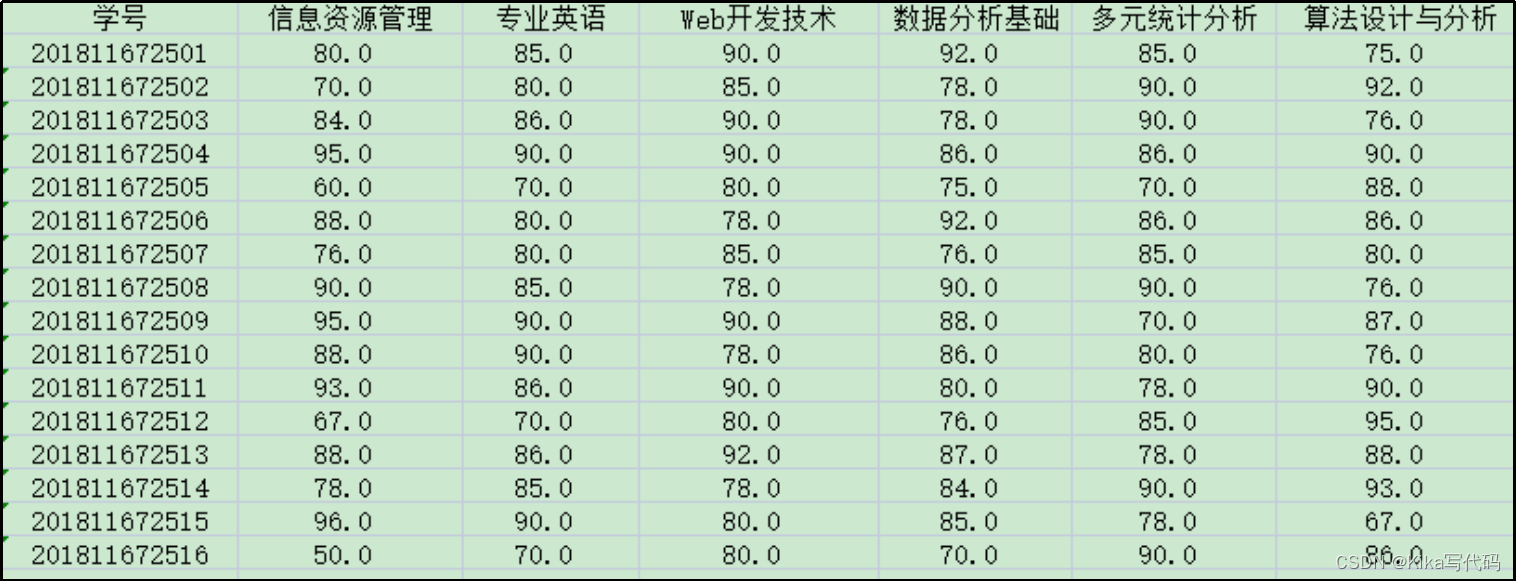
文件score.xlsx
中存放了学生的各个科目的考试成绩(如下图),
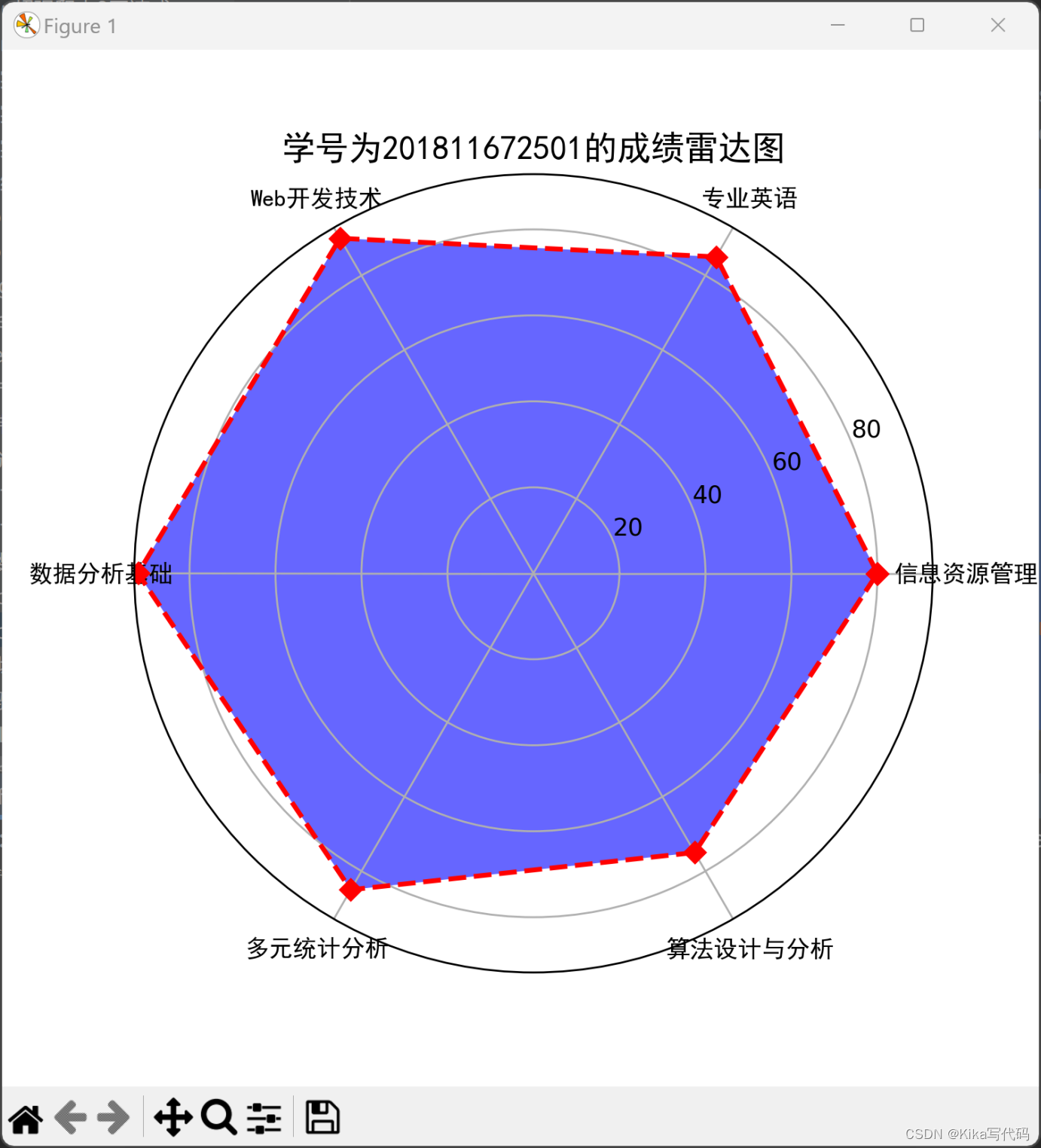
1. 编程实现:输入任意一个学号,将该学号对应的成绩,通过雷达图显示。
(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_excel('score.xlsx')
student_id = input("请输入学号:")
# 获取指定学号的成绩数据
scores = df[df['学号'] == int(student_id)].iloc[:, 1:].values.flatten().tolist()
# 科目名称
courses = df.columns[1:]
# 绘制雷达图
data_length = len(courses)
angles = np.linspace(0, 2 * np.pi, data_length, endpoint=False)
scores.append(scores[0])
angles = np.append(angles, angles[0])
plt.figure(figsize=(6, 6))
plt.polar(angles, scores, 'rD--', linewidth=2)
plt.thetagrids(angles[:-1] * 180/np.pi, courses, fontproperties='SimHei', fontsize=10)
plt.fill(angles, scores, facecolor='b', alpha=0.6)
plt.title(f"学号为{student_id}的成绩雷达图", fontproperties='SimHei', fontsize=14)
plt.show()(2)运行结果(截图):
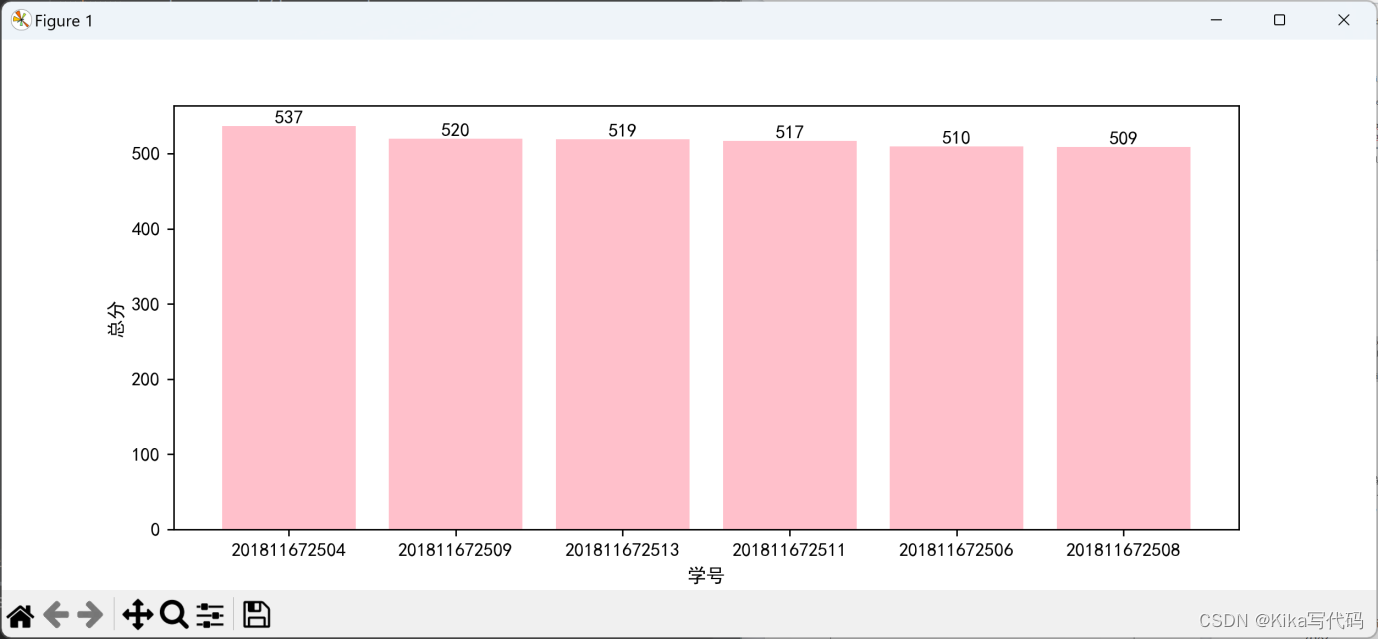
2. 统计所有同学的成绩总分,将总分在前6名的同学总分用柱形图显示出来。(纵坐标标签是"总分",横坐标标签是"学号",每个柱形上方显示具体的成绩总分)
(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']# 设置matplotlib支持中文的字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
df = pd.read_excel('score.xlsx')
# 统计所有同学的成绩总分
df['总分'] = df.iloc[:, 1:7].sum(axis=1)
# 对总分进行排序,找出前6名的学生
top6 = df.nlargest(6, '总分')
plt.figure(figsize=(10, 4))
plt.bar(top6['学号'].astype(str), top6['总分'], color='pink')
# 在每个柱形上方显示具体的成绩总分
for i in range(len(top6['总分'])):
plt.text(i, top6['总分'].iloc[i], str(top6['总分'].iloc[i]), ha='center', va='bottom')
plt.xlabel('学号')
plt.ylabel('总分')
plt.show()(2)运行结果(截图):
