一、大数据诞生背景
1.传统数据处理架构存在问题
|----------|-------------|---------------|-------------------------------------------|
| | 数据结构类型 | 数据库类型 | 在大数据背景下会产生的问题 |
| 传统数据处理架构 | 结构化数据 | 数据库,数据仓库 | 单机处理速度慢。MPP架构存在扩展性,热点问题 |
| 传统数据处理架构 | 非结构化、半结构化数据 | NoSQL数据库、并发程序 | NoSQL数据库只负责存储,程序处理时涉及到数据移动,数据移动的网络开销大,速度慢 |
2.大数据的特征(4V特征)
- 数据规模巨大(volume)
- 生成和处理速度极快(velocity)
- 数据类型多样但密度较低(variety)
- 价值巨大但密度较低(value)
3.大数据离线与实时场景

4.大数据典型应用场景及架构改进
移动计算而非移动数据

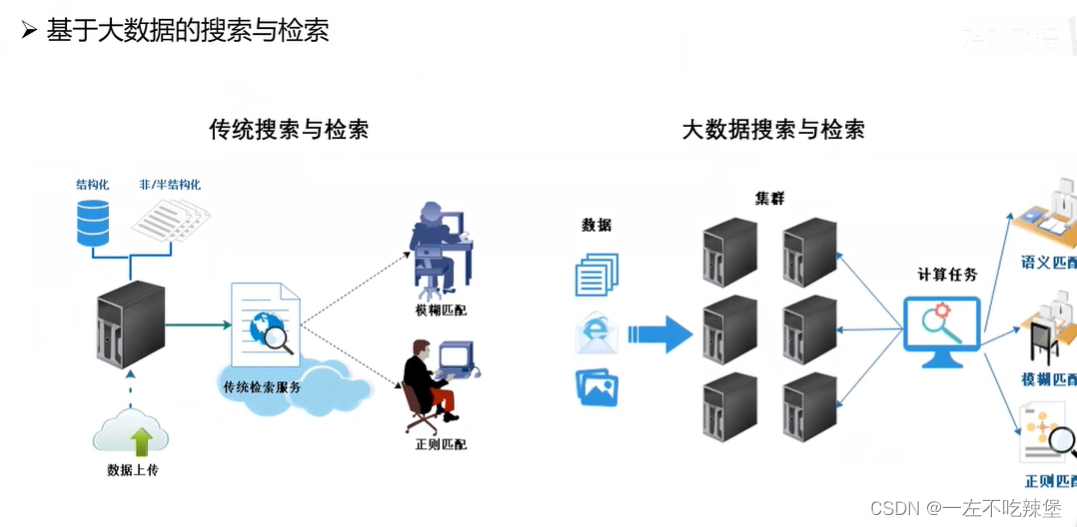
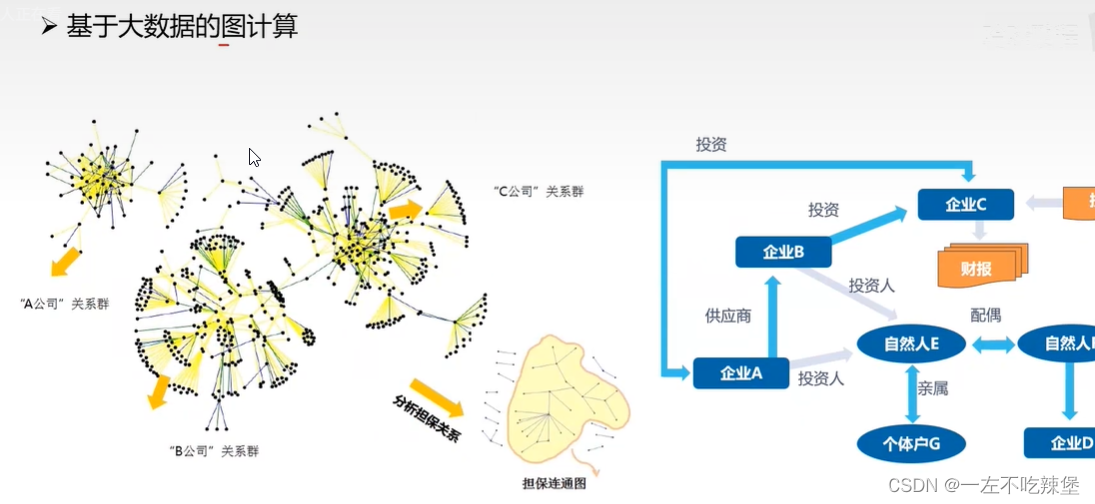

