**前言:**本篇内容的灵感来自于封装。原因就是前几天,本人发现自己对封装的理解只是停留固定的答题模版上面, 也就是类似于------封装是将一个或者多个行为, 属性封装起来。 只对外提供接口, 使用的人通过操作接口来修改相应的属性。有利于代码的可维护, 模块化等等------这些理解缺乏我自身对封装的理解。
碰巧我之前正在研究包装器, 发现包装器的理念和封装的概念是那么的契合。 我特地在网上找了侯捷老师的STL的源码剖析电子版,看了一部分这本书的stl适配器篇------也就是第八章。 个人感觉收货不小, 这不仅仅是对封装的理解的帮助, 而且让我感觉到了泛型编程的强大, 然后又看了迭代器篇, 仿函数篇。 对于迭代器萃取与仿函数的特性惊为天人,个人认为用这本书学习c++真的很好。
本篇就是主要将过去几天学习的内容进行一下复盘以及总结------文章中基本都是对侯捷老师的STL源码剖析------第八章的部分内容的复述以及总结, 但是本人水平有限, 书中有些地方并没有看懂, 所以掺杂着个人理解, 如有错误请私信。
什么是适配器
适配器**(Adaptor)也叫做包装器, 是C++的STL六大组件之一(容器(Container)、迭代器(Iterator)、仿函数(Function)、算法(Algorithm)、适配器(Adaptor)**、分离器(Allocator))
C++的STL全名Standard Template Library, 即"标准模板库"。里面是有着高强的复用性的、类型极多的不同类型的各种组件。这些组件就像一个机器上面的一个个轴承, 弹簧等零件一样。 可以相互配接, 相互组合。但又互不影响。