提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
DQL
DQL数据查询语言,用来查询数据库中表的记录。
DQL-语法
sql
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页列表基本查询
sql
-- 查询多个字段
select 字段1,字段2,字段3... from 表名;
select * from 表名;
-- 设置别名
select 字段1 [as 别名1],字段2 [as 字段2] ... from 表名;
-- 去除重复记录
select distinct 字段列表 from 表名;条件查询
sql
select 字段列表 from 表名 where 条件列表;
select * from players where players.player_id between 1 and 5;
select * from players where players.username like '__';
select * from players where players.username like '%涛';条件有: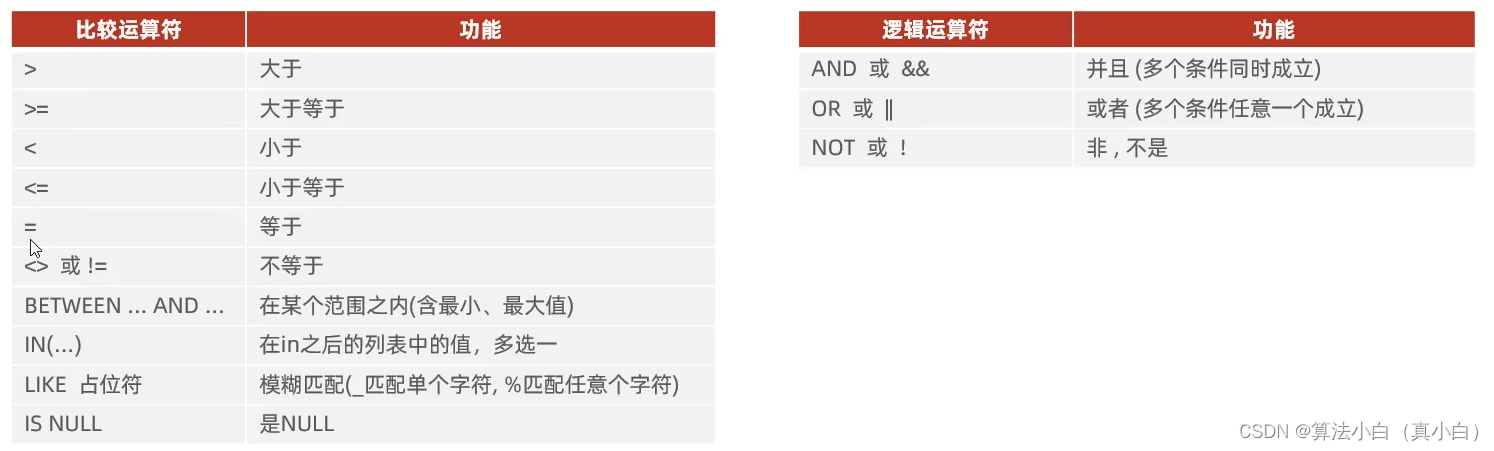
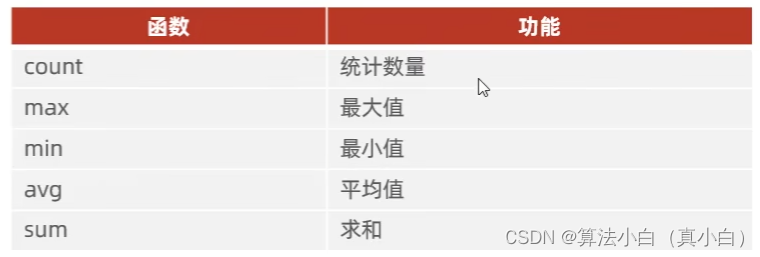
聚合函数
聚合函数:将一列数据作为一个整体,进行纵向计算。
常见的聚合函数:
sql
select 聚合函数(字段列表) from 表名;
select count(players.player_id) from players;
select avg(players.player_id) from players;
select min(players.player_id) from players;
select sum(players.player_id) from players;
/*
null值不参与所有聚合函数运算。
*/分组查询
sql
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
select heroes.hero_class ,count(hero_class) from heroes group by heroes.hero_class;
select heroes.hero_class ,count(hero_class) from heroes group by heroes.hero_class having count(*)>=4;
/*
where与having区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
*/
/*
注意:
- 执行顺序:where > 聚合函数 > having。
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
*/排序查询
sql
select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2;
select * from heroes order by base_health asc;
select * from heroes order by base_health desc;
/*
排序方式:
- asc:升序(默认值)
- desc:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
*/分页查询
sql
select 字段列表 from 表名 limit 起始索引,查询记录数;
select * from players limit 0,10;
select * from players limit 10,10;
/*
注意:
- 起始索引从0开始,起始索引 = (查询页码 - 1)*每页记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是limit。
- 如果查询的是第一页数据。起始索引可以省略,直接简写为limit 10。
*/