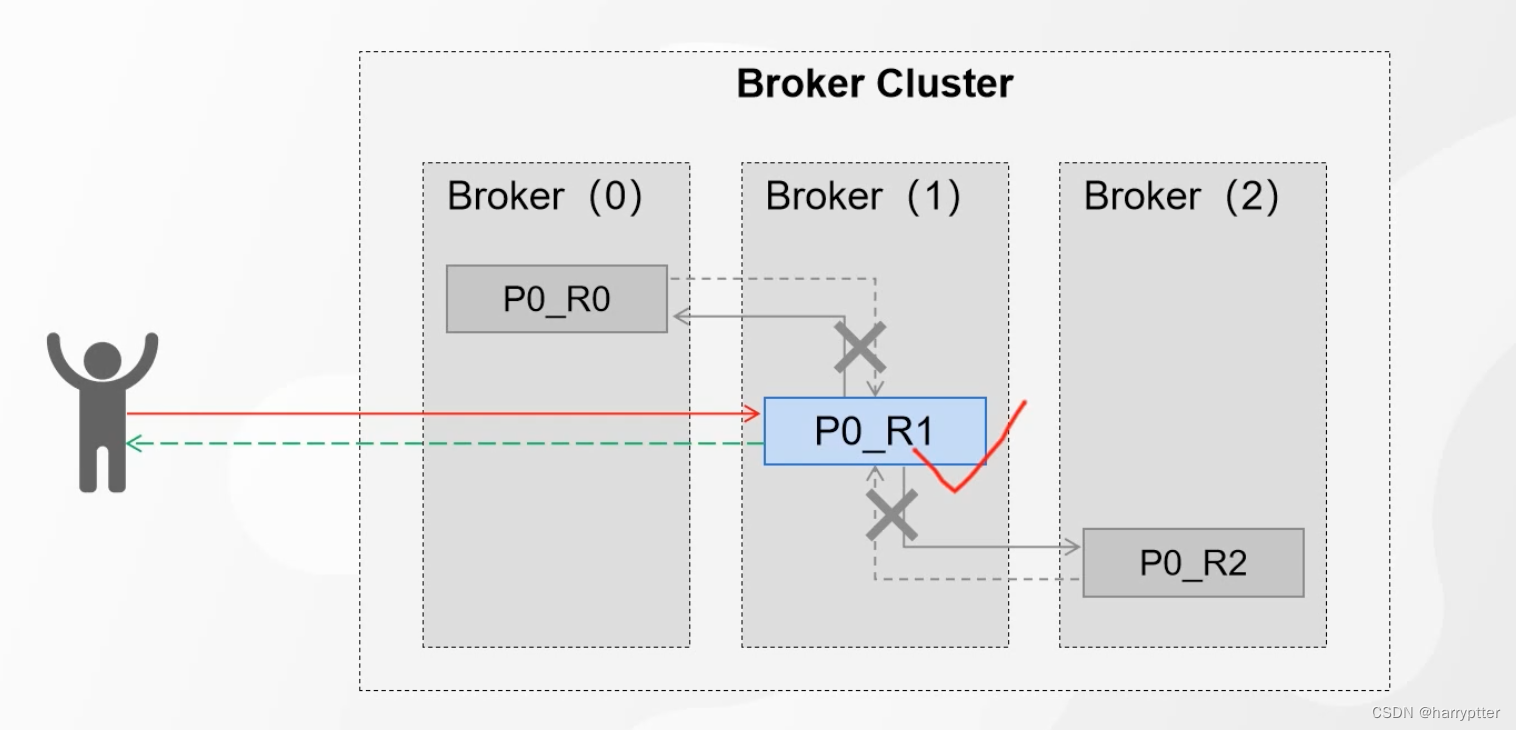
这种模式也会有问题,就是leader数据落盘之后,两个副本都没有备份,这个时候leader又挂了,这个时候就会丢失数据了,如下图所示:
所以要保证进一步的可靠性就有了第三种模式。
3.ack=-1(或者all):broker收到消息,并且leader分区落盘之后,所有fllowers也备份成功之后返回Ack应答。
明显可以看出,以上三种从上到下其可靠性依次增强,延迟也依次增大。
但是这个模式可以想到还是会有两种问题:
问题1:就是在leader,和fllower都落盘成功之后,准备返回ack时候,leader挂了,这个时候Producer就收不到ACK了。