(这也是封装的体现所在, 封装降低了代码的耦合度------降低耦合 ;通过屏蔽掉外部代码的对内部的影响,维护了代码块里面的数据的完整度, 安全性------增加安全。 同时又能屏蔽掉内部的代码对外部的一些影响,只暴露一部分操作在外面供人们使用------改变接口;使代码模块化, 好维护, 易复用------易于复用与维护。)
在C++的STL中, 迭代器, 容器, 算法, 仿函数分别都是一类独特的组件。 其中, STL想要将容器和算法独立开来。 并且迭代器作为他们之间的胶合剂, 仿函数用来配合算法,并且具有很强配接性。 而包装器, 也就是适配器也可以用来配接仿函数。
STL源码剖析中是这样解释适配器 :一种修饰容器或仿函数或迭代器接口的东西。
(ps :个人理解这里的修饰其实就是封装。即:一种封装容器或仿函数或迭代器接口的东西。)
对于适配器来说, 主要分为三种适配器------Iterator Adaptor、Function Adaptor、Container Adaptor;下面开始对这三种适配器的使用进行举例
应用举例
Container Adaptor
容器适配器就是用来封装容器的容器。那么, 请想一下, 在stl容器里面。 哪个容器可以封装别的容器呢?
在stl容器里面,queue, stack, priority_queue都是用来封装其他容器的容器。
- queue模板:
cpptemplate<class T, class Container = deque<T>> class queue { ..................//内部成员 };
- stack的模板:
cpptemplate<class T, class Container = deque<T>> class stack { ..................//内部成员 };
- priority_queue的模板:
cpptemplate<class T, class Container = deque<T>> class priority_queue { ..................//内部成员 };
ps:这里只是举例, 只需要知道这三个容器时用来封装容器的容器, 也就是容器适配器即可。 后面将会手撕代码展现底层, 那时候就可以深入的了解为什么他们是封装容器的容器。
Iterator Adaptor
Insert Iterator
insert iterator是一个统称。 这里面其实有三个迭代器: 代表从头部插入的front_inserter_iterator<Container>、代表从尾部插入的back_inserter_iterator<Container>、代表从随机位置插入的inserter_iterator<Container>;
为了更好的使用这三个迭代器, stl又提供了三个相应的函数: front_inserter<Container>对应front_inserter_iterator<Container>、 back_inserter<Container>对应back_inserter_iterator<Container>、Inserter<Container>对应inserter_iterator<Container>;
这三个迭代器的用法如下:(注意, 这三个迭代器只能用于容器的插入操作, 其实从模板里面也能看出来, 我上面写的无论是函数还是迭代器类, 他们的模板参数都是Container。 也就是容器, 说明他们是用于给任意容器进行适配的------前提是这个容器有头插或者尾插或者插入)
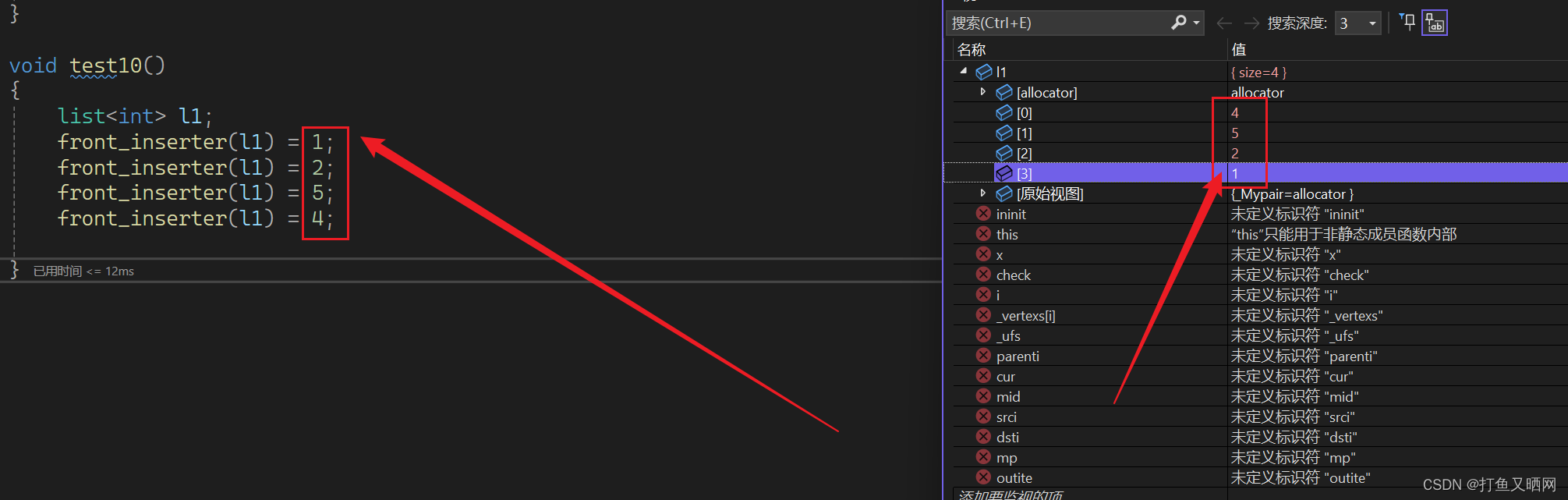
front_inserter_iterator------》front_inserter
cppint main() { list<int> l1; front_inserter(l1) = 1; front_inserter(l1) = 2; front_inserter(l1) = 5; front_inserter(l1) = 4; }
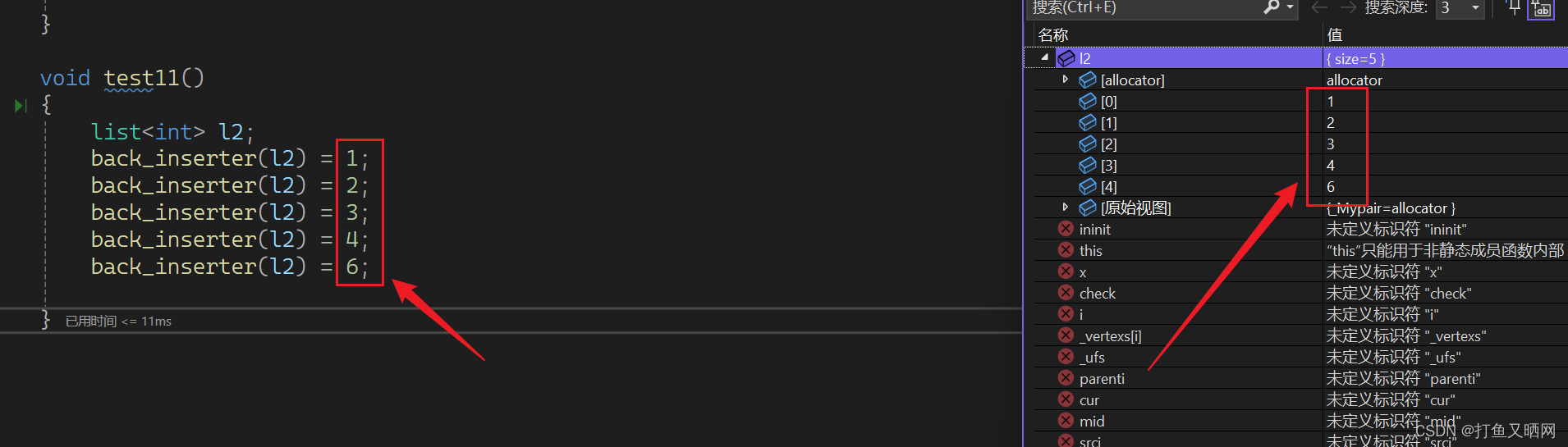
back_inserter_iterator------》back_inserter
cppint main() { list<int> l2; back_inserter(l2) = 1; back_inserter(l2) = 2; back_inserter(l2) = 3; back_inserter(l2) = 4; back_inserter(l2) = 6; }
inserter_iterator------》Inserter
cppint main() { list<int> l3; inserter(l3, l3.begin()) = 1; //inserter的参数除了容器还有迭代器。 inserter(l3, l3.begin()) = 2; inserter(l3, l3.begin()) = 3; inserter(l3, l3.begin()) = 4; inserter(l3, l3.begin()) = 5; inserter(l3, l3.begin()) = 6; }

