本文参考自https://github.com/649453932/Chinese-Text-Classification-Pytorch?tab=readme-ov-file,https://github.com/leerumor/nlp_tutorial?tab=readme-ov-file,https://zhuanlan.zhihu.com/p/73176084,是为了进行NLP的一些典型模型的总结和尝试。
中文数据集
从THUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。
以字为单位输入模型,使用了预训练词向量:搜狗新闻 Word+Character 300d。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据处理
共有两个数据处理脚本utils.py和utils_fasttext.py,这里以utils_fasttext.py为例,其中结合了n-gram信息。以下是代码,添加了注释。
python
# coding: UTF-8
import os
import torch
import numpy as np
import pickle as pkl
from tqdm import tqdm
import time
from datetime import timedelta
# 最大词表大小
MAX_VOCAB_SIZE = 10000
# 将UNK,PAD定义为变量,在字典中操作的时候就不需要加引号了
UNK, PAD = '<UNK>', '<PAD>'
# build_vocab接受四个参数:file_path是文本文件的路径,tokenizer是一个分词函数,
# max_size是词汇表最大大小,min_freq是词汇表中词或字符的最小频率
# return一个词汇表字典,键是词,值是索引,这个字典用于将文本转换为数值序列
def build_vocab(file_path, tokenizer, max_size, min_freq):
# 初始化词汇表字典
vocab_dic = {}
# 读取文件
with open(file_path, 'r', encoding='UTF-8') as f:
# 用tqdm库迭代文件中的每一行,并显示进度条
for line in tqdm(f):
# 去除每行文本前后的空白字符
lin = line.strip()
if not lin:
continue
# 每行文本用制表符分隔,取第一部分内容
content = lin.split('\t')[0]
# 分词器进行分词
for word in tokenizer(content):
# 对每个词更新其在字典中的计数,如果不在就默认为0,然后加1
vocab_dic[word] = vocab_dic.get(word, 0) + 1
# 把字典中的项按照频率降序排列,筛选出频率大于min_freq的词,然后取前max_size个词
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] >= min_freq], key=lambda x: x[1], reverse=True)[:max_size]
# 将排序后的词汇列表vocab_list的词作为键,其索引作为值
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}
# 在词汇表中添加特殊标记UNK------未知词,PAD------填充词
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
return vocab_dic
# build_dataset接收两个参数,config配置信息,use_word决定是否词级分词
def build_dataset(config, ues_word):
# 如果是词级分词,那么用空格分隔,否则都变成char
if ues_word:
tokenizer = lambda x: x.split(' ') # 以空格隔开,word-level
else:
tokenizer = lambda x: [y for y in x] # char-level
# 检查vocab_path是否存在词表,如果有则加载这个文件,如果没有就用build_vocab创建词表并序列化保存
if os.path.exists(config.vocab_path):
vocab = pkl.load(open(config.vocab_path, 'rb'))
else:
vocab = build_vocab(config.train_path, tokenizer=tokenizer, max_size=MAX_VOCAB_SIZE, min_freq=1)
pkl.dump(vocab, open(config.vocab_path, 'wb'))
print(f"Vocab size: {len(vocab)}")
# 定义一个生成二元文法哈希值的函数,接收序列,位置t和桶的数量buckets
def biGramHash(sequence, t, buckets):
t1 = sequence[t - 1] if t - 1 >= 0 else 0
return (t1 * 14918087) % buckets
# 定义一个三元文法哈希值的函数,考虑两个前继元素
def triGramHash(sequence, t, buckets):
t1 = sequence[t - 1] if t - 1 >= 0 else 0
t2 = sequence[t - 2] if t - 2 >= 0 else 0
return (t2 * 14918087 * 18408749 + t1 * 14918087) % buckets
# 定义load_dataset,用于加载和处理数据集,接收文件路径path和可选参数pad_size------填充大小,默认32
def load_dataset(path, pad_size=32):
# 初始化空列表来存储处理后的数据
contents = []
# 逐行读取文件
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
# 每行制表符分隔为文本和标签两部分
content, label = lin.split('\t')
# words_line存储每行的words的索引
words_line = []
# 分词和分词后的长度
token = tokenizer(content)
seq_len = len(token)
# 如果长度不足要填充[PAD],长度超过要截断
if pad_size:
if len(token) < pad_size:
# 列表乘法,会创建一个长度是pad_size-len(token),元素全是PAD的列表,用extend添加
token.extend([PAD] * (pad_size - len(token)))
else:
token = token[:pad_size]
seq_len = pad_size
# word to id,如果在词表中找不到就默认为UNK的索引
for word in token:
words_line.append(vocab.get(word, vocab.get(UNK)))
# fasttext ngram,读取config的n_gram的词表大小作为桶个数
buckets = config.n_gram_vocab
bigram = []
trigram = []
# ------ngram------
# 对每个索引位置,生成哈希值
for i in range(pad_size):
bigram.append(biGramHash(words_line, i, buckets))
trigram.append(triGramHash(words_line, i, buckets))
# -----------------
# 将处理后的序列,包括词索引列表,标签,序列长度,二元、三元文法哈希列表,作为一个元组添加到contents列表中
contents.append((words_line, int(label), seq_len, bigram, trigram))
return contents # [[...],x,x,[...],[...]]
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
# 返回词汇表,训练集,验证集和测试集的数据
return vocab, train, dev, test
# DatasetIterater用于迭代数据集,将数据分批加载
class DatasetIterater(object):
# 接收三个参数,batch_size------批次大小,batches------批次列表,device------设备
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
# 计算数据集可以被分成多少个完整的批次
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
# _to_tensor用于将数据转换为Pytorch张量
def _to_tensor(self, datas):
# xx = [xxx[2] for xxx in datas]
# indexx = np.argsort(xx)[::-1]
# datas = np.array(datas)[indexx]
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
bigram = torch.LongTensor([_[3] for _ in datas]).to(self.device)
trigram = torch.LongTensor([_[4] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
return (x, seq_len, bigram, trigram), y
def __next__(self):
# 如果存在剩余批次,则处理最后一个不完整的批次
if self.residue and self.index == self.n_batches:
# 根据index计算最后一个批次的起始位置,并获取剩余的所有数据
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
# 用_to_tensor转换为张量
batches = self._to_tensor(batches)
return batches
# 如果已经处理完所有的批次,重置索引并抛出'StopIteration'异常,表示迭代结束
# 否则,继续处理下一个完整的批次
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
# 返回迭代器自身,实现迭代协议
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
if __name__ == "__main__":
'''提取预训练词向量'''
vocab_dir = "./THUCNews/data/vocab.pkl"
pretrain_dir = "./THUCNews/data/sgns.sogou.char"
emb_dim = 300
filename_trimmed_dir = "./THUCNews/data/vocab.embedding.sougou"
word_to_id = pkl.load(open(vocab_dir, 'rb'))
embeddings = np.random.rand(len(word_to_id), emb_dim)
f = open(pretrain_dir, "r", encoding='UTF-8')
for i, line in enumerate(f.readlines()):
# if i == 0: # 若第一行是标题,则跳过
# continue
lin = line.strip().split(" ")
if lin[0] in word_to_id:
idx = word_to_id[lin[0]]
emb = [float(x) for x in lin[1:301]]
embeddings[idx] = np.asarray(emb, dtype='float32')
f.close()
np.savez_compressed(filename_trimmed_dir, embeddings=embeddings)训练脚本
把模型权重初始化、训练、评估、测试部分放到了train_eval.py里
python
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from tensorboardX import SummaryWriter
# 权重初始化,默认xavier,根据每层的神经元数量来自动计算初始化参数方差的方法
def init_network(model, method='xavier', exclude='embedding', seed=123):
# named_parameters返回一个包含参数名称和参数本身的迭代器
for name, w in model.named_parameters():
# 如果参数的名称中不包含exclude指定的字符串,默认为embedding,则对该参数进行初始化
if exclude not in name:
# 参数名称包含'weight',则认为是权重参数,根据指定初始化方法进行初始化
if 'weight' in name:
if method == 'xavier':
# xavier正态分布初始化
nn.init.xavier_normal_(w)
elif method == 'kaiming':
# kaiming正态分布初始化
nn.init.kaiming_normal_(w)
else:
# 标准正态分布初始化
nn.init.normal_(w)
elif 'bias' in name:
# 偏置初始化为常数0
nn.init.constant_(w, 0)
else:
# 其他参数不进行任何操作
pass
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
# 学习率指数衰减,每次epoch:学习率 = gamma * 学习率
# scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
# scheduler.step() # 学习率衰减
# 在迭代数据集那里的to_tensor返回的是(x, seq_len, bigram, trigram), y这种形式
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
# outputs.data是输出张量的数据部分,每一行包含了对应于一个样本的类别分数
# torch.max(outputs.data, 1)沿第1维进行操作,返回每个样本中的最大值和索引,这里选取索引[1]
predic = torch.max(outputs.data, 1)[1].cpu()
# 准确率
train_acc = metrics.accuracy_score(true, predic)
# 用evaluate函数评估模型在验证集上的性能,返回验证集准确率和损失
dev_acc, dev_loss = evaluate(config, model, dev_iter)
# 更新最好的损失,保存模型的字典状态
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
# 将训练和验证的损失及准确率添加到TensorBoard
writer.add_scalar("loss/train", loss.item(), total_batch)
writer.add_scalar("loss/dev", dev_loss, total_batch)
writer.add_scalar("acc/train", train_acc, total_batch)
writer.add_scalar("acc/dev", dev_acc, total_batch)
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
writer.close()
test(config, model, test_iter)
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)主程序
run.py是主程序,有一个必要参数和两个可选参数,详细注释添加到了代码里。
python
# coding: UTF-8
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
# 创建了一个ArgumentParser对象,用于处理命令行参数。description参数提供一个描述,在生成帮助信息时显示
parser = argparse.ArgumentParser(description='Chinese Text Classification')
# 向ArgumentParser添加新的命令行参数,--model是添加参数的名称,这是一个必须的参数,因为有required=True,参数被转换成str
parser.add_argument('--model', type=str, required=True, help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
# 名为-embedding的可选参数,有默认值pre_trained
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')
# 名为-word的可选布尔参数,默认值为False,表示使用字符级别,否则使用单词级别(True)
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')
# 调用parse_args方法来解析命令行参数,解析后的结果被存储在args变量中
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews' # 数据集
# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random
embedding = 'embedding_SougouNews.npz'
if args.embedding == 'random':
embedding = 'random'
model_name = args.model # 'TextRCNN' # TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer
# FastText的数据处理、迭代器构建或时间获取的方式可能与其他的模型不同
if model_name == 'FastText':
from utils_fasttext import build_dataset, build_iterator, get_time_dif
embedding = 'random'
else:
from utils import build_dataset, build_iterator, get_time_dif
# import module
x = import_module('models.' + model_name)
# 配置参数
config = x.Config(dataset, embedding)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
vocab, train_data, dev_data, test_data = build_dataset(config, args.word)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
config.n_vocab = len(vocab)
model = x.Model(config).to(config.device)
if model_name != 'Transformer':
init_network(model)
print(model.parameters)
train(config, model, train_iter, dev_iter, test_iter)Fasttext
论文:https://arxiv.org/abs/1607.01759
代码:https://github.com/facebookresearch/fastText
Fasttext是Facebook推出的一个便携的工具,包含文本分类和词向量训练两个功能。
Fasttext的分类实现很简单:把输入转换为词向量,取平均再经过线性分类器得到类别。输入的词向量可以是预先训练好的,也可以随机初始化,跟着分类任务一起训练。
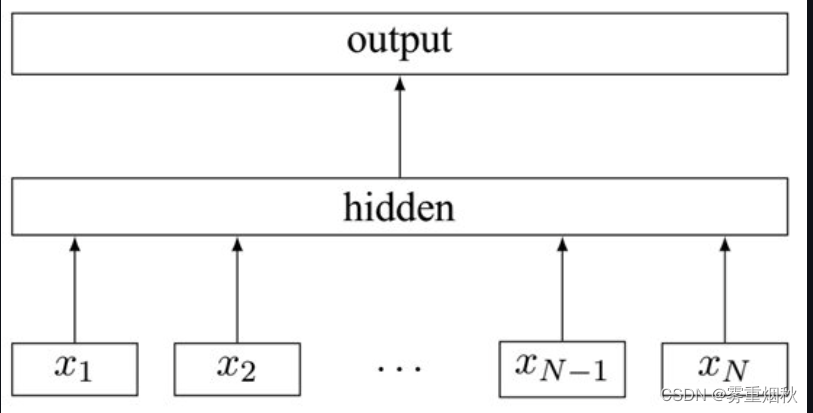
Fasttext直到现在还被不少人使用,主要有以下优点:
- 模型本身复杂度低,但效果不错,能快速产生任务的baseline
- Facebook使用C++进行实现,进一步提升了计算效率
- 采用了char-level的n-gram作为附加特征,比如paper的trigram是pap, ape, per,在将输入paper转为向量的同时也会把trigram转为向量一起参与计算。这样一方面解决了长尾词的OOV(out-of-vocabulary)问题,一方面利用n-gram特征提升了表现
- 当类别过多时,支持采用hierarchical softmax进行分类,提升效率
对于文本长且对速度要求高的场景,Fasttext是baseline首选。同时用它在无监督语料上训练词向量,进行文本表示也不错。不过想继续提升效果还需要更复杂的模型。
知识回顾
由于这里的Fasttext结合了n-gram语言模型,因此需要回顾一下n-gram语言模型的原理。
n-gram语言模型
语言模型计算特定序列中多个单词以一定顺序出现的概率。一个 m m m个单词的序列 w 1 , . . . , w m {w_1,...,w_m} w1,...,wm的概率定义为 P ( w 1 , . . . , w m ) P(w_1,...,w_m) P(w1,...,wm)。单词 w i w_i wi前有一定数量的单词,其特性会根据它在文档中的位置而改变, P ( w 1 , . . . , w m ) P(w_1,...,w_m) P(w1,...,wm)一般只考虑前 n n n个单词而不是考虑全部之前的单词。
P ( w 1 , . . . , w m ) = ∏ i = 1 i = m P ( w i ∣ w 1 , . . . , w i − 1 ) ≈ ∏ i = 1 i = m P ( w m ∣ w i − n , . . . , w i − 1 ) P(w_1,...,w_m)=\prod^{i=m}{i=1} P(w_i | w_1,...,w{i-1})\approx \prod^{i=m}{i=1}P(w_m|w{i-n},...,w_{i-1}) P(w1,...,wm)=i=1∏i=mP(wi∣w1,...,wi−1)≈i=1∏i=mP(wm∣wi−n,...,wi−1)
上面的公式在语言识别和机器翻译系统中有重要的作用,它可以辅助筛选语音识别和机器翻译的最佳结果序列。
在现有的机器翻译系统中,对每个短语/句子翻译,系统生成一些候选的词序列(例如, I h a v e , I h a s , I h a d , m e h a v e , m e h a d {Ihave,Ihas,Ihad,mehave,mehad} Ihave,Ihas,Ihad,mehave,mehad),并对其评分以确定最可能的翻译序列。
在机器翻译中,对一个输入短语,通过评判每个候选输出词序列的得分的高低,来选出最好的词顺序。为此,模型可以在不同的单词排序或单词选择之间进行选择。它将通过一个概率函数运行所有单词序列候选项,并为每个候选项分配一个函数,从而实现这一目标。最高得分的序列就是翻译结果。例如:
- 相比
small is the cat,翻译系统会给the cat is small更高的得分; - 相比
walking house after school,翻译系统会给walking home after school更高的得分。
为了计算这些概率,每个n-gram的计数将与每个单词的频率进行比较,这个成为n-gram语言模型。
- 例如,如果选择bi-gram模型(二元语言模型),每一个bi-gram的概率,通过将单词与其前一个单词相结合进行计算,然后除以对应的uni-gram的概率。
下面的公式展示了bi-gram模型和tri-gram模型的区别。
p ( w 2 ∣ w 1 ) = c o u n t ( w 1 , w 2 ) c o u n t ( w 1 ) p(w_2|w_1)=\frac{count(w_1,w_2)}{count(w_1)} p(w2∣w1)=count(w1)count(w1,w2)
p ( w 3 ∣ w 1 , w 2 ) = c o u n t ( w 1 , w 2 , w 3 ) c o u n t ( w 1 , w 2 ) p(w_3|w1,w2)=\frac{count(w_1,w_2,w_3)}{count(w_1,w_2)} p(w3∣w1,w2)=count(w1,w2)count(w1,w2,w3)
上式tri-gram模型的关系主要是基于一个固定的上下文窗口(即前 n n n个单词)预测下一个单词。一般 n n n的取值为多大才好呢?
