摘要
MergeTree是ClickHouse最核心的存储引擎,采用列式存储+LSM-Tree架构设计,支持高效的数据写入、合并和查询。本文将全面解析MergeTree引擎的基础概念、数据流、核心架构、索引系统以及常见问题。
基础篇:
一、MergeTree引擎基础概念
1. 定义
MergeTree是ClickHouse中最高性能的存储引擎,专为大规模数据分析场景设计,具有以下核心特性:
|---------------|--------------------------------------|--------------------------|
| 特性分类 | 详细说明 | 技术价值 |
| 列式存储结构 | 数据按列而非按行存储,每列独立压缩 | 提升压缩率5-10倍,减少I/O消耗70%+ |
| 主键索引 | 稀疏索引设计(默认8192行粒度),支持ORDER BY键快速定位 | 使范围查询效率提升100倍+ |
| 自动数据分区 | 按PARTITION BY表达式自动划分数据目录 | 实现分区裁剪,减少90%+无关数据扫描 |
| 后台合并机制 | 异步合并小Parts为优化后的大Part(LSM-Tree架构) | 写入吞吐量可达50MB/s,查询性能提升300% |
| 衍生引擎变种 | 包括Replacing/Summing/Aggregating等7种变体 | 覆盖去重、预聚合等专项场景需求 |
2. 引擎家族图谱
|-------|----------------------|--------|
| 引擎类型 | 主要变种 | 核心特性 |