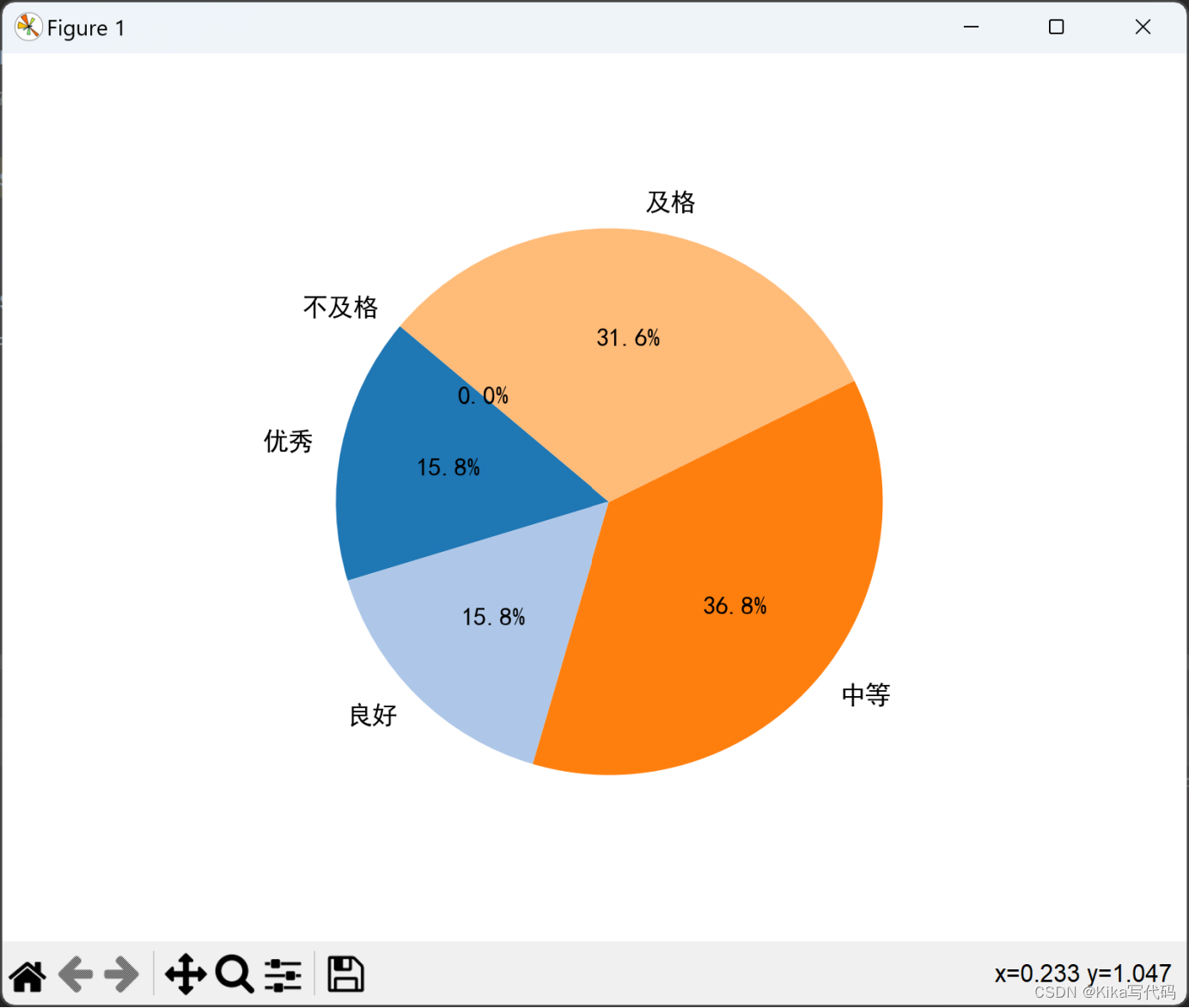
3. 编写程序,输入任意课程名称,统计该课程的各个成绩等级的比例,用饼状图显示。(优秀:90~100;良好:80~89;中等:70~79;及格:60~69;不及格:0~59)
(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置matplotlib支持中文的字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
df = pd.read_excel('score.xlsx')
course_name = input("请输入课程名称:")
# 根据输入的课程名称获取对应的成绩列
if course_name in df.columns:
scores = df[course_name]
else:
print(f"未找到课程:{course_name}")
exit()
grades = {90: '优秀', 89: '良好', 79: '中等', 69: '及格', 59: '不及格'}
# 统计各个成绩等级的数量
labels = []
sizes = []
for grade in sorted(grades, reverse=True):
if grade == 59: # 因为成绩不可能低于0,所以不及格的下限是0
labels.append(grades[grade])
sizes.append(scores[scores <= grade].count())
else:
labels.append(grades[grade])
sizes.append(scores[(scores >= grade) & (scores < (grade + 10))].count())
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140, colors=plt.cm.tab20.colors)
plt.show()(2)运行结果(截图):
超市营业额2.xlsx
1. Series一维数组的创建和使用
练习如下命令语句,熟悉pandas中Series一维数组的创建和使用。
(1)程序代码:
python
import pandas as pd
# 使用字典创建Series,使用字典的"键"作为索引
s2 = pd.Series({'语文': 90, '数学': 92, 'Python': 98, '物理': 87, '化学': 92})
print(s2.argmax(), '\n') # s2最大值的索引
print(s2.between(90, 94, inclusive='both'), '\n') # 测试s2的值是否在指定区间内
print(s2[s2 > 90], '\n') # 查看s2中90分以上的数据
print(s2.median(), '\n') # 查看s2的中值
print(s2[s2 > s2.median()], '\n') # 查看s2中高于中值的数据
print(round((s2 ** 0.5) * 10, 1), '\n') # s2与数字之间的运算
print(s2.nsmallest(2), '\n') # s2中最小的2个值2. 数据查看head() .iloc
练习如下命令语句,熟悉Excel文件数据读取到pandas中DataFrame二维结构后进行数据查看的方法。
(1)程序代码:
python
import pandas as pd
# 设置列对齐
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
# 读取工号、姓名、时段、交易额这四列数据,使用默认索引
df = pd.read_excel('超市营业额2.xlsx', usecols=['工号', '姓名', '时段', '交易额'])
print(df.head(5), end='\n\n') # 输出前5行数据
print(df.iloc[5:10], end='\n\n') # 下标在[5:10]区间的行3. 数据排序、分组统计
练习如下命令语句,熟悉使用DataFrame数据结构后进行数据排序、分组统计的方法。
(1)程序代码:
python
import pandas as pd
df = pd.read_excel('超市营业额2.xlsx') # 读取全部数据,使用默认索引
print(df, end='\n\n')
print(df.iloc[[3, 5, 10], [0, 1, 4]], end='\n\n') # 行下标为[3, 5, 10],列下标为[0, 1, 4]的数据
print(df.loc[[3, 5, 10], ['姓名', '交易额']], end='\n\n') # 使用标签文本作为索引,输出下标为[3, 5, 10]的行的'姓名'和'交易额'列
print(df.at[3, '姓名'], end='\n\n') # 输出行下标为3,'姓名'列的值
print(df[df['交易额'] > 1700], end='\n\n') # 输出交易额高于1700元的数据
print(df[df['柜台'] == '日用品']['交易额'].sum(), end='\n\n') # 输出日用品柜台销售总额
print(df[df['交易额'].between(1580, 6000)], end='\n\n') # 输出交易额在指定范围内的记录
# 按交易额降序、工号升序排序,并输出前8行
print('按交易额降序、工号升序排序'.ljust(20, '='))
print(df.sort_values(by=['交易额', '工号'], ascending=[False, True])[:8])
print('按工号升序排序'.ljust(20, '='))
print(df.sort_values(by='工号', na_position='last').head(8))
print('各柜台的销售总额'.ljust(30, '='))
print(df.groupby(by='柜台')['交易额'].sum())
print('每个员工不同时段的交易额'.ljust(30, '='))
print(df.groupby(by=['姓名', '时段'])['交易额'].sum())
print('使用DataFrame结构的agg方法对指定列进行聚合'.ljust(30, '='))
print(df.agg({'交易额': ['sum', 'mean', 'min', 'max', 'median'], '日期': ['min', 'max']}))
print('对分组结果进行聚合'.ljust(30, '='))
print(df.groupby(by='姓名')['交易额'].agg(['max', 'min', 'mean', 'median']))
print('查看分组聚合后的部分结果'.ljust(30, '='))
