- Mysql5.x和Mysql8性能的差异
整体性能有所提高,
在非高并发场景下,他们2这使用区别不大,性能没有明显的区别。
只有高并发时,mysql8才体现他的优势。
- Mysql数据存储结构Innodb逻辑结构
数据选用 B+ 树结构存储数据,其中树的每一个节点是一个 page 页。
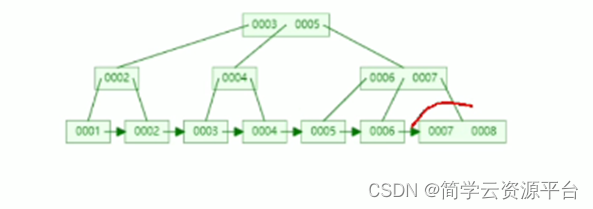

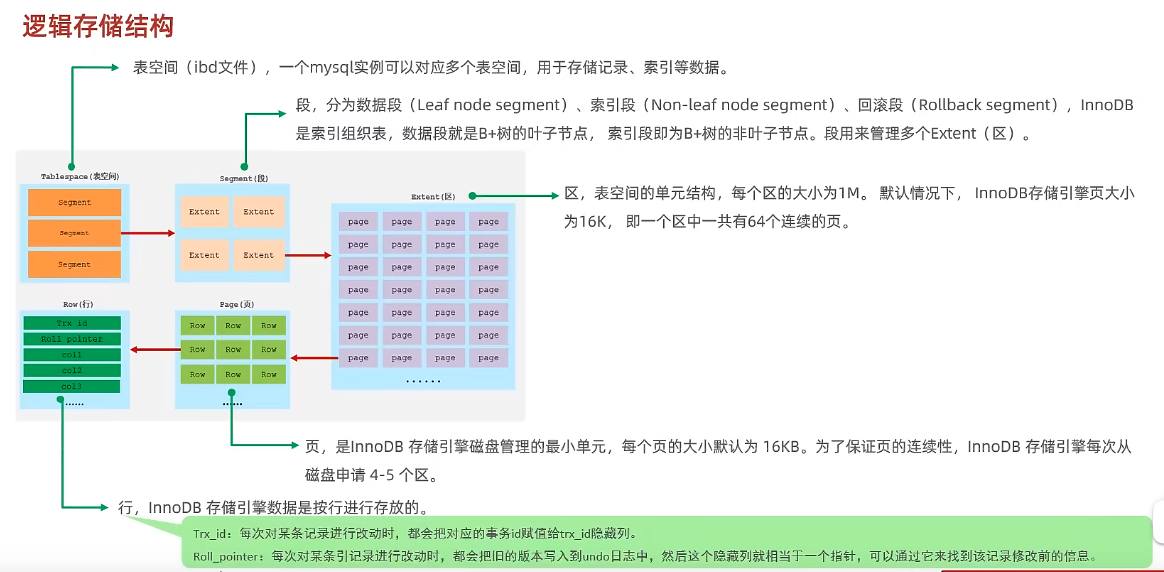
Page页的结构
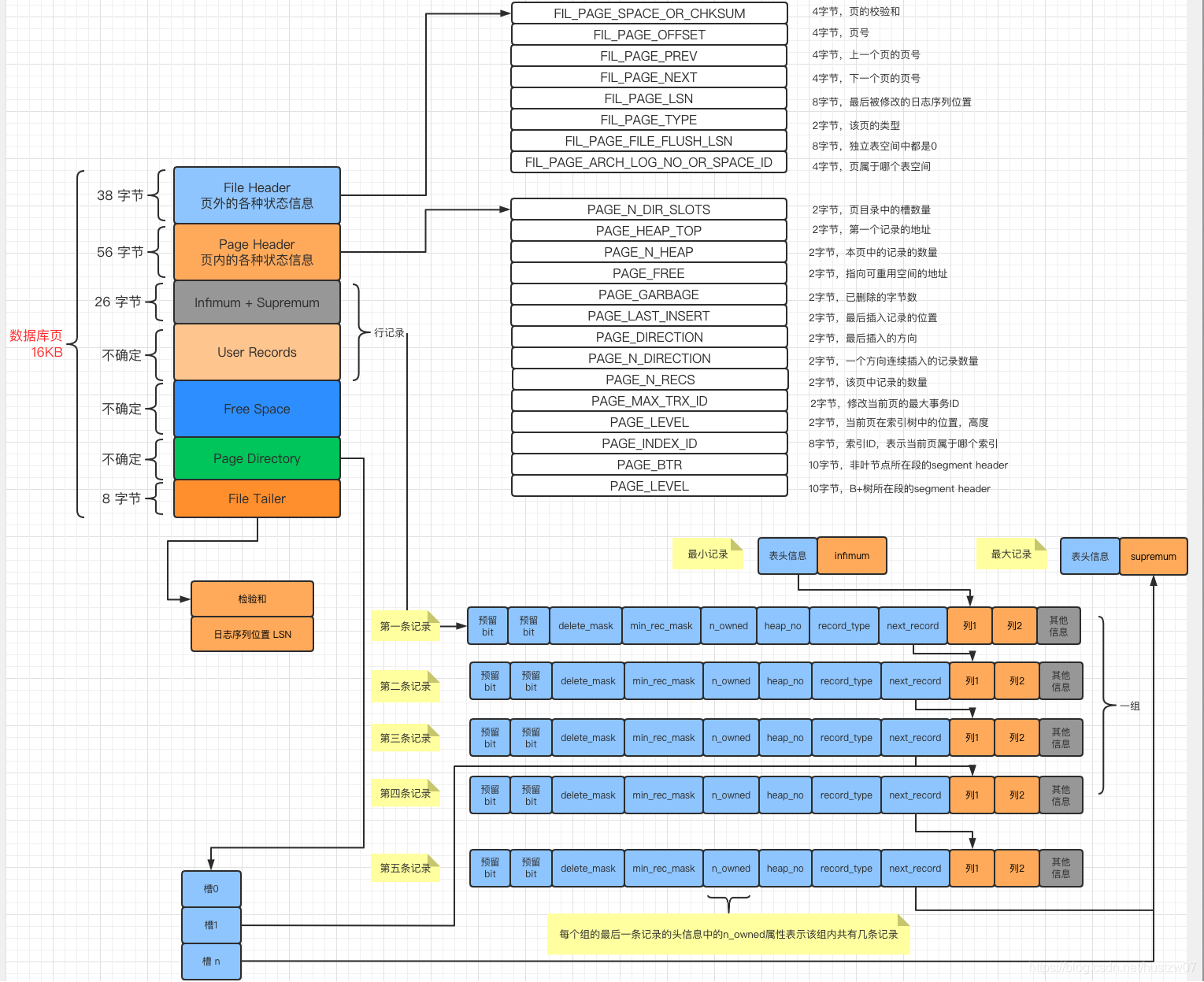
-
-
-
Mysql索引类型
根据存储方式的不同,MySQL 中常用的索引在物理上分为 B-树索引和 HASH 索引两类,两种不同类型的索引各有其不同的适用范围
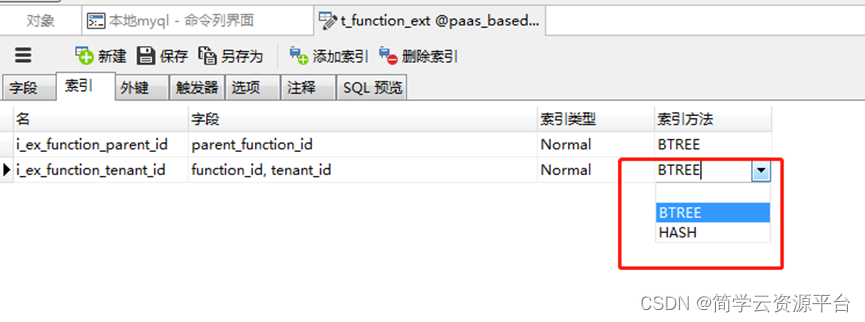
- B-树索引
B-树索引又称为 BTREE 索引,目前大部分的索引都是采用 B-树索引来存储的。
B-树索引是一个典型的数据结构,其包含的组件主要有以下几个:
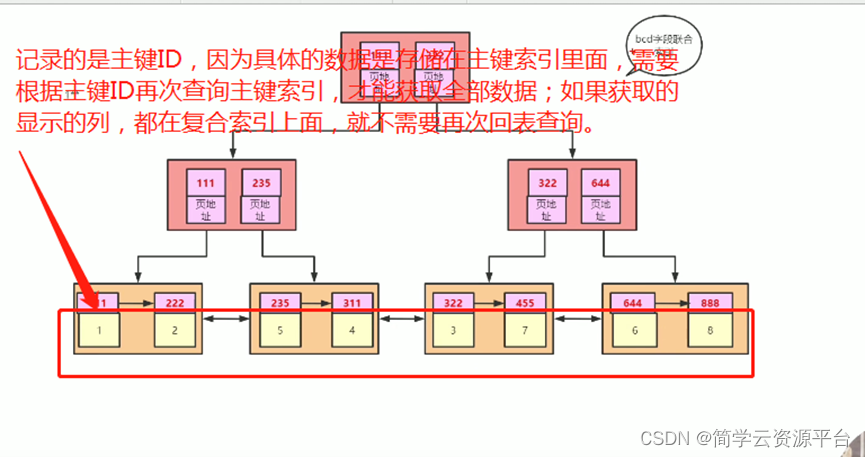
叶子节点:包含的条目直接指向表里的数据行。叶子节点之间彼此相连,一个叶子节点有一个指向下一个叶子节点的指针。