Reverse iterator
Reverse iterator翻译过来就是反向迭代器。我们打开c++list库的文档就可以看到, list是有反向迭代器的:
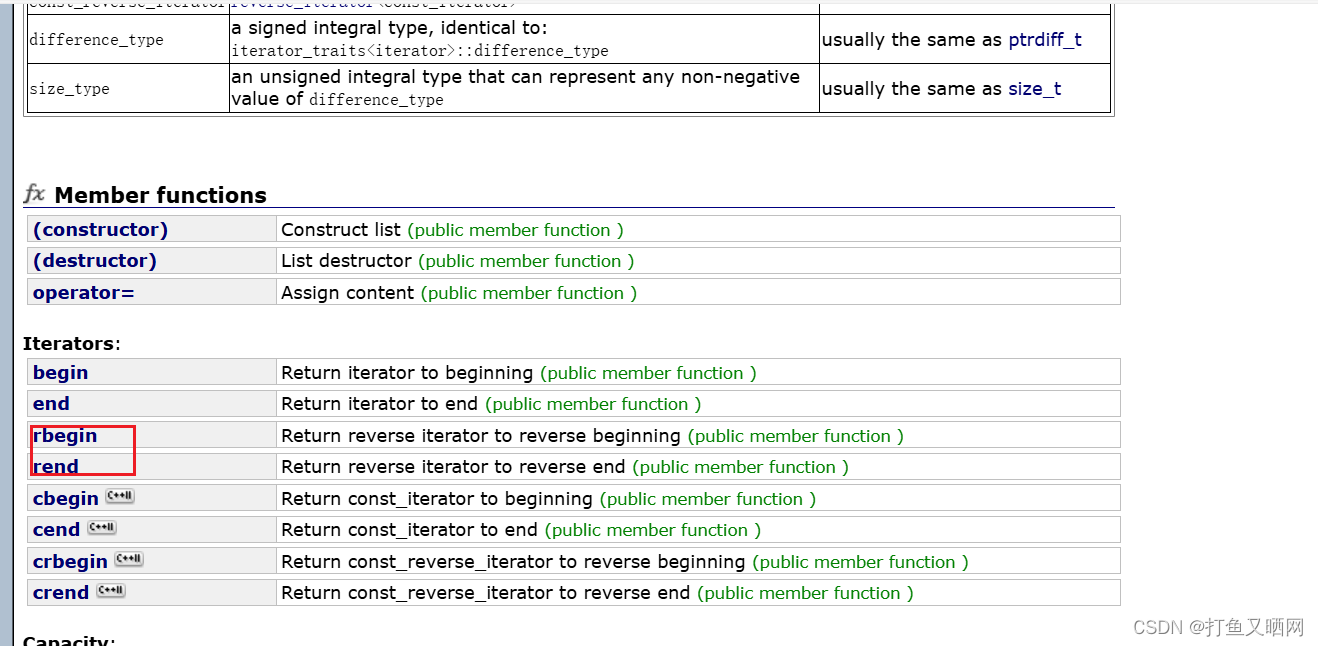
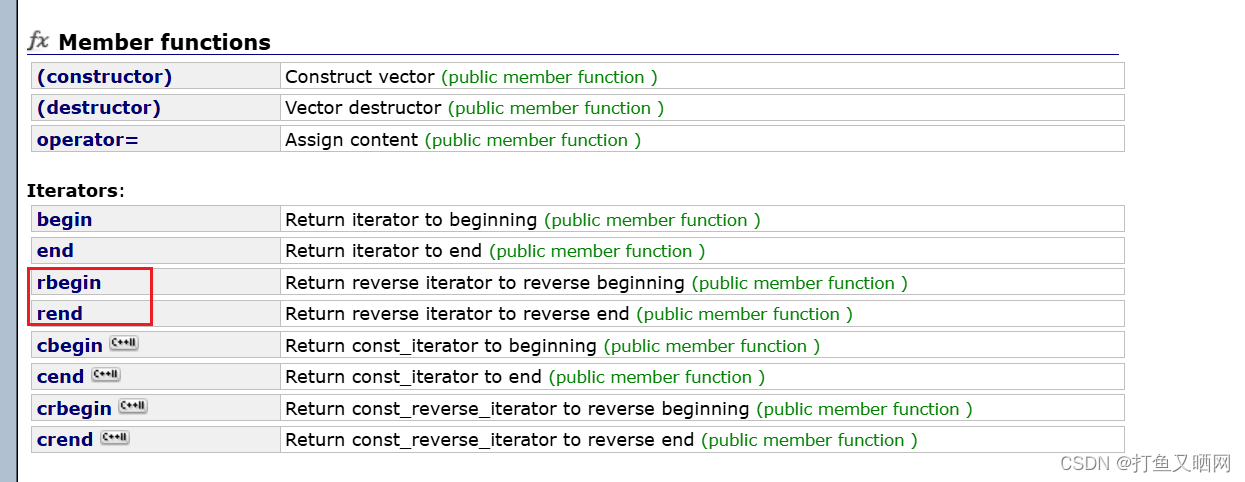
不仅list, vector, deque也都有着反向迭代器。
vector:
deque:
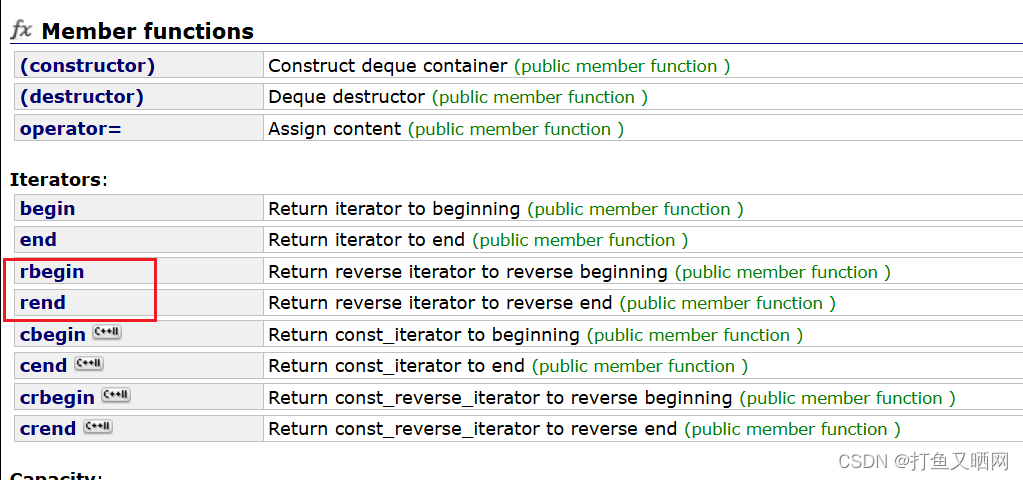
反向迭代器的加加其实就是正常容器迭代器的减减,而反向迭代器的减减其实就是正常迭代器的加加;
至于为什么会这样, 后面会手撕Reverse iterator来深入解析如何产生这种效果。
stream iterator
IOstream iterator是用来封装流的适配器。 他能够将流的对象进行封装, 然后进行统一处理。 IOstream iterator分为 : 代表流插入的osteram iterator 、 代表流提取的istream iterator。
ostream_iteartor的应用举例:
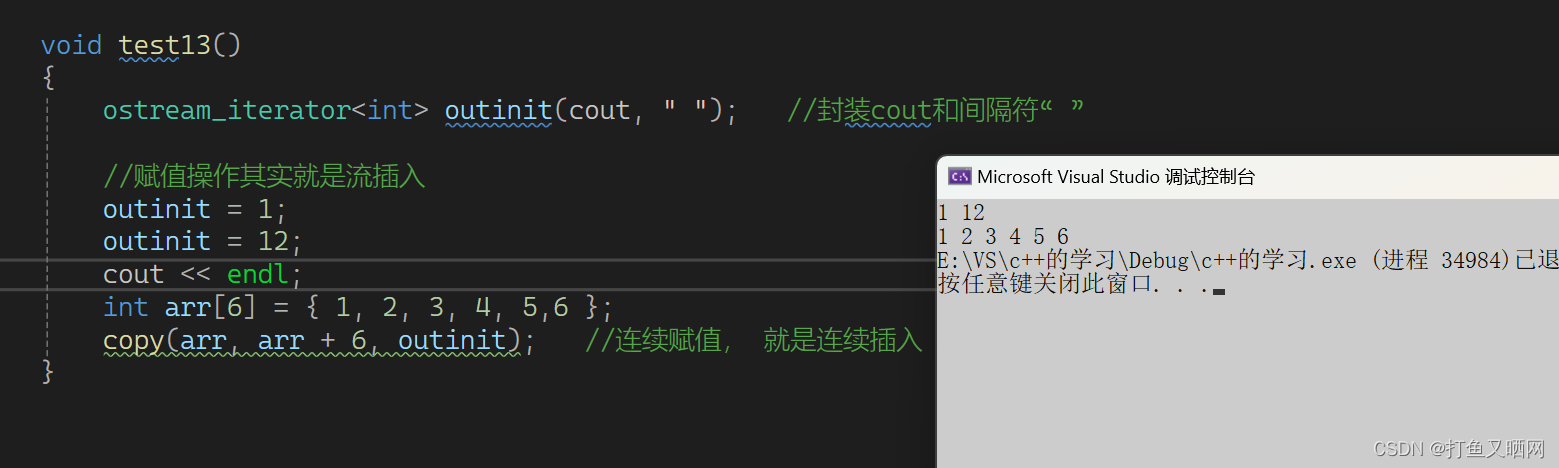
