import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
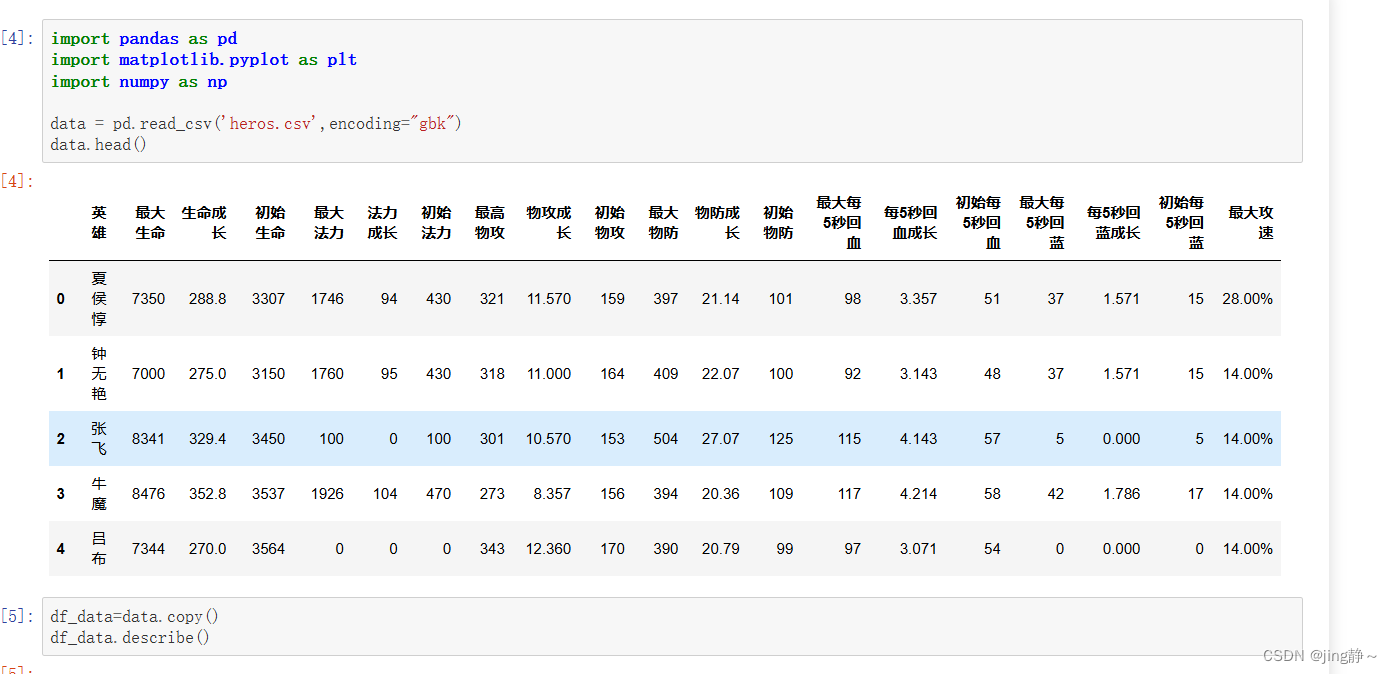
data = pd.read_csv('heros.csv',encoding="gbk")
data.head()导入数据集 进行分析
df_data=data.copy()
df_data.describe()
df_data.info()
df_data.drop('英雄',axis=1,inplace=True)
df_data['最大攻速']=df_data['最大攻速'].apply(lambda str: str.replace('%',''))
from sklearn import preprocessing
for feature in ['初始法力','最高物攻']:
le = preprocessing.LabelEncoder()
le.fit(df_data[feature])
df_data[feature] = le.transform(df_data[feature])
features = df_data.columns.values.tolist()
import seaborn as sns
sns.heatmap(df_data[features].corr(),linewidths=0.1, vmax=1.0, square=True,
cmap=sns.color_palette('RdBu', n_colors=256),
linecolor='white', annot=True)
plt.title('the feature of corr')
plt.show()这里的代码其实还有一点不足 需要进行优化 这里给同学们进步的空间进行改成(提示:需要看看前面倒库有没有具体化)

df_data=df_data[features]
df_data.head()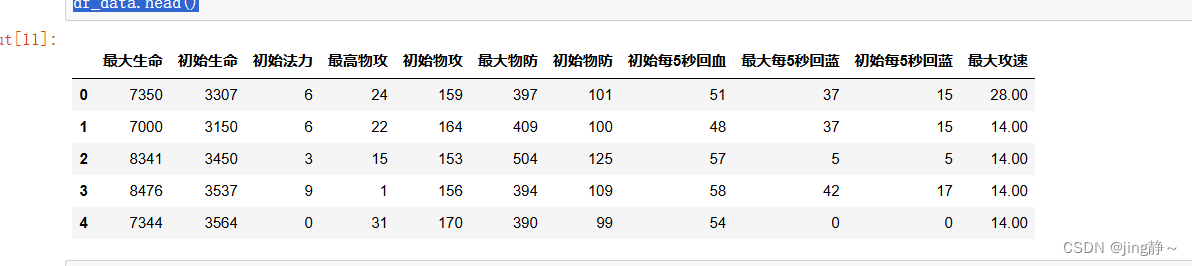
from sklearn.preprocessing import StandardScaler
stas = StandardScaler()
df_data = stas.fit_transform(df_data)
