Hive on Spark仅在特定版本的Spark上进行测试,因此给定版本的Hive只能保证与特定版本的Spark一起工作。其他版本的Spark可能与给定版本的Hive一起工作,但不能保证。以下是Hive版本及其对应的Spark版本列表:
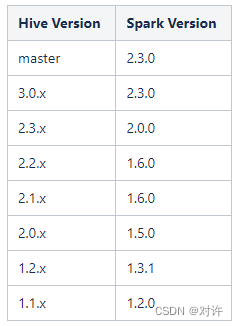
详情参考官方文档:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
Hive on Spark仅在特定版本的Spark上进行测试,因此给定版本的Hive只能保证与特定版本的Spark一起工作。其他版本的Spark可能与给定版本的Hive一起工作,但不能保证。以下是Hive版本及其对应的Spark版本列表:
详情参考官方文档:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started