分支节点:包含的条目指向索引里其他的分支节点或者叶子节点。
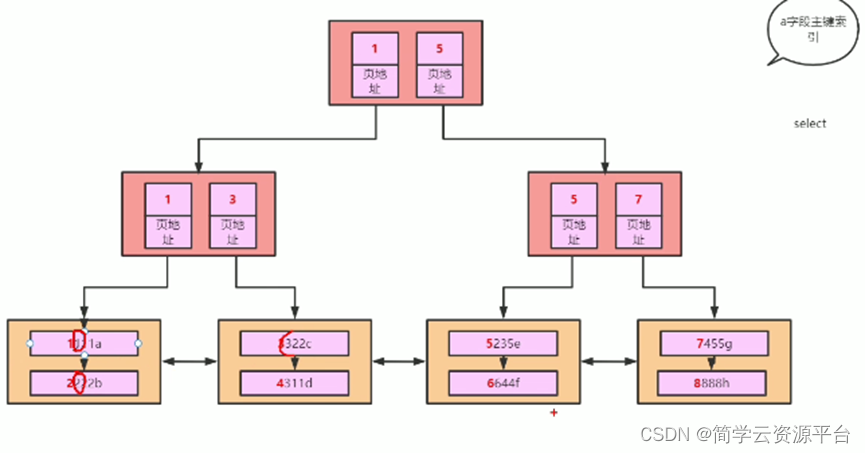
根节点:一个 B-树索引只有一个根节点,实际上就是位于树的最顶端的分支节点。
基于这种树形数据结构,表中的每一行都会在索引上有一个对应值。因此,在表中进行数据查询时,可以根据索引值一步一步定位到数据所在的行。
B-树索引可以进行全键值、键值范围和键值前缀查询,也可以对查询结果进行 ORDER BY 排序。但 B-树索引必须遵循左边前缀原则,要考虑以下几点约束:
查询必须从索引的最左边的列开始。
查询不能跳过某一索引列,必须按照从左到右的顺序进行匹配。
存储引擎不能使用索引中范围条件右边的列。
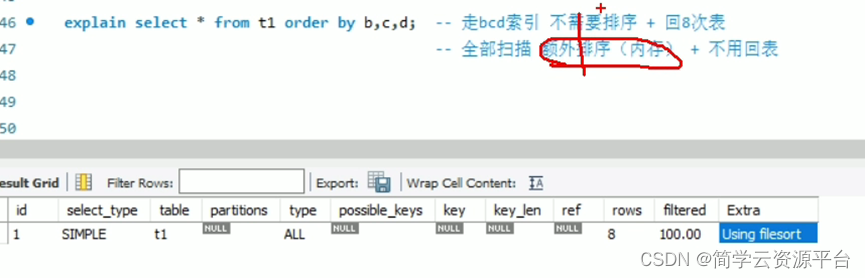
下面截图,显示的列表是*所有字段,走的是全表扫描,没走bcd索引,extra有额外的排序耗时。
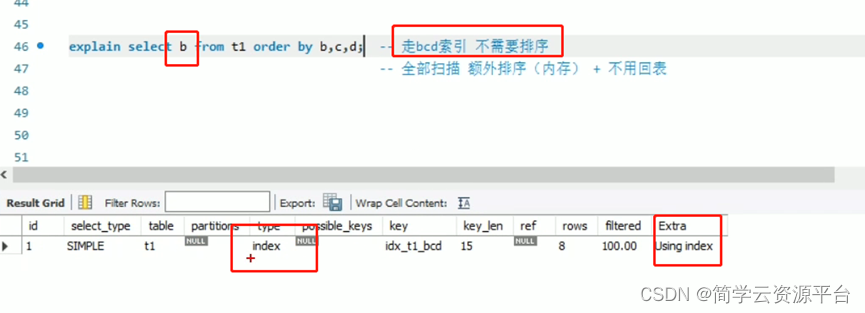
下面截图,是因为现实字段自由b了。所以走了bcd索引,extra也就没有了。
 容量瓶颈:
容量瓶颈:
从性能⽅⾯来说,由于关系型数据库⼤多采⽤ B+ 树类型的索引,
数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO 。
在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;
哈希索引
哈希(Hash)一般翻译为"散列",也有直接音译成"哈希"的,就是把任意长度的输入(又叫作预映射,pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
哈希索引也称为散列索引或 HASH 索引。MySQL 目前仅有 MEMORY 存储引擎和 HEAP 存储引擎支持这类索引。其中,MEMORY 存储引擎可以支持 B-树索引和 HASH 索引,且将 HASH 当成默认索引。
HASH 索引不是基于树形的数据结构查找数据,而是根据索引列对应的哈希值的方法获取表的记录行。哈希索引的最大特点是访问速度快,但也存在下面的一些缺点:
MySQL 需要读取表中索引列的值来参与散列计算,散列计算是一个比较耗时的操作。也就是说,相对于 B-树索引来说,建立哈希索引会耗费更多的时间。
不能使用 HASH 索引排序。
HASH 索引只支持等值比较,如"=""IN()"或"<=>"。
HASH 索引不支持键的部分匹配,因为在计算 HASH 值的时候是通过整个索引值来计算的