文章地址
https://blog.csdn.net/qq_43618881/article/details/118657040
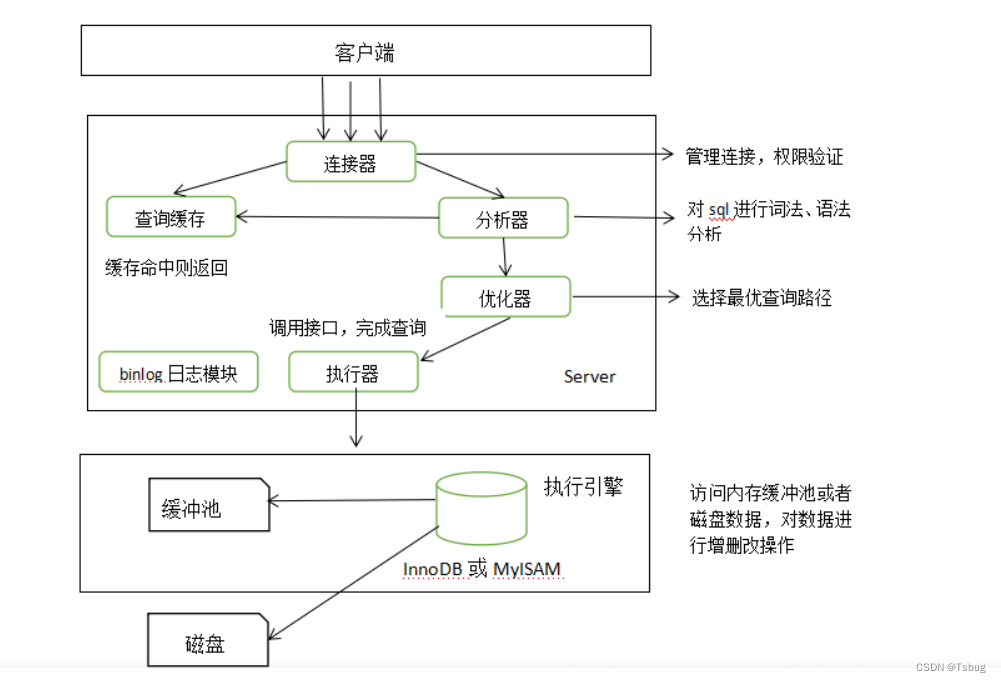
连接器
请求先走到连接器,与客户端建立连接、获取权限、维持和管理连接
mysql缓存池
如果要查找的数据直接在mysql缓存池里面就直接返回数据
分析器
请求已经建立了连接,现在需要对请求的语法进行分析,生成一个语法树
如果语法不对在这里直接报错
优化器
在这里对你写的sql进行优化
比如说表连接查询的时候小表 left join 大表
最后生成执行计划
也就是explain出来的结果
执行器
随后将执行计划交给执行引擎进行操作,比如innodb存储引擎,mysql的存储引擎支持插件化
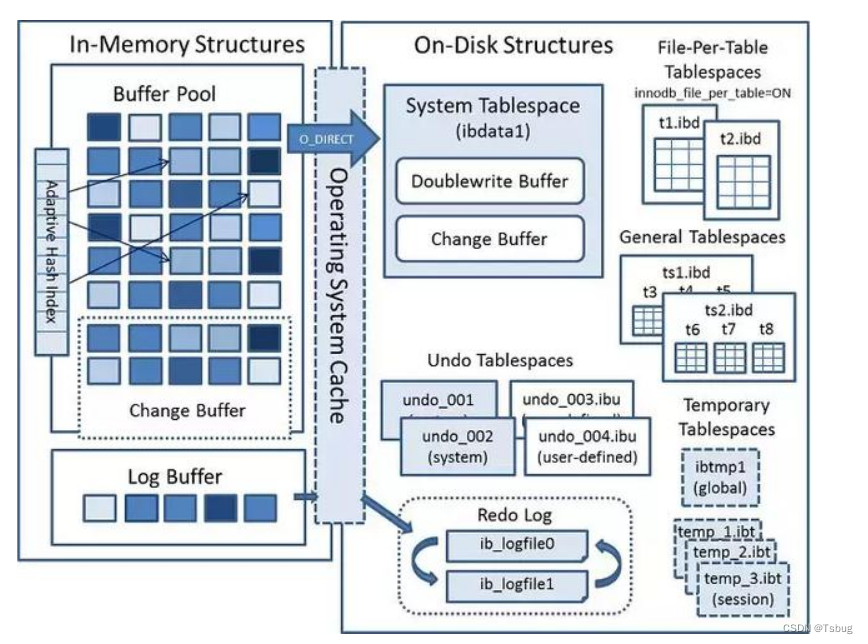
执行引擎
INNODB存储引擎,会对执行计划进行处理
INNODB缓存池
在INNODB里面也有缓存池,里面会有各种各样的脏页
INNODB流程
select
首先查看数据是否在缓存池当中,如果是的话直接对数据进行返回
如果不在缓存池当中从磁盘读取root 的下面的非聚簇索引页,根据slot,进行二分查找,最后按照偏移量找到对应的页表,如果下一个节点还是非聚簇节点,就重复这个步骤,如果不是非聚簇节点,就查找真正的数据
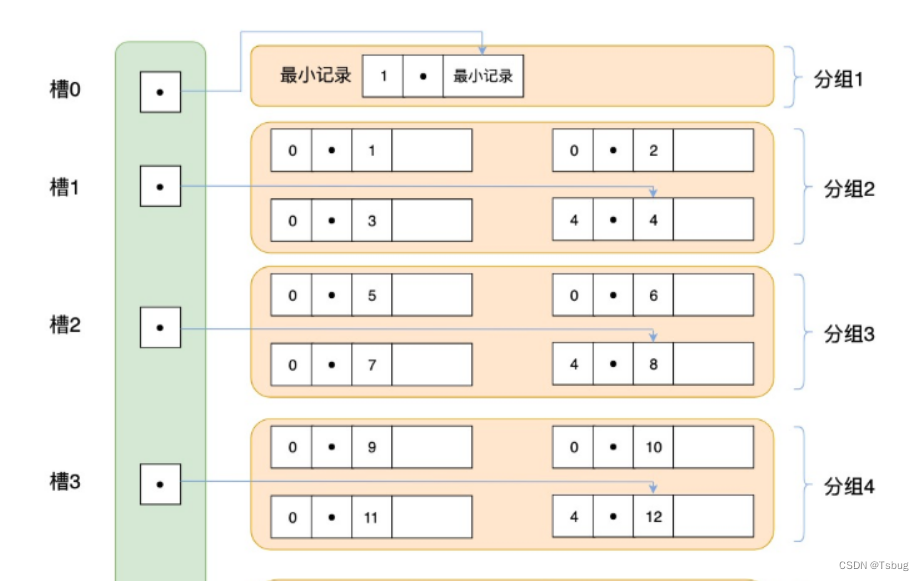
slot槽
slot槽在页头中,每个页都是有的
slot 记录了每一个页的偏移量,是一个数组的结构,可以支持二分查找
先从 B+Tree 的根开始,逐层检索,直到找到叶子节点,也就是找到对应的数据页为止,然后将数据页加载到内存中,页目录中的槽(slot)采用二分查找的方式先找到一个粗略的记录分组,最后在分组中通过链表遍历的方式查找到记录。
insert

先记录undo日志
修改buffer pool中的数据
使用double write buffer 两次写进行持久化
写redo log
redo log 根据设置的频率进行刷盘
记录binlog