df_data
from sklearn.cluster import KMeans #导入kmeans算法库
n_clusters=3 #设置聚类结果的类簇
kmean = KMeans(n_clusters) #设定算法为KMeans算法
df_data_kmeans=df_data.copy()
kmean.fit(df_data_kmeans) #进行聚类算法训练
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
labels = kmean.labels_ #输出每一样本的聚类的类簇标签
centers = kmean.cluster_centers_ #输出聚类的类簇中心点
print ('各类簇标签值:', labels)
print ('各类簇中心:', centers)
from scipy.spatial.distance import cdist
import numpy as np
#类簇的数量2到9
clusters = range(2, 10)
#距离函数
distances_sum = []
for k in clusters:
kmeans_model = KMeans(n_clusters = k).fit(df_data_kmeans) #对不同取值k进行训练
#计算各对象离各类簇中心的欧氏距离,生成距离表
distances_point = cdist(df_data_kmeans, kmeans_model.cluster_centers_, 'euclidean')
#提取每个对象到其类簇中心的距离(该距离最短,所以用min函数),并相加。
distances_cluster = sum(np.min(distances_point,axis=1))
#依次存入range(2, 10)的距离结果
distances_sum.append(distances_cluster)
plt.plot(clusters, distances_sum, 'bx-') #画出不同聚类结果下的距离总和
# 设置坐标轴的label
plt.xlabel('k')
plt.ylabel('distances')
plt.show() 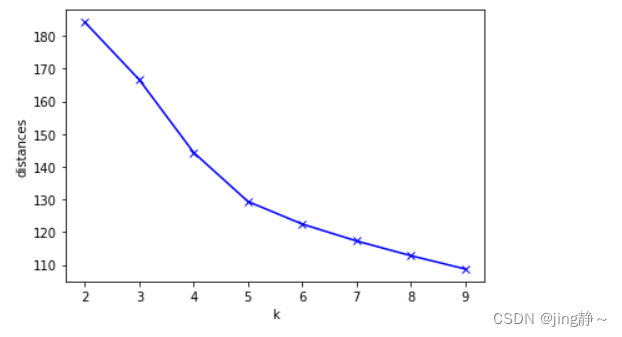