cppint main() { ostream_iterator<int> outinit(cout, " "); //封装cout和间隔符" " //赋值操作其实就是流插入 outinit = 1; outinit = 12; cout << endl; int arr[6] = { 1, 2, 3, 4, 5,6 }; copy(arr, arr + 6, outinit); //连续赋值, 就是连续插入 return 0; }
istream_iterator的应用举例:
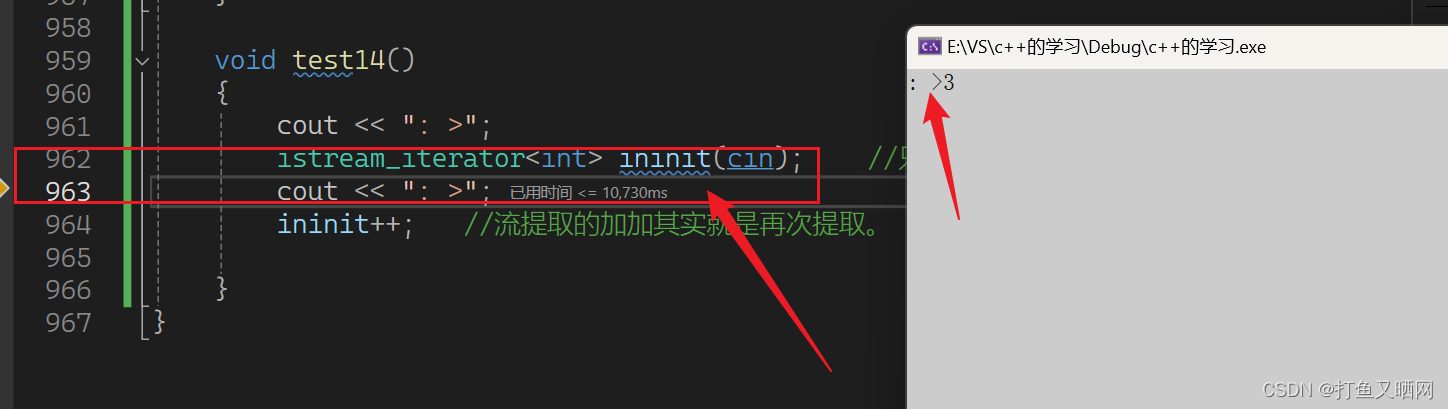
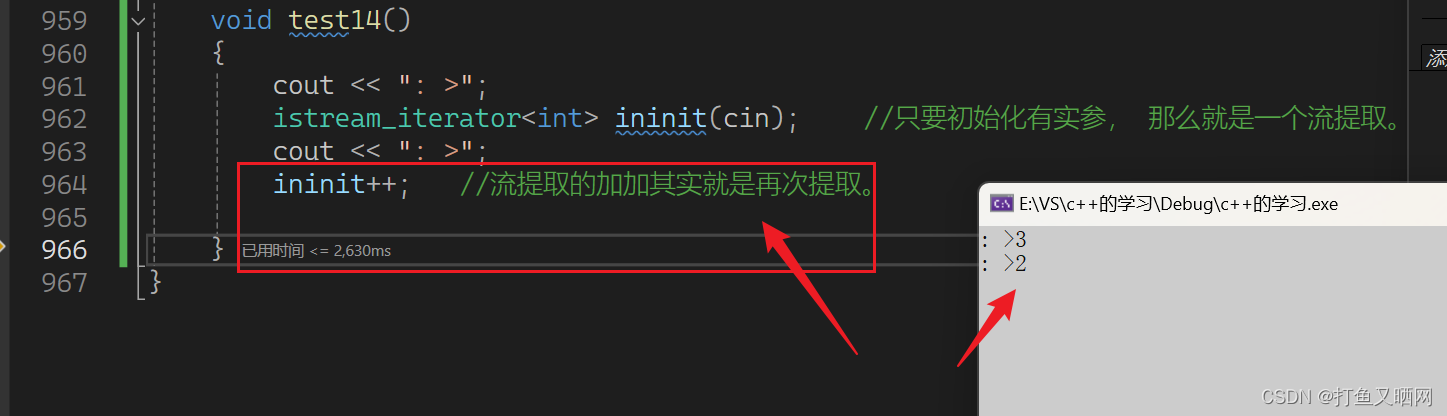
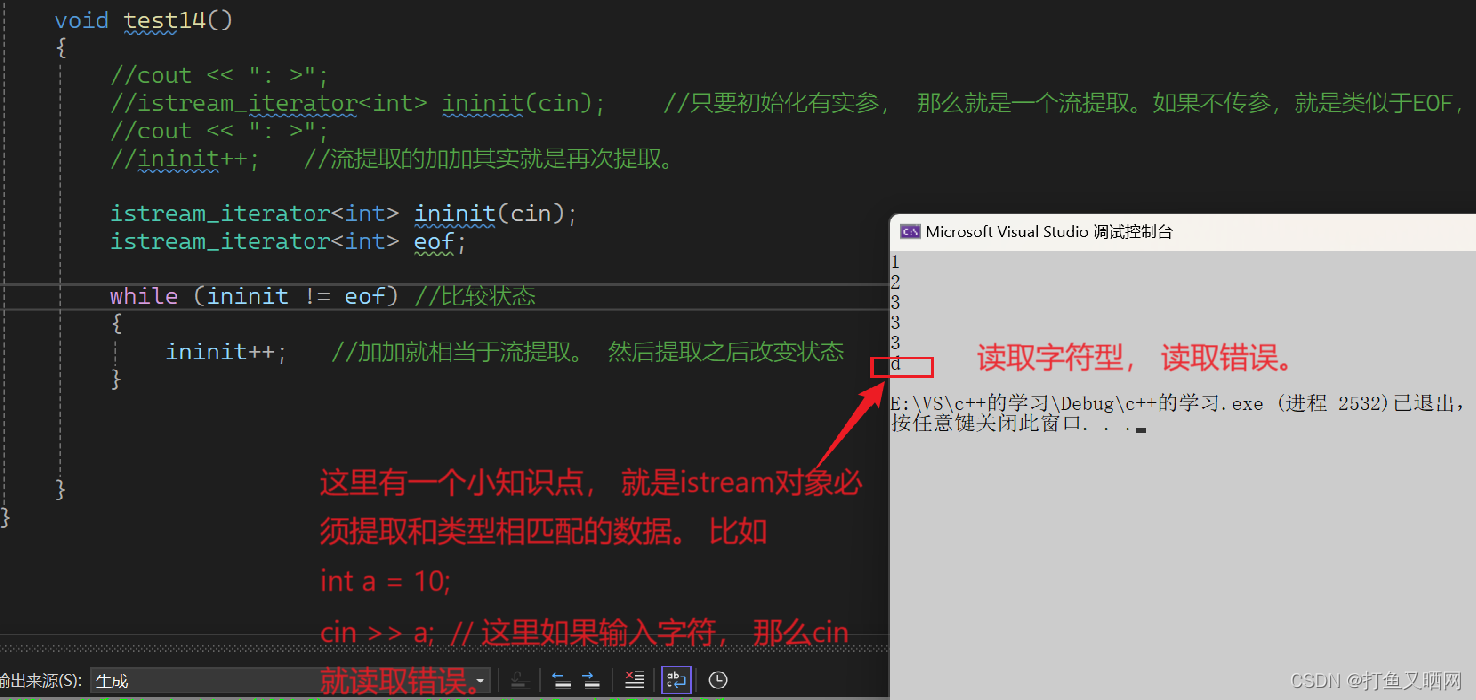
cppint main() { cout << ": >"; istream_iterator<int> ininit(cin); //只要初始化有实参, 那么就是一个流提取。如果不传参,就是类似于EOF,作为终点标记 cout << ": >"; ininit++; //流提取的加加其实就是再次提取。 return 0; }第一次提取是初始化的时候:
第二次提取是加加的时候 :
不进行传参, 类似于eof的使用:
cppint main() { istream_iterator<int> ininit(cin); istream_iterator<int> eof; while (ininit != eof) //比较状态 { ininit++; //加加就相当于流提取。 然后提取之后改变状态 } return 0; }
以上, IOstream iterator的大概用法, 后面会手撕代码来深入解析底层原理。
Function Adaptor