那么生产者正常来讲就会重发消息,这个时候对于broker来说明显消息重复了(当然实际上Kafka可以通过消息的幂等性来判断),就有问题了。
这个时候,除了Kafka自带的消息幂等性处理,还有一种方案,就是配置里有个重试次数,我们可以设置为0也可以实现。
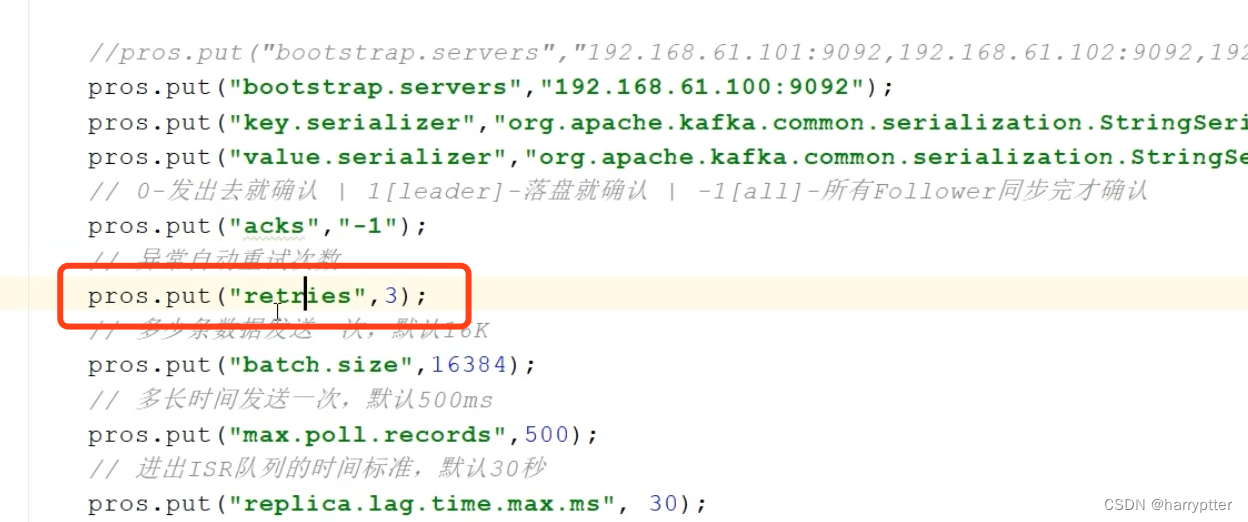
但明显这只能解决这一种问题,可能引起其他情况的异常问题(例如需要重发来保证可靠性的情况)
问题2:如果fllower重有挂了的节点,那么这种情况Producer明显永远拿不到Ack了,明显会阻塞消息过程。如下图:
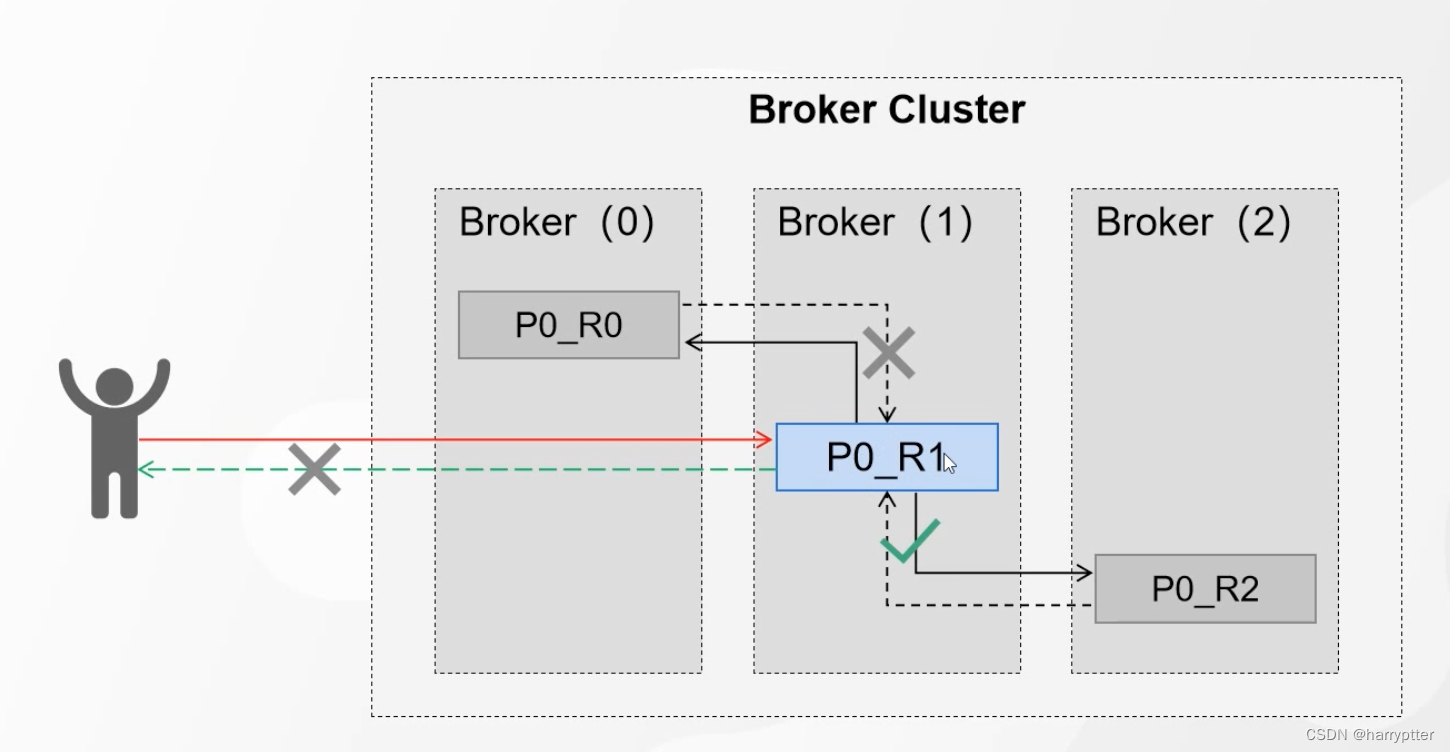