from sklearn.cluster import KMeans #导入kmeans算法库
n_clusters=5 #设置聚类结果的类簇
kmean = KMeans(n_clusters) #设定算法为KMeans算法
df_data_kmeans=df_data.copy()
kmean.fit(df_data_kmeans) #进行聚类算法训练
labels = kmean.labels_ #输出每一样本的聚类的类簇标签
centers = kmean.cluster_centers_ #输出聚类的类簇中心点
print ('各类簇标签值:', labels)
print ('各类簇中心:', centers)
kmeans_result=data.copy()
#将分组结果输出到原始数据集中
kmeans_result.insert(0,'分组',labels)
kmeans_result
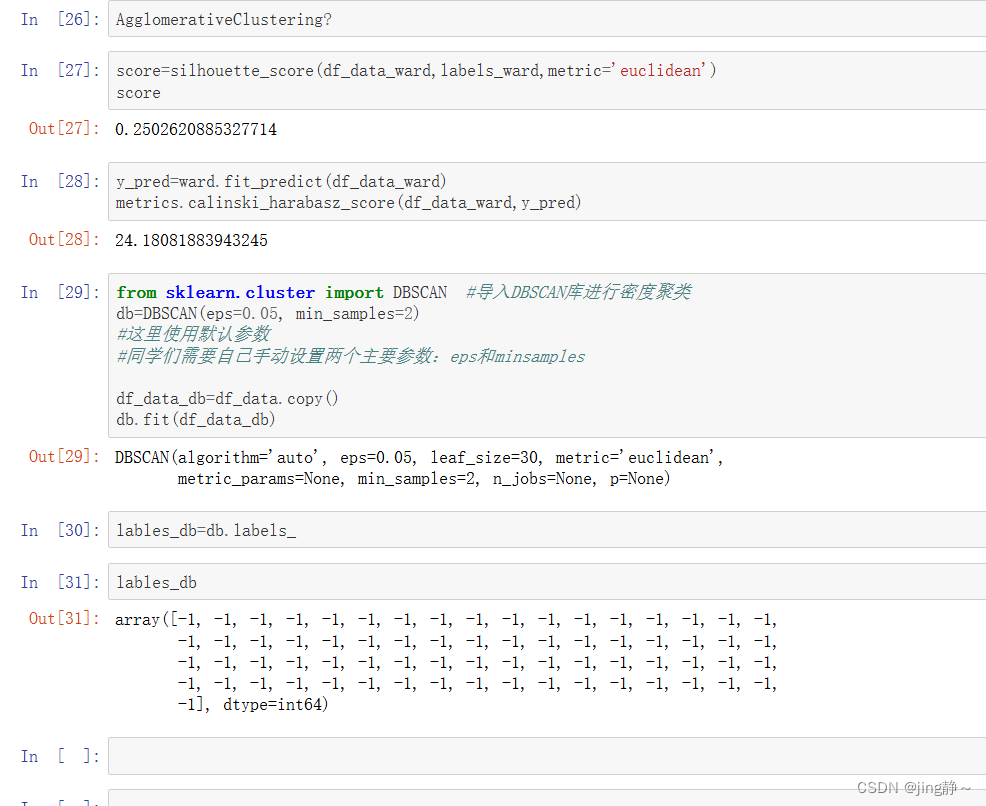
"""根据轮廓系数计算模型得分"""
from sklearn.metrics import silhouette_score
score=silhouette_score(df_data_kmeans,labels,metric='euclidean')
score
0.2939377309323035
from sklearn import metrics
y_pred=kmean.predict(df_data_kmeans)
metrics.calinski_harabasz_score(df_data_kmeans,y_pred)
26.680175815073525
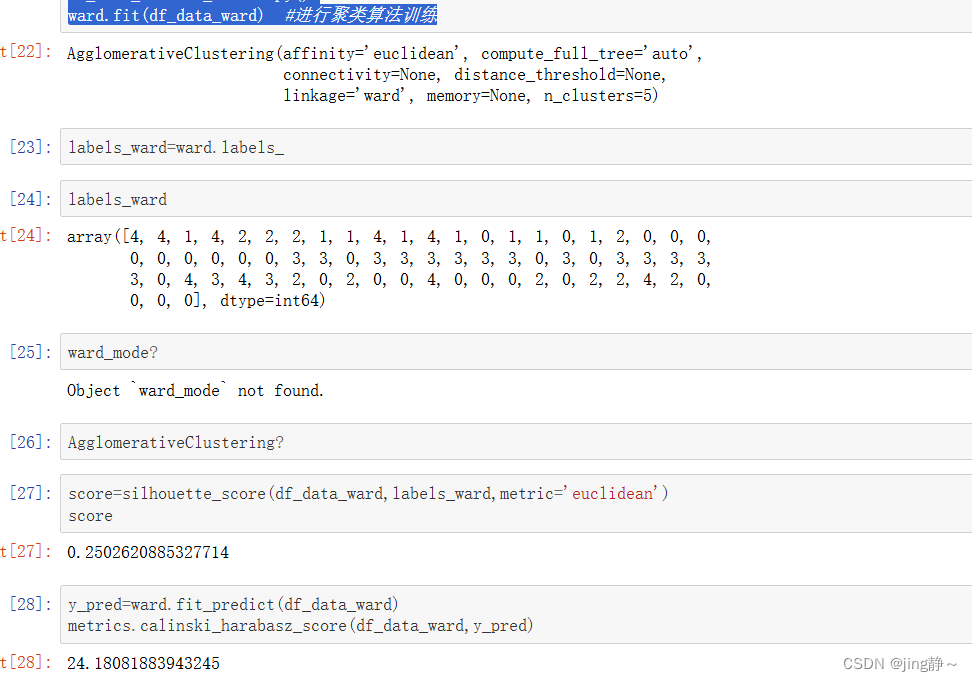
from sklearn.cluster import AgglomerativeClustering #导入凝聚型算法库
n_clusters=5 #设置聚类结果的类簇
#设定算法为AGNES算法,距离度量为最小距离
ward = AgglomerativeClustering(n_clusters, linkage='ward')
df_data_ward=df_data.copy()
ward.fit(df_data_ward) #进行聚类算法训练