clickhouse
之前定时任务读取binlog 批量同步clickhouse
kafka 批量给clickhouse灌数据
- clickhouse列式数据库,运行时创建库表,加载数据查询
- 数据压缩,磁盘存储,向量化引擎,利用CPU多核并行处理
- 缺少完整的update/delete,不支持事务,不适合k-v blob等文档型数据库
基础
column和field:接口和实现 icolumn对数据的各种运算
dataType序列化反序列化,二进制/文本列/值 直接与表的数据类型
idataType存储元数据,数据的序列化和反序列化由dataType负责,对应的数据类型实现
数据读取交给column和field获取
块:block 内存中表的子集的容器,icolumn/idataType/列名 构成的集合
数据操作面向block进行的,流的形式
blockStream:读取 数据转换 写入
iblockInputStream数据读取和关系运算,read 下一块数据
数据定义DDL/关系运算/表引擎对应
iblockOutputStream数据输出到下一个环节,write
数据读写:readBuffer/writeBuffer 抽象类 面向字节输入输出
连续缓冲区/指向缓冲区某个位置的指针:处理文件 描述符 网络套接字 压缩
表table:istorage接口,表引擎
read方法返回iblockInputStream 并行处理数据,多块输入流一个表并行读取
ast查询被传递给read方法,表引擎用它判断是否使用索引,表中读取更少的数据
解析器parser:递归解析
解释器Interpreter:ast 创建流水线 块输入 输出流,将sql 递归下降 解析ast语法树
函数:functions
普通函数:不改行数 独立处理每行数据,block为单位 向量查询一整列
聚合函数:状态函数,可序列化 分布式查询执行期间通过网络传输/内存不够的时候写入硬盘
传入的值激活到某个状态,从该状态取结果
引擎

log/mergeTree/integration/special四个系列
- log少量数据(小于一百万行)不支持索引,so范围查询效率不高
- integration导入外部数据到ck,或ck直接操作外部数据,kafka hdfs jdbc mysql
- special,如memory将数据存储在内存,重启后丢失数据,查询性能极好,file将本地文件作为数据存储等大多是为了特定场景定制
- mergeTree自身拥有多种引擎的变种,mergeTree作为家族最基础引擎提供逐渐索引/数据分区/副本/采样等能力并且支持极大量的数据写入
mergeTree,多种表引擎 最基础 主键索引/数据分区/数据副本/采样
写入一批数据,数据以数据片段形式写入磁盘,不可修改片段
后台定期合并片段,相同分区合并一个新的
分区目录保存到磁盘,数据写入不断创建新分区目录,后台任务合并
主键:可重,一般主键 same 排序键,可不同 主键必须为排序键的子集
主键字段必须在排序键字段中最左侧
ReplacingMergeTree
合并分区去掉重复数据,直接删除/查询的时候去重
- ver版本列未指定,相同主键行中保留最后插入的一行
- ver版本列已经指定,去重将保留的version值最大的一行,与数据插入顺序无关
- 合并时机不确定,在查询时会有重复数据,最终去重,手动调optimize,引发大量读写
- 同一分区的数据会被删除,不同的重复数据不会被删除
- final/argMax做查询去重,select * from table final 只对本地表去重 不跨分片;select argMax(field) from table 比较version大小,取最新数据,每个shard数据同一个shard计算
- 强制分区 optimize table table_name final
CollapsingMergeTree
sian字段 记录 数据行状态,sign=1 有效数据,-1取消 需要被删除
对写入的顺序有严格要求,按照正常顺序写入,先写sign=1的行再写sign=-1的行,正常合并
- optimize强制合并,不建议
- group by配合符号的sign列,增加编码成本
- sign=1比sign=-1的数据多至少一行,保留最后一行sign=1多数据
- sign=-1 比 sign=1 多至少一行,则保留第一行 sign=-1 的行
- sign=1 与 sign=-1 的行数一样多,最后一行是 sign=1,则保留第一行 sign=-1 和最后一行 sign=1 的数据
- sign=1 与 sign=-1 的行数一样多,最后一行是 sign=-1,则什么都不保留
- 其他情况 ClickHouse 不会报错但会打印告警日志,查询的结果是不确定不可预知的
数据分区
分区id决定,分区键 * 字段表达式声明
- 不指定分区键,不适用 默认 all 所有数据都写入all分区
- 整形,无法转换日期YYYYMMDD,直接按照整形字符串输出
- 日期,YYYYMMDD格式化后字符串形式输出,分区ID
- 其他类型,128位hash取值作为分区id值
分区号:时间戳_minBolckNum_maxBolckNum_合并次数
最小块/最大块minBolckNum maxBolckNum
分布式表
- 逻辑表不存储真实物理数据