- 在某些情况下,前面的连续的 n n n个单词的窗口可能不足以捕获足够的上下文信息。例如,考虑句子(类似完形填空,预测下一个最可能的单词):
Asthe proctor started the clock, the students opened their _
如果窗口只是基于前面的三个单词the students opened their,那么基于这些语料计算的下划线中最有可能出现的单词就是为books------但是如果n足够大,能包括全部的上下文,那么下划线中最有可能出现的单词会是exam。
这就引出了n-gram语言模型的两个主要问题:【稀疏性】和【存储】。
1)n-gram语言模型的稀疏性问题
n-gram语言模型的稀疏性问题源于两个问题。
1.对应公式中的分子,可能有稀疏性问题。
- 如果 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3在语料中从未出现过,那么 w 3 w_3 w3的概率就是0。
- 为了解决这个问题,在每个单词计数后面加上一个很小的 δ \delta δ,这就是平滑操作。
2.对应公式中的分母,可能有稀疏性问题。
- 如果 w 1 , w 2 w_1,w_2 w1,w2在语料中从未出现过,那么 w 3 w_3 w3的概率将会无法计算。
- 为了解决这个问题,这里可以只是单独考虑 w 2 w_2 w2,这就是
backoff操作。
增加 n n n会让稀疏问题更加严重,所以一般 n < = 5 n<=5 n<=5。
2)n-gram语言模型的存储问题
需要存储在语料中看到的所有n-gram的统计数。随着 n n n的增加(或语料库大小的增加),模型的大小也会增加。(这里的模型的大小增加并不是统计数的增加,因为滑动窗口,所以随着 n n n的增加,统计数是减少的,但是由于模型需要处理更长的上下文,因此需要存储和计算更多的参数,所以大小增加,因此需要一个合适的 n n n)。
模型结构
- 用哈希算法将2-gram、3-gram信息分别映射到两张表内。这里就是一种利用n-gram思想的特征工程的手段,将词袋模型加入了上下文信息,生成哈希值
- 模型输入:batch_size, seq_len
- embedding层:随机初始化,词向量维度为embed_size,2-gram和3-gram同理:
word: batch_size, seq_len, embed_size
2-gram:batch_size, seq_len, embed_size
3-gram:batch_size, seq_len, embed_size - 拼接embedding层:
batch_size, seq_len, embed_size \* 3 - 求所有seq_len个词的均值
batch_size, embed_size \* 3 - 全连接+非线性激活:隐层大小hidden_size
batch_size, hidden_size - 全连接+softmax归一化:
batch_size, num_class==>batch_size, 1
模型代码
模型代码在Fasttext.py。
python
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'FastText'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.hidden_size = 256 # 隐藏层大小
self.n_gram_vocab = 250499 # ngram 词表大小
'''Bag of Tricks for Efficient Text Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
# 嵌入层,如果有预训练的嵌入矩阵那么就用from_pretrained方法创建嵌入层,freeze=False表示不冻结权重,权重会在训练过程更新
# 如果没有预训练的嵌入矩阵,那么用默认的方式创建嵌入层,config.n_vocab是词汇表的大小,即嵌入层需要包含多少个不同的嵌入向量
# config.embed每个嵌入向量的维度,padding_idx=config.n_vocab-1指定一个索引作为填充索引确保序列一致
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
out_word = self.embedding(x[0])
out_bigram = self.embedding_ngram2(x[2])
out_trigram = self.embedding_ngram3(x[3])
# 在最后一个维度上进行拼接
out = torch.cat((out_word, out_bigram, out_trigram), -1)
# 在维度1求均值,对于序列数据,维度0通常表示不同样本(即批大小),维度1表示序列的长度
out = out.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out这里需要解释输出层为什么没有用softmax函数,如果是多分类任务,使用nn.CrossEntropyLoss()作为损失函数,自动就会实现softmax的效果,pytorch官方文档这么说Note that this case is equivalent to applying LogSoftmax on an input, followed by NLLLoss.,所以加不加softmax那一层效果是一样的。
最终结果
加了n-gram信息的训练和验证过程可视化:
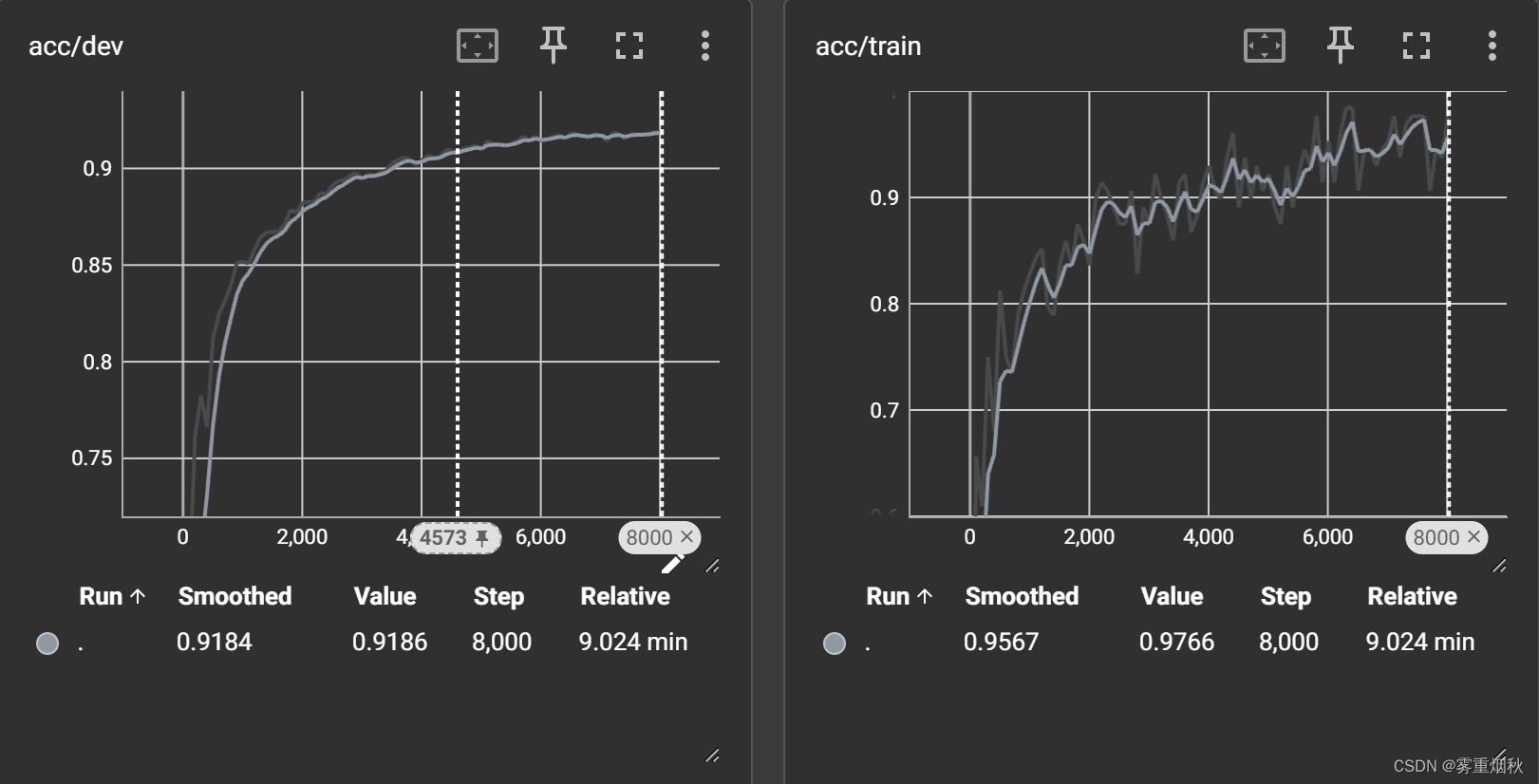
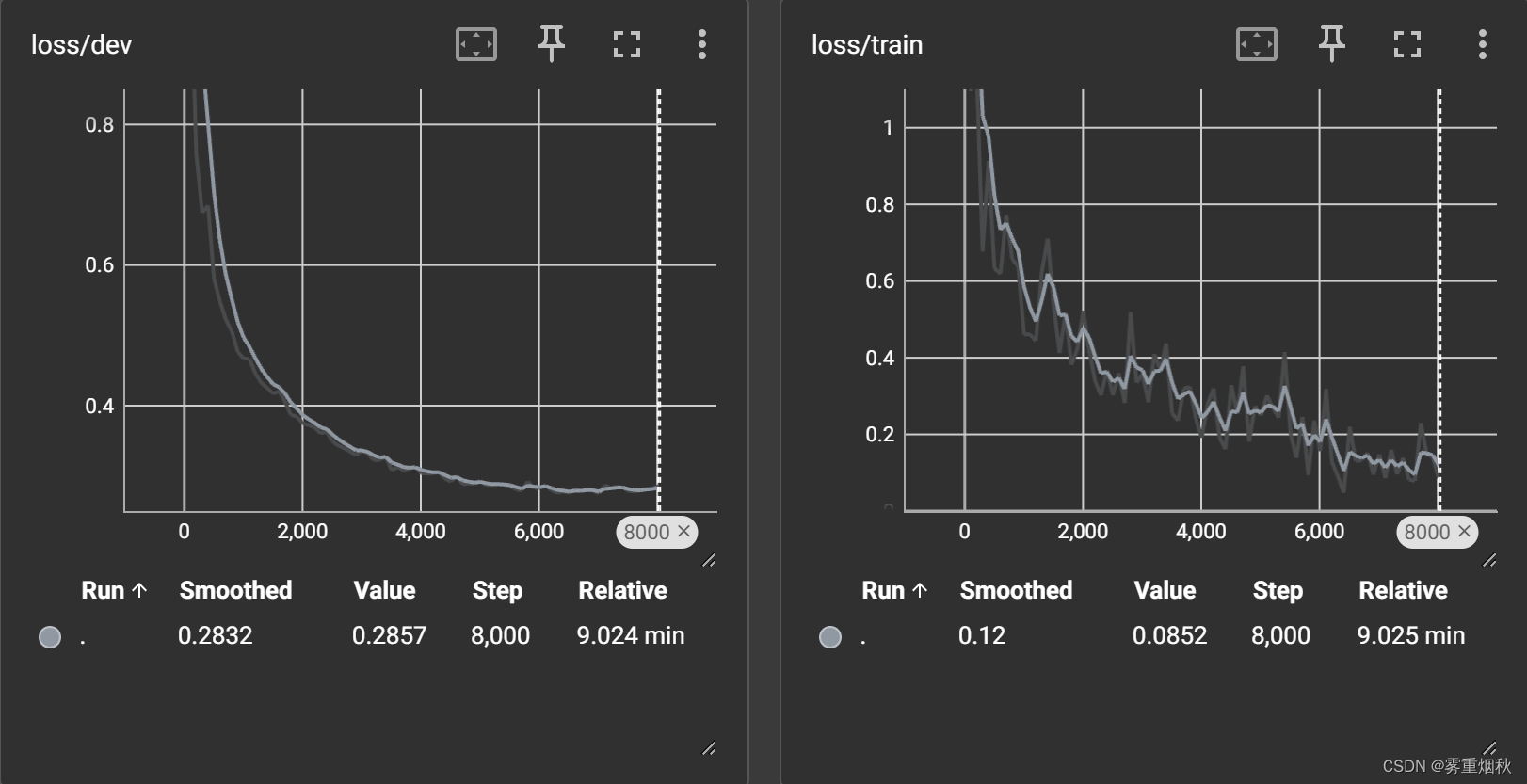
加了n-gram信息后准确率92.12%,不加n-gram信息,也就是词袋模型,准确率,n-gram词表大小15w,准确率91.49%,词表大小35w,准确率92.01%,相差不大,但是如果不加n-gram信息只有88.58%,如果把学习率设置为1e-2,那么准确率92.27%。
TextCNN