| 基础变种 | ReplacingMergeTree | 支持数据去重 |
| 基础变种 | SummingMergeTree | 预聚合计算 |
| 基础变种 | AggregatingMergeTree | 高级聚合功能 |
| 分布式变种 | ReplicatedMergeTree | 支持数据副本 |
| 分布式变种 | Distributed | 分片集群支持 |
二、核心架构与数据流
1. 存储架构分层图
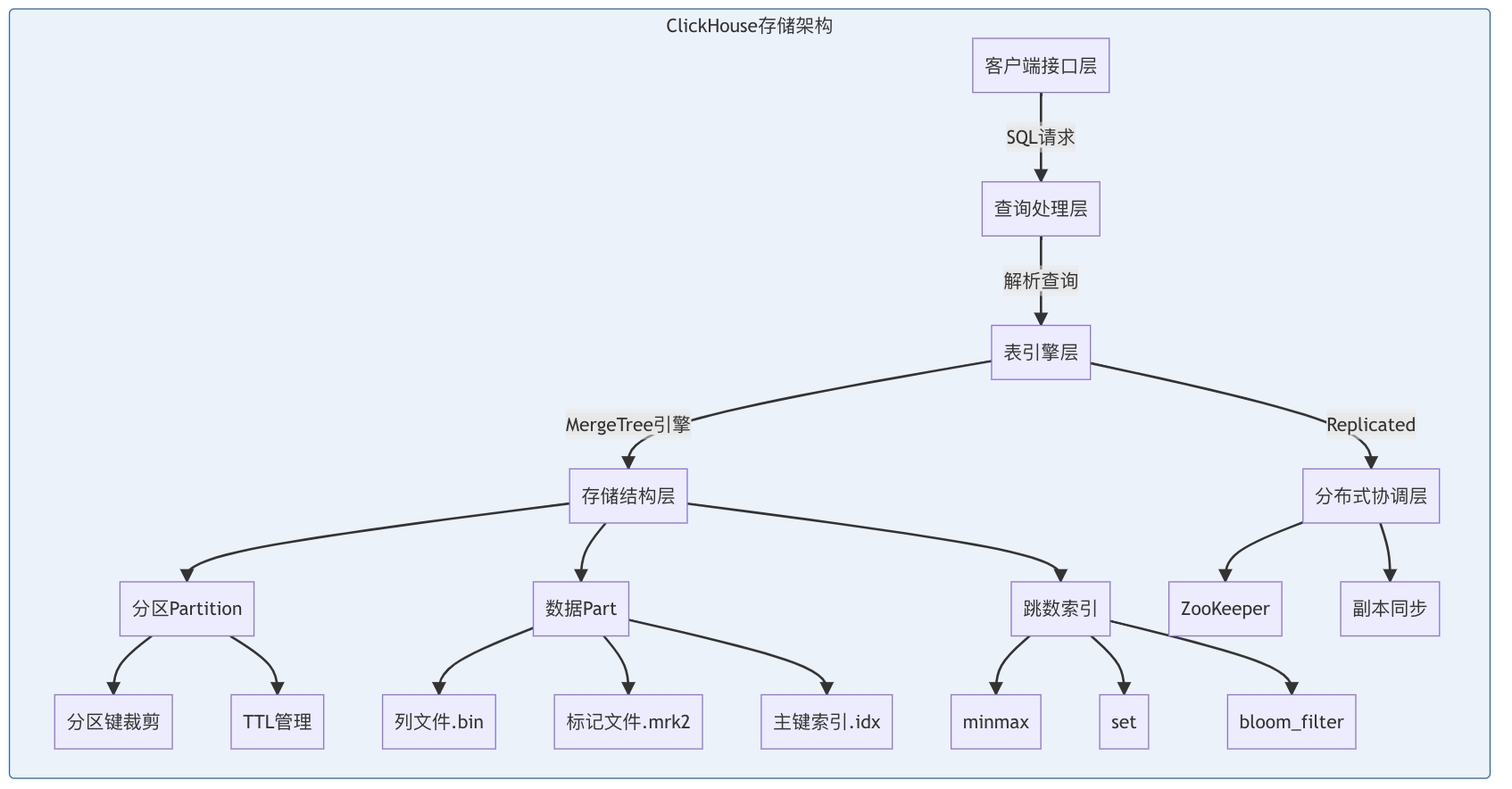
关键说明:
- 分区(Partition)是数据物理隔离的最小单位,按分区键自动裁剪
- 每个Part包含列文件、标记文件和主键索引三要素
- 跳数索引通过minmax/set等算法加速查询
2. 数据写入时序图
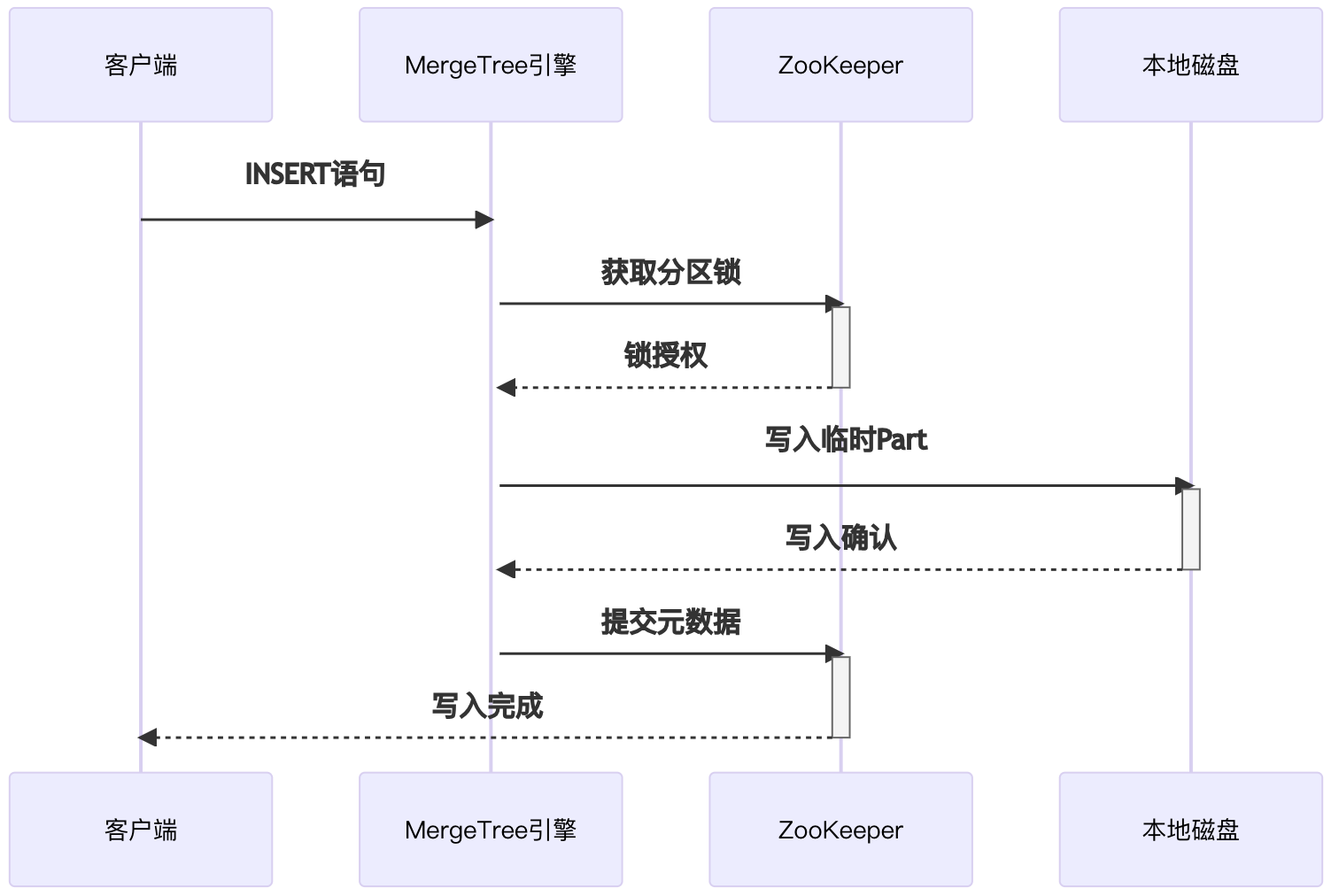
关键说明:
- 采用两阶段提交保证分布式一致性
- 临时Part经后台合并转为正式Part
- 元数据变更通过ZooKeeper同步
3. 后台合并流程时序图
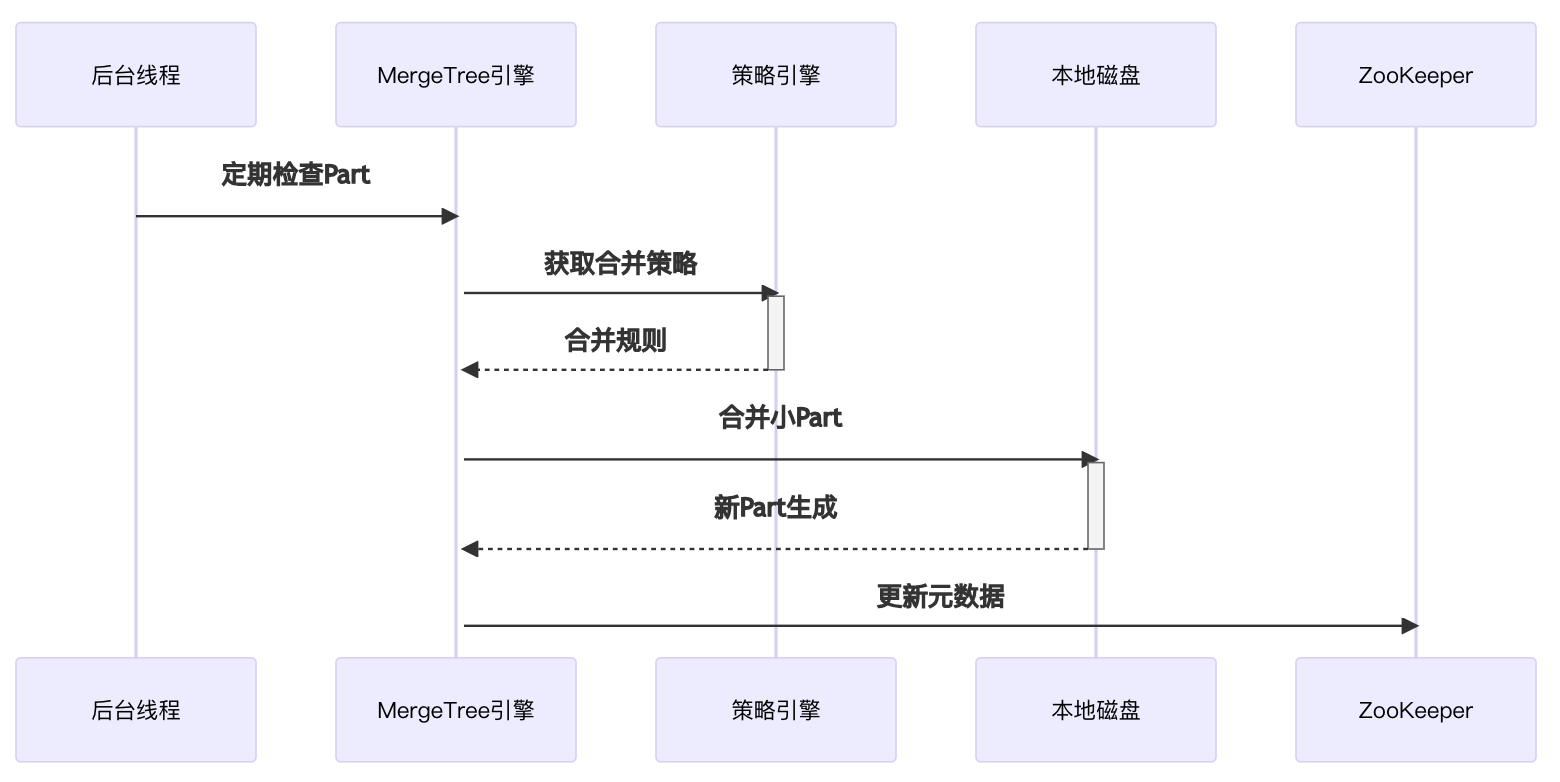
关键说明:
- 合并策略基于Part大小/数量自动触发
- 合并过程产生新Part并原子替换旧Part
- 后台线程默认10分钟执行一次
4. 数据查询时序图
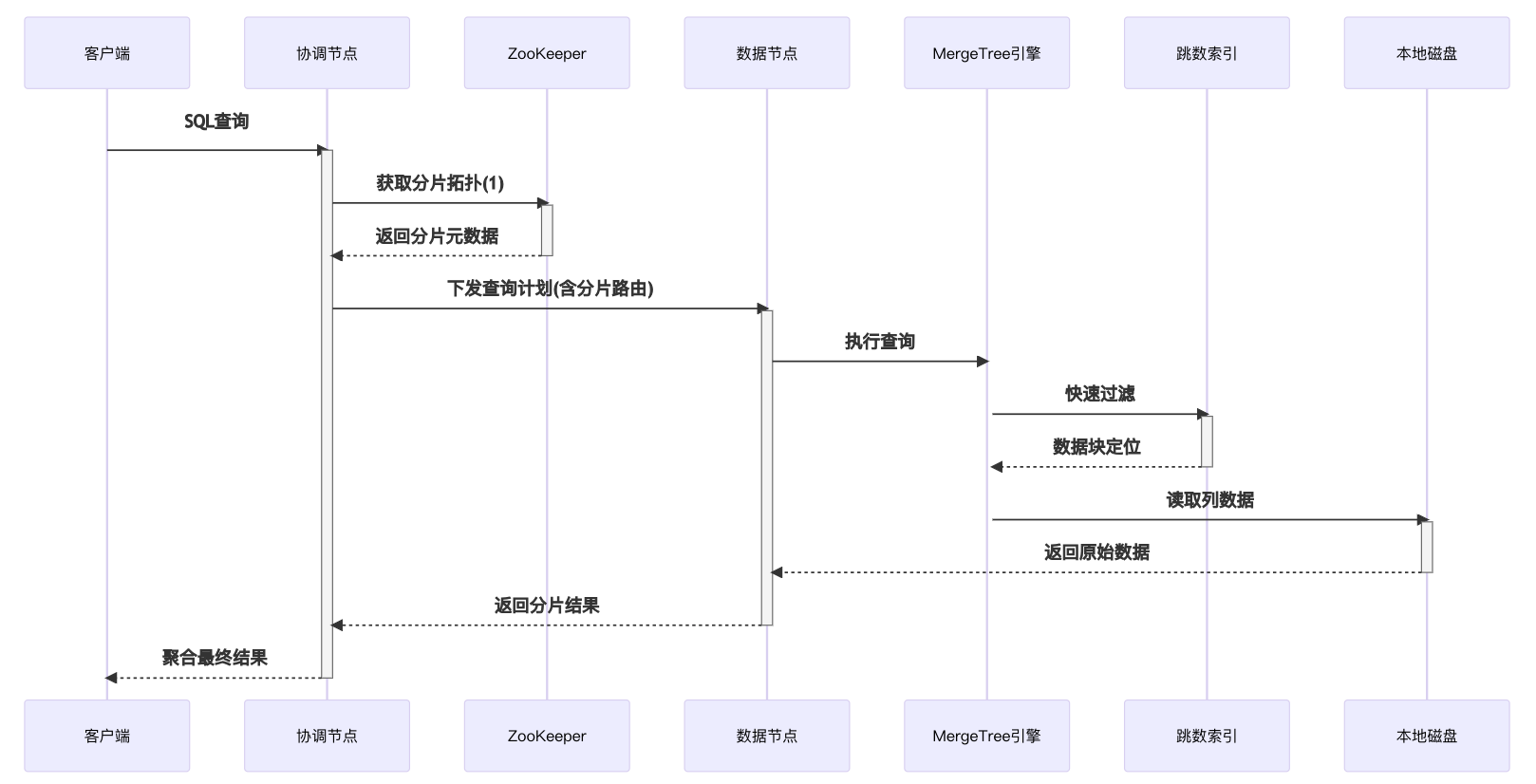
关键说明:
- 查询采用MPP并行处理模式
- 跳数索引实现"预过滤"优化
- 列存储实现按需读取
