精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、开发环境
- 三、视频展示
- 四、项目展示
- 五、代码展示
- 六、项目文档展示
- 七、总结
-
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻)
一、项目介绍
选题背景
近年来,随着国家医疗体制改革的深入推进,医用耗材集中采购已成为控制医疗费用、规范市场秩序的重要手段。根据国家医保局发布的数据显示,2023年全国医用耗材集中带量采购累计节约费用超过500亿元,涉及产品种类达到15大类。然而,面对数量庞大的医用耗材数据,传统的人工统计和简单报表分析已经无法满足决策需求。医用耗材市场涉及上万种产品,价格差异悬殊,从几元的基础耗材到数万元的高值耗材,市场格局复杂多变。同时,随着国产化替代进程的加快,进口与国产产品的竞争态势、技术发展趋势、价格波动规律等都需要通过大数据技术进行深度挖掘和分析。当前大部分医疗机构和采购部门仍然依赖传统的Excel表格和简单的数据库查询来处理这些信息,导致数据价值无法充分发挥,决策效率低下,迫切需要构建专业的数据可视化分析系统来支撑科学决策。
选题意义
本课题的研究具有重要的实际应用价值和理论探索意义。从实用角度来看,基于Spark的大数据处理技术能够高效处理海量医用耗材数据,为医疗机构、政府采购部门以及生产企业提供科学的决策支持工具。通过构建可视化分析系统,能够直观展现市场价格趋势、品牌竞争格局、产品技术发展方向等关键信息,帮助采购人员制定更加合理的采购策略,降低采购成本,提升采购效率。对于监管部门而言,该系统能够实时监控市场动态,及时发现价格异常波动和垄断风险,为政策制定提供数据依据。从技术层面来说,本课题将Hadoop生态系统与现代Web技术相结合,探索了大数据技术在医疗健康领域的创新应用,为类似行业数据分析系统的开发提供了可复制的技术方案。