一、动态表 & 连续查询(Continuous Query)
1、动态表(Dynamic Tables)
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为"动态表"(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是"静态表";而动态表则完全不同,它里面的数据会随时间变化。
2、 连续查询
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作"持续查询"(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
下图显示了流、动态表和连续查询之间的关系:
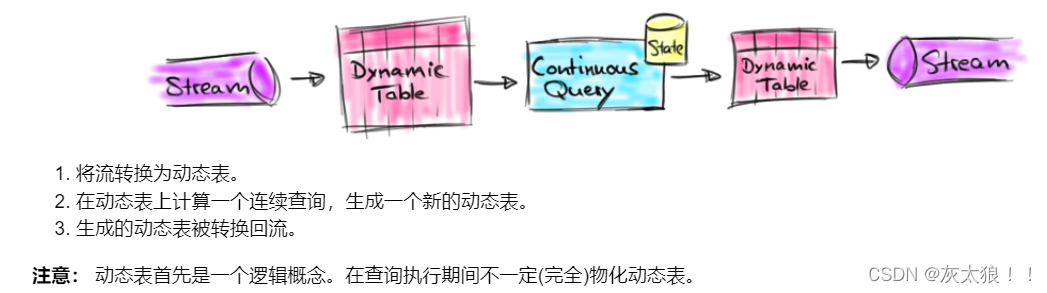
3、在流上定义表
为了使用关系查询处理流,必须将其转换成 Table。从概念上讲,流的每条记录都被解释为对结果表的 INSERT 操作。本质上我们正在从一个 INSERT-only 的 changelog 流构建表。
下图显示了单击事件流(左侧)如何转换为表(右侧)。当插入更多的单击流记录时,结果表将不断增长。

4、三种查询机制
动态表可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。它可能是一个只有一行、不断更新的表,也可能是一个 insert-only 的表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的 Table API 和 SQL 支持三种方式来编码一个动态表的变化:
(1)Append-only 流: 仅通过 INSERT 操作修改的动态表可以通过输出插入的行转换为流。(追加查询 )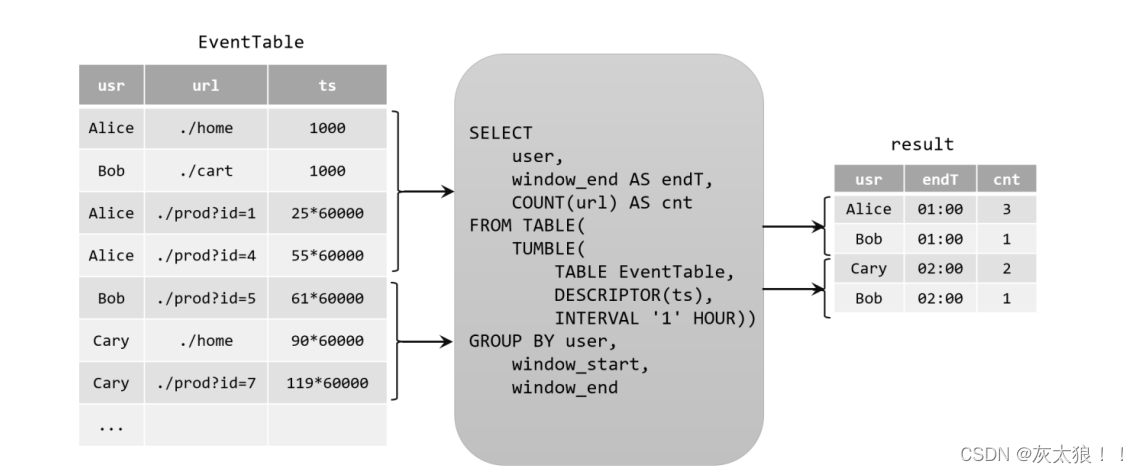
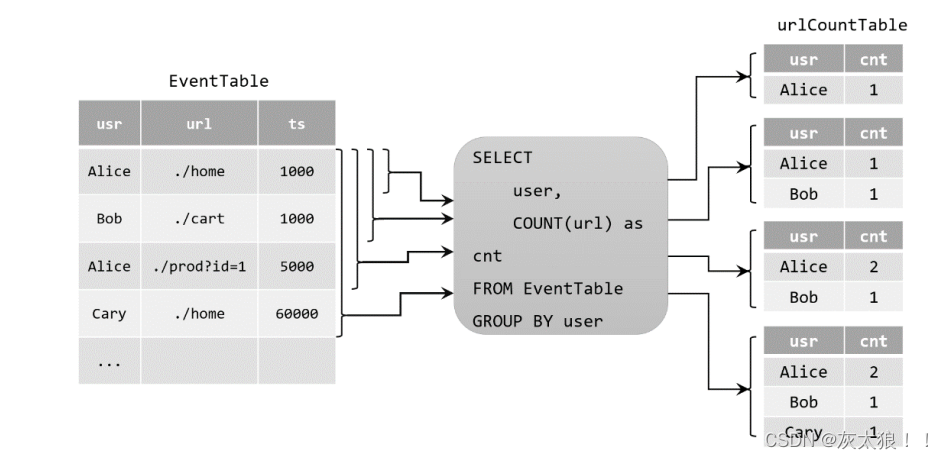
(2)**Upsert 流:**当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用toChangelogStream()方法。
二、准备工作
1、sql - client准备
基于yarn-session模式
1.1启动flink集群
1.2进入sql命令行

2、sql命令行打印结果模式
2.1、表格模式(table mode)
在内存中实体化结果,并将结果用规则的分页表格可视化展示出来,为默认模式。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';
2.2 变更日志模式(changelog mode)
不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'changelog';
2.3 Tableau模式(tableau mode)
更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type),执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'tableau';
3、处理模式
3.1 流处理模式
1、可以用于处理有界流和无界流
2、流处理模式输出连续结果
3、流处理模式底层时持续流模型
执行如下命令启用:
SET 'execution.runtime-mode' = 'streaming';
3.2 批处理模式
1、批处理模式只能用于处理有界流
2、输出最终结果
3、底层是MapReduce模型
执行如下命令启用:
SET 'execution.runtime-mode' = 'batch';
3.3 关系型表/SQL与流处理对比

三、连接器(Connector)
1、kafka
kafka source
sql
-- 创建表 --- 无界流
-- TIMESTAMP(3): 是flink总的时间字段
CREATE TABLE students_kafka (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING,
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 获取kfka时间戳
`partition` BIGINT METADATA VIRTUAL, -- 获取kafka数据所在的分区
`offset` BIGINT METADATA VIRTUAL,-- 偏移量
-- 指定时间字段和水位线生成策略
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'students',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset', --指定读取数据的模式
'format' = 'csv',
'csv.ignore-parse-errors' ='true' -- 当有脏数据时是否跳过当前行
);
select id,name,event_time,`partition`,`offset` from students_kafka;
-- 每隔5秒统计每个班级的人数
select
clazz,
TUMBLE_START(event_time,INTERVAL '5' SECOND) as win_start,
TUMBLE_END(event_time,INTERVAL '5' SECOND) as win_end,
count(id) as num
from
students_kafka
group by
clazz,
-- 滚动的事件时间窗口
TUMBLE(event_time,INTERVAL '5' SECOND);kafka sink
sql
-- 创建sink表
CREATE TABLE students_kafka_sink (
id STRING,
name STRING
) WITH (
'connector' = 'kafka',
'topic' = 'id_name',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
-- 1、将仅插入的结果写入sink表
insert into students_kafka_sink
select id,name from
students_kafka;
-- 查看结果