仿函数适配器是用来封装仿函数的一种适配器。 他们可以将一个仿函数配接成为一个带有全新功能的可调用对象。 这种仿函数适配的种类有: 用来绑定参数,操作参数的适配器bind、用来取反逻辑, 让仿函数的逻辑相反的not、用来组合仿函数的compose、 以及修饰函数指针, 修饰成员函数,来让他们以仿函数的形式进行调用的ptr系列等等。
ps:本篇内容只讲述bind, not以及修饰函数指针的仿函数适配器。
先看应用:
bind系列
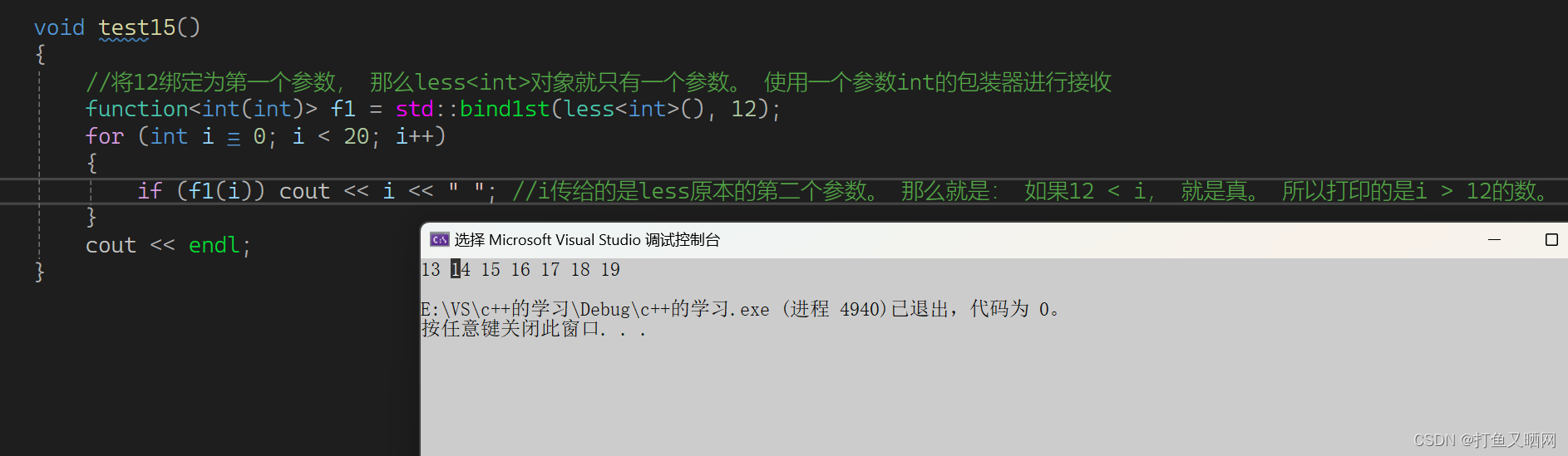
- bind1st:
cppint main() { //将12绑定为第一个参数, 那么less<int>对象就只有一个参数。 使用一个参数int的包装器进行接收 function<int(int)> f1 = std::bind1st(less<int>(), 12); for (int i = 0; i < 20; i++) { if (f1(i)) cout << i << " "; //i传给的是less原本的第二个参数。 那么就是: 如果12 < i, 就是真。 所以打印的是i > 12的数。 } cout << endl; return 0; }
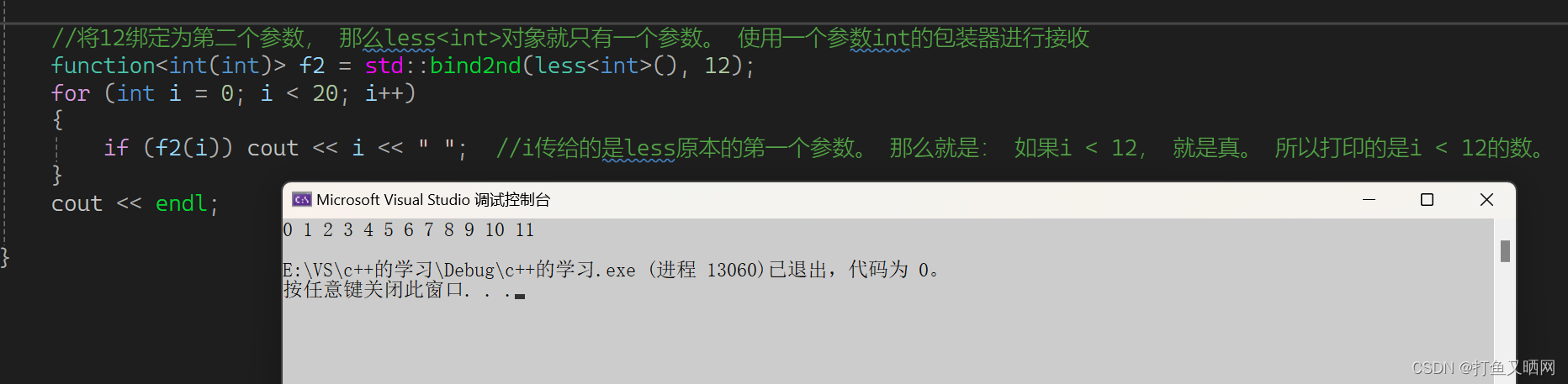
- bind2nd:
cppint main() { //将12绑定为第二个参数, 那么less<int>对象就只有一个参数。 