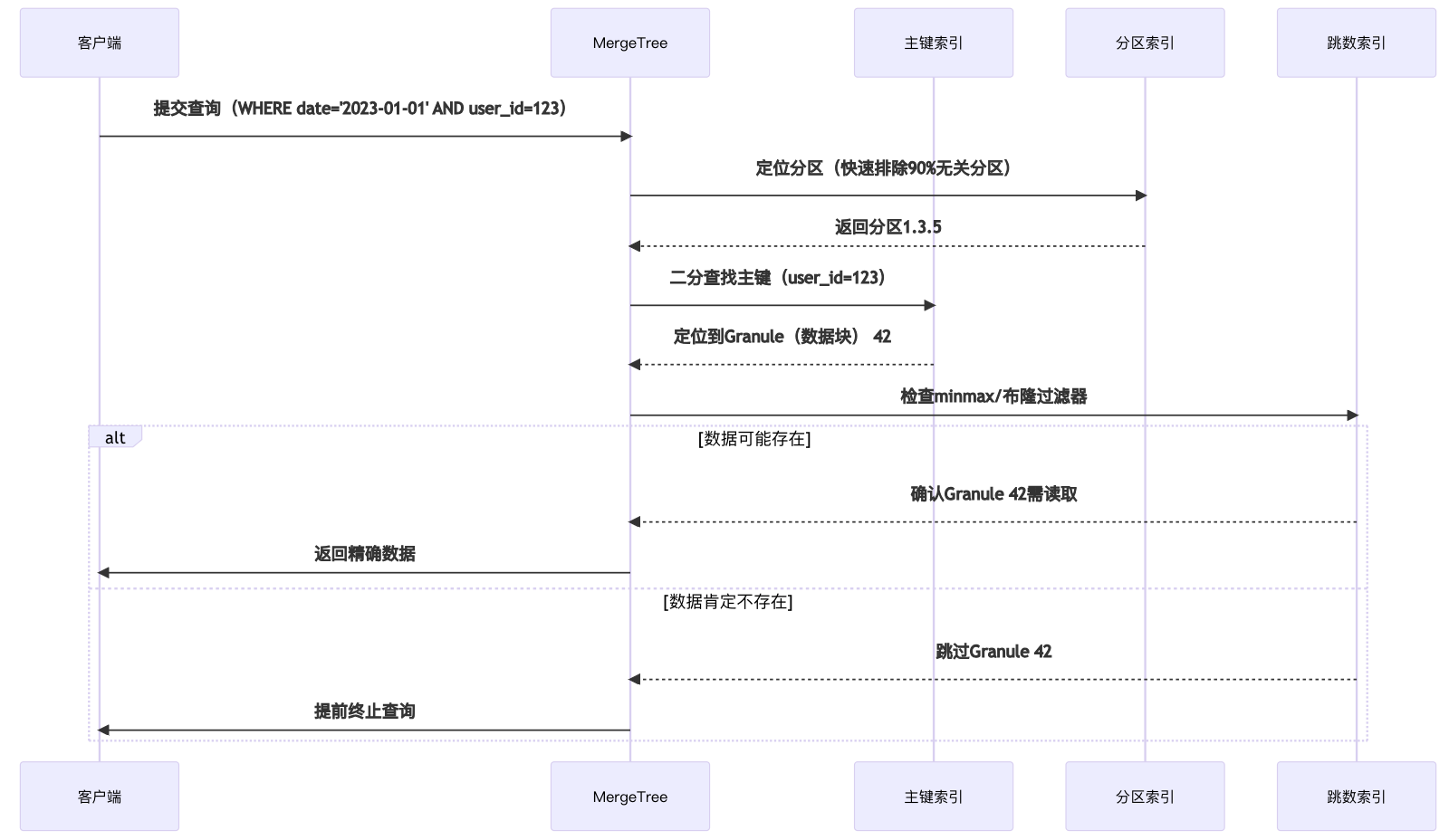
三、索引解析:三级索引协同工作原理
1. 三级索引体系架构图
2. 索引功能对照表
|-------------|-------------|----------------------|------------------------|----------------------|
| 索引类型 | 物理结构 | 触发条件 | 优化效果 | 项目案例 |
| 一级索引 | 内存中的稀疏索引 | WHERE涉及PRIMARY KEY | 减少99%数据扫描 | 用户画像查询从12s→0.3s |
| 分区索引 | 分区目录元数据 | WHERE涉及PARTITION BY列 | 大表查询速度提升8-10倍 | 日志分析按day分区后QPS提升430% |
| 跳数索引 | Granule级元数据 | WHERE涉及普通列 | 减少I/O 30-70%(取决于索引类型) | 商品搜索使用布隆过滤器降低60%IO |
3. 协同工作深度解析
**阶段一:分区裁剪(Partition Pruning)**
# 分区表达式示例`
`partition_expr =` `"toYYYYMMDD(event_time)"`
`# 查询优化器自动转换为分区范围`
`WHERE event_time >` `'2023-01-01'`
`→ 转换为分区ID范围:20230101 ≤ partition_id ≤ 20231231`
`**阶段二:主键定位(Primary Key Lookup)**
// ClickHouse内核处理流程`