所以为了解决问题2这种情况,Kafka就采用了ISR的机制。
2)ISR机制
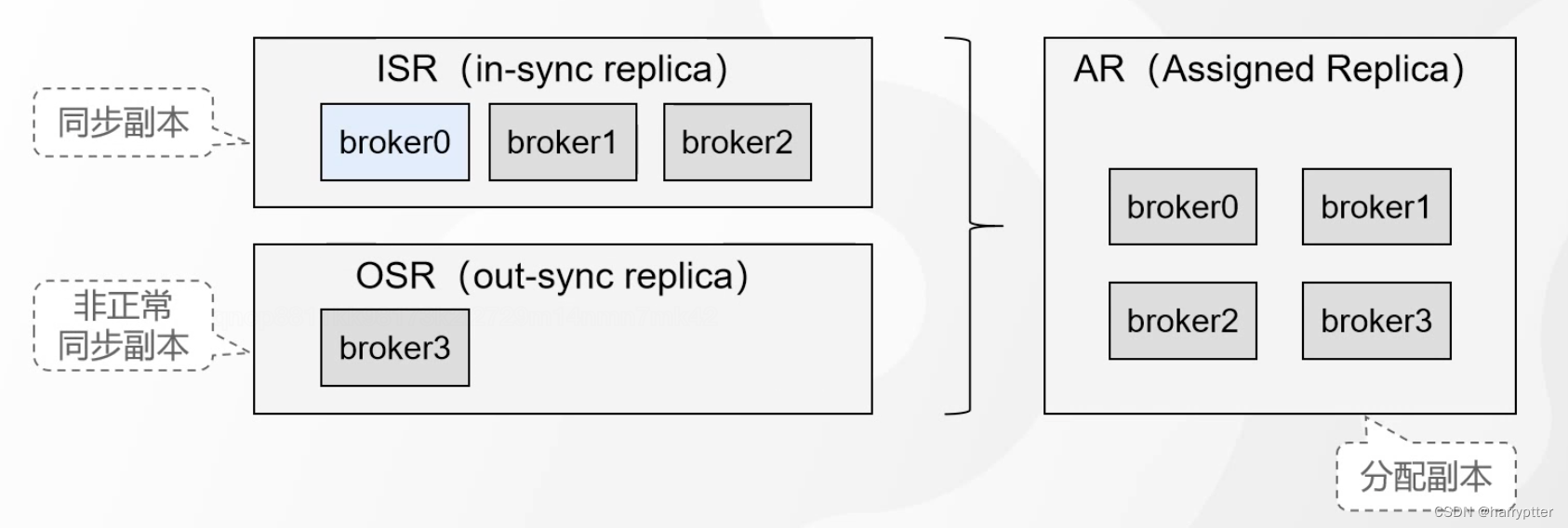
ISR(in-sync replica set):是一组动态维护副本的集合。
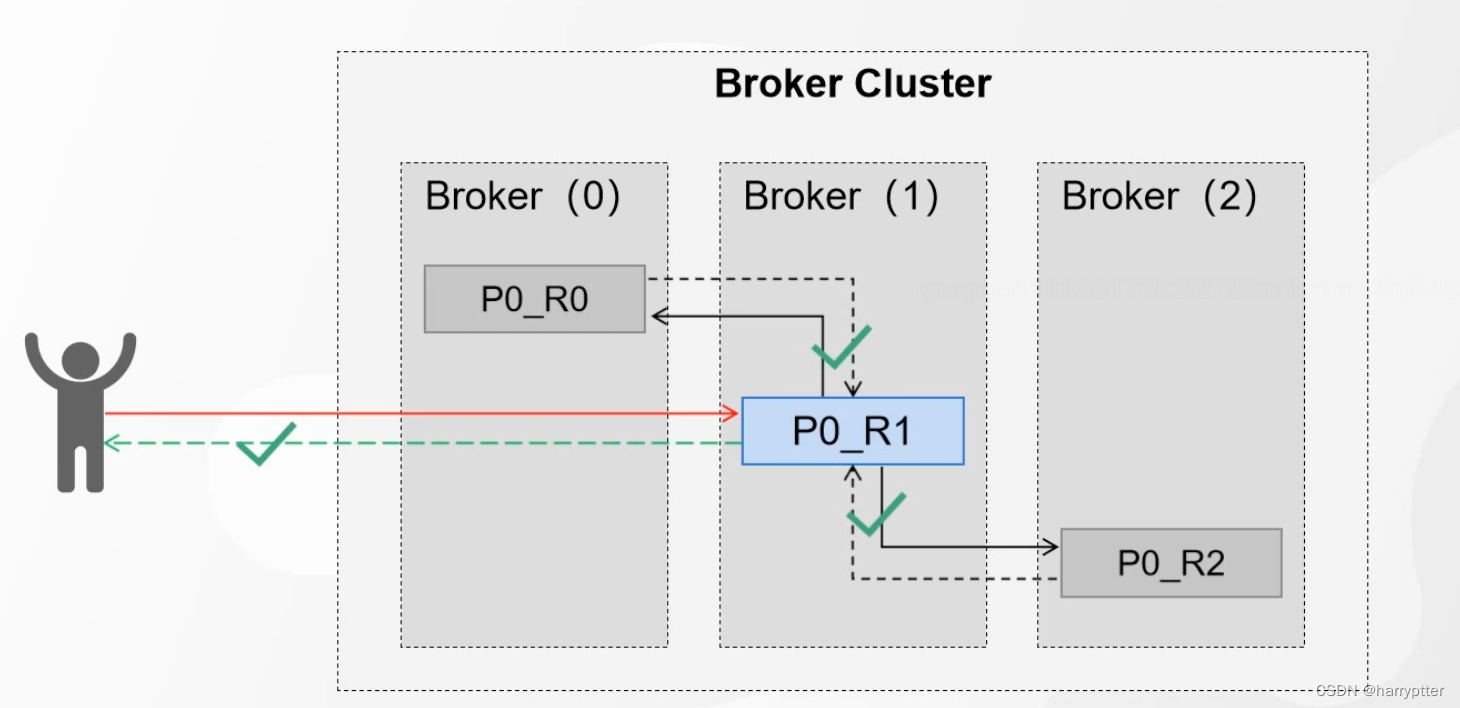
ISR的界定标准(可以自己设置):replica.lag.time.ms(默认是30秒),也就是P0_R0 30秒钟还没有从P0_R1中同步数据
简单的理解,ISR就是一个Set集合,里面存储的就是同步积极的分区集合,当分区同步出现问题时候,就把这个分区移除ISR集合。
还是在下图那种情况