同时,通过Django+Vue的前后端分离架构设计,结合Echarts丰富的图表展现形式,实现了复杂数据的直观化呈现,这种技术组合在医疗信息化建设中具有广阔的推广前景。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
三、视频展示
基于大数据spark的医用消耗选品采集数据可视化分析系统【Hadoop、spark、python】
四、项目展示
登录模块:
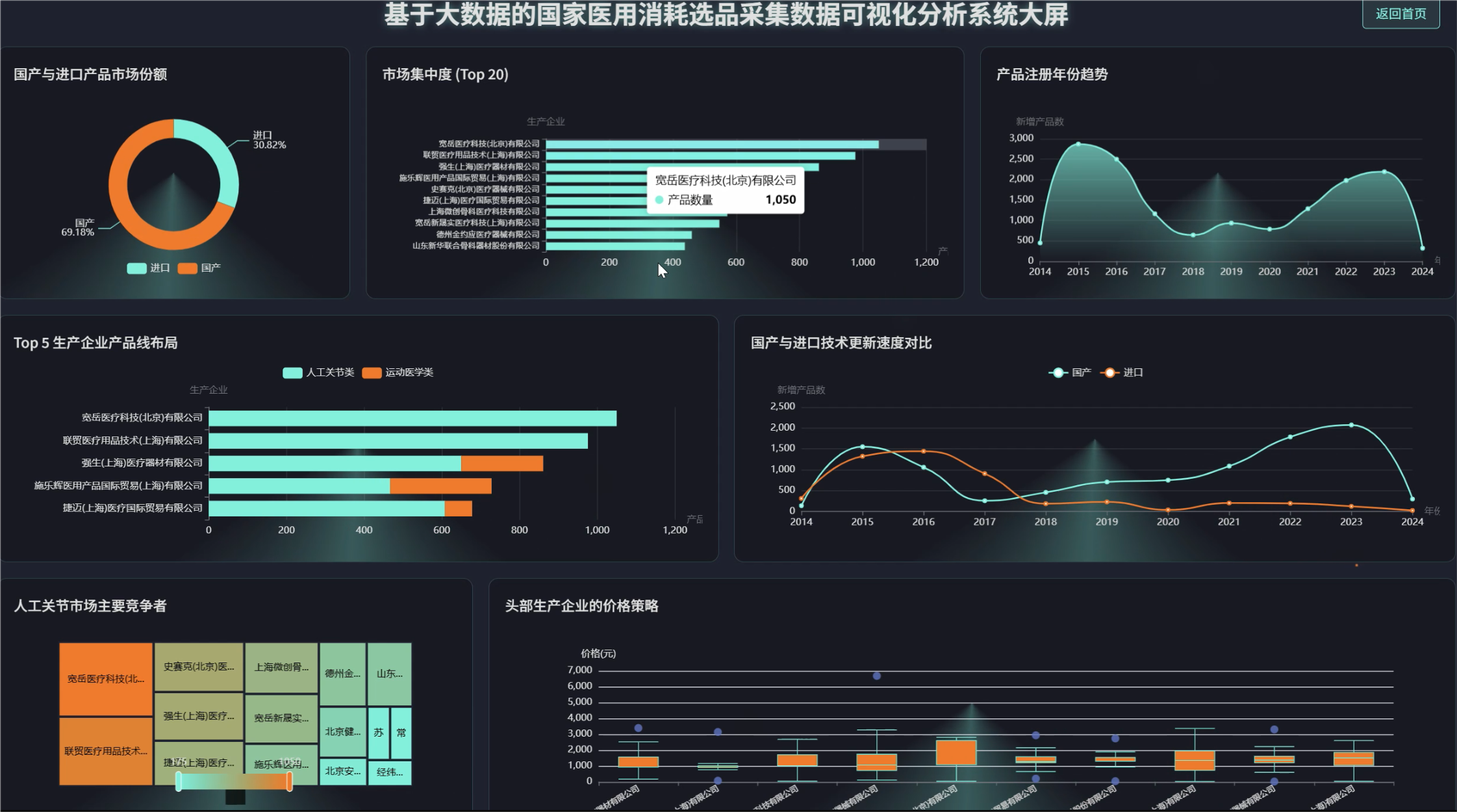
管理模块:
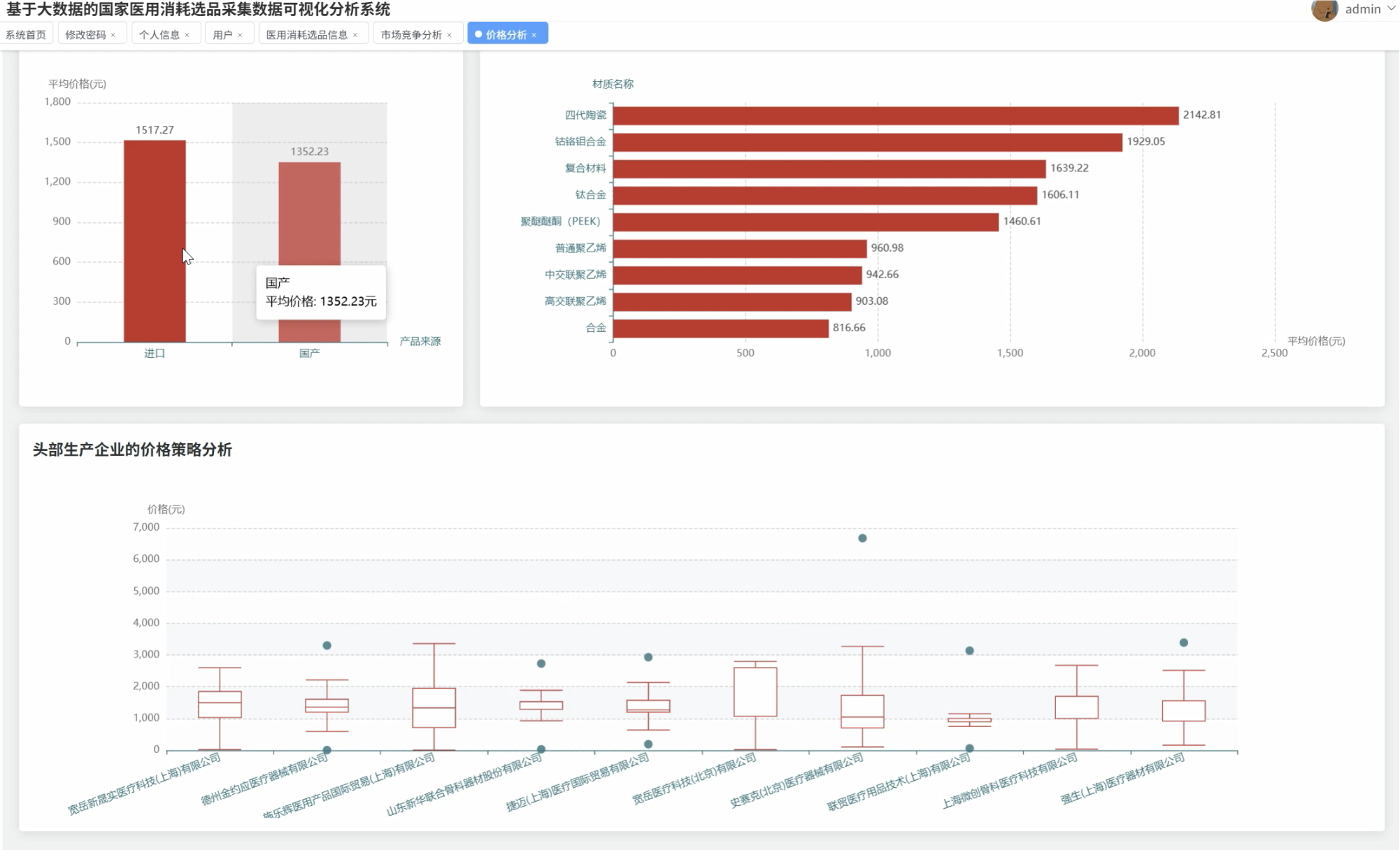
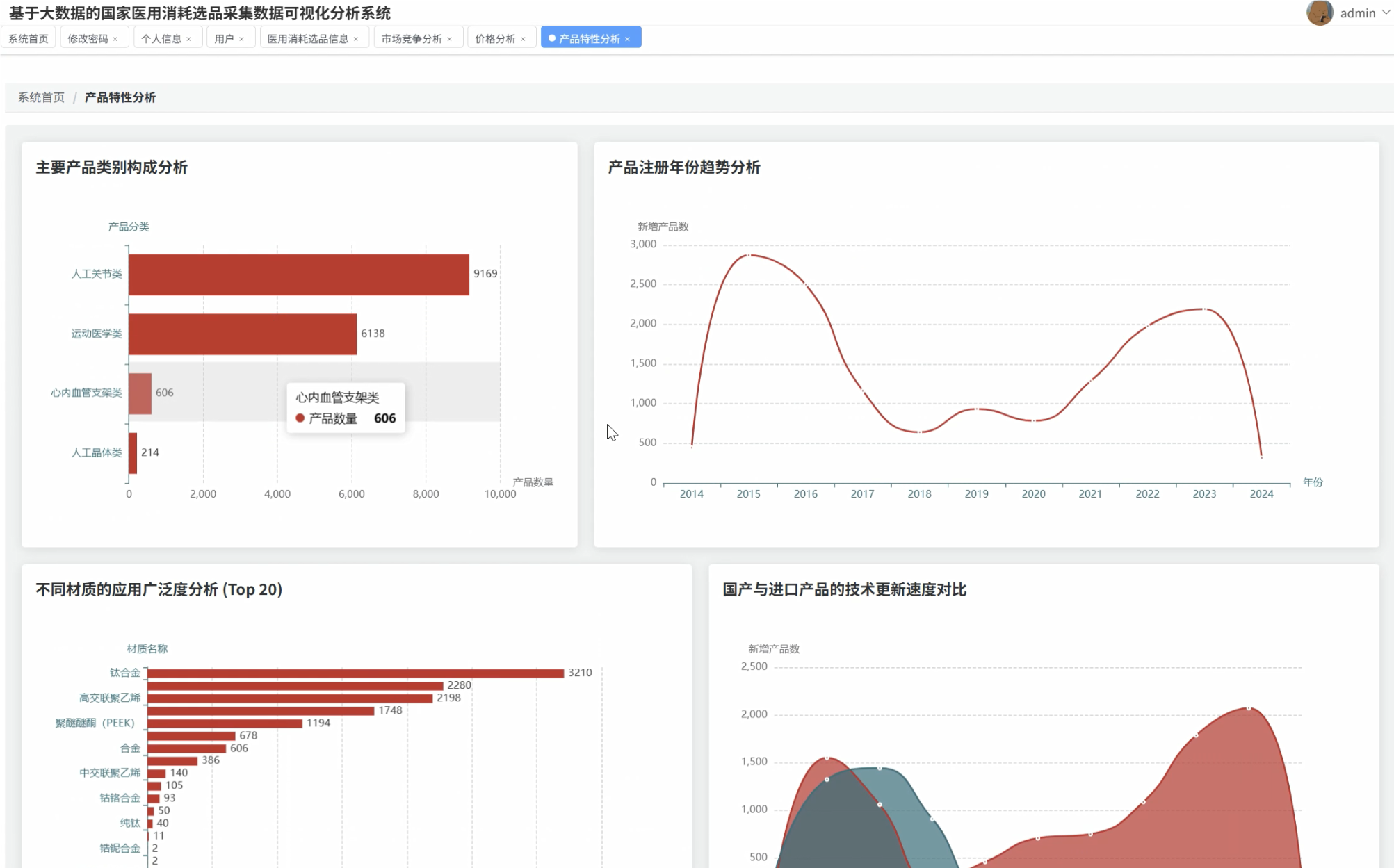
五、代码展示
bash
# 核心功能1: 价格分布分析处理
def analyze_price_distribution(request):
try:
# 从Spark处理后的数据中获取价格信息
spark_data = get_spark_processed_data('medical_consumables')