`1. 将WHERE user_id=123转为Mark Range(区间标记)`
`2. 通过稀疏索引定位到Granule(数据块) 42(假设每8192行一个Mark)`
`3. 仅加载对应Granule的列文件(.bin)`
`**阶段三:跳数索引过滤(Skipping Index Filter)**
|---------------------|-------------|-------------------------------------------|-------------|
| 索引类型 | 适用场景 | 项目配置 | 性能收益 |
| minmax(极值索引) | 数值范围查询 | INDEX idx_price TYPE minmax GRANULARITY 3 | 减少45%读取量 |
| bloom_filter(布隆过滤器) | IN/等值查询 | INDEX idx_sku TYPE bloom_filter(0.025) | 降低60%CPU开销 |
实战篇:
四 、 数据更新与删除策略深度解析
1. 核心设计理念
ClickHouse采用LSM-Tree架构,其数据变更处理遵循"追加写入+后台合并"原则。与传统OLTP数据库不同,ClickHouse原生设计更侧重高性能分析而非高频单行变更,这导致其UPDATE/DELETE实现具有显著特殊性。
2. 实现原理
|------------|-------|-------------------------------|-----------------------|
| 变更类型 | 实现方案 | 核心机制 | 适用场景 |
| 删除 | 状态标记法 | 增加_is_deleted字段(0/1) | 需要保留历史记录的删除 |
| 删除 | 墓碑标记法 | 增加_sign字段(1/-1) | VersionedCollapsing场景 |
| 删除 | 轻量级删除 | 22.8+版本ALTER TABLE DELETE语法 | 物理删除需求 |
| 更新 | 版本覆盖法 | ReplacingMergeTree+_version字段 | 通用更新场景 |
| 更新 | 聚合更新法 | AggregatingMergeTree+状态函数 | 指标类数据更新 |
| 更新 | 增量合并法 | CollapsingMergeTree+_sign字段 | 状态变更类更新 |
3. 技术实现方案案例
场景:电商商品数据实时新增/更新
实时管道最佳实践**:**
mysql binlog →` `Kafka → Flink实时ETL → ODS层` `→ DWD层(物化视图)`
`物化视图通过预计算和自动更新机制,显著提升大数据分析查询性能,详见我的博客《ClickHouse物化视图避坑指南:原理、数据迁移与优化》
clickhouse中的脚本如下:
sql
-- 1. 基础存储层(全量快照)
CREATE TABLE ods.products_snapshot
(
product_id UInt64,
product_name String,
price Decimal(18,2),
category_id UInt32,
update_time DateTime,
