一直很慢 🐢
运行中状态、卡住了,可以从以下两种方式入手:
如果 Spark UI 上,有正在运行的 Job/Stage/Task,看 Executor 相关信息就好。💻
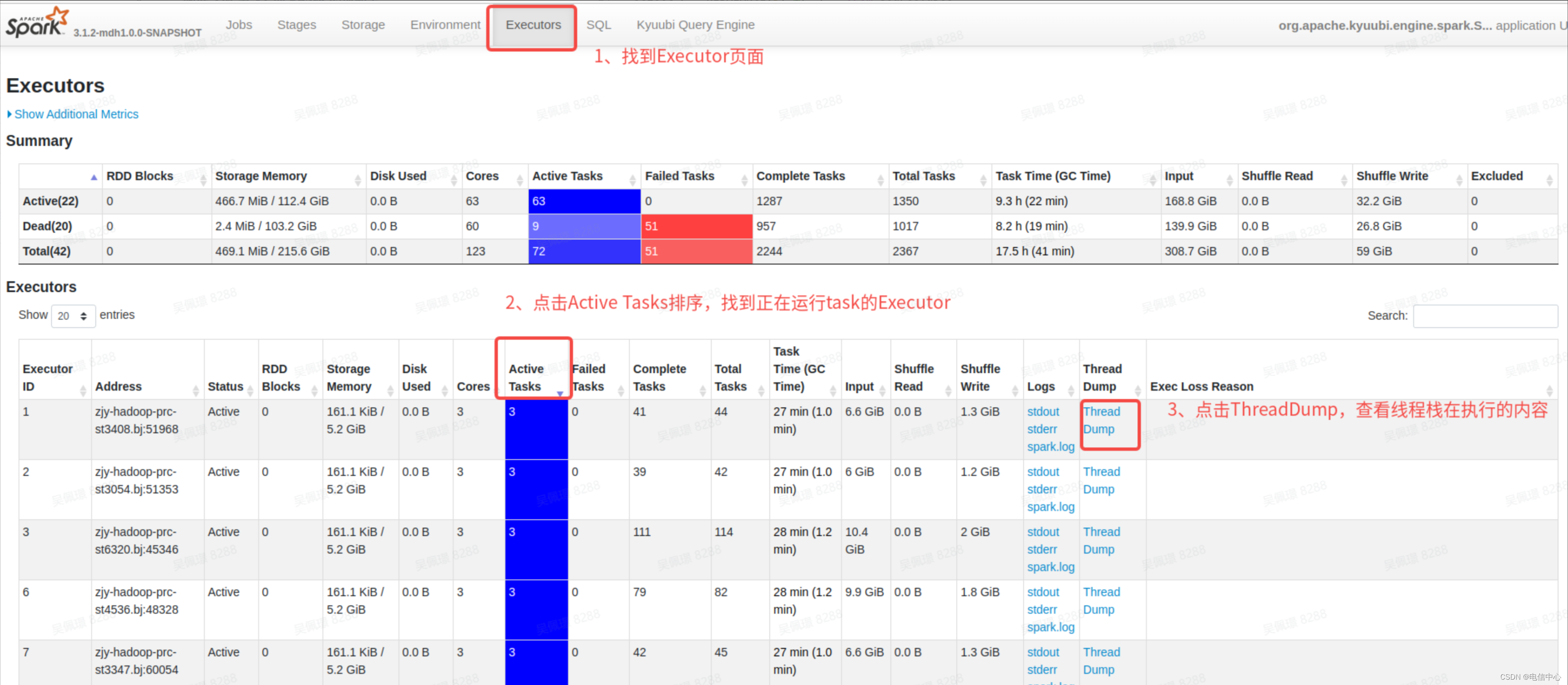
- 第一步,如果发现卡住了,直接找到对应的 Executor 页面:
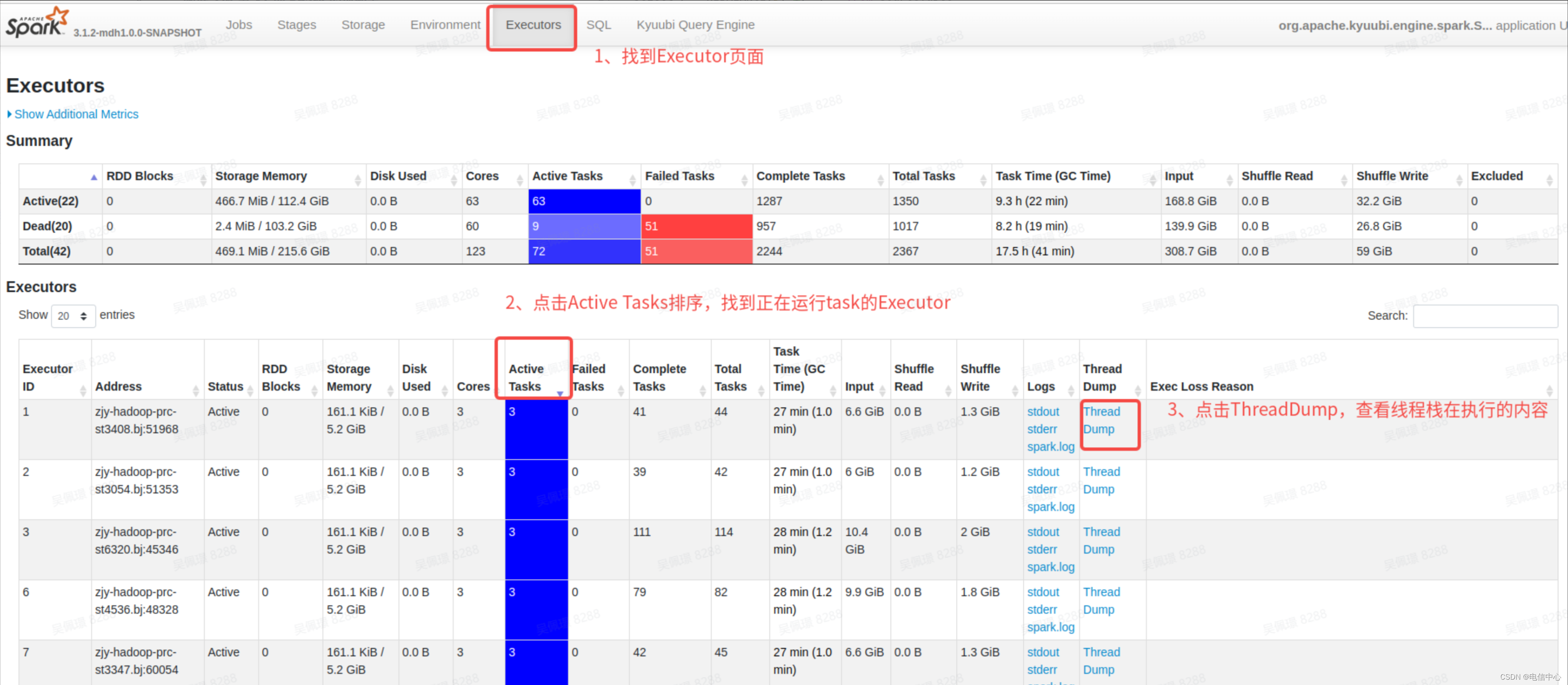
- 第二步,不断的刷新,看看 Task 线程栈执行的内容是什么:
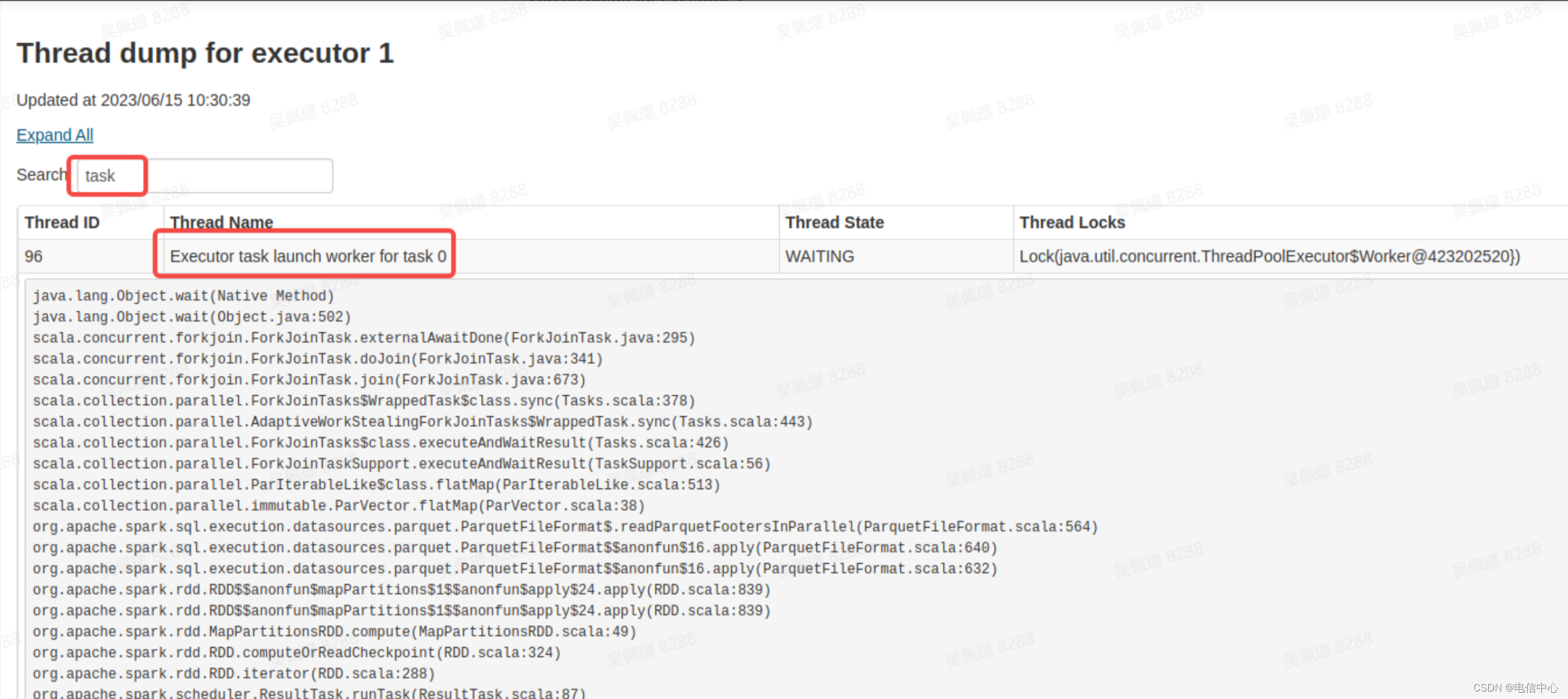
如果 Spark UI 上,没有正在运行的 Job/Stage/Task,看 Driver 相关信息就好。🖥️
- 第一选择是看 Driver 的 ThreadDump,分析 Driver 在执行什么逻辑。
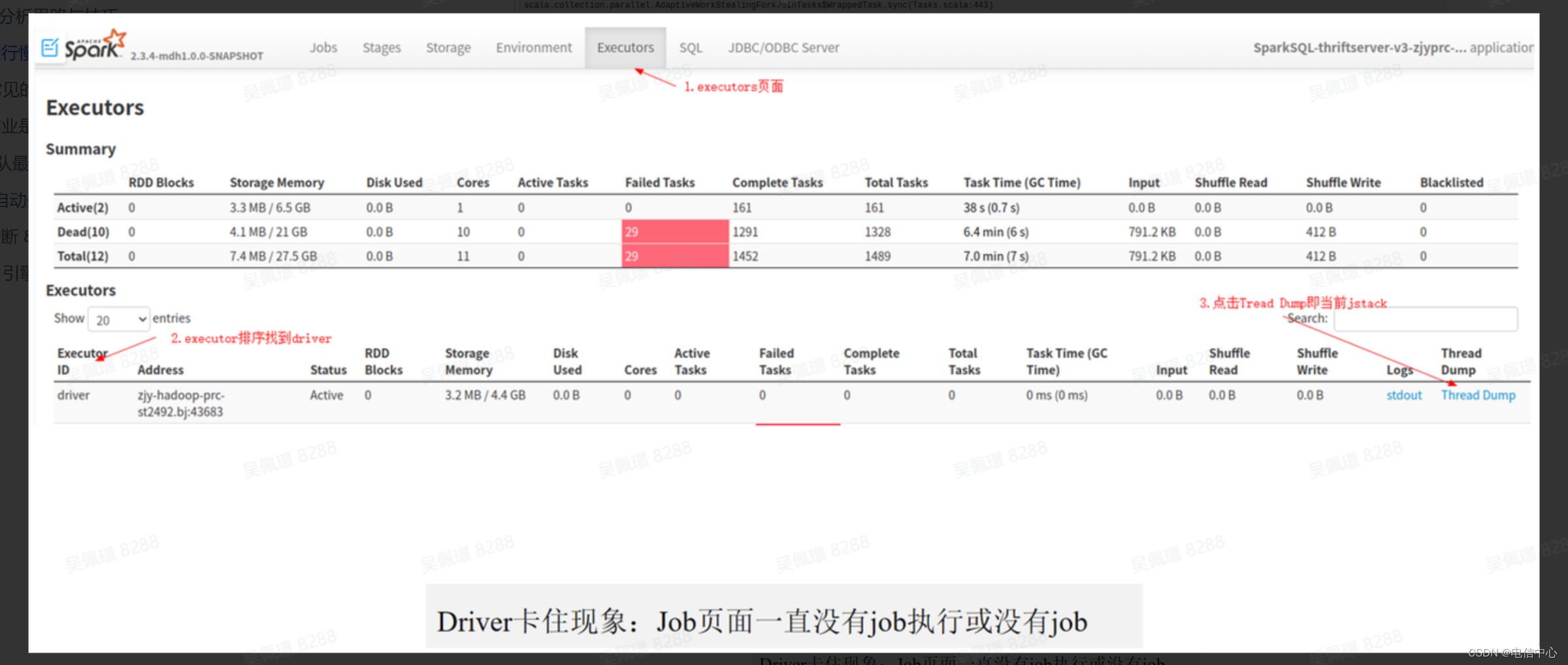
- 第二选择,如果发现 Driver 的线程栈没异常的时候,可以结合 driver 日志查看日志最后的信息是什么。
运行结束了 🏁