print(df.groupby(by='姓名')['交易额'].agg(['max', 'min', 'mean', 'median']).head(2))4. 值异常、值缺失、值重复
练习如下命令语句,熟悉使用DataFrame数据结构进行异常数据(值异常、值缺失、值重复等)处理的方法。
(1)程序代码:
python
import pandas as pd
df = pd.read_excel('超市营业额2.xlsx')
# 把高于3000的交易额都替换为固定的3000
df.loc[df.交易额 > 3000, '交易额'] = 3000
print('交易额低于200或高于3000的数量'.ljust(20, '='))
print(df[(df.交易额 < 200) | (df.交易额 > 3000)]['交易额'].count())
print('使用每人交易额均值替换缺失值'.ljust(20, '='))
dff = df[:] # 复制为dff, 不影响原来的数据
for i in dff[dff.交易额.isnull()].index:
dff.loc[i, '交易额'] = round(dff.loc[dff.姓名 == dff.loc[i, '姓名'], '交易额'].mean())
print(dff.iloc[[110, 124, 168], :])
print('使用整体均值的80%填充缺失值'.ljust(20, '='))
df.fillna({'交易额': round(df['交易额'].mean()*0.8)}, inplace=True)
print(dff.iloc[[110, 124, 168], :])
# 可以查看是否有录入错误的工号和姓名
print('所有工号与姓名的对应关系'.ljust(20, '='))
dff = df[['工号', '姓名']]
print(dff.drop_duplicates())5. 各员工在不同柜台业绩平均值的柱状图
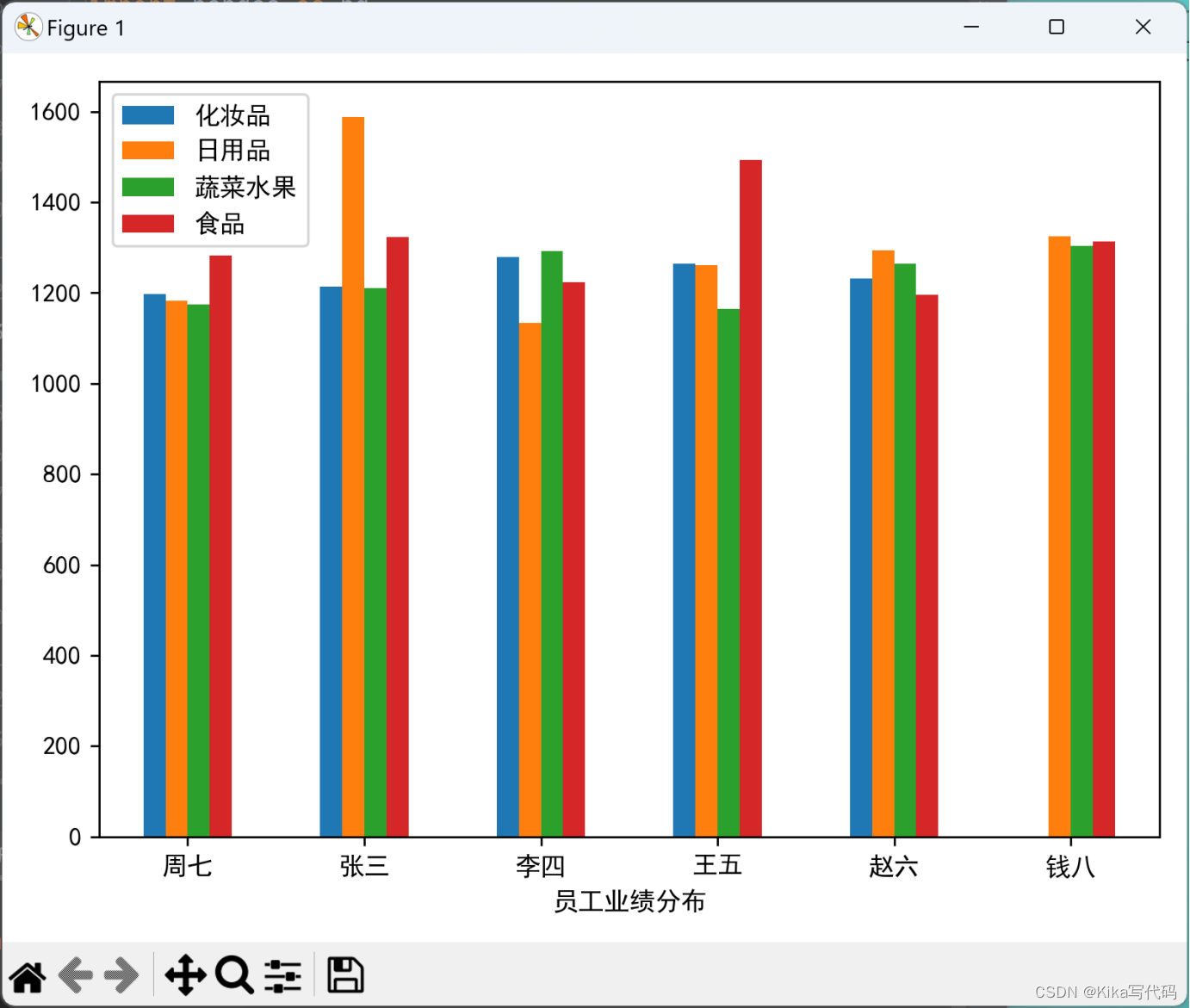
结合pandas数据处理和matplotlib数据可视化两个扩展库,绘制各员工在不同柜台业绩平均值的柱状图。
参考代码:

(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置matplotlib支持中文的字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
df = pd.read_excel("超市营业额2.xlsx")
# 修改异常值:将交易额高于3000的替换为3000,低于200的替换为200
df.loc[df.交易额 > 3000, '交易额'] = 3000
df.loc[df.交易额 < 200, '交易额'] = 200
df.drop_duplicates(inplace=True) # 删除重复值
df['交易额'].fillna(df['交易额'].mean(), inplace=True) # 填充缺失值
# 使用交叉表得到每人在各柜台交易额平均值
print(''.ljust(20, '='))
df_group = pd.crosstab(df.姓名, df.柜台, df.交易额, aggfunc='mean').apply(round)
df_group.plot(kind='bar') # 绘制柱状图,默认使用index作为横坐标