- 查询分布式表,把查询请求分发到每个分片的本地表上进行查询,集合结果汇总返回
- 写入分布式表,根据一定规则,将写入的数据按规则存储到不同分片上
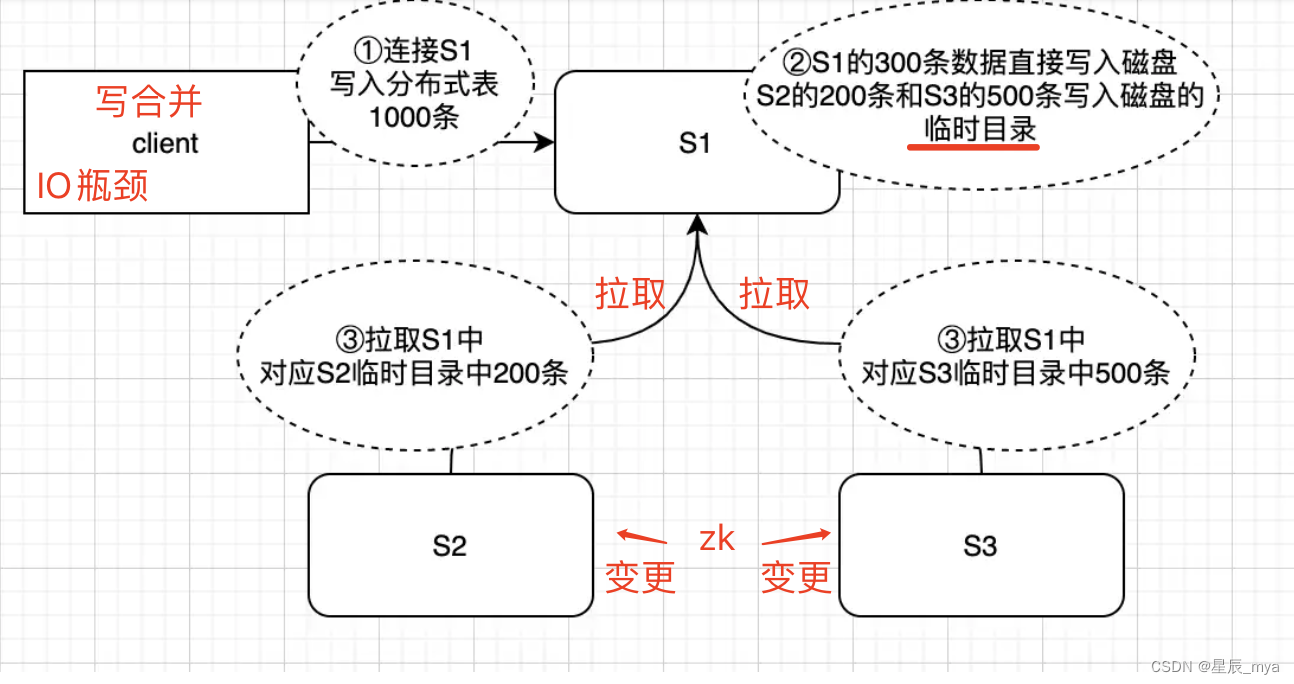
问题:
数据分布不均,部分节点CPU高:分片策略尽可能均匀 好吧
节点触发合并,导致该节点CPU高: 分区不均匀 建立(二级)索引
物理故障
定位问题:
- sql执行频率是否过高:grafana自定义sql定位查询接口代码逻辑
- 慢sql在执行,system.query_log本地表
高频执行 或 慢查询大量消耗cpu计算资源
优化:
降低 ClickHouse 单次查询处理的数据量,也就是降低磁盘 IO
-
clickhouse-client,send_logs_level 参数指定日志级别为 trace,是否使用(主键/分区)索引
clickhouse-client -h 地址 --port 端口 --user 用户名 --password 密码 --send_logs_level=trace
- 建表优化,尽量不使用nullable,不能被索引,还需要额外存储文件null标记
分区粒度:据业务场景设置,查询只处理本次查询条件范围内的数据,不额外处理不相关的数据
分片规则:唯一性,高识别度
clickhouse-benchmark
clickhouse-benchmark -c 1 -h 链接地址 --port 端口号 --user 账号 --password 密码 <<< "具体SQL语句"条件聚合函数 :减少整体扫描量/提升性能
二级索引:mergeTree表引擎指定跳数索引
- 数据片段按粒度(建表index_granulartiry)分割成小块,granularity_value数量小块组合成一个大块
- 重建分区索引数据:建二级索引前,不走二级索引,重建每个分区的索引数据才能生效
final替换argMax去重:
#final方式
select count(distinct groupOrderCode), sum(arriveNum), count(distinct sku) from tms.group_order final prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1'
#argMax方式
select count(distinct groupOrderCode), sum(arriveNumTemp), count(distinct sku) from (select argMax(groupOrderCode,version) as groupOrderCode, argMax(arriveNum,version) as arriveNumTemp, argMax(sku,version) as sku from tms.group_order prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1' group by docId)prewhere代替where
sql的filter条件加上prewhere过滤条件,存储扫描两个阶段
-
读取prewhere表达式中依赖的列值存储块,检查是否有记录满足条件
-
prewhere优先于final执行,对status值可变的字段能查询到中间状态的数据行,导致数据不一致
--语句1:使用where + status=1 查询,无法命中docId:123_1这行数据
select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '1';
--语句2:使用where + status=2 查询,可以查询到docId:123_1这行数据
select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '2';
-- 语句3:错误方式,将status放到prewhere
select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' and status = '1';
-- 语句4:正确prewhere方式,status可变字段放到where上
select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;
列裁剪,分区裁剪
大数据量宽表,减少select * 操作,对列裁剪,只选择需要的,消耗io少
where/group by列顺序
要和建表语句中order by列顺序一致,放在最前面使得它连续不断公共前缀
高并发
降低查询速度,提高吞吐量:max_threads,users.xml中单个查询所能使用的最大cpu数=cpu核数
调低,牺牲单次查询速度保证ck可用性,提高并发能力,可通过jdbc的url设置
接口增加一定时间的缓存
异步任务执行查询语句
物化试图,预聚合方式
flink
ck:不少于1000行批量写入,每秒不超过一个写入请求
https://zhuanlan.zhihu.com/p/657456888
https://www.zhihu.com/question/505958148/answer/3043910138?utm_id=0