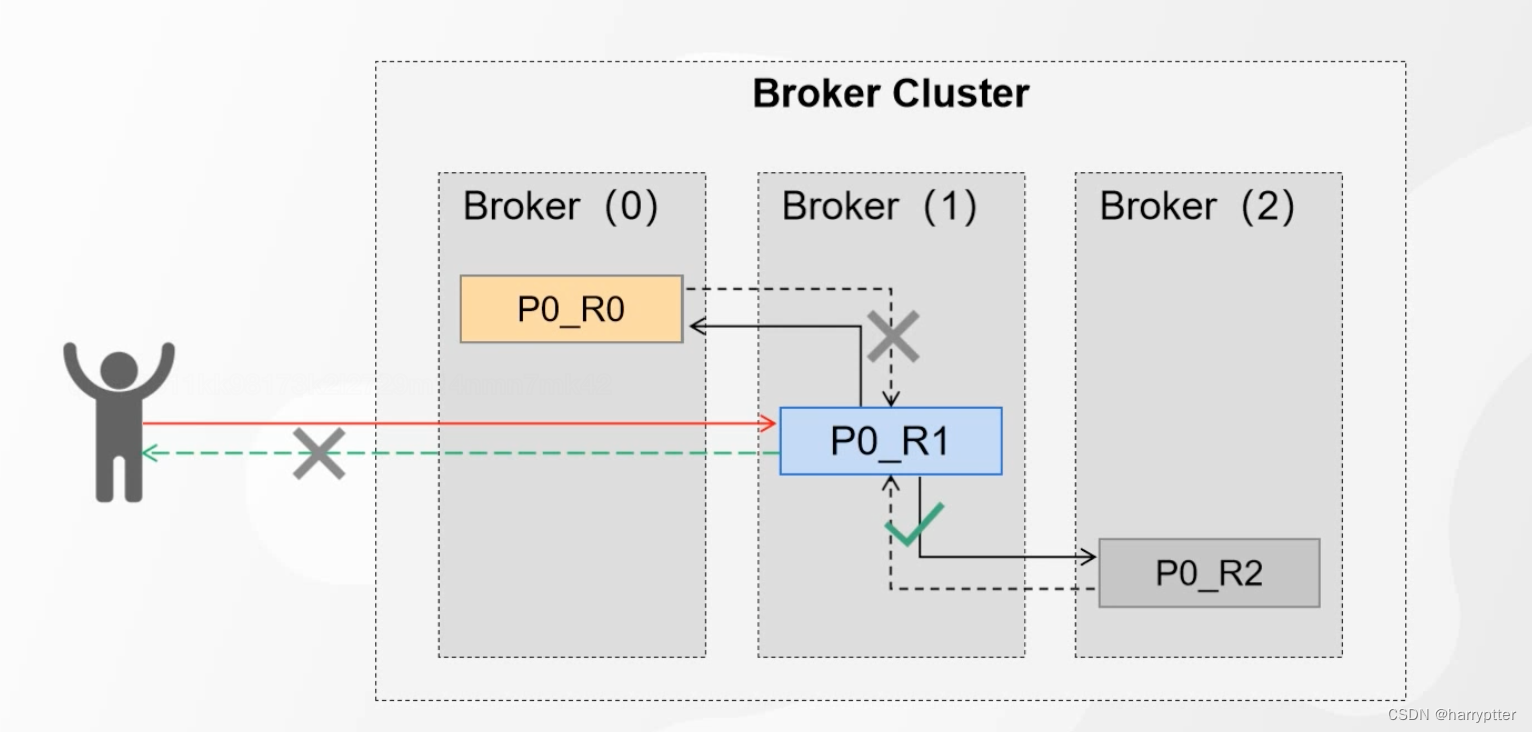 所以初始的时候,ISR集合里面是有P0_R0,P0_R1,P0_R2三个分区的,但是当P0_R0同步出现问题的时候,就把P0_R0移除ISR集合。这个时候ISR集合中只有P0_R1,P0_R2。此时这两个分区落盘都成功了,这个时候leader也就返回了ack了。
所以初始的时候,ISR集合里面是有P0_R0,P0_R1,P0_R2三个分区的,但是当P0_R0同步出现问题的时候,就把P0_R0移除ISR集合。这个时候ISR集合中只有P0_R1,P0_R2。此时这两个分区落盘都成功了,这个时候leader也就返回了ack了。
相对应ISR,也有一个OSR(out-sync replica),也就是没有正常同步数据的副本