plt.xlabel('员工业绩分布', fontproperties='SimHei')
plt.xticks(fontproperties='SimHei', rotation=0)
plt.legend()
plt.tight_layout()
plt.show()(2)运行结果(截图):
**6.**groupby()、nsmallest()
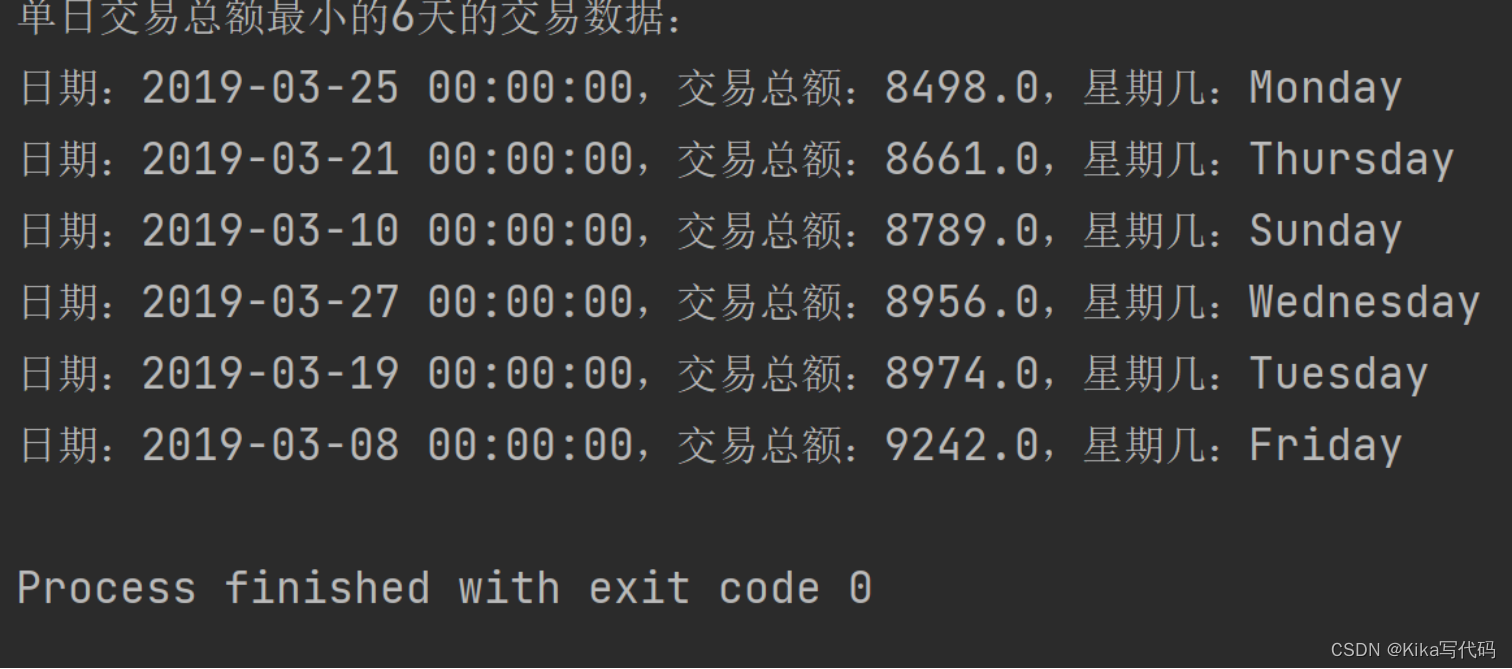
编程实现:查看单日交易总额最小的6天的交易数据,并查看这几天是星期几。
(1)程序代码:
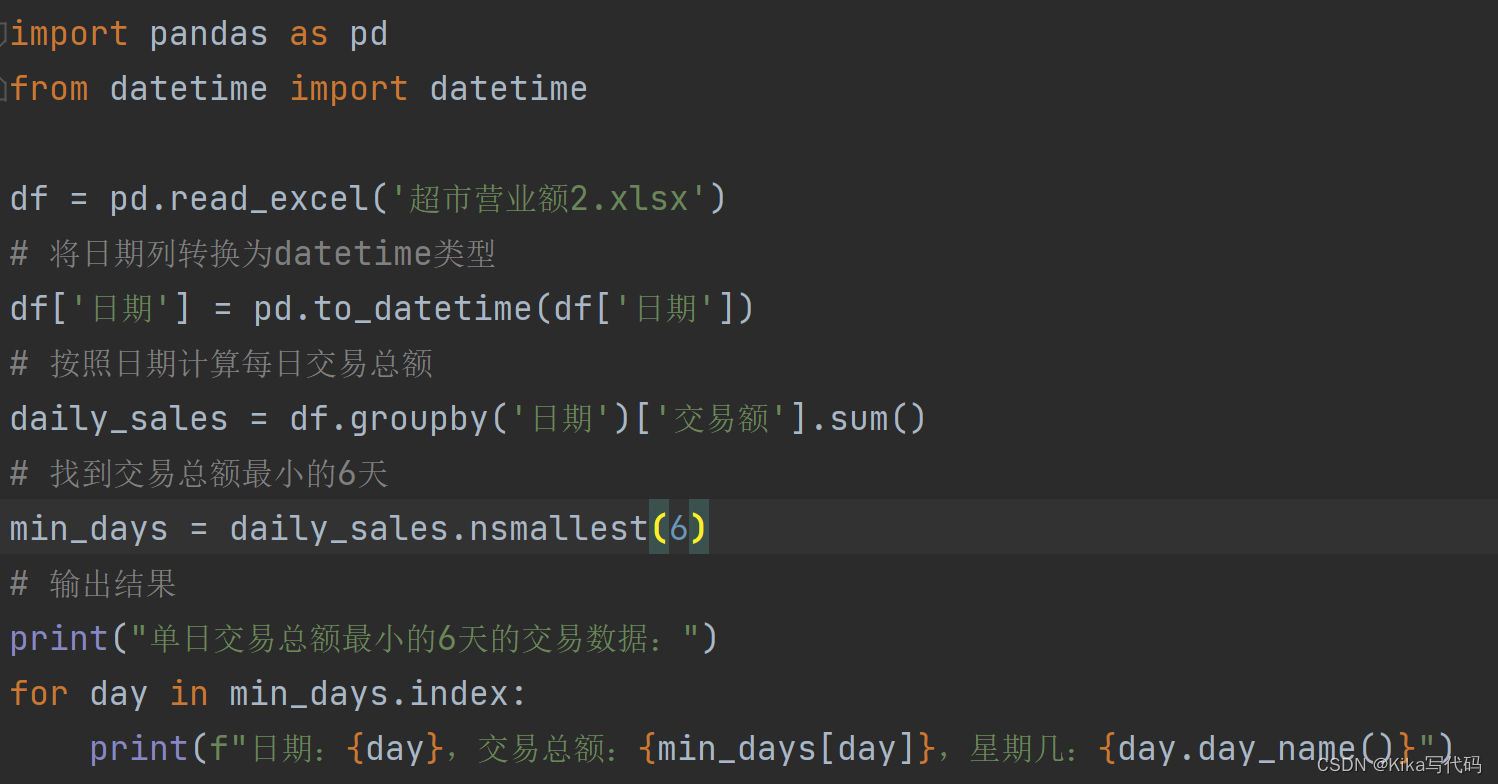
(2)运行结果(截图):
7.写入文件ExcelWriter()
编程实现:把每位员工的交易额数据写入文件"员工销售数据统计.xlsx",每位员工的数据占一个工作表(worksheet),每个工作表以员工姓名命名,表结构同"超市营业额2.xlsx"一样。
(1)程序代码:
python
import pandas as pd
df = pd.read_excel("超市营业额2.xlsx")
# 创建一个ExcelWriter对象,并指定要写入的文件路径
with pd.ExcelWriter('员工销售数据统计.xlsx') as writer:
# 遍历df中唯一的员工姓名
for name in df['姓名'].unique():
# 筛选出当前员工的所有交易记录
employee_data = df[df['姓名'] == name]
# 将筛选出的员工数据写入一个新的工作表,工作表名称为员工姓名
employee_data.to_excel(writer, sheet_name=name, index=False)8. 饼状图每个柜台营业额占总额比例
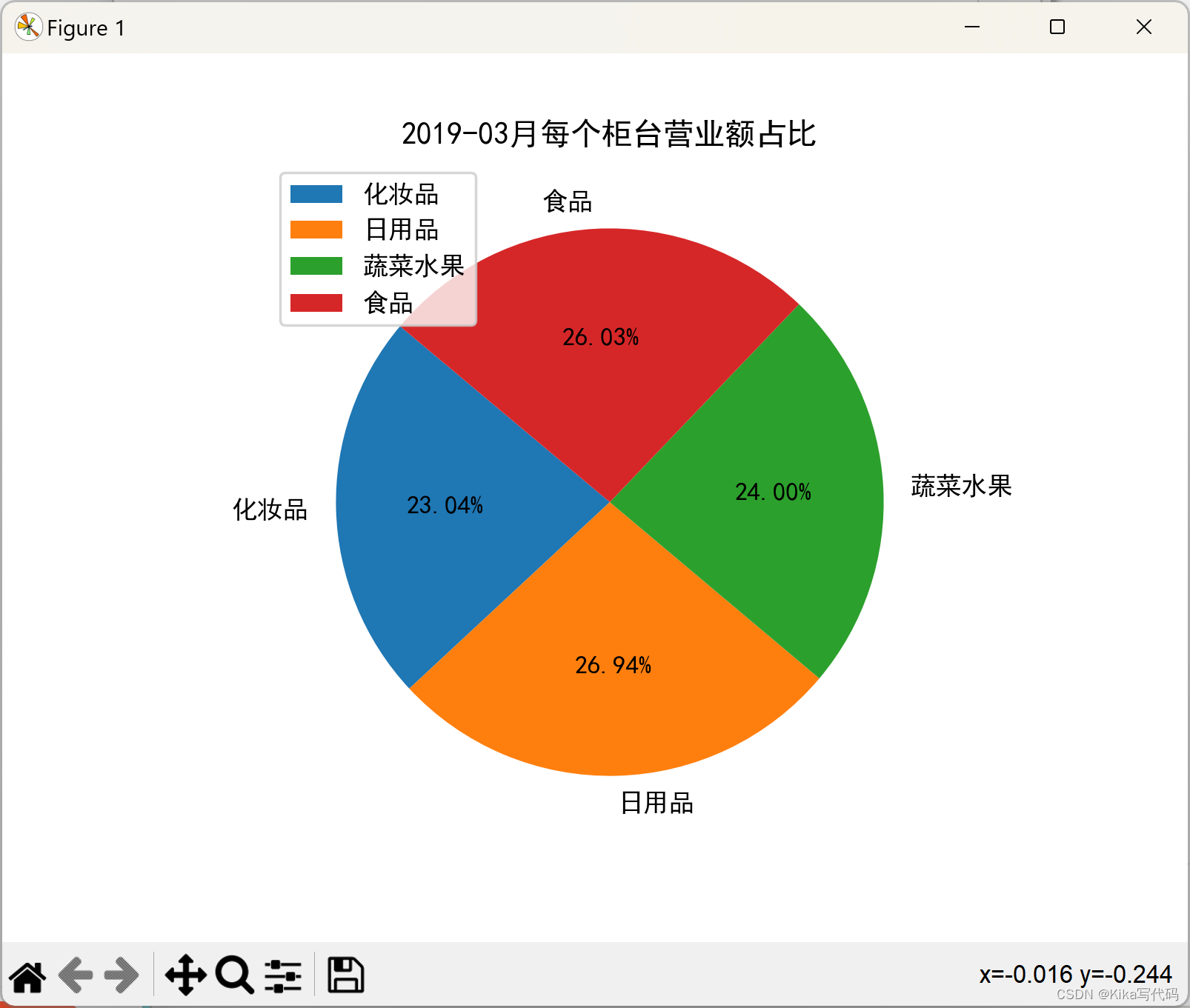
编写实现:绘制饼状图展示每月每个柜台营业额的在交易总额中的比例。
示例代码:

import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['simhei'] df = pd.read_excel(r"数据分析基础课程/超市营业额2.xlsx") ddf = df.loc[:, ['柜台', '交易额']].groupby(by='柜台', as_index=False).sum() ddf.plot(x='柜台', y='交易额', kind='pie', labels=ddf['柜台'], autopct='%0.2f%%') plt.savefig('sale.jpg')
(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置matplotlib支持中文的字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
df = pd.read_excel("超市营业额2.xlsx")
df['日期'] = pd.to_datetime(df['日期'])
df['月份'] = df['日期'].dt.to_period('M') # 将日期转换为月份
# 对数据按柜台和月份进行分组,计算每个组合的营业额
grouped = df.groupby(['柜台', '月份'])['交易额'].sum().reset_index()
print(grouped)