- 首先看看是否有执行时间明显比较长(或者对比历史执行时间比较长)的 Job, Stage:
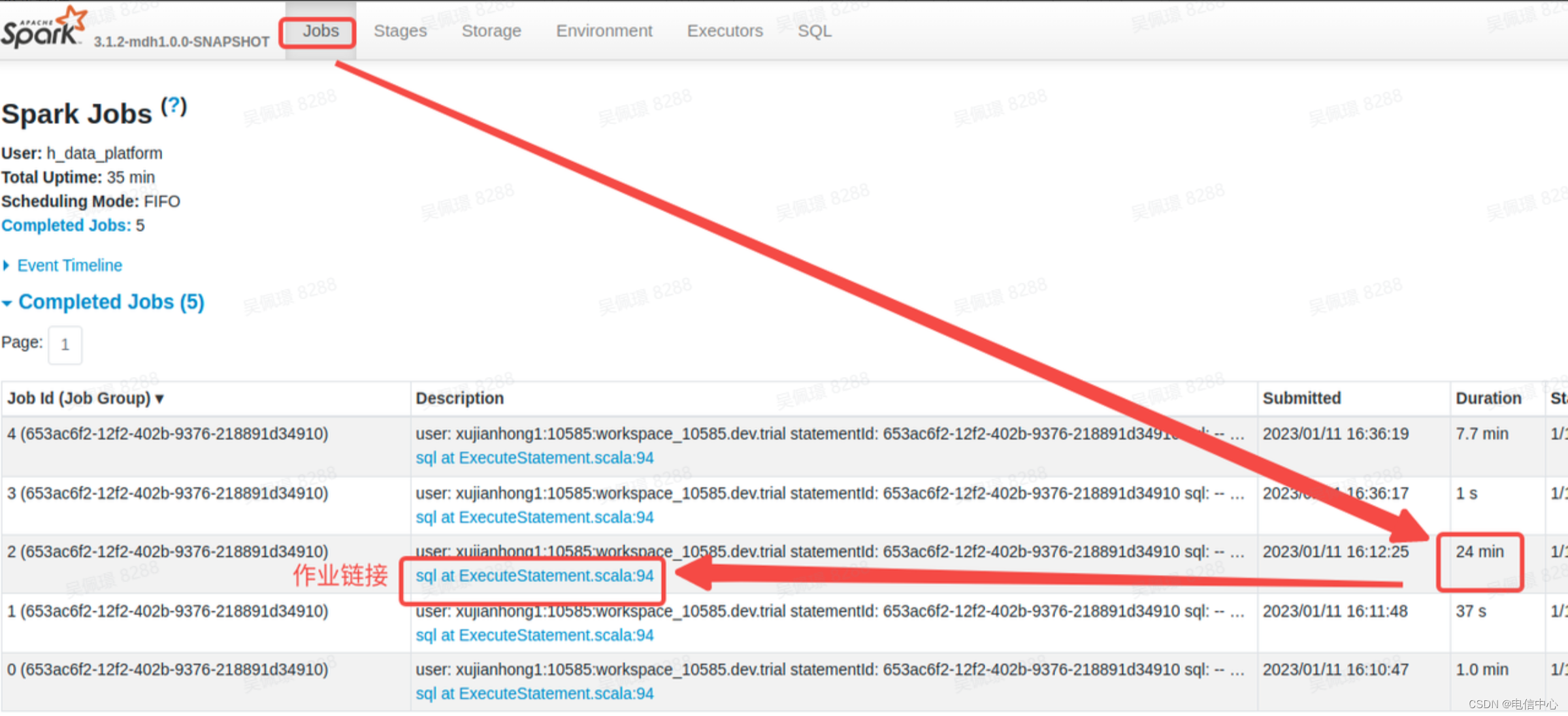
- 查看 Jobs 页面,寻找运行耗时相对较长的作业(注意:这里的 Duration 时间是 Job 启动时间和结束时间的耗时,不代表真正的耗时,例如可能存在多个 Job 同时运行,就会出现受资源影响的情况,可能 Duration 比较长,实际真正执行时间比较短的情况):
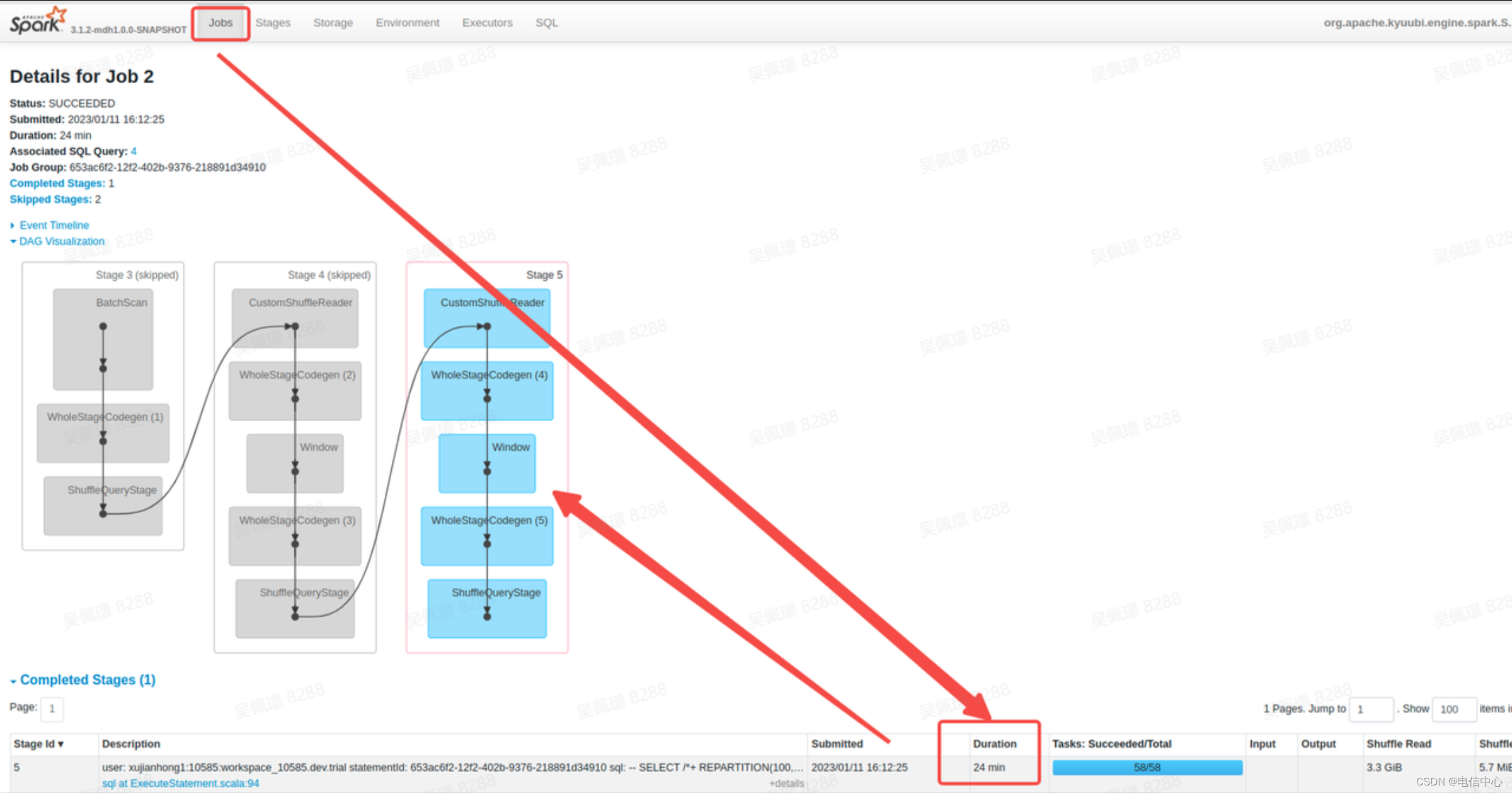
