将Spark安装到指定目录
// 通过wget下载Spark安装包
$ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz
// 将spark解压到安装目录
$ tar --zxvf spark-2.1.1-bin-hadoop2.7.tgz --C /usr/local/
// 重命名
$ mv /usr/local/spark-2.1.1-bin-hadoop2.7 /usr/local/spark设置Spark配置文件
修改 slave 配置文件
$ vim /usr/local/conf/slaves
localhost # 在文件最后将本机主机名将那些添加修改 Spark-Env 配置文件
$ cd /usr/local/spark
$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
$ vim ./conf/spark-env.sh
SPARK_MASTER_HOST=localhost #添加spark master的主机名
SPARK_MASTER_PORT=7077 #添加spark master的端口号
export JAVA_HOME=/usr/local/java/jdk1.8.0_162 #添加javahome如果没有JDK可以安装JDK!!!
启动和关闭Spark服务
启动Spark集群
$ cd /usr/local/spark
$ ./sbin/start-all.sh// 访问Spark 集群,浏览器访问 http://localhost:8080
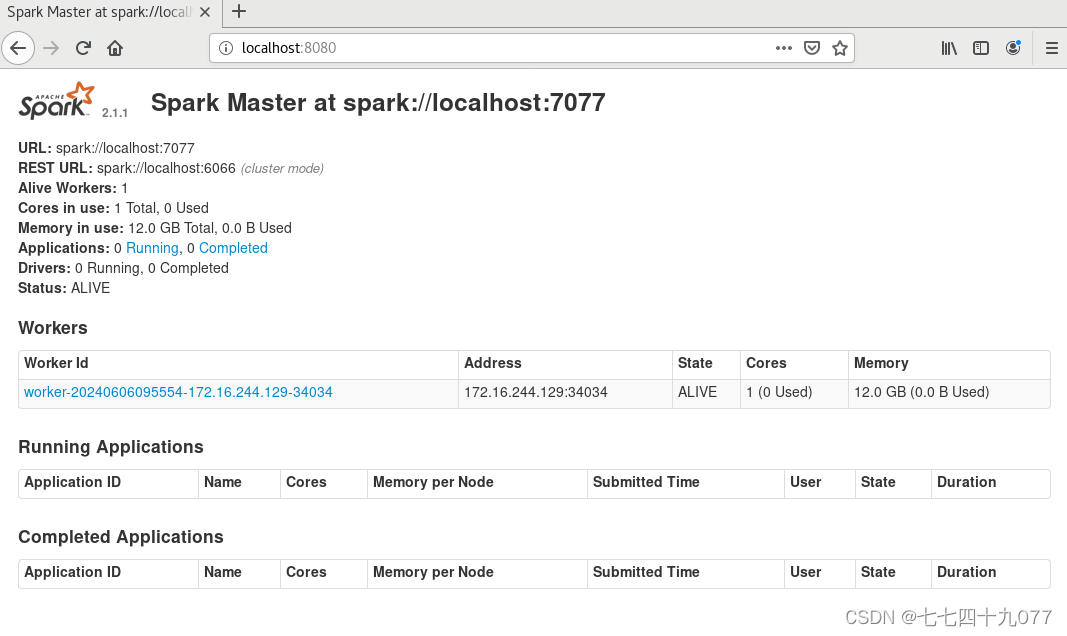
关闭 Spark 集群
$ cd /usr/local/spark
$ ./sbin/stop-all.sh