论文:https://arxiv.org/abs/1408.5882
代码:https://github.com/yoonkim/CNN_sentence
TextCNN是Yoon Kim在2014年提出的模型,开创了用CNN编码n-gram特征的先河。
模型结构
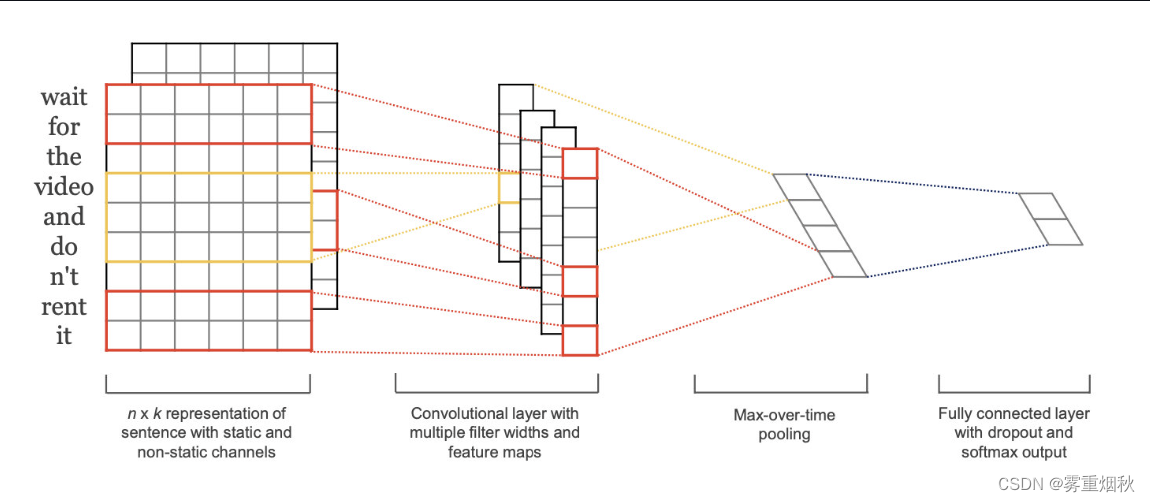
模型结构如图,图像中的卷积都是二维的,而TextCNN使用【一维卷积】,即filter_size * embedding_dim,有一个维度和embedding相等,这样filter_size就能抽取n-gram的信息。以一个样本为例,整体的前向逻辑是:
- 对词进行embedding,得到
[seq_length, embedding_dim] - 用N个卷积核,得到N个
seq_length-filter_size+1长度的一维feature map - 对feature map进行max-pooling(因为是时间维度的,也称max-over-time-pooling),得到N个
1x1的数值,拼接成一个N维向量,作为文本的句子表示 - 将N维向量压缩到类目的个数,过Softmax
在TextCNN的实践中,有很多地方可以优化(参考这篇论文):
- Filter尺寸:这个参数决定了抽取n-gram特征的长度,主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
- Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可
- CNN的激活函数:可以尝试Identity、ReLU、tanh
- 正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了
- Embedding表:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练
- 蒸馏BERT的logits,利用领域内无监督数据
- 加深全连接:原论文只使用了一层全连接,而加到3、4层左右效果会更好
TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用特征。另外再仔细想的话,TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,解决了词袋模型的稀疏性问题。
TextCNN的详细过程原理图如下:
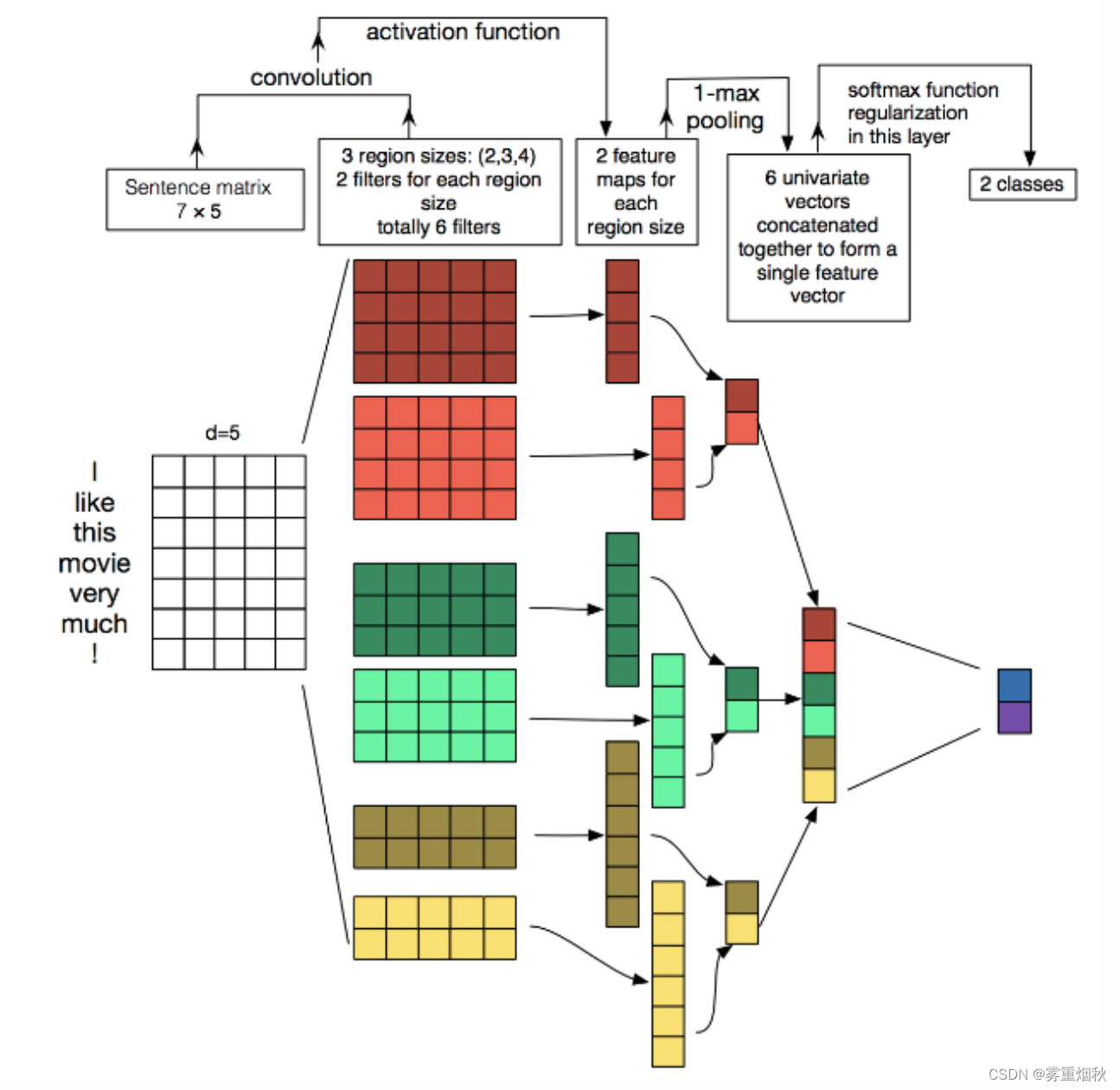
模型代码
模型代码在TextCNN.py中。下面给出经过注释后的代码。
python
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
'''Convolutional Neural Networks for Sentence Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
# 文本通常被视为单通道数据,config,num_filters是输出通道数,即卷积核的数量
# 卷积核尺寸是从config.filter_sizes------一个包含不同核大小的列表中取值,维度和嵌入向量维度相同
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
# 全连接层,输入特征的数量是输出的通道数乘以不同的核的数量,输出特征是类别数,因为在全连接之前是经过了池化的
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
# 卷积+Relu激活函数,并使用squeeze函数去除单维度大小为1的维度------这里指定第3个维度,如果大小不是1会报错
# x.shape首先是[128,1,32,300]
# 经过了卷积层变成了[128,256,31,1]
x = F.relu(conv(x)).squeeze(3) # [128,256,31],相当于用N个卷积核得到N个seq_length-filter_size+1长度的feature map
# 最大池化,池化窗口大小与整个序列长度相同,然后再次使用squeeze去除单维度
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x[0]) # [batch, seq_length, config.embed]
# 增加一个维度到第一维,以匹配卷积层的输入要求
out = out.unsqueeze(1) # [batch, x, seq_length, config_embed]
# 遍历所有卷积层,对每个卷积层调用conv_and_pool函数,并将结果使用torch.cat拼接
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out) # [128,768],3个256的特征拼在一起了
out = self.fc(out)
return out最终结果
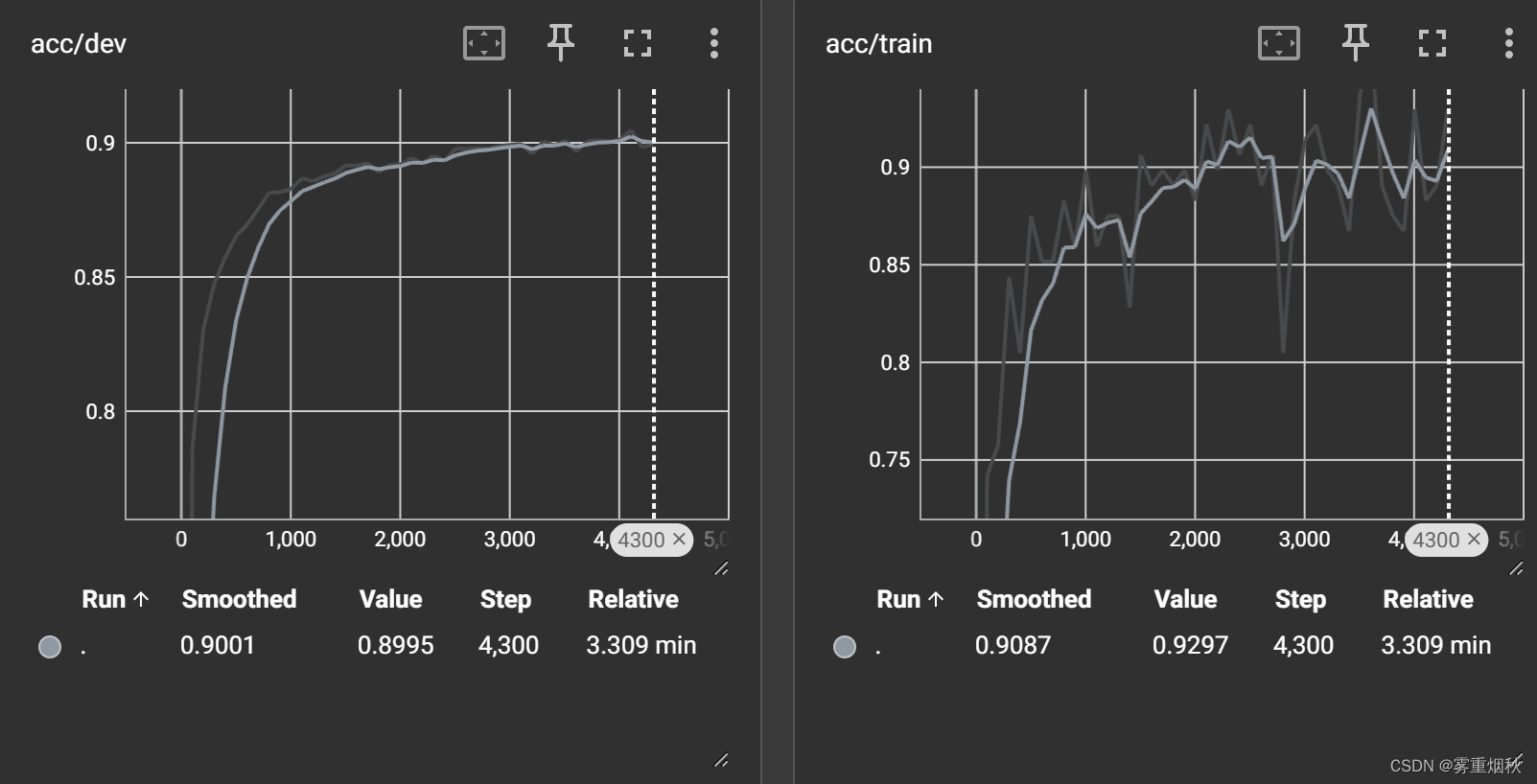
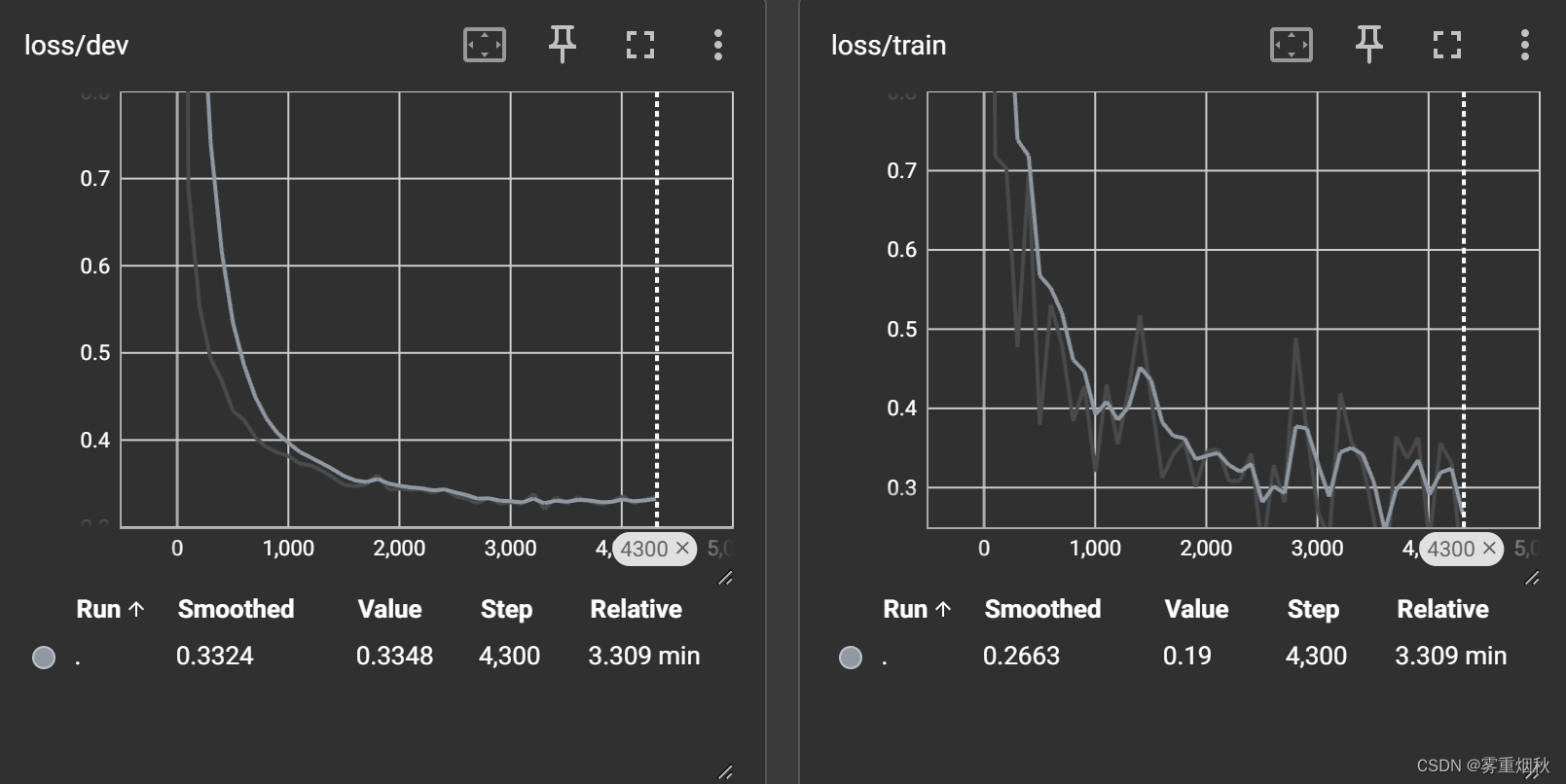
- 按上面代码进行训练的准确率为90.37%
- 如果加一层全连接,准确率变成了91.43%,如果再加一层全连接,准确率并没有提升
- 修改filter尺寸(2,3,4)变成(2,3,4,5),准确率为90.88%
- 更改CNN的激活函数,如果用恒等变换,那么准确率变成90.27%,如果用tanh,准确率90.78%
- 如果把filter个数由256变成128,准确率为90.85%
DPCNN
论文:https://ai.tencent.com/ailab/media/publications/ACL3-Brady.pdf
代码:https://github.com/649453932/Chinese-Text-Classification-Pytorch
上面介绍的TextCNN有太浅和长程依赖问题,那么如果多加几层CNN是否可以呢,事情没有想象中的那么简单,直到2017年,tencent提出了把TextCNN做到更深的DPCNN模型。
模型结构
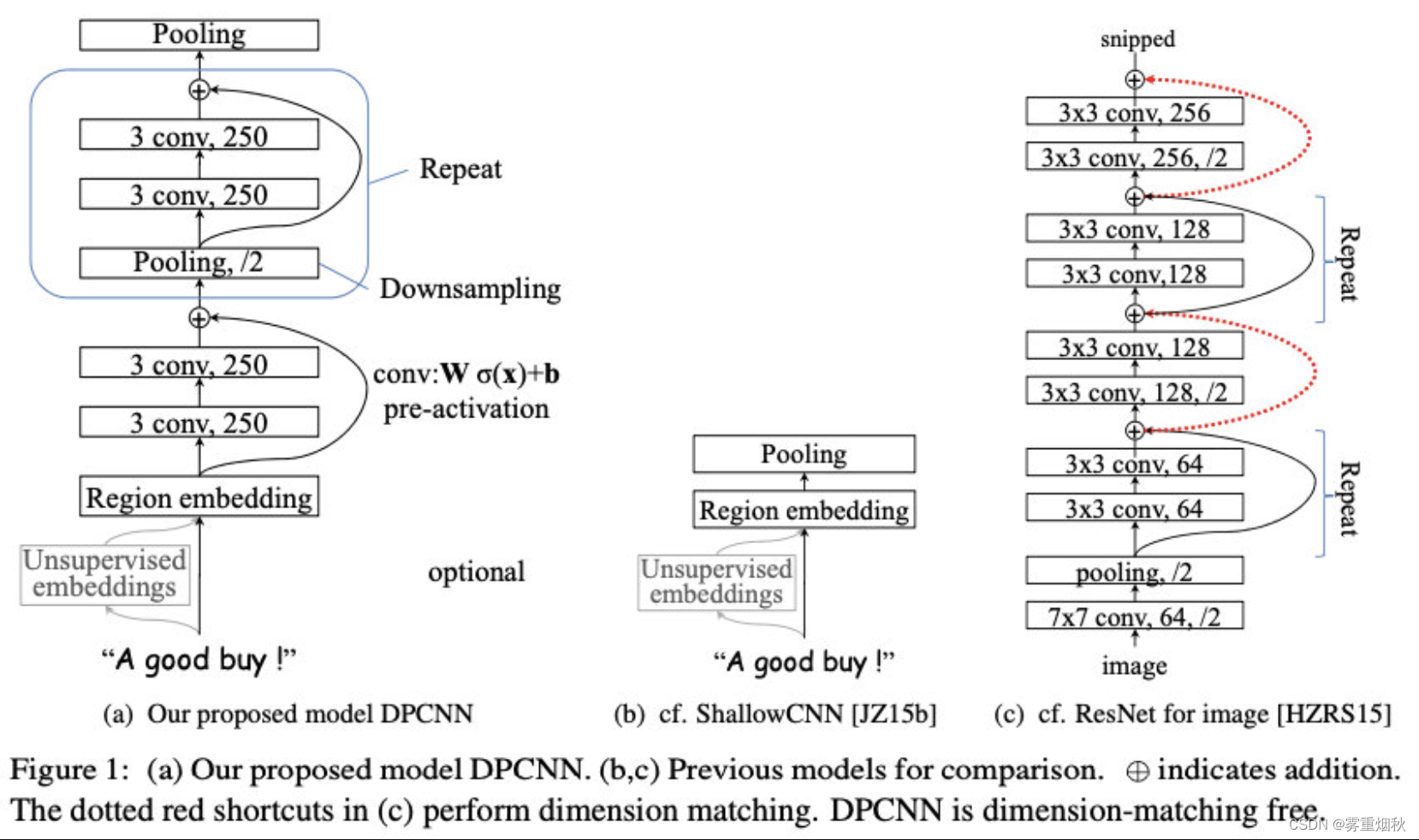
上图中的ShallowCNN指TestCNN。DPCNN的核心改进如下:
- 在Region embedding时不采用CNN那样加权卷积的做法,而是对n个词进行pooling后再加个1x1的卷积,因为实验下来效果差不多,且作者认为前者的表示能力更强,容易过拟合
- 使用1/2池化层,用size=3,stride=2的卷积核,直接让特征图的高度减半
- 残差连接,参考ResNet,减缓梯度弥散问题
这部分反映在代码里就是在embedding后进行两次卷积,得到的特征图的高度为seq_length-3+1,宽度为1,然后用1/2pooling将高度减半后再卷积,重复这个过程直到特征图为1x1,也就是之前是先卷积后池化,这个是先池化再卷积。
模型代码
代码在DPCNN.py里,添加注释后的代码如下:
python
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'DPCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.num_filters = 250 # 卷积核数量(channels数)
'''Deep Pyramid Convolutional Neural Networks for Text Categorization'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
# 卷积核大小(3, config.embed),个数config.num_filters
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embed), stride=1)
# 输入和输出通道数都是num_filters,卷积核大小(3,1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
# 池化核大小(3,1),步长2
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom添加一个零填充
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom添加一个零填充
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
x = x[0] # [128,32]
x = self.embedding(x) ## [128,32,300]
x = x.unsqueeze(1) # [batch_size, 1, seq_len, embed]->[128,1,32,300]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]->[128,250,30,1]
x = self.padding1(x) # [batch_size, 250, seq_len-3+1, 1]->[128,250,32,1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]->[128,250,30,1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]->[128,250,32,1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]->[128,250,30,1]
# 只要特征图的高度(序列的长度那一维)大于2,就应用一个自定义的卷积块_block
while x.size()[2] > 2: # [batch_size, 250, 1, 1]
x = self._block(x)
x = x.squeeze() # [batch_size, 250]
x = self.fc(x)
return x
# 残差块(residual block)
def _block(self, x):
# 在底部添加零填充,增加了特征图高度
x = self.padding2(x) # [128,250,31,1]
# 在经过零填充的特征图上应用最大池化,
px = self.max_pool(x) # px.shape->[128,250,15,1]
# 对经过最大池化操作后的特征图px进行零填充,增加了2高度
x = self.padding1(px) # [128,250,17,1]
x = F.relu(x)
# 对特征图经过卷积层
x = self.conv(x) # [128,250,15,1]
# 再进行零填充
x = self.padding1(x) # [128,250,17,1]
x = F.relu(x)
x = self.conv(x) # [128,250,15,1]
# Short Cut
x = x + px
return x最终结果

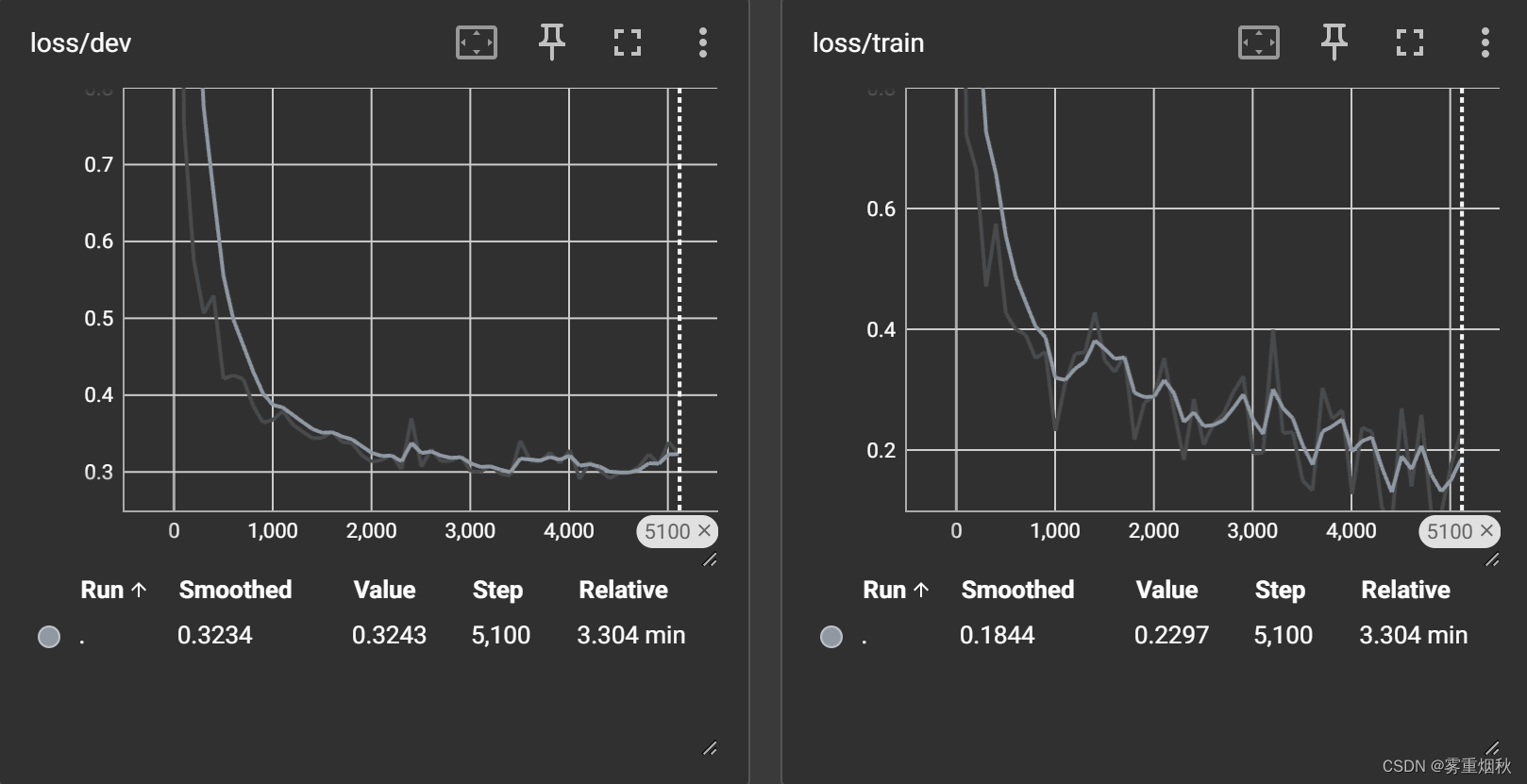
- 准确率91.41%
TextRCNN
论文:https://dl.acm.org/doi/10.5555/2886521.2886636
代码:https://github.com/649453932/Chinese-Text-Classification-Pytorch
除了DPCNN那样增加感受野的方式(因为用了空洞卷积和池化,步长为2,感受野变大了,结合了padding保证特征图的长度),RNN也可以缓解长距离依赖的问题。下面介绍一篇经典TextRCNN。
模型结构

模型的前向过程是:
- 得到单词 i i i的表示 e ( w i ) e(w_i) e(wi)
- 通过RNN得到左右双向的表示 c l ( w i ) c_l(w_i) cl(wi)和 c r ( w i ) c_r(w_i) cr(wi)