那明显ISR+OSR 就能拿到全部的副本(AR:Assigned replica)了:AR = ISR+OSR,如下图所示:
三、消息的幂等性
生产者的幂等性,可以理解为不管生产者发送多少次效益,对于broker来说,如果是同一条消息,broker端只存一条消息。
上面问题1的那种情况,一般为了保证重试机制的正常,不会将重试参数retires设置为0,Kafka是通过broker的幂等性判断来解决这个问题的。下面详细介绍下实现的思路。
问题的情况如下图:
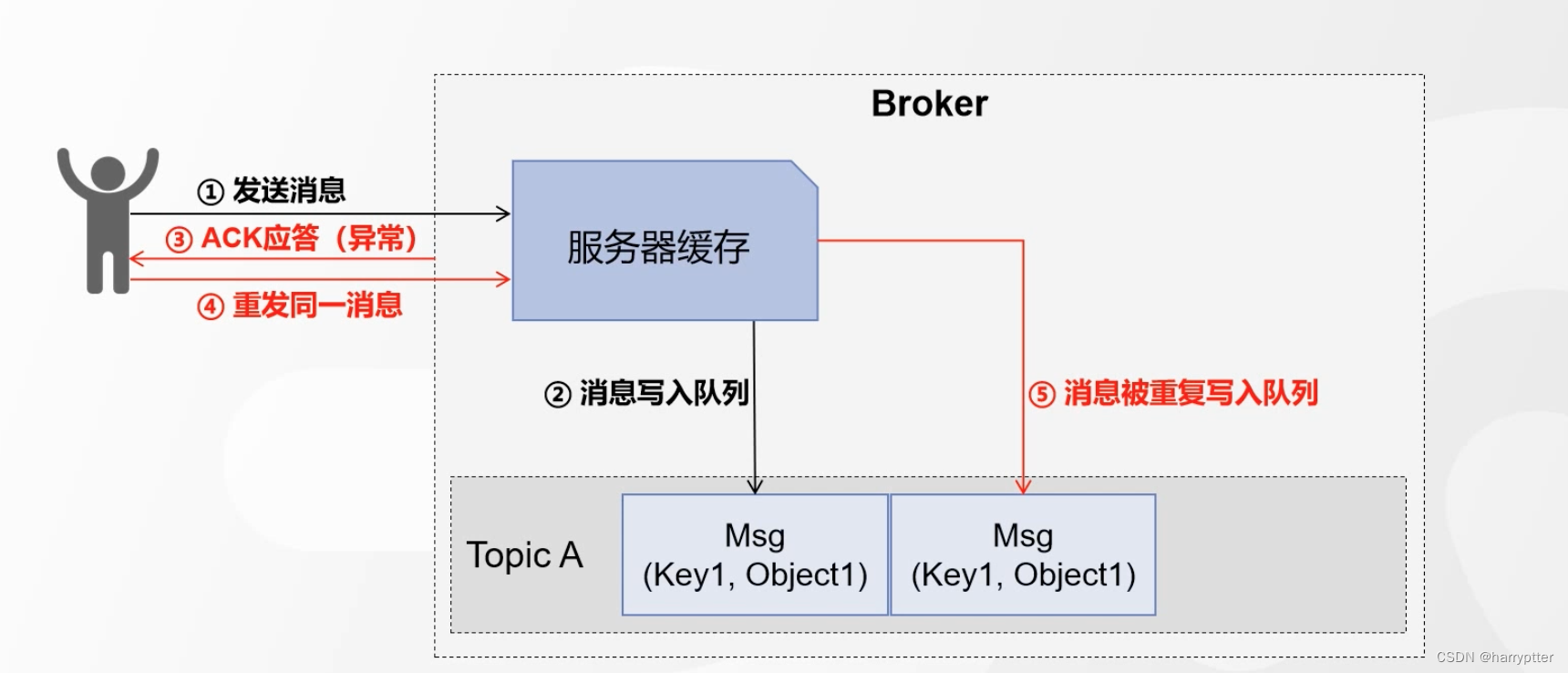
再返回ack时候,由于网络抖动等问题,导致服务端返回失败,此时生产者进行重试,导致消息被重复写入了broker服务端。