- 查看 Stages 页面,确定运行时间比较长的 Stage(注意,这里的 Duration 和 Job 的 Duration 是一样的,只代表执行起始时间的跨度,不代表实际执行耗时)
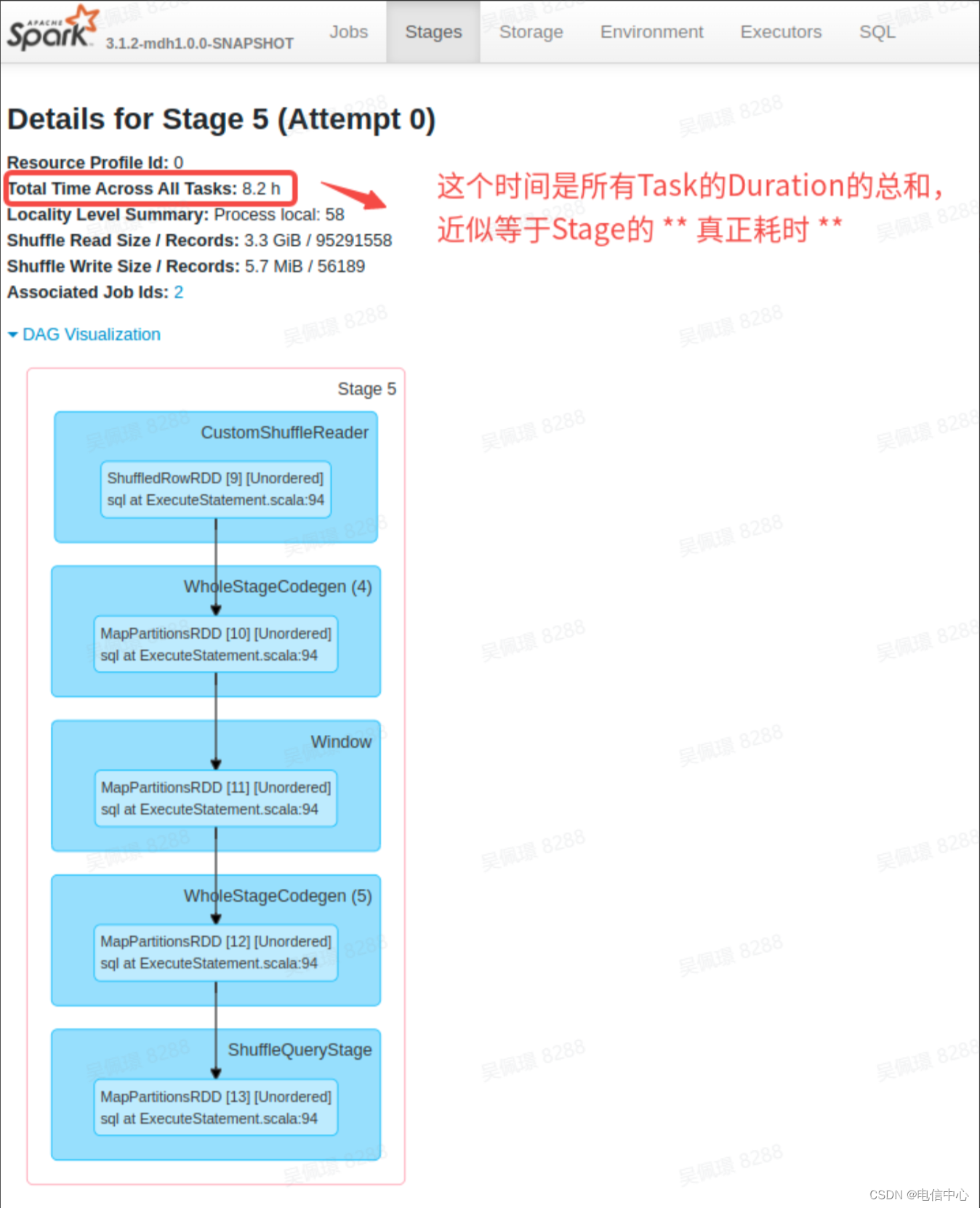
- 查看 Duration 时间比较长的 Stage 的实际执行时间,找到执行时间较长的 Stage:
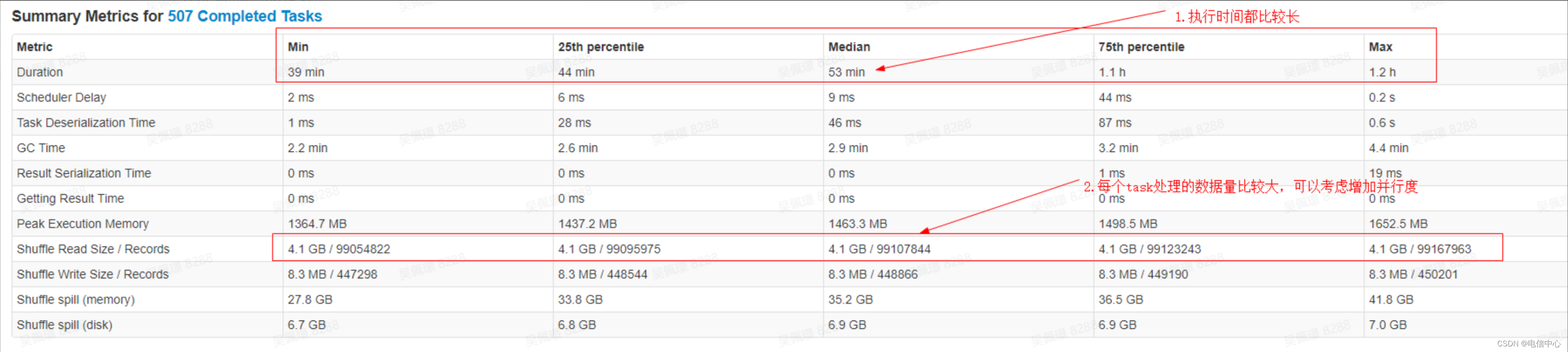