price_list = [float(item['price']) for item in spark_data if item['price'] and float(item['price']) > 0]
# 计算价格统计指标
total_count = len(price_list)
min_price = min(price_list)
max_price = max(price_list)
avg_price = sum(price_list) / total_count
price_list.sort()
median_price = price_list[total_count // 2] if total_count % 2 == 1 else (price_list[total_count // 2 - 1] + price_list[total_count // 2]) / 2
# 定义价格区间进行分组统计
price_ranges = [(0, 100), (100, 500), (500, 1000), (1000, 5000), (5000, 10000), (10000, float('inf'))]
range_labels = ['0-100元', '100-500元', '500-1000元', '1000-5000元', '5000-10000元', '10000元以上']
range_counts = [0] * len(price_ranges)
for price in price_list:
for i, (low, high) in enumerate(price_ranges):
if low <= price < high:
range_counts[i] += 1
break
# 计算各区间占比
range_percentages = [count / total_count * 100 for count in range_counts]
# 构造返回数据
chart_data = {
'labels': range_labels,
'data': range_counts,
'percentages': range_percentages
}
statistics = {
'total_count': total_count,
'min_price': round(min_price, 2),
'max_price': round(max_price, 2),
'avg_price': round(avg_price, 2),
'median_price': round(median_price, 2)
}
return JsonResponse({
'status': 'success',
'chart_data': chart_data,
'statistics': statistics
})
except Exception as e:
return JsonResponse({'status': 'error', 'message': str(e)})
# 核心功能2: 市场竞争格局分析
> 系统错误❌:stream error: stream ID 1; INTERNAL_ERROR; received from peer六、项目文档展示

七、总结
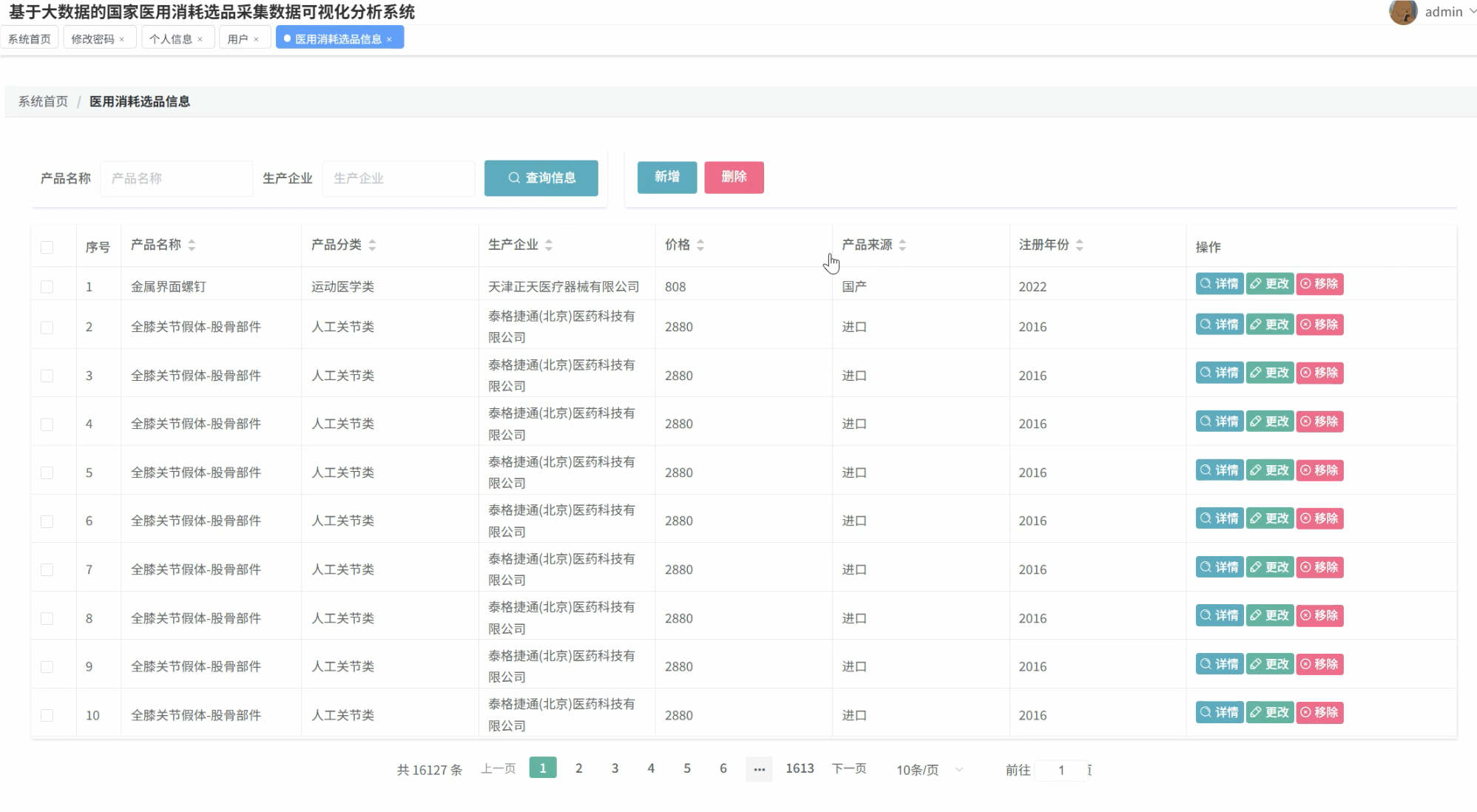
本课题基于Spark的国家医用消耗品选品采集数据可视化分析系统,成功将大数据技术与医疗健康领域的实际业务需求相结合,构建了一套完整的数据分析解决方案。系统采用Hadoop+Spark作为大数据处理核心,能够高效处理海量医用耗材数据,通过Python+Django框架搭建稳定的后端服务,结合Vue前端框架和Echarts可视化组件,实现了从数据采集、处理到可视化展示的全流程管理。