month = grouped['月份'].unique()
# 将每个柜台的营业额转换为百分比
grouped['百分比'] = grouped['交易额'] / grouped['交易额'].sum() * 100
plt.pie(grouped['百分比'], labels=grouped['柜台'], autopct='%.2f%%', startangle=140)
plt.title(f'{month[0]}月每个柜台营业额占比')
plt.legend()
plt.show()(2)运行结果(截图):
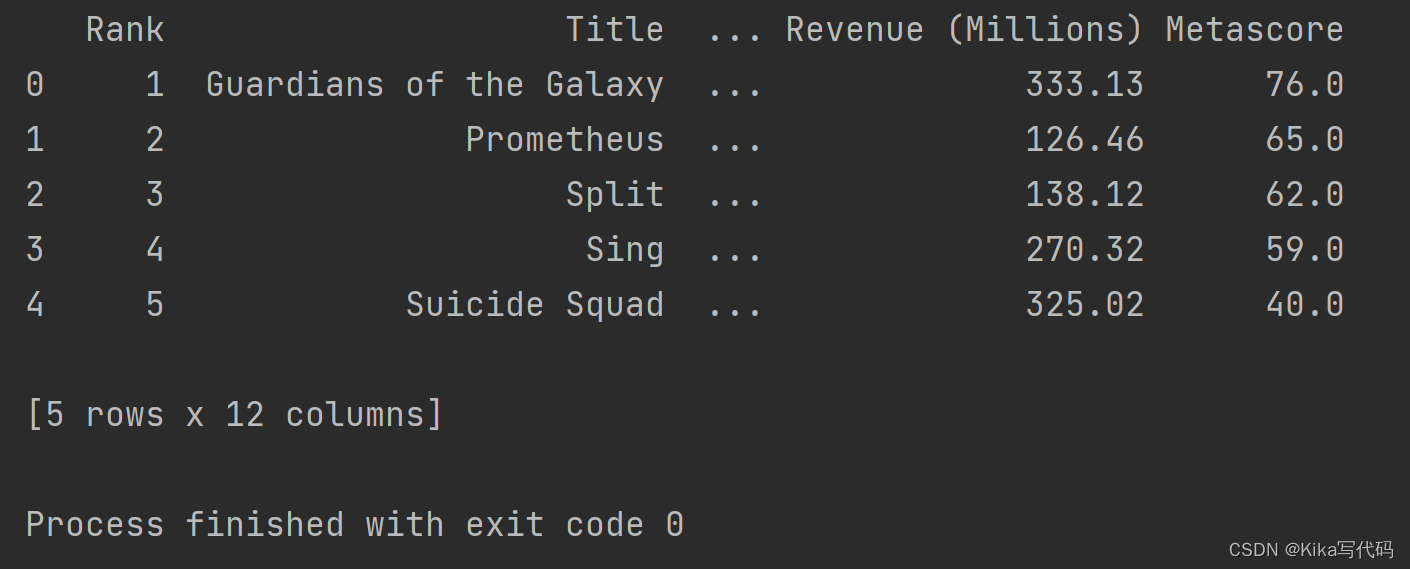
电影数据文件IMDB-Movies-Data.csv
1. 读取
运行如下代码,读取电影数据文件IMDB-Movies-Data.csv( 该文件会在超星平台与实验任务书同时发放,下面代码中的文件路径要注意根据文件下载后实际存放位置更换 )
(1)程序代码:
python
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv('IMDB-Movie-Data.csv')
print(df.head())(2)运行结果(截图):
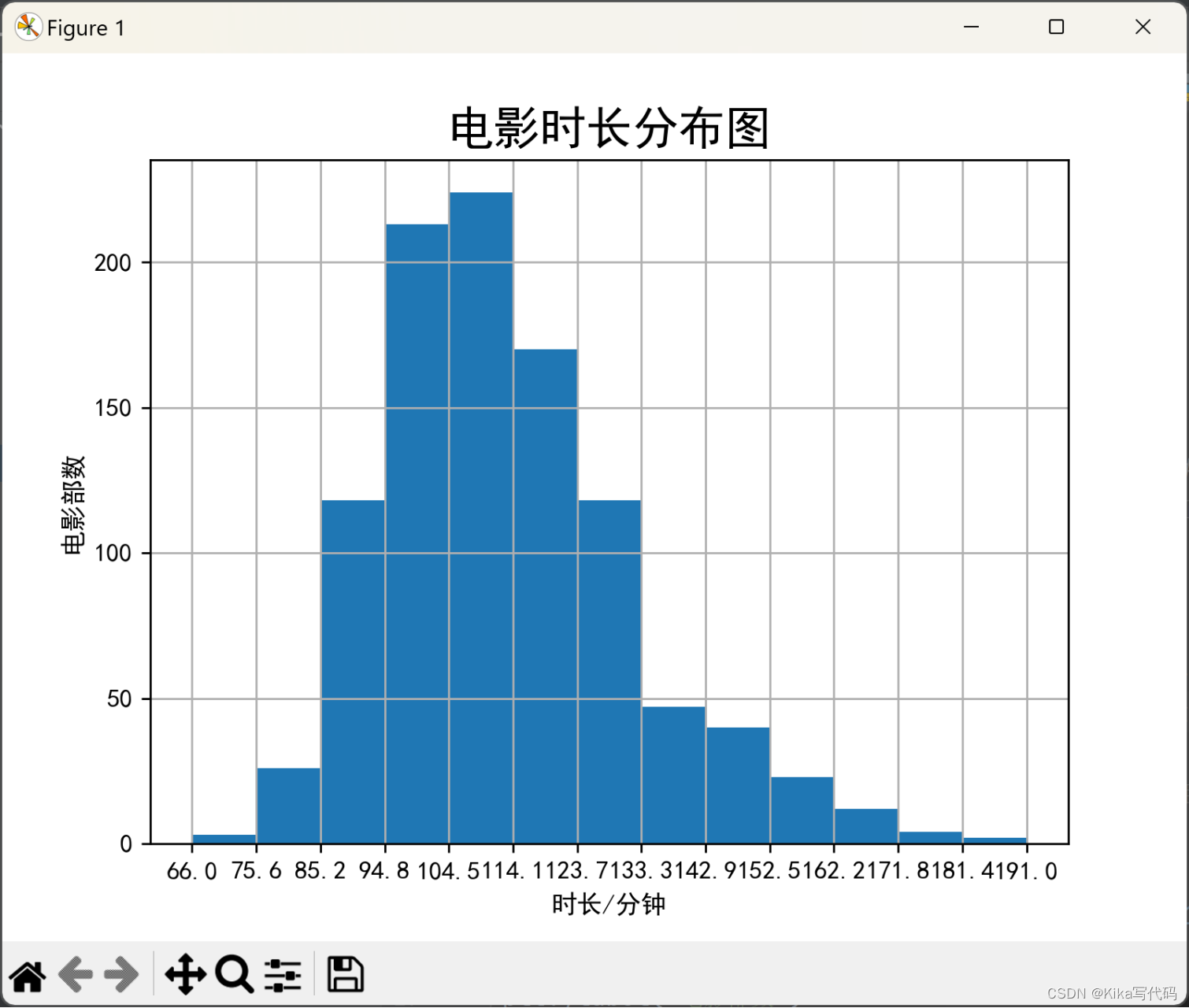
2. 柱状图显示时长分布
统计所有电影的时长,并用柱状图显示时长分布情况。
(1)程序代码:
python
from matplotlib import pyplot as plt
from pylab import mpl
import pandas as pd
import numpy as np
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 使用宋体显示中文
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
df = pd.read_csv('IMDB-Movie-Data.csv')
min_ = df['Runtime (Minutes)'].min() # 获取最小值
max_ = df['Runtime (Minutes)'].max() # 获取最大值
t = np.linspace(min_, max_, num=14) # 生成等间距的时间刻度
plt.xticks(t) # 设置x轴的刻度
plt.grid() # 显示网格
plt.hist(df['Runtime (Minutes)'].values, bins=13) # 绘制直方图,bins=13表示将数据分为13个区间
plt.xlabel('时长/分钟')
plt.ylabel('电影部数')
plt.title('电影时长分布图', fontsize=18)
plt.show()(2)运行结果(截图):
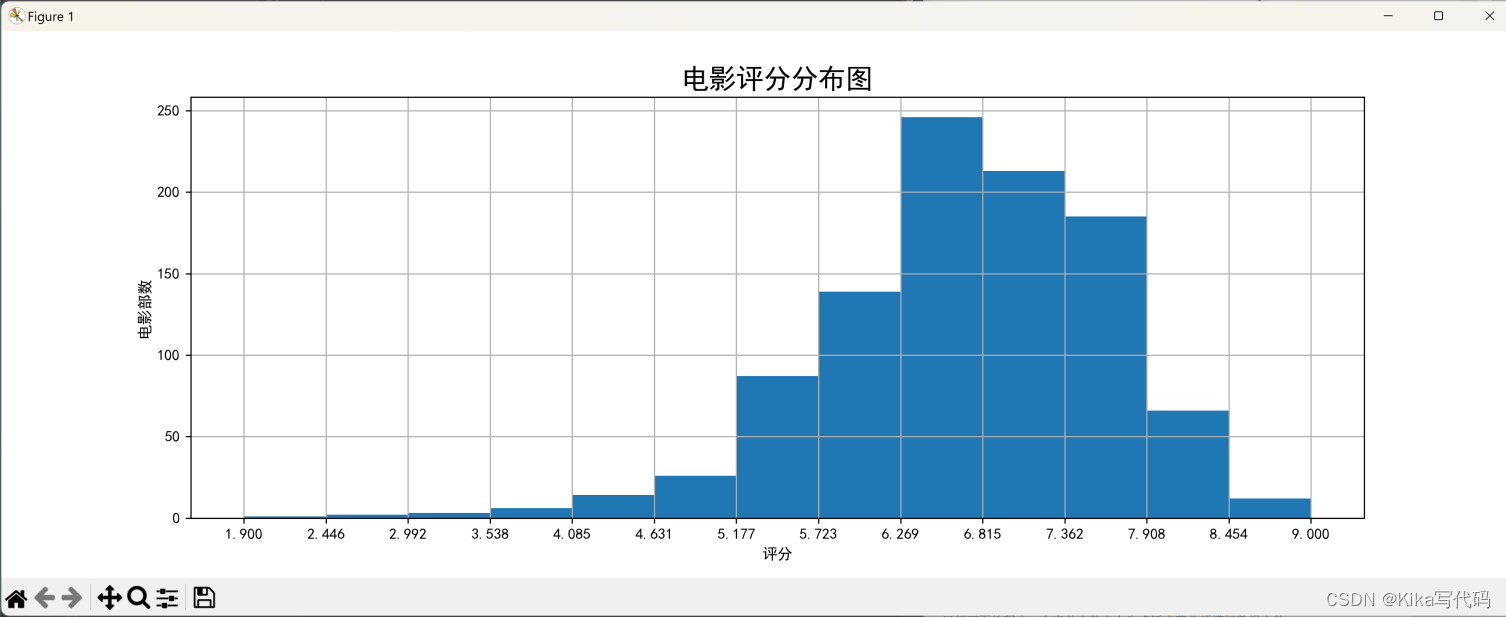
3. 柱状图显示电影类型的分布
统计所有电影的分类,并用柱状图显示电影类型的分布情况。
(1)程序代码:
python
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用宋体显示中文
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
df = pd.read_csv('IMDB-Movie-Data.csv')