- 还可以查看所有成功 Task 的执行 Metrics 的直方统计图,以便分析数据倾斜等情况,同时注意 GC 时间的占比,分析是否存在内存问题。
- 查看 Jobs 页面,寻找运行耗时相对较长的作业(注意:这里的 Duration 时间是 Job 启动时间和结束时间的耗时,不代表真正的耗时,例如可能存在多个 Job 同时运行,就会出现受资源影响的情况,可能 Duration 比较长,实际真正执行时间比较短的情况):
注意 ⚠️
上面提到了执行慢可能是 资源问题 也可能是 逻辑或者数据问题,如何确定呢:
- 如果上述的 Stage 的详情耗时与历史执行对比,基本一致,那么基本可以判断为资源问题。
- 如果直方图中显示的 Task Duration 有可判断为数据倾斜的情况(个别 Task 慢,且输入或输出数据远大于其他 Task),可能是数据倾斜导致的。
- 如果并不符合数据倾斜的特征,但是某个节点的 Task 执行都慢,可能是机器负载异常导致。
- Spill 指标比较高,可能是内存压力大,spill 至磁盘导致计算变慢,这种情况需要总结和评估是否加内存或者接受稍慢的情况。
比历史慢 🐢
排查步骤:
- 首先对比两次执行的 Job 或者 Stage 是否有明显的运行时间区别。
- 对比执行逻辑是否有改变(例如 broadcast join 变为 sortmerge join),sql 可以查看执行计划,rdd 可以分区 job 的 dag。
- driver 内存压力大,导致调度能力下降(目前可以关注 Driver 的 gc 日志)。
- 对比是否有数据量的变动,查看 stage 的输入输出就可以了:

- 资源的差异,可以查看对应的 stage 的 executor 统计或者队列资源的监控。
- 数据倾斜:
