生态模型基础:生态模型的基本和物种分布模型(SDMs)的重要性。
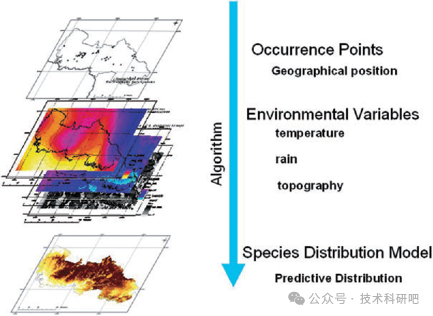
biomod2:探讨biomod2的历史、发展和主要功能。
R语言重点工具入门:数据输入与输出、科学计算、地理数据分析、数据可视化等功能。
第二:数据获取与预处理
常见地球科学数据(数据特点与获取途径):
(1)物种分布数据;
(2)环境变量(站点数据、遥感数据)。
基于R语言的数据预处理:
(1)数据提取:根据需求批量提取相关数据;
(2)数据清洗:数据清洗的原则与方法;
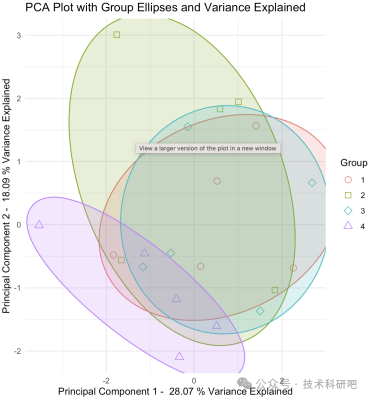
(3)特征变量选择:通过相关性分析、主成分分析(PCA)等方法选择具有代表性的特征变量,提高模型效率。
第三: 模型的建立与评估
机器学习与R语言实践
(1)机器学习原理;(2)常见机器学习算法与流程
基于单一机器学习算法的物种分布特征模拟(以最大熵算法为例)。

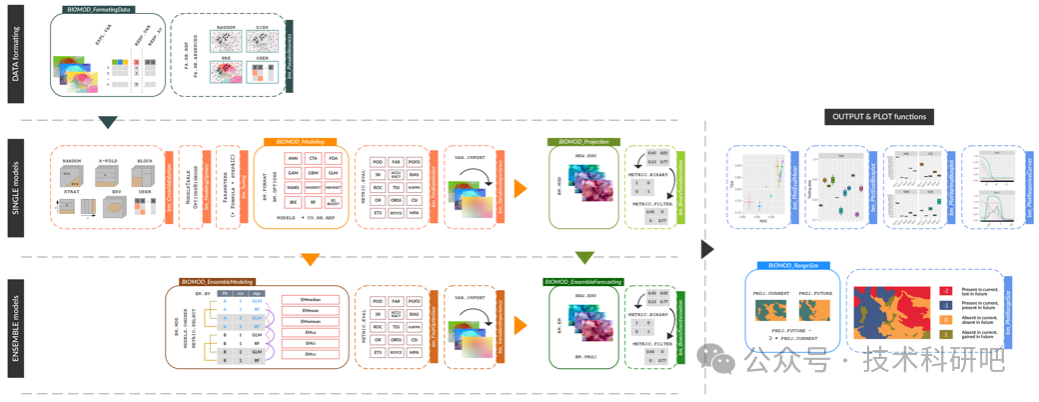
biomod2程序包与使用:原理、构成
实际操作:构建第一个物种分布模型,包括选择模型类型和调整参数。
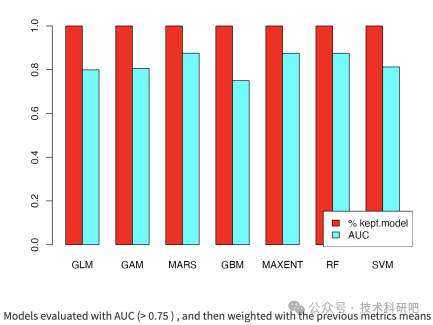
模型评估方法:通过ROC曲线、AUC值等方法评估模型的有效性和准确性。
第四: 模型优化与多模型集成
典型算法参数优化:对随机森林、最大熵等算法进行参数优化,提高模型性能。
集成方法:结合多个模型提高预测结果的稳定性和准确性。
物种分布特征预测: 基于单一模型与集成模型预测物种未来分布特征。
实战:参与者使用自己的数据或示例数据集,尝试实现多模型集成。
第五: 结果分析和案例研究
结果分析:物种分布特征、环境变量与物种分布关系、未来分布特征预测。
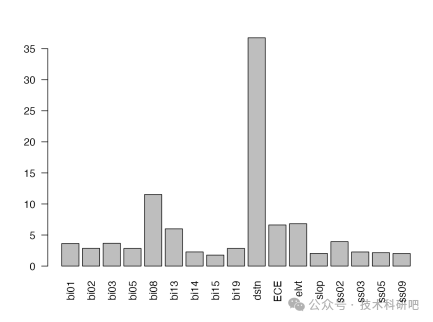
科学制图:栅格图、柱状图、降维结果图等。
案例研究:分析物种分布案例,如何应用学到的技能和知识。