# 获取Rating列的最小值和最大值
min_val = df['Rating'].min()
max_val = df['Rating'].max()
plt.figure(figsize=(14, 5), dpi=100)
t = np.linspace(min_val, max_val, num=14) # 生成x轴刻度列表
plt.xticks(t)
plt.grid()
plt.hist(df['Rating'].values, bins=13)
plt.xlabel('评分')
plt.ylabel('电影部数')
plt.title('电影评分分布图', fontsize=18)
plt.show()(2)运行结果(截图):
饭店营业额模拟data.csv
1. 生成模拟数据文件
运行下面的程序,在当前文件夹中生成饭店营业额模拟数据文件data.csv,然后完成以下任务。

python
import csv
import random
import datetime
# 打开文件用于写入,如果文件不存在则创建
fn = 'data.csv'
with open(fn, 'w', newline='', encoding='utf-8') as fp:
wr = csv.writer(fp) # 写入对象
wr.writerow(['日期', '销量']) # 写入表头
startDate = datetime.date(2023, 11, 1) # 起始日期
for i in range(365): # 生成365个模拟数据
amount = 300 + i * 5 + random.randint(0, 100) # 生成一个模拟数据
wr.writerow([startDate, amount]) # 写入csv文件
startDate += datetime.timedelta(days=1) # 下一天2. 删除缺失值
使用pandas读取文件data.csv中的数据,创建DataFrame对象,并删除其中所有缺失值。
(1)程序代码:
python
# 删除所有包含缺失值的行
df_cleaned = df.dropna()3. 柱状图显示每个月份的营业额
按月份进行统计,使用matplotlib绘制柱状图显示每个月份的营业额,并把图形保存为本地文件"饭店营业额(按月统计).jpg" 。
(1)程序代码:
python
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 使用宋体显示中文
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
df = pd.read_csv('data.csv')
# 删除所有包含缺失值的行
df = df.dropna()
# 确保日期列是datetime类型,如果不是,则进行转换
df['日期'] = pd.to_datetime(df['日期'])
# 从日期列中提取月份信息,并创建一个新的月份列
df['Month'] = df['日期'].dt.month
# 按月份分组并计算每个月的总营业额
monthly_revenue = df.groupby('Month')['销量'].sum().reset_index()
# monthly_revenue是一个包含'Month'和'Revenue'两列的DataFrame,其中'Revenue'是每个月的总营业额
# 绘制按月份统计的营业额柱状图
plt.figure(figsize=(10, 6))