解决的方案如下:
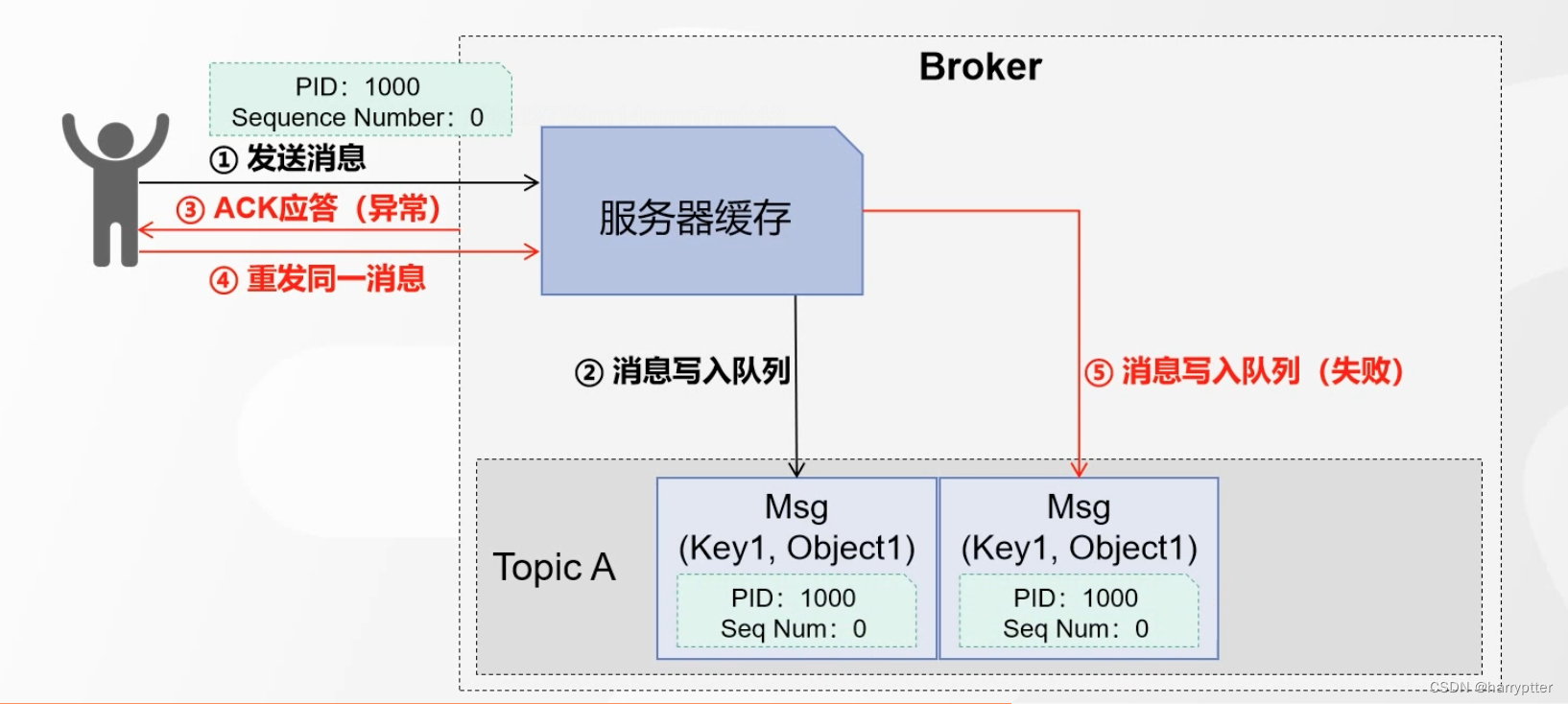
在发送消息的时候,每条消息增加两个参数,PID(Producer ID):生产者id; Sequence Number:消息序列数(一般从0开始)
如上图所示,在第4步重发同一消息时候,Broker服务端在网队列里面写消息时候,会判断PID和Seq Num是否重复,如果重复,就写入队列失败。那么就不会往队列里面写入重复的消息了。
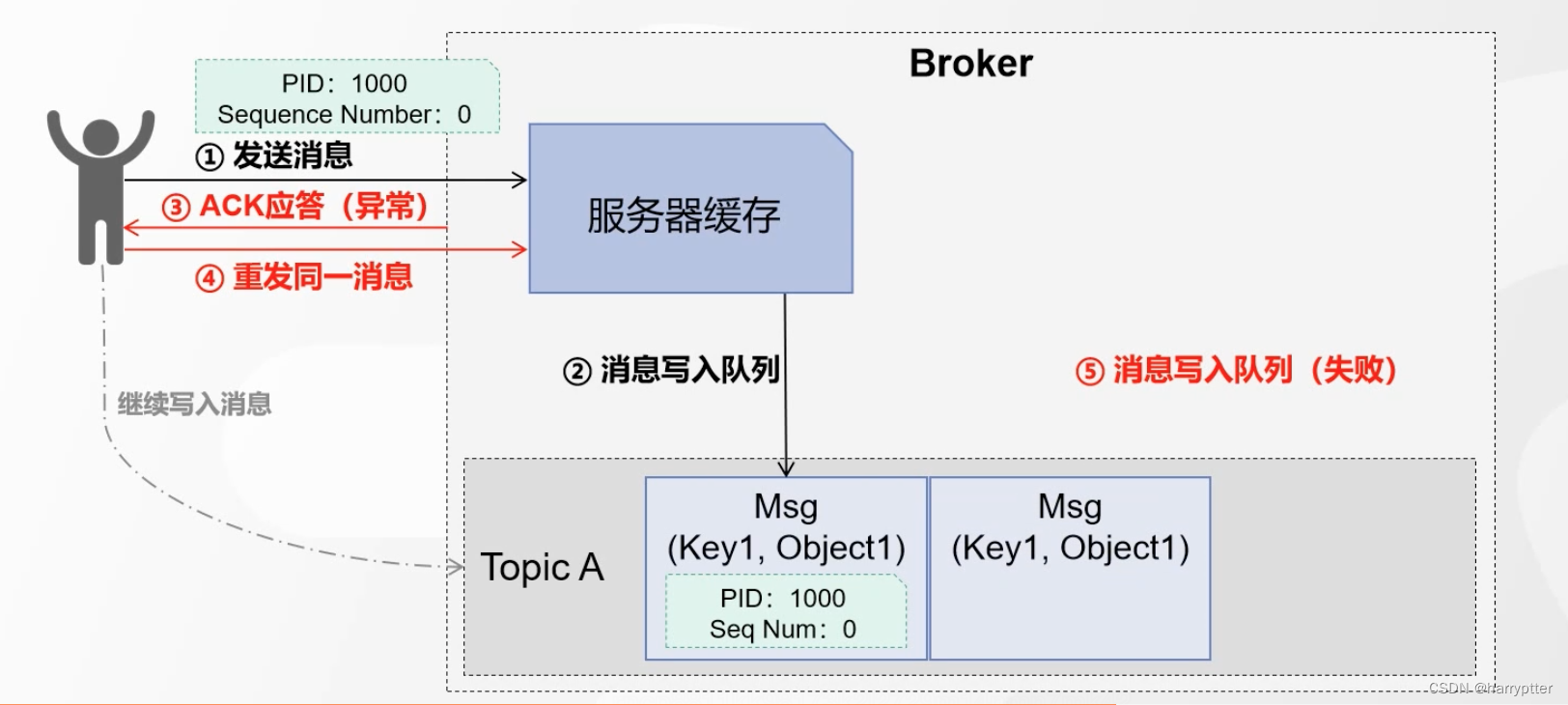
(这里面的Seq Num还会有多种情况,就是假设前一条消息的Seq Num=1,现在这条消息的PID相同,但是Seq Num=3,那么就会判断丢失了消息,Kafka就会抛出丢失消息的异常信息)