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic id_name
select * from students_kafka_sink;
-- 2、将更新更改查询结果写入kafka
-- 将更新更改的流写入kafka需要使用canal-json格式,
-- canal-json中带上了数据操作的类型
-- {"data":[{"clazz":"理科六班","num":377}],"type":"INSERT"}
CREATE TABLE clazz_num (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'clazz_num',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json'
);
insert into clazz_num
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;
-- 查看结果
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic clazz_num
select * from clazz_num;2、mysql
准备工作:
将依赖包上传到flink的lib目录下
flink-connector-jdbc-1.15.2.jar
mysql-connector-java-5.1.47.jar
依赖更新后需要重启集群才会生效
yarn application -list
yarn application -kill appid
mysql source
sql
-- 字段名称和字段类型需要和数据库中保存一致
CREATE TABLE students_mysql (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29',
'table-name' = 'student',
'username' ='root',
'password' = '123456'
);mysql sink
sql
-- 创建mysql sink表。需要增加主键约束,flink会通过主键更新数据
CREATE TABLE clazz_num_mysql (
clazz STRING,
num BIGINT,
PRIMARY KEY (clazz) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'clazz_num_mysql', -- 需要手动创建
'username' ='root',
'password' = '123456'
);
insert into clazz_num_mysql
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;**3、**HDFS
hdfs source
sql
-- 创建hdfs source表 -- 有界流
CREATE TABLE students_hdfs (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/bigdata29/data/students.csv', -- 必选:指定路径
'format' = 'csv' -- 必选:文件系统连接器指定 format
);
CREATE TABLE clazz_num_batch (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/clazz_num_batch', -- 必选:指定路径
'format' = 'csv' -- 必选:文件系统连接器指定 format
);
-- 查询数据
insert into clazz_num_batch
select
clazz,
count(1) as num
from
students_hdfs
group by clazz;
-- 创建hdfs source表 -- 无界流
CREATE TABLE students_hdfs_stream (
id int,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/students', -- 必选:指定路径
'format' = 'csv', -- 必选:文件系统连接器指定 format
'source.monitor-interval' = '5000' -- 指定扫描目录的间隔时间
);hdfs sink
sql
-- 将仅追加的结果流写入hdfs
CREATE TABLE students_hdfs_sink (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/students_sink', -- 必选:指定路径
'format' = 'csv' -- 必选:文件系统连接器指定 format
);
insert into students_hdfs_sink
select id,name,age,sex,clazz from students_kafka;
-- 2、将更新更改的结果写入hdfs
CREATE TABLE clazz_num_hdfs (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'hdfs://master:9000/data/clazz_num', -- 必选:指定路径
'format' = 'canal-json' -- 必选:文件系统连接器指定 format
);
insert into clazz_num_hdfs
select
clazz,
count(1) as num
from
students_kafka
group by clazz;4、hbase
准备工作:
将依赖包上传到flink的lib目录下
flink-sql-connector-hbase-2.2-1.15.2.jar
依赖更新后需要重启集群才会生效
yarn application -list
yarn application -kill appid
sql
-- 1、在hbase中创建表
create 'students_flink','info'
-- 创建hbase sink表
CREATE TABLE students_hbase (
id STRING,
info ROW<name STRING,age INT,sex STRING,clazz STRING>, -- 指定列簇中的列