- 将表示拼接得到 x i = c l ( w i ) ; e ( w i ) ; c r ( w i ) x_i=c_l(w_i);e(w_i);c_r(w_i) xi=cl(wi);e(wi);cr(wi),再经过变换得到 y i = t a n h ( W x i + b ) y_i=tanh(Wx_i+b) yi=tanh(Wxi+b)
- 对多个 y i y_i yi进行max-pooling,得到句子表示 y y y,再做最终的分类
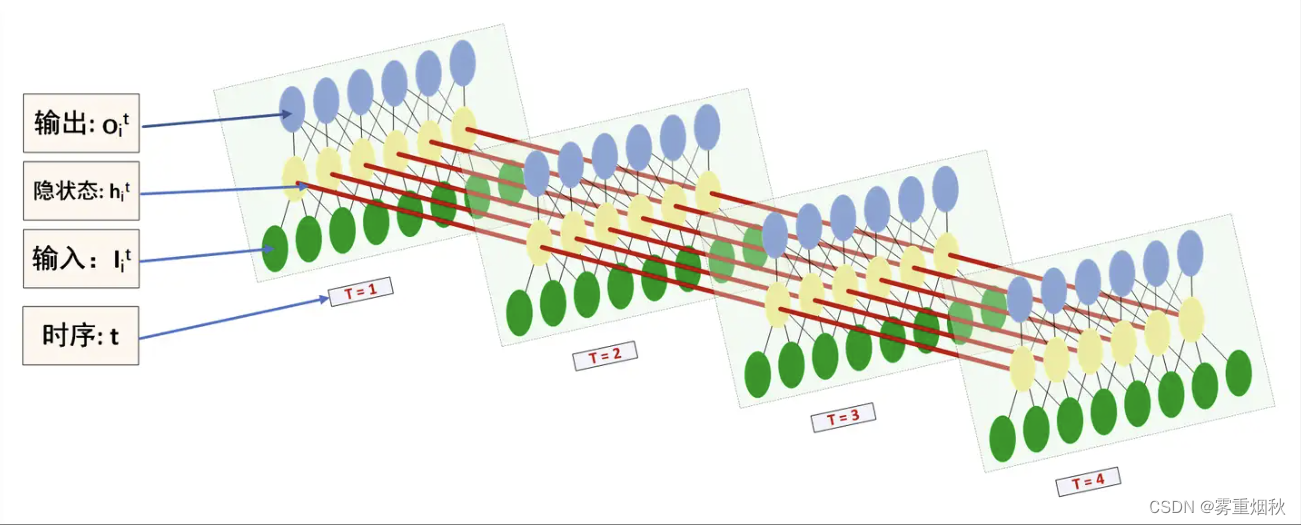
LSTM示意图,这样看起来更直观,图片来源https://www.zhihu.com/question/41949741/answer/318771336
模型代码
上图解释的已经很清楚了,所以直接放代码,代码在TextRCNN.py中,添加注释后的代码如下(这里并没有用tanh而是用的ReLU)。
python
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 1.0 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 256 # lstm隐藏层
self.num_layers = 1 # lstm层数
'''Recurrent Convolutional Neural Networks for Text Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
# 初始化一个双向LSTM层,embed------嵌入维度,hidden_size------隐藏层大小,num_layers------LSTM层数
# bidirectional=True表示双向的,batch_first=True表示输入和输出的张量第一个维度是批次大小
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
# 池化窗口大小pad_size
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
x, _ = x
embed = self.embedding(x) # x->[128,32],embed->[128,32,300]
out, _ = self.lstm(embed) # out->[128,32,256*2]
out = torch.cat((embed, out), 2) # out->[128,32,300+512]
out = F.relu(out)
out = out.permute(0, 2, 1) # out->[128,812,32],一维池化核默认对最后一个维度进行池化
out = self.maxpool(out).squeeze() # out->[128,812]
out = self.fc(out)
return out最终结果
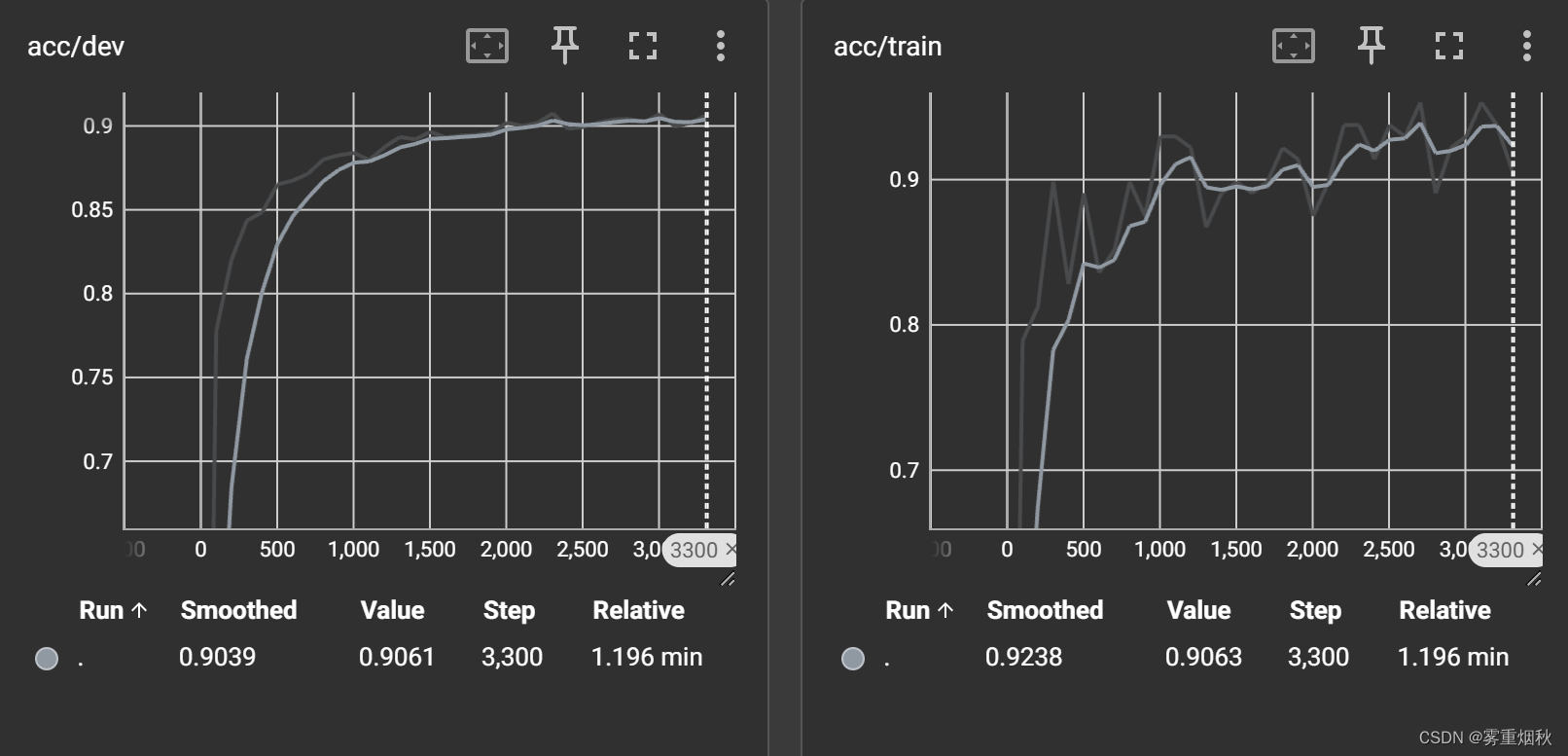
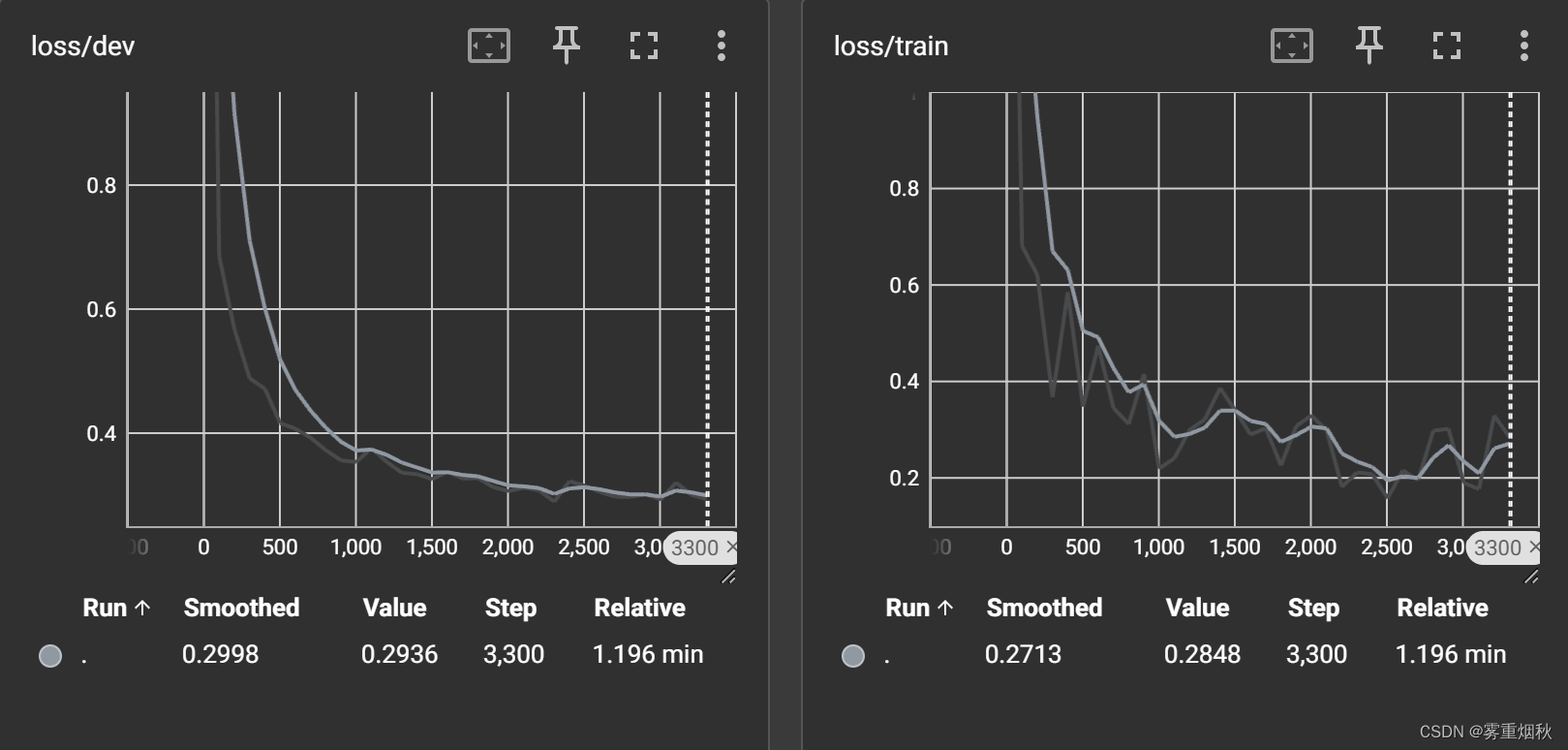
准确率90.97%
TextRNN_attn(TextBiLSTM+Attention)
论文:https://www.aclweb.org/anthology/P16-2034.pdf
代码:https://github.com/649453932/Chinese-Text-Classification-Pytorch
从前面介绍的几种方法,可以自然地得到文本分类的框架,就是先基于上下文对token编码,然后pooling出句子表示再分类。在最终池化时,max-pooling通常表现更好,因为文本分类经常是主题上的分类,从句子中一两个主要的词就可以得到结论,其他大多是噪声,对分类没有意义。而到更细粒度的分析时,max-pooling可能又把有用的特征去掉了,这时便可以用attention进行句子表示的融合。
模型结构
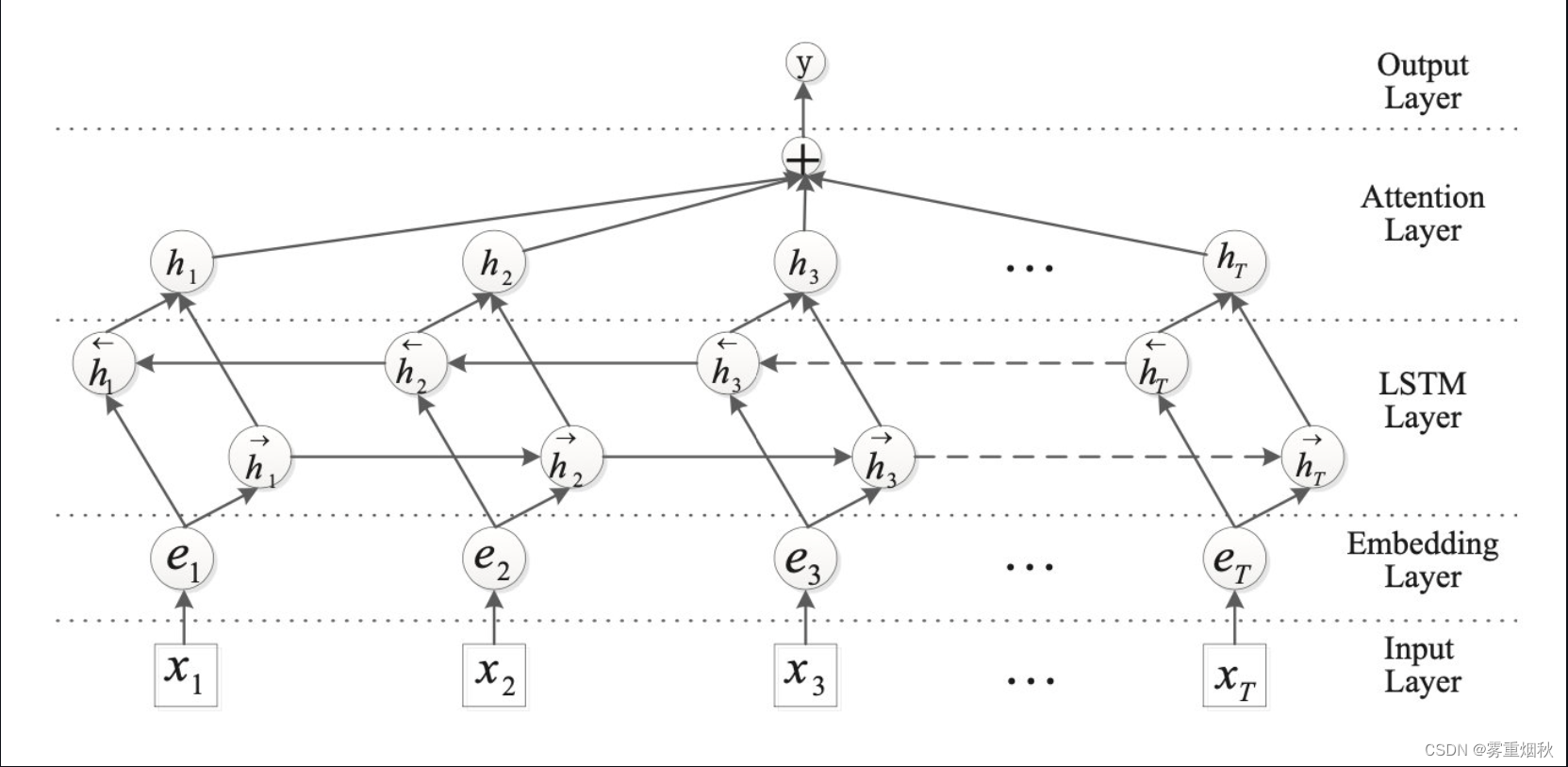
这个图很直观,在Attention Layer,计算attention score时会先进行变换
M = t a n h ( H ) M=tanh(H) M=tanh(H)
α = s o f t m a x ( w T M ) \alpha=softmax(w^TM) α=softmax(wTM)
r = H a T r=Ha^T r=HaT
其中 w w w是context vector,随机初始化并随着训练更新。最后得到句子表示 r r r,再进行分类。
这个加attention的套路用到CNN编码器之后代替pooling也是可以的。
模型代码
代码在TextRNN_Att.py,添加注释后的代码如下:
python
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRNN_Att'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 128 # lstm隐藏层
self.num_layers = 2 # lstm层数
self.hidden_size2 = 64
'''Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
# 双向LSTM
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
# self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2))
# 定义了一个可学习参数,大小是hidden_size*2,初始化全0
self.w = nn.Parameter(torch.zeros(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
# 两个全连接层
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
x, _ = x
emb = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 128*2]
M = self.tanh1(H) # [128, 32, 256]
