Tomcat服务器集群
目录:
1. 描述
在单一的服务器上执行WEB应用程序有一些问题,当网站成功建成并开始接受大量请求时,单一服务器无法满足需要处理的负荷量。
另外一个常见的问题是会产生单点故障,如果该服务器坏掉,那么网站就立刻无法运作了。
不论是因为要有较佳的扩充性还是容错能力,我们都会想在一台以上的服务器计算机上执行WEB应用程序。
所以,这时候我们就需要用到集群这一门技术了。
1.1 集群(Cluster)
集群是一组协同工作的服务实体(可理解为服务器),用以提供比单一服务实体更具扩展性与可用性的服务平台。在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。
1.2 负载均衡(Load Balance)
负载均衡实现了并发数的分流从而有效的实现减少单机服务器的压力,使高并发的情况下集群整体依然能够拥有较好的性能。同时负载均衡后的集群具有一定的容错率,当某一单机服务器down掉后,负载均衡使用分发机制将其分配到其他正在运行的服务器上,继续操作。
1.3 反向代理负载均衡
常用的负载均衡技术有很多种,本文使用反向代理Apache+JK2实现Tomcat集群与负载均衡。
使用代理服务器可以将请求转发给内部的Web服务器,让代理服务器将请求均匀地转发给多台内部Web服务器之上,从而达到负载均衡的目的。
1.4 实现原理
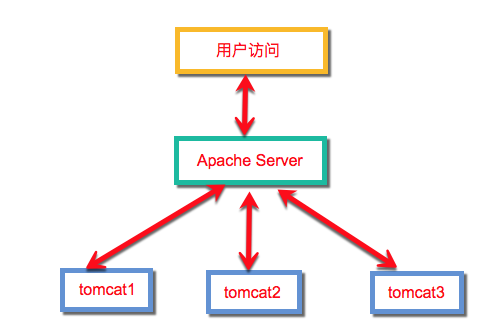
- 环境准备
测试环境为win8.1+jdk1.8.0
| 版本 | 下载 | 作用 |
|---|---|---|
| Apache2.4 | Download - The Apache HTTP Server Project | 用于分发请求 |
| Tomcat8.5.15 | Apache Tomcat® - Welcome! | web服务器 |
| Mod_jk | Index of /dist/tomcat/tomcat-connectors/jk/binaries/windows | 建立Apahce和Tomcat直接的连接 |
本文采用上述的版本进行演示,其他版本操作可能略有不同,请自行处理。
2.1 Apache
下载完成之后,直接安装apache,安装完成之后,在浏览器中输入http://localhost/,能够看到下图则说明安装成功:
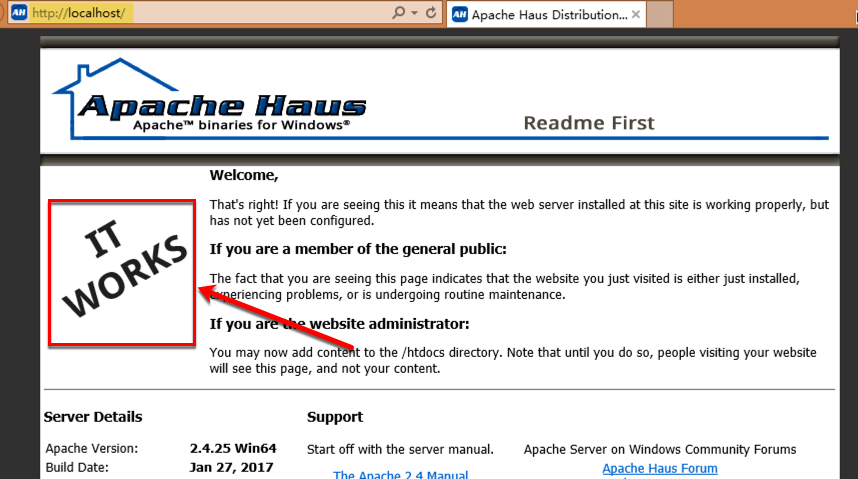
2.2 Tomcat
解压下载好的tomcat压缩包,复制三分解压好的tomca文件夹,分别重命名为tomcat1,tomcat2,tomcat3。
3. 配置过程
后面使用的文件功能说明:
(a) mod_jk.conf:主要定义 mod_jk 模块的位置以及 mod_jk 模块的连接日志设置,还有定义 worker.properties 文件的位置。
(b) worker.properties:定义 worker 的参数,主要是连接 tomcat 主机的地址和端口信息。如果 Tomcat 与 apache 不在同一台机器上,或者需要做多台机器上 tomcat 的负载均衡只需要更改 workers.properties 文件中的相应定义即可。% APACHE_HOME %为你的安装目录。
3.1 Apache配置修改
(1)修改httpd.conf
我的Apache安装在C:\cluster\Apache24找到conf目录下的httpd.conf,在文件的最后一行添加:
- Include "C:\cluster\Apache24\conf\mod_jk.conf"
注:以上表示将 mod_jk.conf 配置文件包含进来
(2)新建mod_jk.conf文件
在conf目录下新建mod_jk.conf文件,内容如下:
-
LoadModule jk_module modules/mod_jk.so
-
JkWorkersFile conf/workers.properties
-
JkMount /*.jsp controller
第一行最后的文件名为jk的文件名,根据下载的jk的名字不同而不同。
第二行表示指定哪些请求交给tomcat处理,"controller"为在workers.propertise里指定的负载分配控制器名。
第三行表示可以进行集群的文件类型,这里写*.jsp表示集群的文件只能是jsp文件,如果不区分文件类型,则直接写成JkMount /* controller即可。
(3)Mod_jk
在bin目录下输入.\httpd -v查看apache版本号,下载对应的文件