plt.bar(monthly_revenue['Month'], monthly_revenue['销量'])
plt.xlabel('月份')
plt.ylabel('营业额')
plt.title('饭店营业额')
# 保存图形为本地文件
plt.savefig('饭店营业额(按月统计).jpg')
plt.show()(2)运行结果(截图):
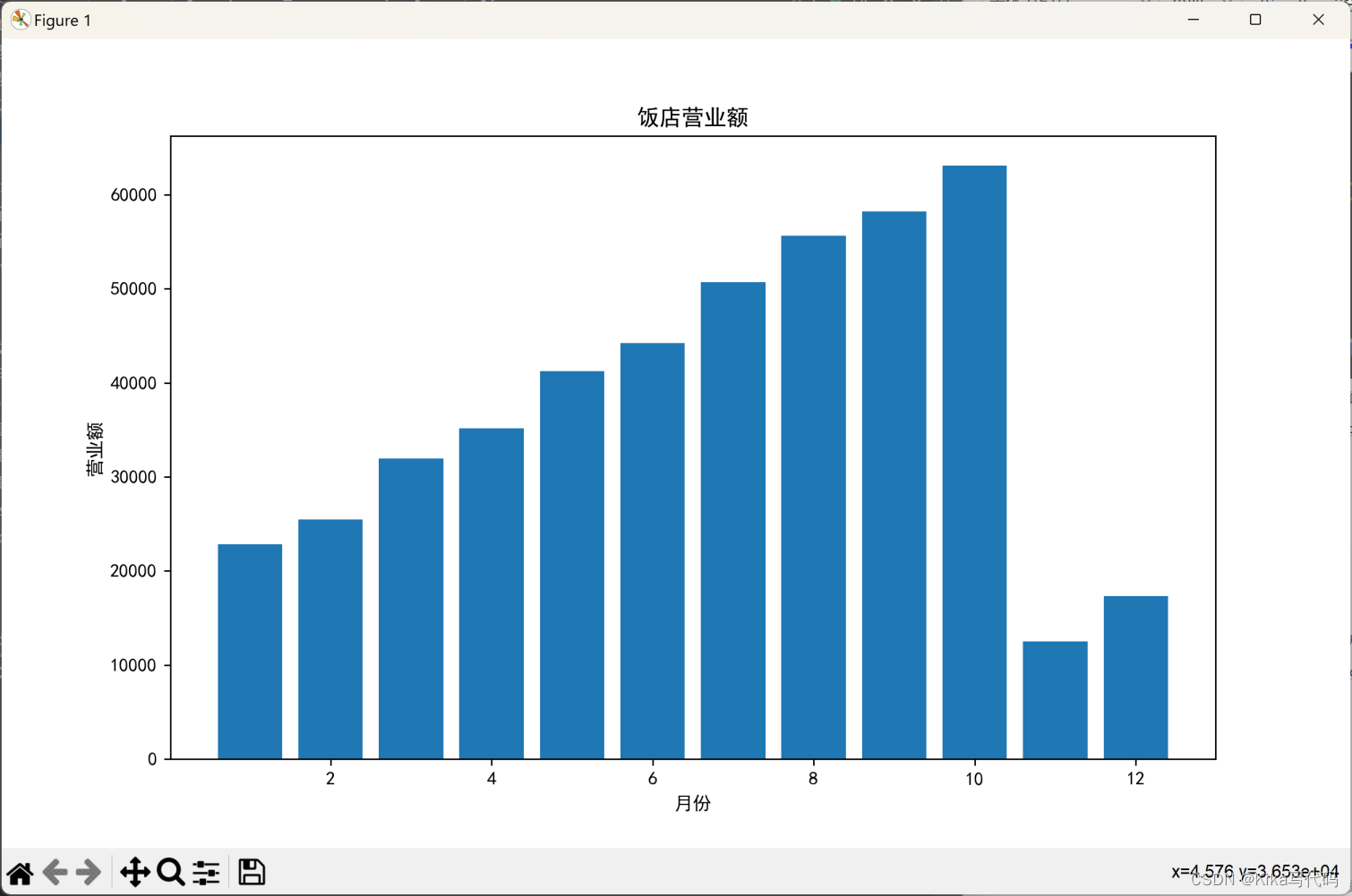
4. 按月份统计涨幅
按月份进行统计,找出相邻两个月最小和最大涨幅,并把涨幅最小的月份写入minMonth.txt、涨幅最大的月份写入文件maxMonth.txt。
(1)程序代码:
python
# 计算每个月的营业额与前一个月的差值,即涨幅
monthly_revenue['Change'] = monthly_revenue['销量'].diff().fillna(0)
# 找出涨幅最小和最大的月份
min_change = monthly_revenue.loc[monthly_revenue['Change'].idxmin()]
max_change = monthly_revenue.loc[monthly_revenue['Change'].idxmax()]
# 将涨幅最小的月份写入minMonth.txt
with open('minMonth.txt', 'w') as f:
f.write(f"{int(min_change['Month'])} {min_change['Change']}\n")
# 将涨幅最大的月份写入maxMonth.txt
with open('maxMonth.txt', 'w') as f:
f.write(f"{int(max_change['Month'])} {max_change['Change']}\n")
print(f"最小涨幅月份: {int(min_change['Month'])},涨幅: {min_change['Change']}")
print(f"最大涨幅月份: {int(max_change['Month'])},涨幅: {max_change['Change']}")(2)运行结果(截图):

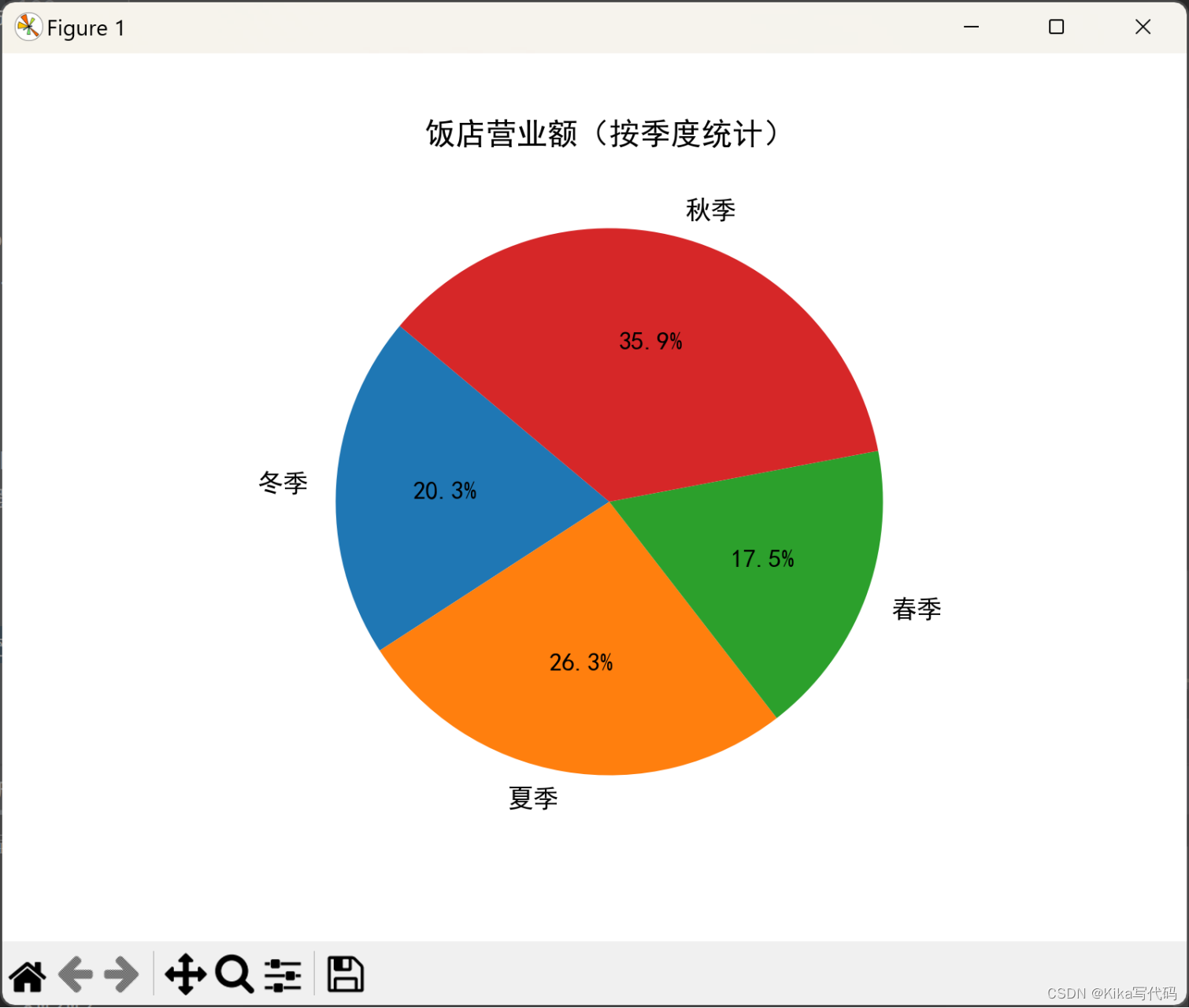
5. 按季度统计营业额
按季度统计该饭店2023年的营业额数据,使用matplotlib生成饼状图显示2023年4个季度的营业额分布情况,并把图形保存未本地文件"饭店营业额(按季度统计).jpg"
(1)程序代码:
python
df['季度'] = df['日期'].dt.quarter
season_map = {1: '春季', 2: '夏季', 3: '秋季', 4: '冬季'}
df['季度'] = df['季度'].map(season_map)
# 按季度对营业额进行分组并求和
quarterly_revenue = df.groupby('季度')['销量'].sum()
# print(quarterly_revenue)
plt.pie(quarterly_revenue, labels=quarterly_revenue.index, autopct='%1.1f%%', startangle=140)
plt.title('饭店营业额(按季度统计)')
plt.savefig('饭店营业额(按季度统计).jpg')
plt.show()(2)运行结果(截图):