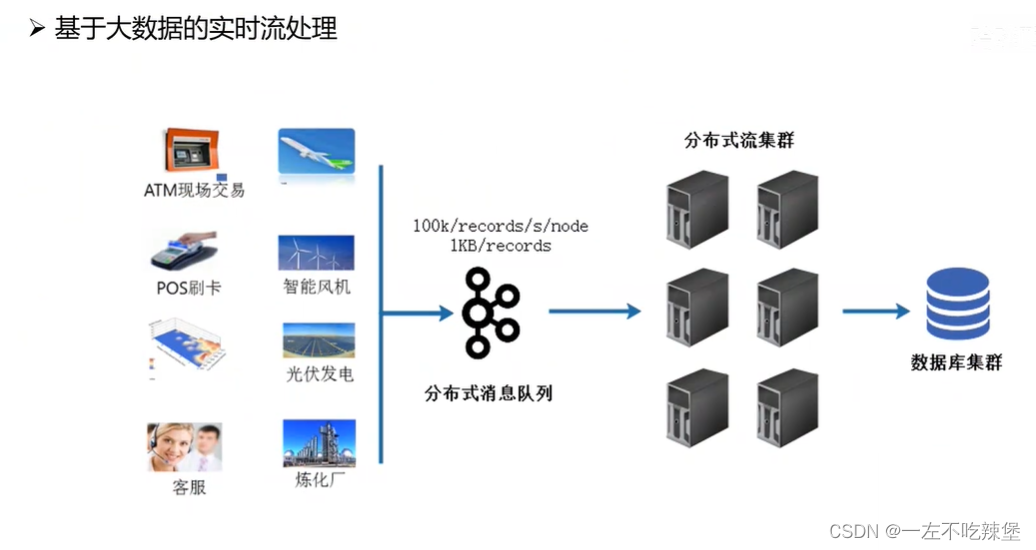
5.大数据的编年史


6.大数据技术生态

二、大数据之HDFS
1.HDFS概念与优缺点
Hadoop分布式文件系统(Hadoop Distributed File System),2003年10月Google发表了GFS(Google File System)论文,HDFS是GFS的开源实现,HDFS是Hadoop的核心子项目(一个三个核心:HDFS、YARN、MapReduce),在开源大数据体系中,地位无可替代
HDFS组成
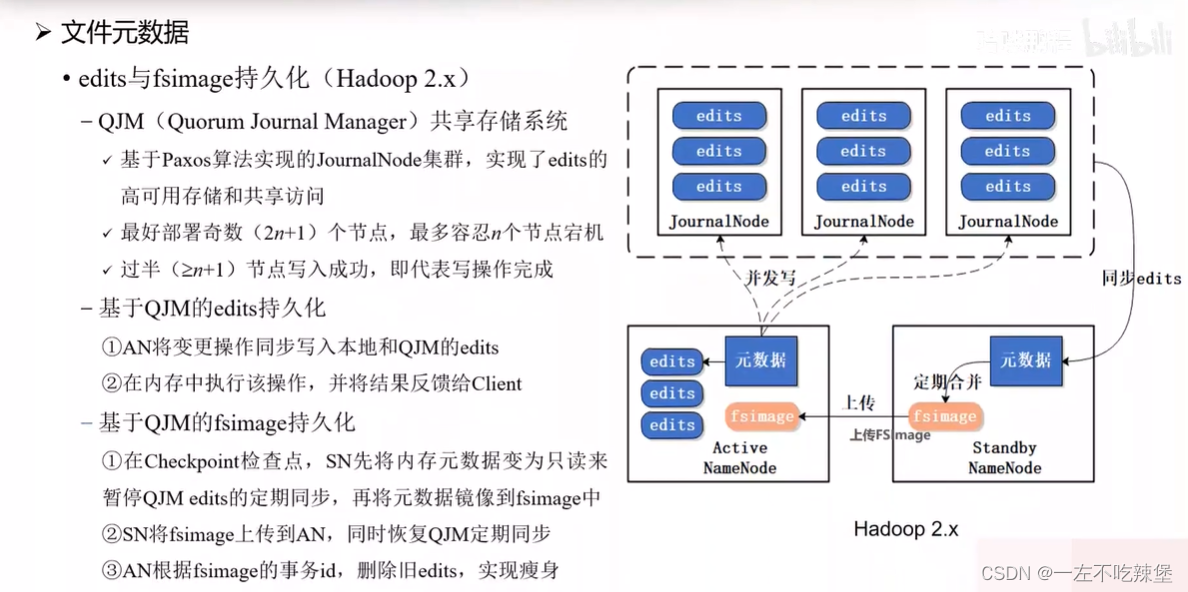
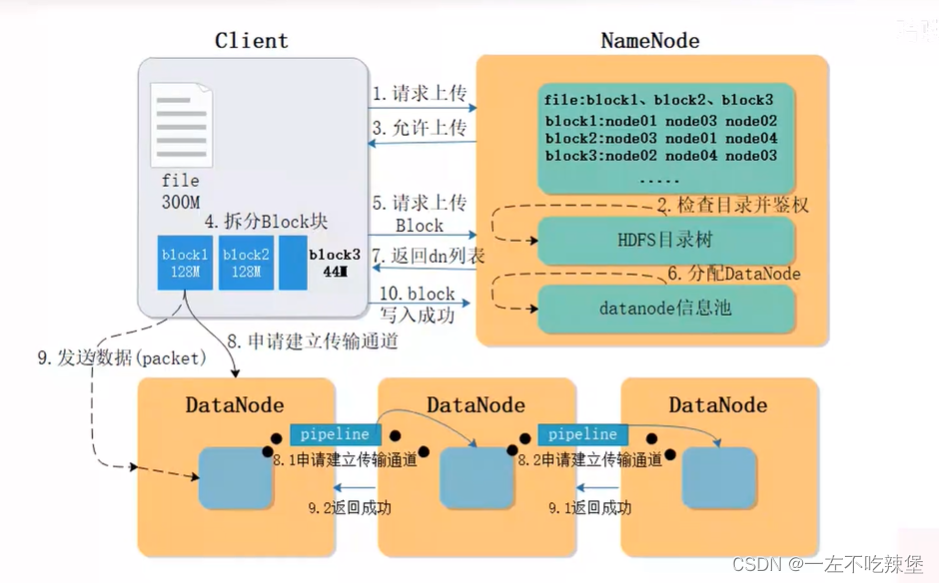
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
HDFS优点
- 高容错、高可用、高扩展
- 海量数据存储:典型文件大小GB~TB,百万以上文件数量,PB以上规模数据
- 构建成本低:构建在廉价的商用服务器上即可
- 安全可靠:提供了容错和恢复机制
- 适合大规模离线批处理
HDFS缺点
- 不适合低延迟数据访问
- **不支持并发写入:**一个文件同时只能有一个写入者
- 不适合大量小文件存储
- 不支持文件随机修改
2.HDFS架构