解压下载的Mod_jk文件,将里面的so文件复制到Apache安装目录的modules目录下,这里下载的Mod_jk文件名为mod_jk.so。
(4)新建并编辑workers.properties文件
在conf文件夹下新建workers.properties,内容如下: -
#server
-
worker.list = controller
-
#========tomcat1========
-
worker.tomcat1.port=11009
-
worker.tomcat1.host=localhost
-
worker.tomcat1.type=ajp13
-
worker.tomcat1.lbfactor = 1
-
#========tomcat2========
-
worker.tomcat2.port=12009
-
worker.tomcat2.host=localhost
-
worker.tomcat2.type=ajp13
-
worker.tomcat2.lbfactor = 1
-
#========tomcat3========
-
worker.tomcat3.port=13009
-
worker.tomcat3.host=localhost
-
worker.tomcat3.type=ajp13
-
worker.tomcat3.lbfactor = 1
-
#========controller,负载均衡控制器========
-
worker.controller.type=lb
-
worker.controller.balanced_workers=tomcat1,tomcat2,tomcat3
-
worker.controller.sticky_session=false
-
worker.controller.sticky_session_force=1
-
#worker.controller.sticky_session=1
worker.controller.sticky_session=false,提交页面,将按照负载均衡的规则切换服务器,实现"完全的负载均衡",代价是Tomcat不停交换session数据,慢;
worker.controller.sticky_session_force=true,始终转发到session创建的服务器上。
注:其中1代表true,0代表false
上面最后的代码中使用到的参数详细解释如下:
| sticky_session | sticky_session_force | 含义 |
|---|---|---|
| true | false | SESSION不复制,有粘性 |
| true | true | SESSION复制,有粘性 |
| false | false | SESSION不复制,无粘性 |
| false | true | SESSION复制,无粘性 |
如果需要配置远程的tomcat服务器的话,只需要将worker.tomcat3.host=localhost中的localhost改为远程服务器的IP地址即可。
本次配置都是本地的tomcat,并且在一台机器上,所以端口号都不相同,如果在不同机器上,http和shutdown端口号则不需要更改。
3.2 Tomcat集群配置
分别打开tomcat1/tomcat2/tomcat3目录下的conf/server.xml文件,进行修改
(1)修改tomcat端口
由于这里是同一台机器上使用三个tomcat,为了避免端口冲突,需要修改tomcat服务器的http/shutdown/ajp端口号。
(2)修改集群设置
对于tomcat8.5.15要做集群的话,只需要将<Engine>元素下的
<!--
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"/>
-->
的注释符号去掉,启用这句配制就可以正常使用集群。
(3)Engine 增加 jvmRoute 属性设置
jvmRoute 的值来自于 workers.properties 文件所设置的服务器名称,3个tomcat里,jvmRoute分别配置成tomcat1/tomcat2/tomcat3。
修改完成后如下图:
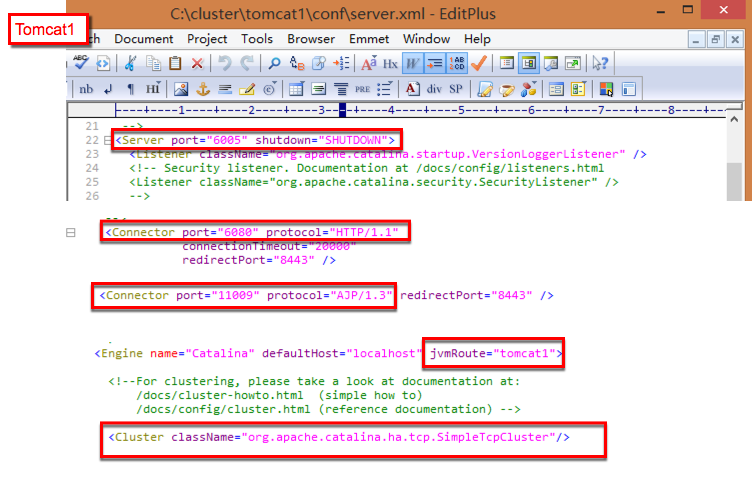
注:由于这里三个tomcat全在一台机器上,所以需要修改三种类型的端口号,如果是在不同的机器上,则只需要修改AJP13的connector的port,其他端口号不需要修改。