总结一下:
1)Producer端发送消息(消息,PID,Seq Num)
- Broker端接收消息(将消息,PID,Seq Num一起保存)
3)若ack失败,生产者重试,再次发生消息,Broker判断是否重复
四、Kafka生产者事务
上面的幂等性,只能保证在单分区,单会话(客户端重启之后,在建立连接,会认为是新的producer id)场景下有效。
对于多分区,多会话,Kafka通过生产者事务提供了多个分区写入的原子性操作(理解参照数据库的原子性)。
Kafka事务的API相关方法:

Kafka事务操作的基本流程:
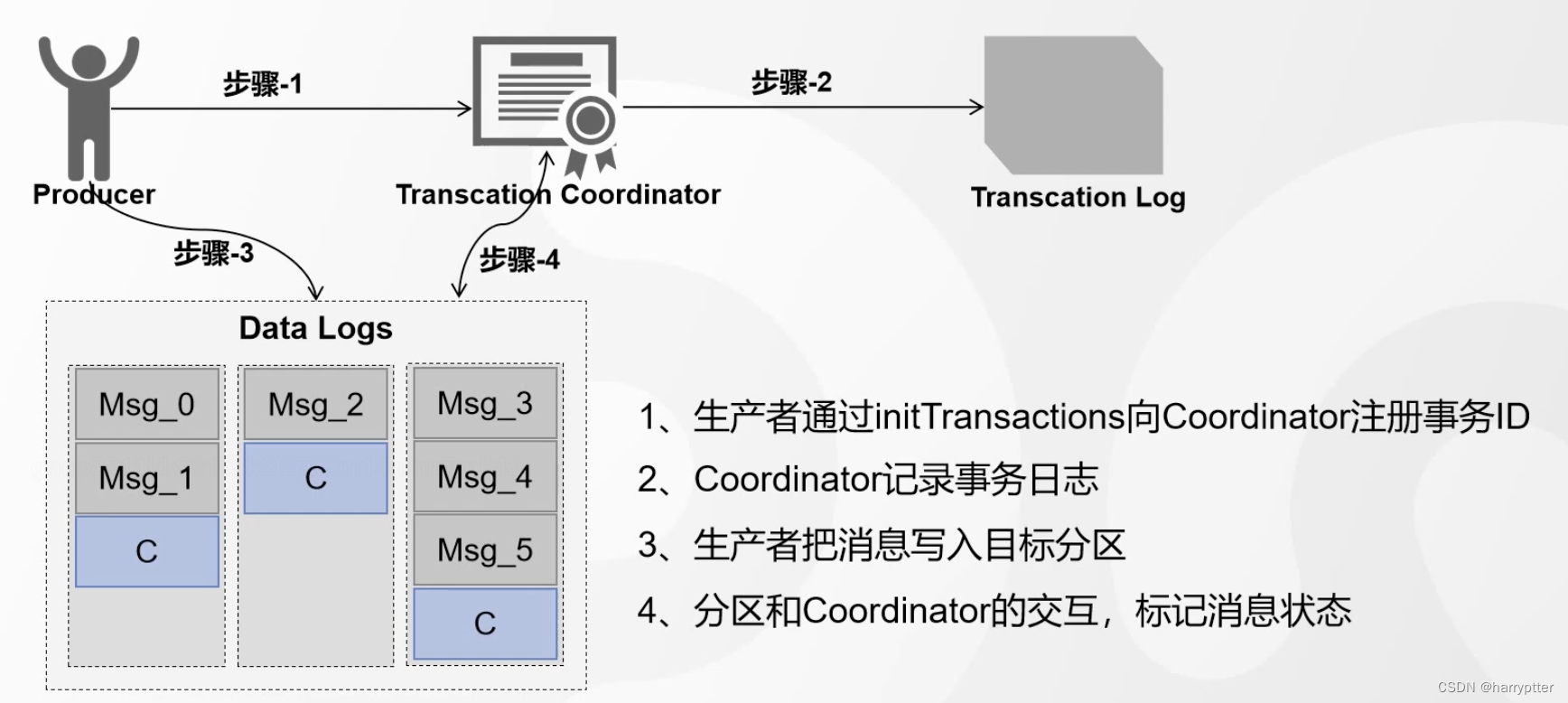