# M = torch.tanh(torch.matmul(H, self.u))
# M和w进行矩阵乘法,相当于加权池化,[128,32,256]和[256,]经过matmul的结果是[128,32],因此在最后加一个维度以匹配H的维度
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
# 将加权系数alpha应用于LSTM的输出H,相当于对每个时间步的隐藏状态根据器对应的注意力权重进行放大或缩小
out = H * alpha # [128, 32, 256]
# 对加权后的隐藏状态进行求和,可以看作是池化,保留了注意力机制强调的部分
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out最终结果
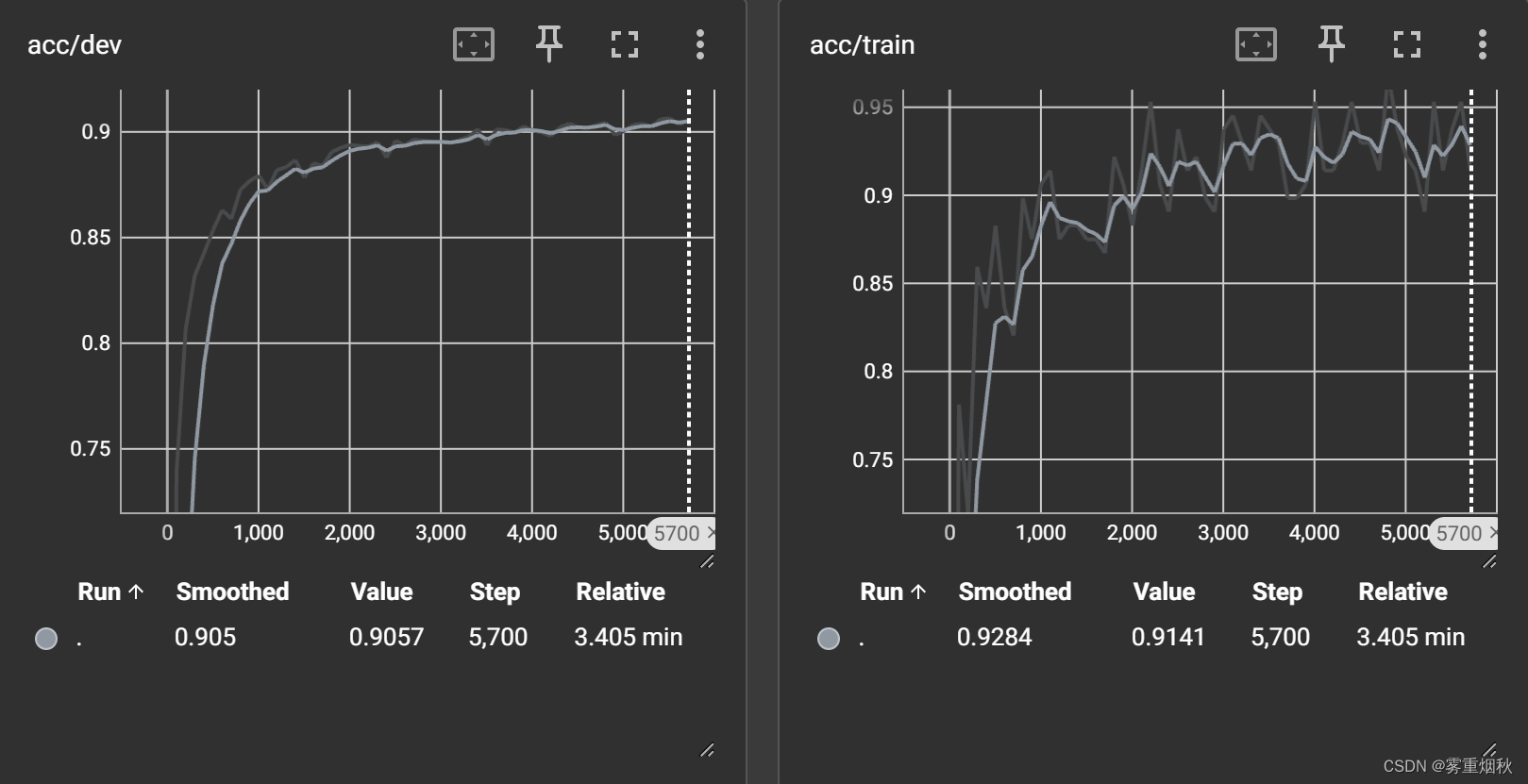
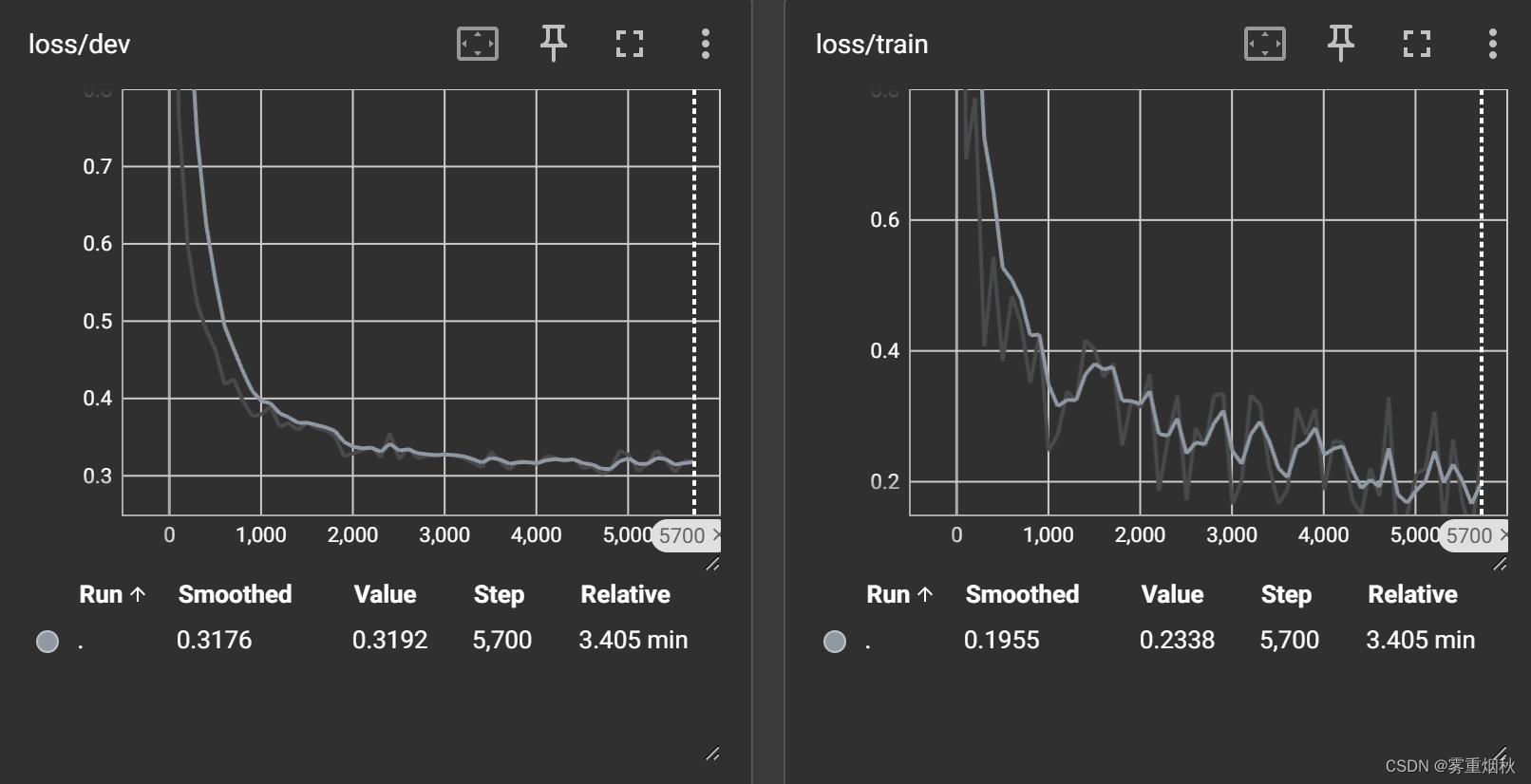
准确率90.95%
TextRNN(不加attention)
- 准确率90.84%,相差不大
Transformer
模型结构
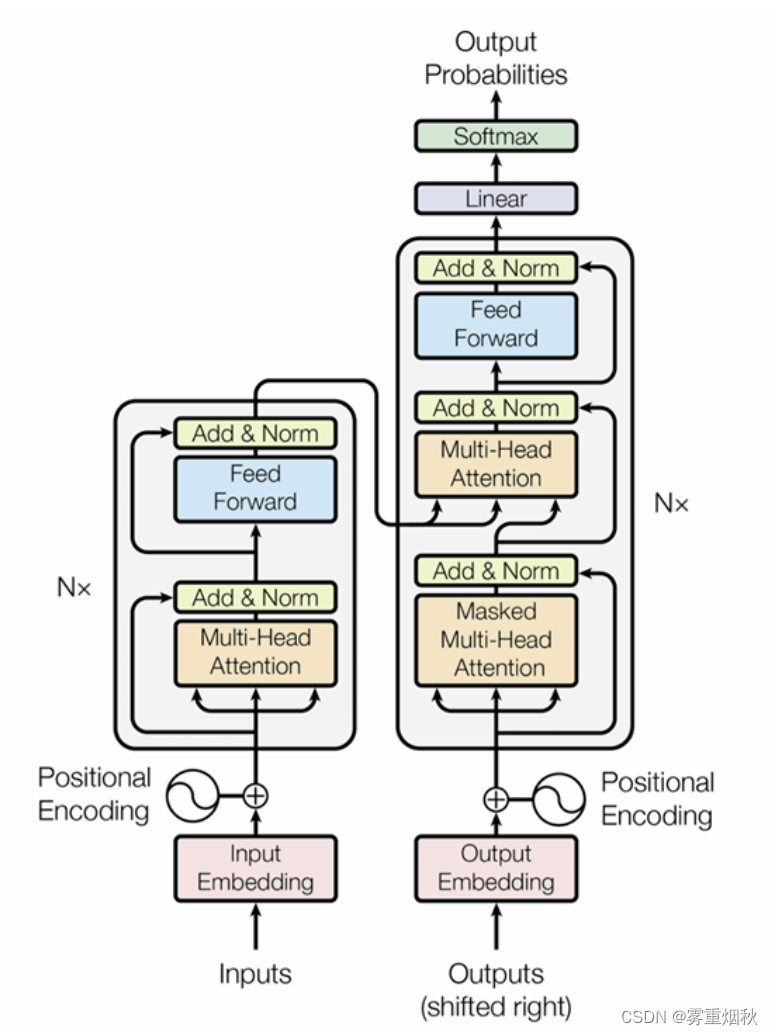
代码中并没有按上图结构来做,而是使用两个encoder,包含Positional Encoding位置编码,Multi-Head Attentiond多头注意力模块,并没有明确的decoder部分
模型代码
模型的代码在Transformer.py,添加注释后的具体代码如下:
python
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'Transformer'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 2000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-4 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.dim_model = 300
self.hidden = 1024
self.last_hidden = 512
self.num_head = 5
self.num_encoder = 2
'''Attention Is All You Need'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
# 位置编码层,提供关于序列中单词位置的信息
self.postion_embedding = Positional_Encoding(config.embed, config.pad_size, config.dropout, config.device)
# 编码器层
self.encoder = Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
# 编码器层的列表,列表中的每个元素都是self.encoder的深拷贝
self.encoders = nn.ModuleList([
copy.deepcopy(self.encoder)
# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
for _ in range(config.num_encoder)])
self.fc1 = nn.Linear(config.pad_size * config.dim_model, config.num_classes)
# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)
# self.fc1 = nn.Linear(config.dim_model, config.num_classes)
def forward(self, x):
out = self.embedding(x[0])
out = self.postion_embedding(out)
for encoder in self.encoders:
out = encoder(out)
# 将编码器的输出扁平化为二位张量,第一维是批次大小,第二维是特征维度的总和
out = out.view(out.size(0), -1)
# out = torch.mean(out, 1)
out = self.fc1(out)
return out
class Encoder(nn.Module): # 编码器层
def __init__(self, dim_model, num_head, hidden, dropout):
super(Encoder, self).__init__()
# 初始化一个多头自注意力模块,dim_model_模型的维度,num_head_头的数量
self.attention = Multi_Head_Attention(dim_model, num_head, dropout)
# 前馈神经网络模块
self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)
def forward(self, x):
out = self.attention(x)
out = self.feed_forward(out)
return out
class Positional_Encoding(nn.Module): # 位置编码
def __init__(self, embed, pad_size, dropout, device):
super(Positional_Encoding, self).__init__()
self.device = device
# 创建一个位置编码矩阵self.pe,使用正弦和余弦函数生成不同频率的波形,为每个位置和每个维度生成位置编码
self.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])
self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])