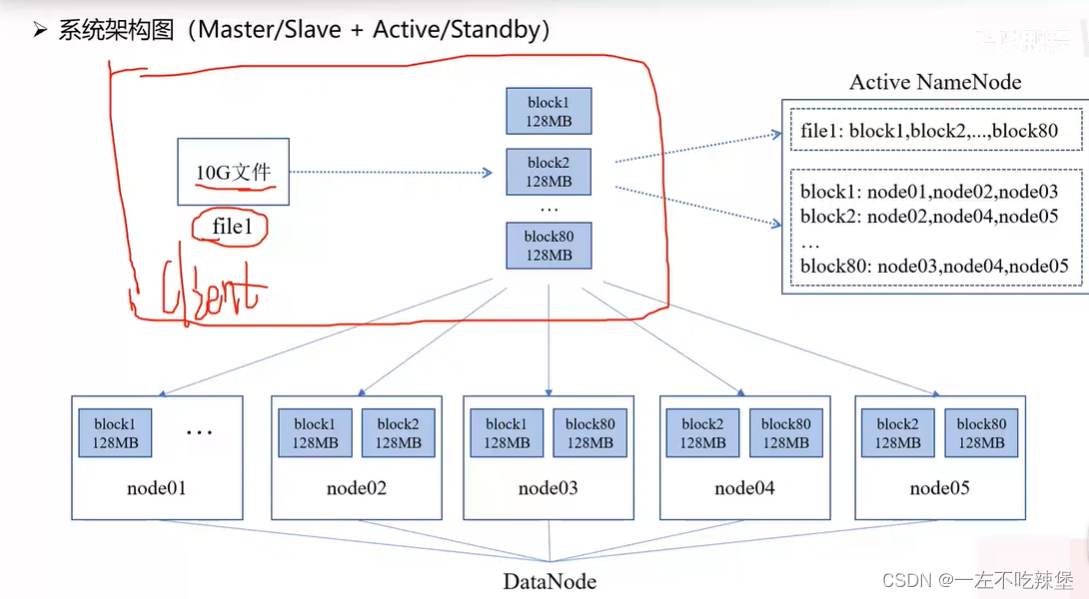
3.HDFS数据存储Block-DataNode



4.HDFS元数据存储-NameNode



5.HDFS读写流程
6.HDFS安全模式


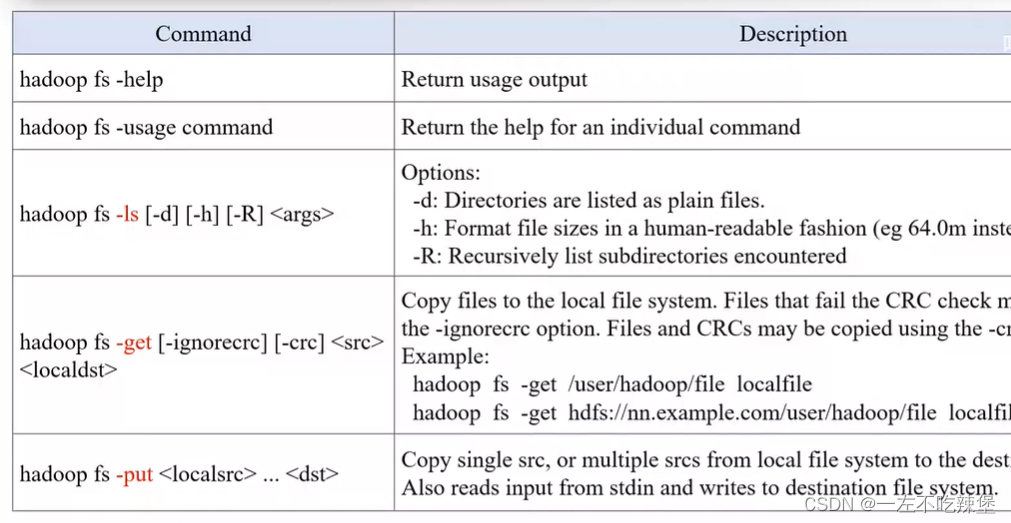
7.HDFS基本用法