如上图所示:
Kafka通过事务协调者(Transaction Coordinator)和事务日志(Transcation Log)来实现的。
流程就是:
1)生产者通过initTransactions向Coordinator注册事务ID
2)Coordinator记录事务日志。
3)生产者把消息写入目标分区 (此时这三部的数据对于消费者都是不可见的)
4)分区和Coordinator的交互,标记消息状态。消息装状态标记为Commited,才对消费者可见,否则不可见。
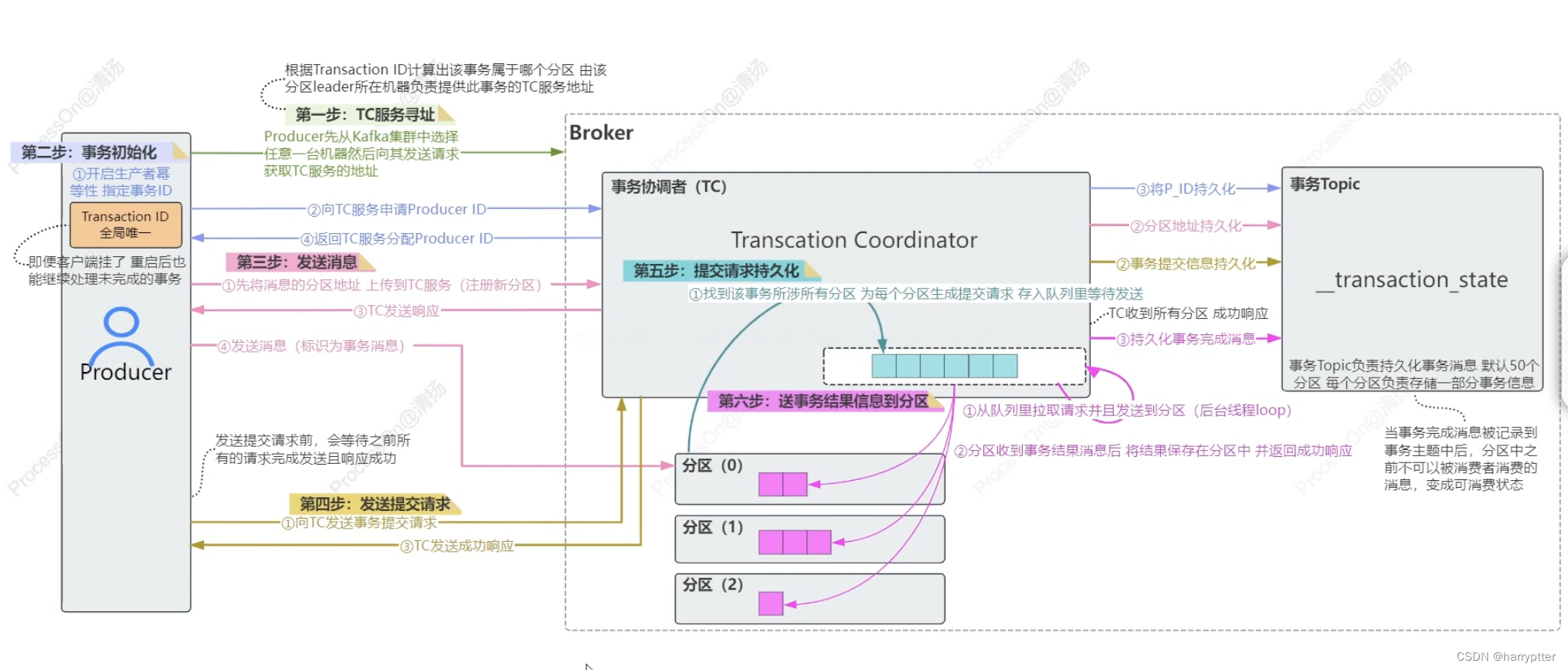
详细流程如下图:
以上就是Kafka,producer端相关原理了。