PRIMARY KEY (id) NOT ENFORCED -- 设置hbase 的 rowkey
) WITH (
'connector' = 'hbase-2.2',
'table-name' = 'students_flink',
'zookeeper.quorum' = 'master:2181,node1:2181,node2:2181' --指定zookeeper集群列表
);
insert into students_hbase
select
id,
ROW(name,age,sex,clazz) as info
from students_kafka;
-- 查看结果
select * from students_hbase;
scan 'students_flink'5、datagen
用于随机生成测试数据,可以用于高性能测试
sql
CREATE TABLE students_datagen (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5', -- 指定每秒生成的数据量
'fields.id.length'='5',
'fields.name.length'='3',
'fields.age.min'='1',
'fields.age.max'='100',
'fields.sex.length'='1',
'fields.clazz.length'='4'
);6、print
在task manager中打印结果
sql
CREATE TABLE print_table (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'print'
);
insert into print_table
select * from students_datagen;7、BlackHole
黑洞,数据进入就出不来,用于高性能测试

sql
CREATE TABLE blackhole_table (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'blackhole'
);
insert into blackhole_table
select * from students_datagen;四、数据格式
1、csv
数据中字段的顺序需要和建表语句字段的顺序保持一致 (顺序映射) 默认按照逗号分割
sql
CREATE TABLE students_csv (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'csv', -- 指定数据的格式
'csv.field-delimiter' = ',' ,-- 指定分隔符
'csv.ignore-parse-errors' ='true' -- 跳过脏数据
);2、json
flink表中的字段和类型需要和json中保持一致(同名映射)
sql
CREATE TABLE cars (
car STRING,
city_code STRING,
county_code STRING,
card BIGINT,
camera_id STRING,
orientation STRING,
road_id BIGINT,
`time` BIGINT,
speed DOUBLE
) WITH (
'connector' = 'kafka',
'topic' = 'cars', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'json', -- 指定数据的格式
'json.ignore-parse-errors' ='true'
);3、canal-json
用于保存更新结果流
sql
CREATE TABLE clazz_num (
clazz STRING,
num BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'clazz_num',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'canal-json'
);
insert into clazz_num
select
clazz,
count(1) as num
from
students_kafka
group by
clazz;五、案例
数据为json格式:
{"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"01001","orientation":"西南","road_id":34052056,"time":1614711904,"speed":35.38}
实时统计道路拥堵情况
sql
CREATE TABLE cars (
car STRING,
city_code STRING,
county_code STRING,
card BIGINT,
camera_id STRING,
orientation STRING,
road_id BIGINT,
`time` BIGINT,
speed DOUBLE,
event_time as TO_TIMESTAMP(FROM_UNIXTIME(`time`)),-- 生成新的字段
-- 指定事件时间和水位线
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'cars', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'json', -- 指定数据的格式
'json.ignore-parse-errors' ='true'
);
--每隔1分钟计算最近15分钟每个道路的车流量和平均车速(滑动事件时间窗口)
select
road_id,
HOP_start(event_time,INTERVAL '1' MINUTES, INTERVAL '15' MINUTES) as win_start,
HOP_end(event_time,INTERVAL '1' MINUTES, INTERVAL '15' MINUTES) as win_end,
count(distinct car) as flow,
avg(speed) as avg_speed
from
cars
group by
road_id,
HOP(event_time,INTERVAL '1' MINUTES, INTERVAL '15' MINUTES);