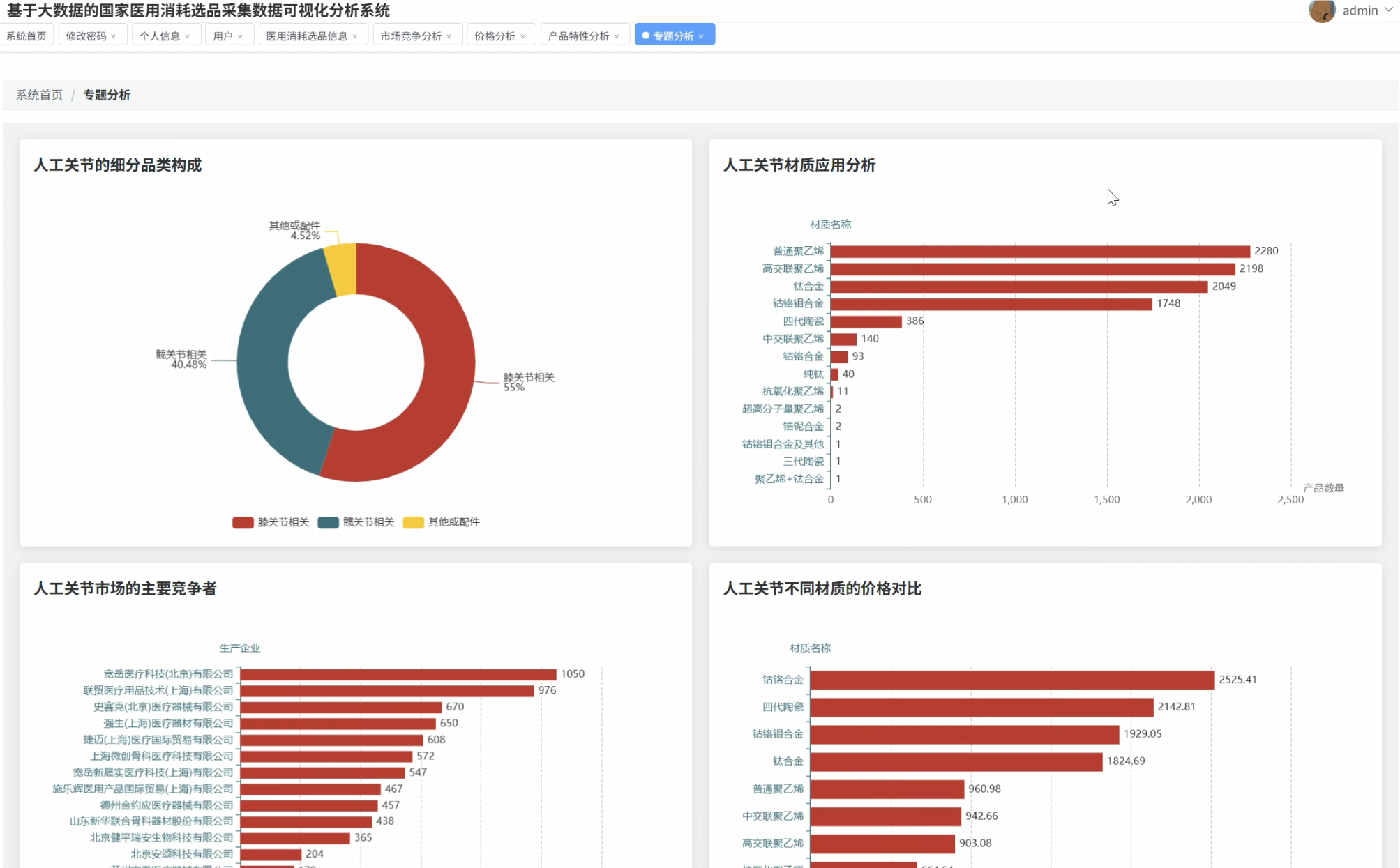
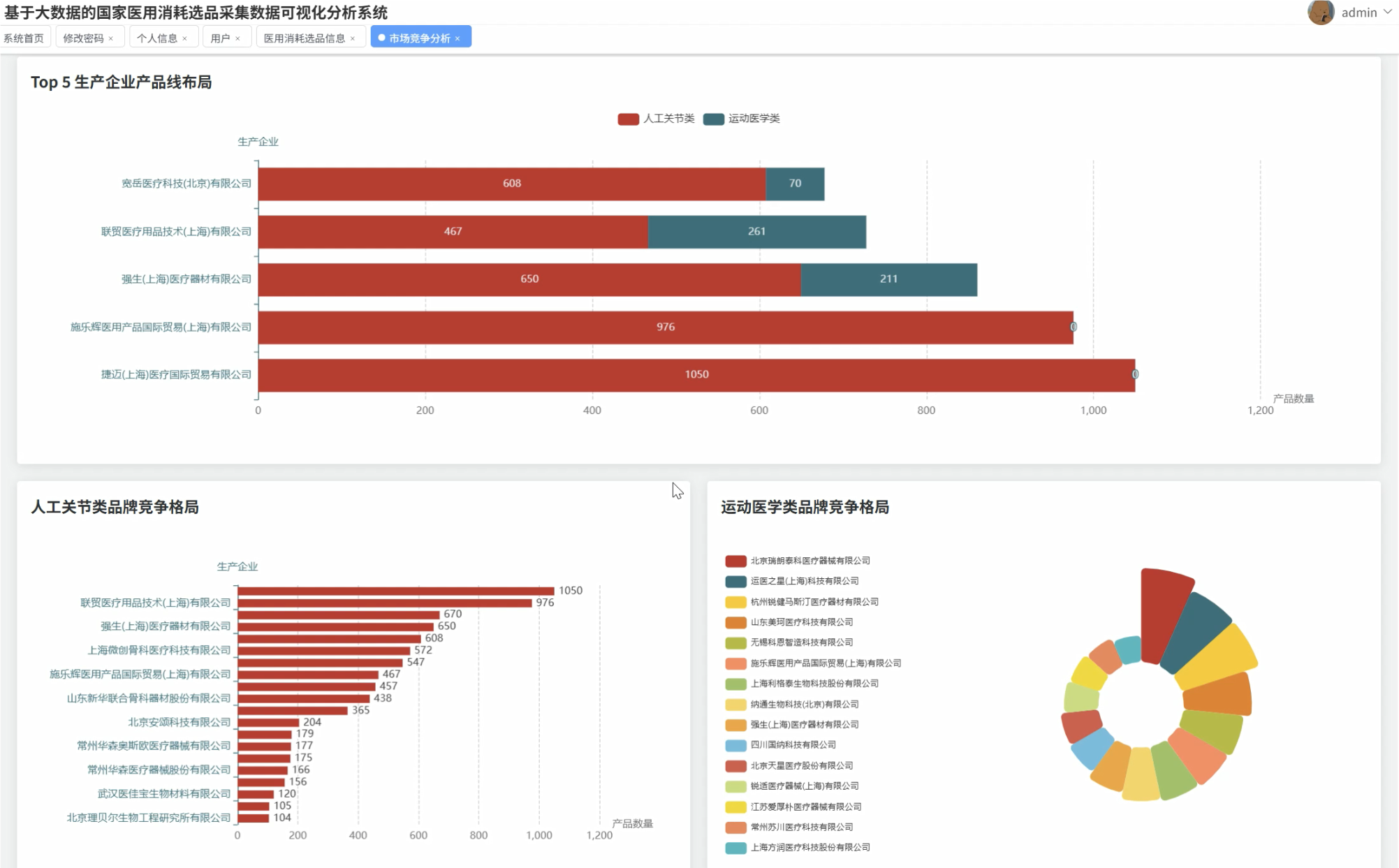
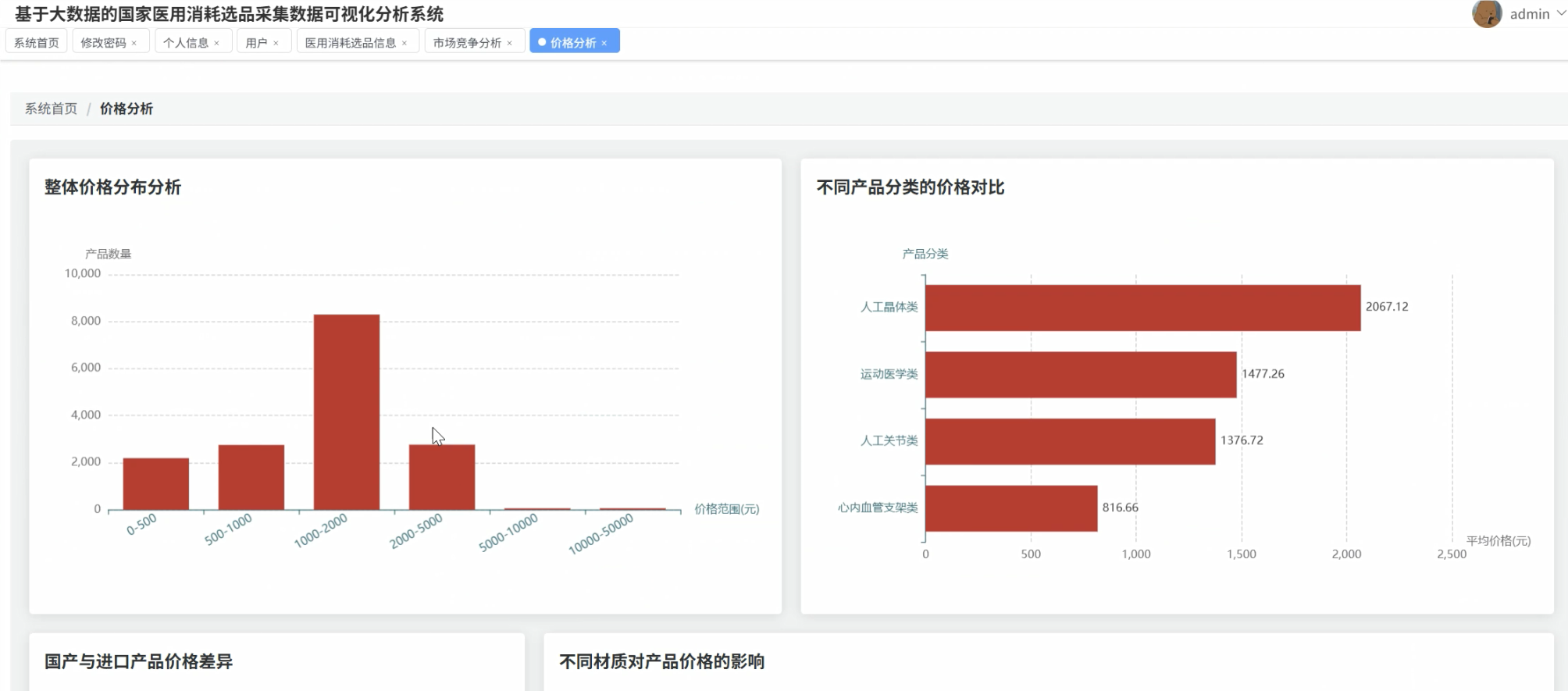
系统围绕价格水平分析、市场竞争格局、产品特性趋势以及人工关节专题分析四个核心维度,深入挖掘医用耗材数据的潜在价值。通过价格分布统计、品牌集中度分析、国产进口对比等功能模块,为医疗机构采购决策、政府监管部门政策制定以及生产企业市场布局提供了科学的数据支撑。系统不仅解决了传统人工统计效率低下的问题,更通过直观的图表展示帮助用户快速洞察市场动态和发展趋势。
该项目的成功实施验证了大数据技术在医疗信息化建设中的应用价值,为相关领域的数据分析系统开发提供了可借鉴的技术方案和实践经验,具有良好的推广应用前景。
大家可以帮忙点赞、收藏、关注、评论啦👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