另:jvmRoute里的名称和workers.properties中配置都必须对应。
4. 结果测试
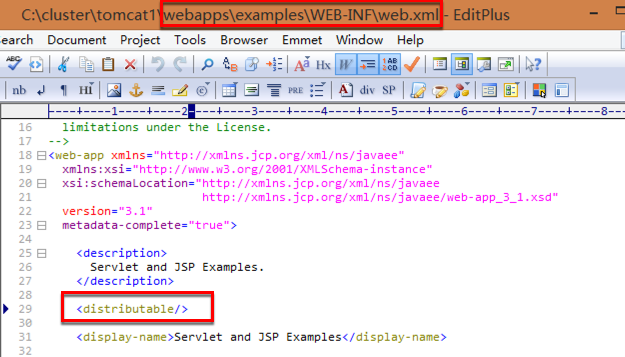
在tomcat下面的项目文件夹中修改web.xml,如这里使用自带的examples项目,则修改三个tomcat下面的examples项目中的web.xml,在每个web.xml的<web-app>节点里添加新的节点<distributable/>,此应用将与集群服务器复制Session,如下图:
注:这里是用来测试此种情况演示效果的,实际部署我们工程的时候,web.xml可以不添加
在每个examples项目文件夹下新建test.jsp,内容如下:
- <%@ page contentType="text/html; charset=GBK" %>
- <%@ page import="java.util.*" %>
- <html><head><title>Cluster App Test</title></head>
- <body>
- Server Info:
- <%
- out.println(request.getLocalAddr() + " : " + request.getLocalPort()+"<br>");%>
- <%
- out.println("<br> ID " + session.getId()+"<br>");
- // 如果有新的 Session 属性设置
- String dataName = request.getParameter("dataName");
- if (dataName != null && dataName.length() > 0) {
- String dataValue = request.getParameter("dataValue");
- session.setAttribute(dataName, dataValue);
- }
- out.println("<b>Session 列表</b><br>");
- System.out.println("============================");
- Enumeration e = session.getAttributeNames();
- while (e.hasMoreElements()) {
- String name = (String)e.nextElement();
- String value = session.getAttribute(name).toString();
- out.println( name + " = " + value+"<br>");
- System.out.println( name + " = " + value);
- }
- %>
- <form action="test.jsp" method="POST">
- 名称:<input type=text size=20 name="dataName">
- <br>
- 值:<input type=text size=20 name="dataValue">
- <br>
- <input type=submit>
- </form>
- </body>
- </html>
4.1 节点插拔测试
项目部署好之后,启动三个tomcat以及Apache,启动顺序随意,然后再浏览器中输入http://localhost/examples/test.jsp
(1)关闭Tomcat
关闭tomcat3,刷新页面,可以不断访问tomcat1和tomcat2,再关闭tomcat2,只能够访问tomcat1,说明节点关闭时运行正常。
(2)启动tomcat
如果重启Tomcat2,无论怎么刷新,始终访问Tomcat3,无法访问tomcat2,这时利用另外台机器访问页面,发现Tomcat2正常,然后在刷本地页面,又可以访问Tomcat2了。
对于每个新来的session,Apache按照节点配置中的lbfactor比重选择访问节点,如果某节点node1不能访问,则寻找下一可访问节点,并且将此node1就在该访问session的访问黑名单中,以后该session的访问直接不考虑node1,即使node1又可以访问了。
而新来的session是无黑名单的,如果新的session能够访问到node1了,则会将node1在其他所有session访问的黑名单删除,这样其他session就又能访问node1节点了。
经过以上测试,说明Tomcat集群和负载均衡已经实现了。