_version UInt64 MATERIALIZED toUnixTimestamp(update_time)
)
ENGINE = MergeTree()
ORDER BY (product_id);
-- 2. DWD层(版本化视图)
CREATE MATERIALIZED VIEW dwd.products
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/dwd_products', '{replica}', _version)
ORDER BY product_id
AS SELECT
product_id,
argMax(product_name, update_time) as product_name,
argMax(price, update_time) as price,
argMax(category_id, update_time) as category_id,
max(update_time) as update_time,
max(_version) as _version
FROM ods.products_snapshot
GROUP BY product_id;
-- 3. 基础查询(获取最新商品版本)
SELECT
product_id,
product_name,
price,
category_id
FROM dwd.products FINAL
WHERE product_id = 123;核心技术函数说明表
|-------------|------------------------|--------------|
| 函数类别 | 关键函数 | 功能说明 |
| 状态函数 | argMax/argMin | 保留指定字段最新/最旧值 |
| 版本控制 | toUnixTimestamp(now()) | 生成版本号 |
| 特殊引擎 | ReplacingMergeTree | 按版本自动去重 |
五、常见问题
1. 架构设计常见问题
- 如何选择排序键?推荐采用(ad_id, event_time)等双字段组合键
- 优先选择低基数且高频过滤的字段
- 避免过度使用Nullable类型
- 物化视图如何优化?
- 配合物化视图可实现毫秒级分析
- 建议按业务场景设计专用物化视图
2. 性能优化问题
- 分区策略优化:
- 设置分区TTL可自动清理旧数据
- 控制分区粒度在1-10GB/分区
- 索引优化:
- 跳数索引可使查询性能提升
- 合理设置max_parts_in_total参数
3. 工程实践问题
- 数据分层设计:
- 通过DWD/DWS分层可降低查询复杂度
- 建议基于原始底表构建轻聚合明细层(DWD)与指标服务层(DWS)
- 高并发支撑:
- 分布式物化视图集群可支撑5000+ QPS高并发查询
- 需考虑查询路由和负载均衡策略
六、总结
MergeTree引擎通过分层架构实现高性能分析:存储层(列文件+分区)保障数据压缩与局部性,计算层(稀疏索引+跳数索引)实现查询加速,管理层(ZooKeeper协调)确保分布式一致性。这种"写入即合并"的LSM-Tree设计,配合物化视图等衍生能力,使其在OLAP场景实现吞吐量与查询效率的完美平衡。