self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])
self.dropout = nn.Dropout(dropout)
def forward(self, x): # 将输入和位置编码相加,以在词嵌入中添加位置信息
out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)
out = self.dropout(out)
return out
class Scaled_Dot_Product_Attention(nn.Module): # 缩放点积自注意力
'''Scaled Dot-Product Attention '''
def __init__(self):
super(Scaled_Dot_Product_Attention, self).__init__()
def forward(self, Q, K, V, scale=None):
'''
Args:
Q: [batch_size, len_Q, dim_Q]
K: [batch_size, len_K, dim_K]
V: [batch_size, len_V, dim_V]
scale: 缩放因子 论文为根号dim_K
Return:
self-attention后的张量,以及attention张量
'''
attention = torch.matmul(Q, K.permute(0, 2, 1))
if scale:
attention = attention * scale
# if mask: # TODO change this
# attention = attention.masked_fill_(mask == 0, -1e9)
attention = F.softmax(attention, dim=-1)
context = torch.matmul(attention, V)
return context
class Multi_Head_Attention(nn.Module): # 多头自注意力模块
def __init__(self, dim_model, num_head, dropout=0.0):
super(Multi_Head_Attention, self).__init__()
self.num_head = num_head
assert dim_model % num_head == 0
# 计算每个头的维度
self.dim_head = dim_model // self.num_head
# 定义线性变换层fc_Q,fc_K,fc_V,用于将输入特征映射到查询Q、键K和值V
self.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)
# 缩放点积注意力的实例化
self.attention = Scaled_Dot_Product_Attention()
# 线性层fc,将注意力的输出合并回dim_model维度
self.fc = nn.Linear(num_head * self.dim_head, dim_model)
self.dropout = nn.Dropout(dropout)
# 规范化输入特征
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
batch_size = x.size(0)
Q = self.fc_Q(x) # Q->(128,32,300)
K = self.fc_K(x) # K->(128,32,300)
V = self.fc_V(x) # V->(128,32,300)
Q = Q.view(batch_size * self.num_head, -1, self.dim_head) # Q->(640,32,60)
K = K.view(batch_size * self.num_head, -1, self.dim_head) # K->(640,32,60)
V = V.view(batch_size * self.num_head, -1, self.dim_head) # V->(640,32,60)
# if mask: # TODO
# mask = mask.repeat(self.num_head, 1, 1) # TODO change this
scale = K.size(-1) ** -0.5 # 缩放因子,通常为1/sqrt(dim_head)
context = self.attention(Q, K, V, scale) # context->(640,32,60)
context = context.view(batch_size, -1, self.dim_head * self.num_head) # context->(128,32,300)
out = self.fc(context)
out = self.dropout(out)
out = out + x # 残差连接(输入x和输出out相加)
out = self.layer_norm(out)
return out
class Position_wise_Feed_Forward(nn.Module): # 前馈模块,也使用了残差连接、层归一化和dropout
def __init__(self, dim_model, hidden, dropout=0.0):
super(Position_wise_Feed_Forward, self).__init__()
self.fc1 = nn.Linear(dim_model, hidden)
self.fc2 = nn.Linear(hidden, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out最终结果
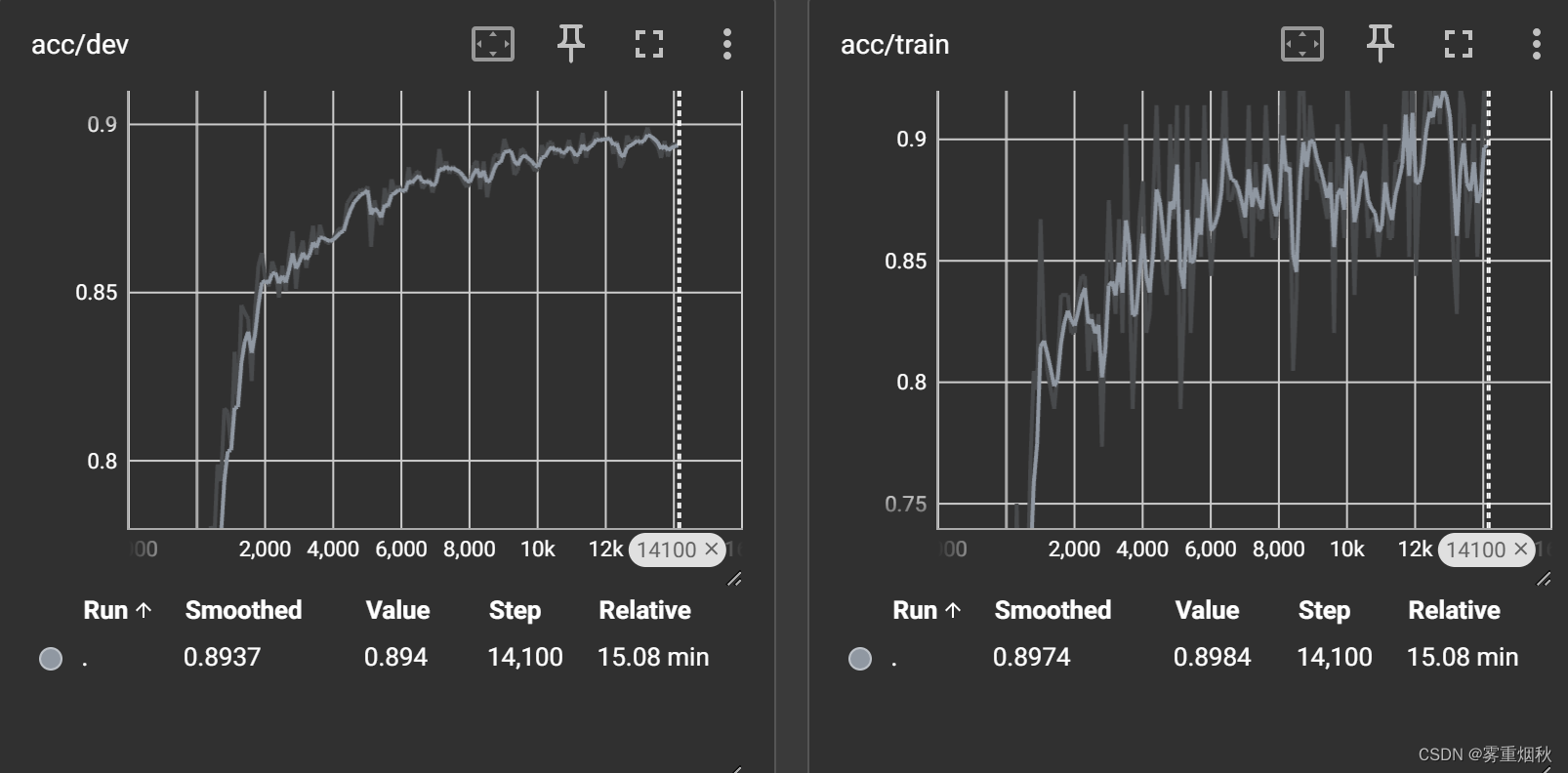
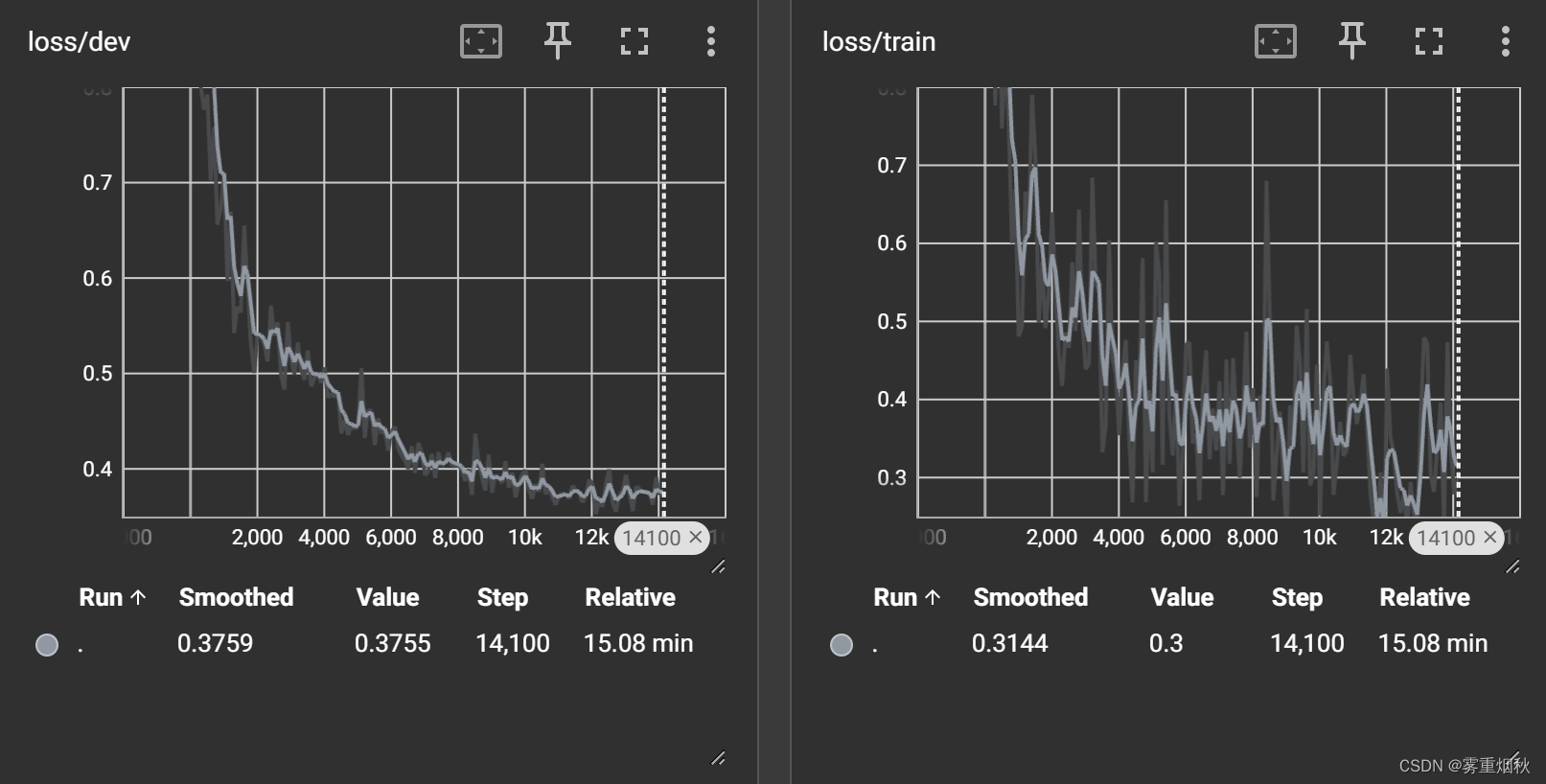
准确率89.89%
Bert
模型结构
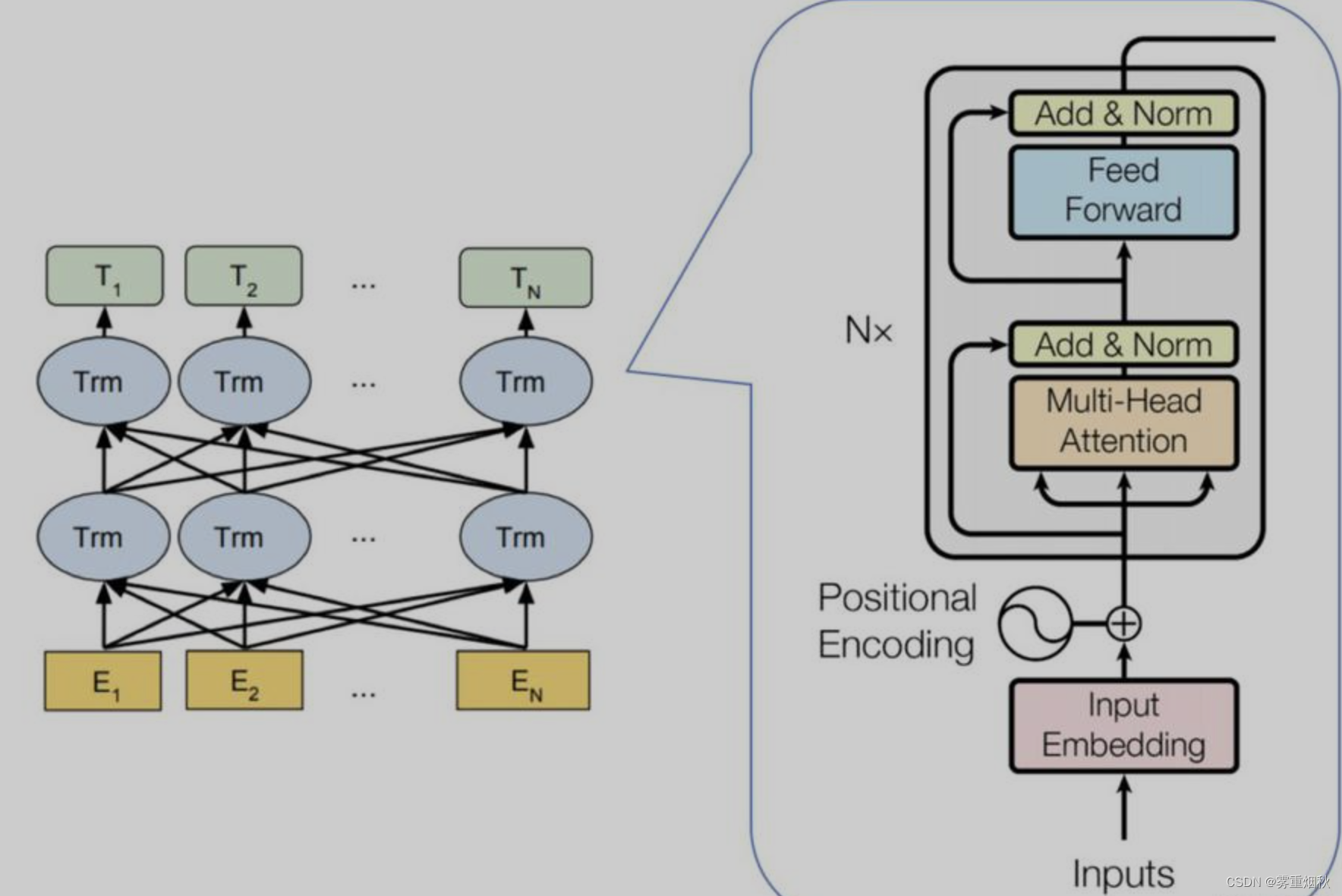
这里的Bert的数据处理部分发生了变化,增加了mask,由于下游任务是分类,因此掩码没有遮蔽令牌的作用,是用来指示忽略填充的部分,如[1,1,1,0,0],这里的0表示padding部分,让attention忽略。
模型代码及结果
run.py
python
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
from utils import build_dataset, build_iterator, get_time_dif
parser = argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model', type=str, required=True, help='choose a model: Bert, ERNIE')
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews' # 数据集
model_name = args.model # bert
x = import_module('models.' + model_name)
config = x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
model = x.Model(config).to(config.device)
train(config, model, train_iter, dev_iter, test_iter)utils.py
python
# coding: UTF-8
import torch
from tqdm import tqdm
import time
from datetime import timedelta
PAD, CLS = '[PAD]', '[CLS]' # padding符号, bert中综合信息符号
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
# 如果不是填充部分那么就是[1],否则为[0]
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, test
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iter
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))Bert的程序在bert.py
python
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
# 初始化BERT模型,使用from_pretrained方法从预训练模型权重加载BERT
self.bert = BertModel.from_pretrained(config.bert_path)
# requires_grad=True设置模型所有参数为可更新
for param in self.bert.parameters():
param.requires_grad = True
# fc,输入是BERT隐藏层的维度
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # (x, seq_len, mask),取出x
mask = x[2] # 取出mask,这里的掩码是指示忽略填充,下游任务是分类,因此不需要起到遮蔽令牌的作用
# 调用BERT,attention_mask忽略mask部分,output_all_encoded_layers=False表示只输出最后一层的输出,而不是所有层输出
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out准确率94.35%
BERT分类的优化可以尝试:
- 不同的预训练模型,比如RoBERT、WWM、ALBERT
- 除了CLS外还可以用avg、max池化做句表示,甚至可以把不同层组合起来
- 在领域数据上增量预训练
- 集成蒸馏,训练多个大模型集成起来后蒸馏到一个上
- 先用多任务训练,再迁移到自己的任务
这里粘贴https://github.com/leerumor/nlp_tutorial?tab=readme-ov-file上的内容


ERNIE
模型结构
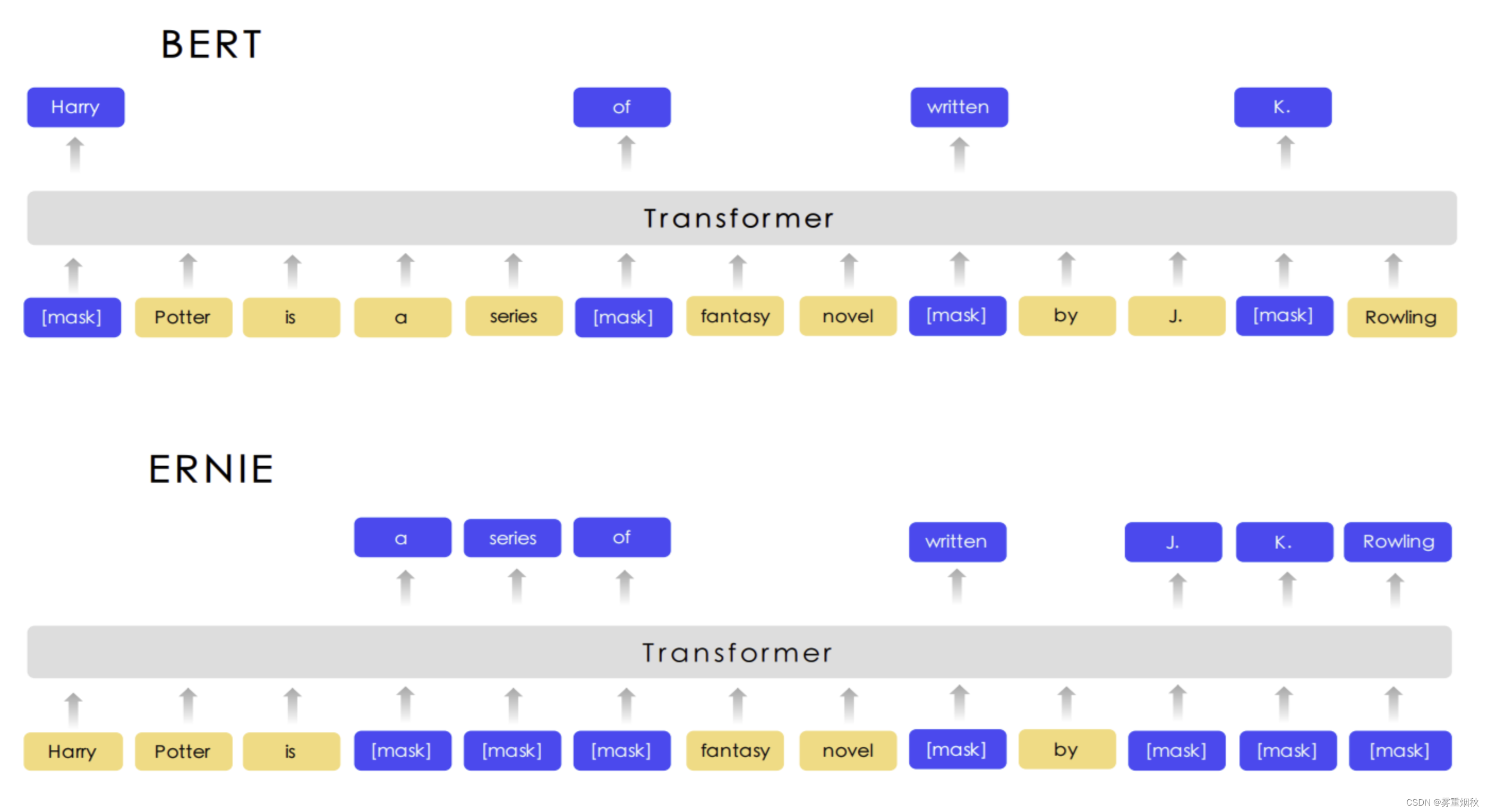
这里的ERNIE由于下游任务是分类,因此整体的流程和Bert是类似的,只不过就是加载的预训练模型变成了ERNIE。
模型代码及结果
ERNIE.py
python
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'ERNIE'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './ERNIE_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
print(self.tokenizer)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out准确率94.73%
效果总表
| 模型 | acc | 备注 |
|---|---|---|
| FastText | 92.12% | cbow+bigram+trigram |
| TextCNN | 90.37% | Kim 2014经典的CNN文本分类 |
| DPCNN | 91.41% | 金字塔CNN |
| TextRCNN | 90.97% | BiLSTM+池化 |
| TextRNN | 90.84% | BiLSTM |
| TextRNN_attn | 90.95% | BiLSTM+Attention |
| Transformer | 89.89% | 效果并不是很好 |
| Bert | 94.35% | bert+fc |
| ERNIE | 94.73% | 比bert稍好 |