使用一个参数int的包装器进行接收 function<int(int)> f2 = std::bind2nd(less<int>(), 12); for (int i = 0; i < 20; i++) { if (f2(i)) cout << i << " "; //i传给的是less原本的第一个参数。 那么就是: 如果i < 12, 就是真。 所以打印的是i < 12的数。 } cout << endl; return 0; }
not系列
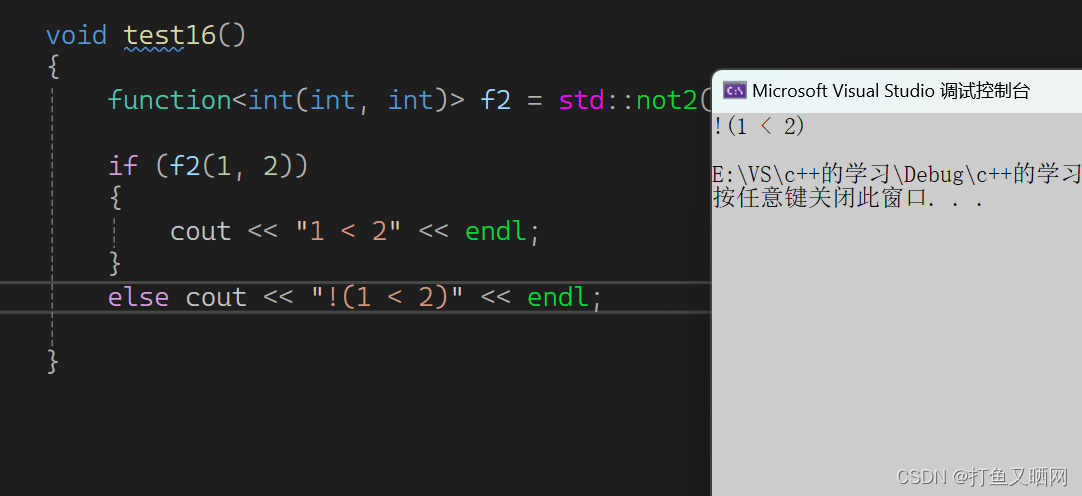
- not2(用来封装两个参数的仿函数)
cppint main() { function<int(int, int)> f2 = std::not2(less<int>()); //将两个参数的仿函数进行封装 if (f2(1, 2)) { cout << "1 < 2" << endl; } else cout << "!(1 < 2)" << endl; return 0; }
- not1(用来封装一个参数的仿函数)
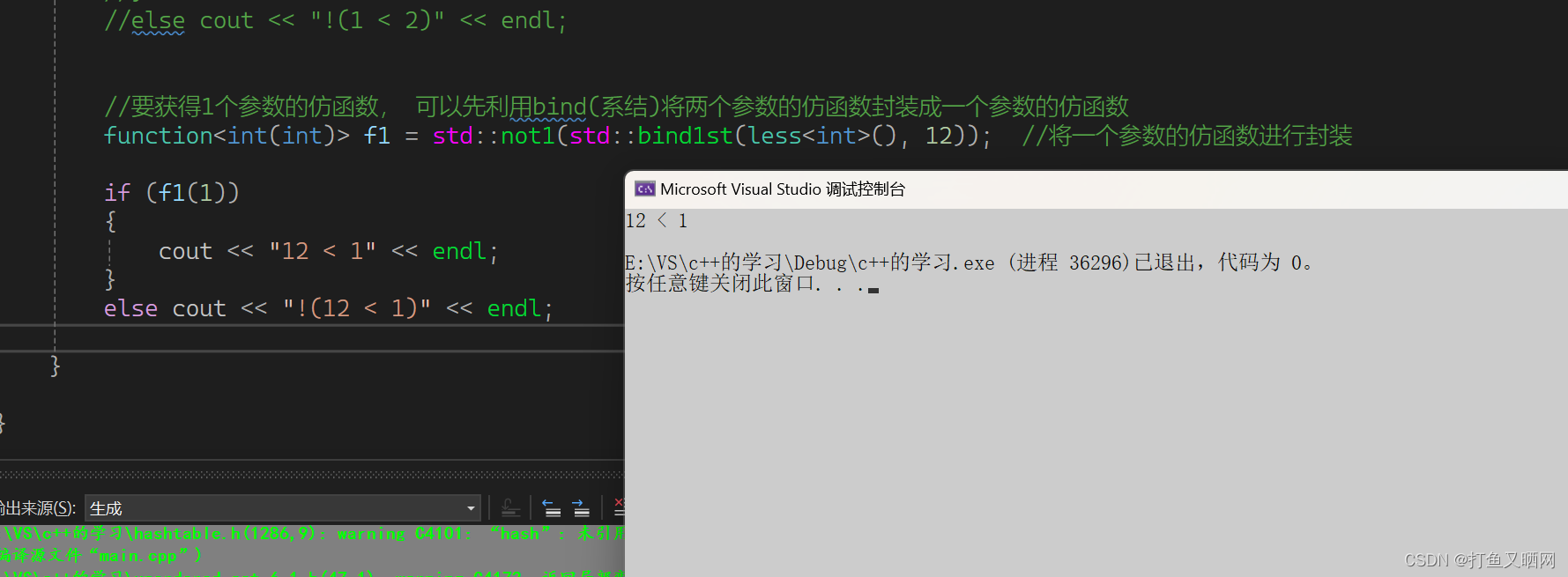
cppint main() { //要获得1个参数的仿函数, 可以先利用bind(系结)将两个参数的仿函数封装成一个参数的仿函数 function<int(int)> f1 = std::not1(std::bind1st(less<int>(), 12)); //将一个参数的仿函数进行封装 if (f1(1)) { cout << "12 < 1" << endl; } else cout << "!(12 < 1)" << endl; return 0; }
ptr系列
ptr系列这里只讲述一个用来封装函数指针的适配器:ptr_fun
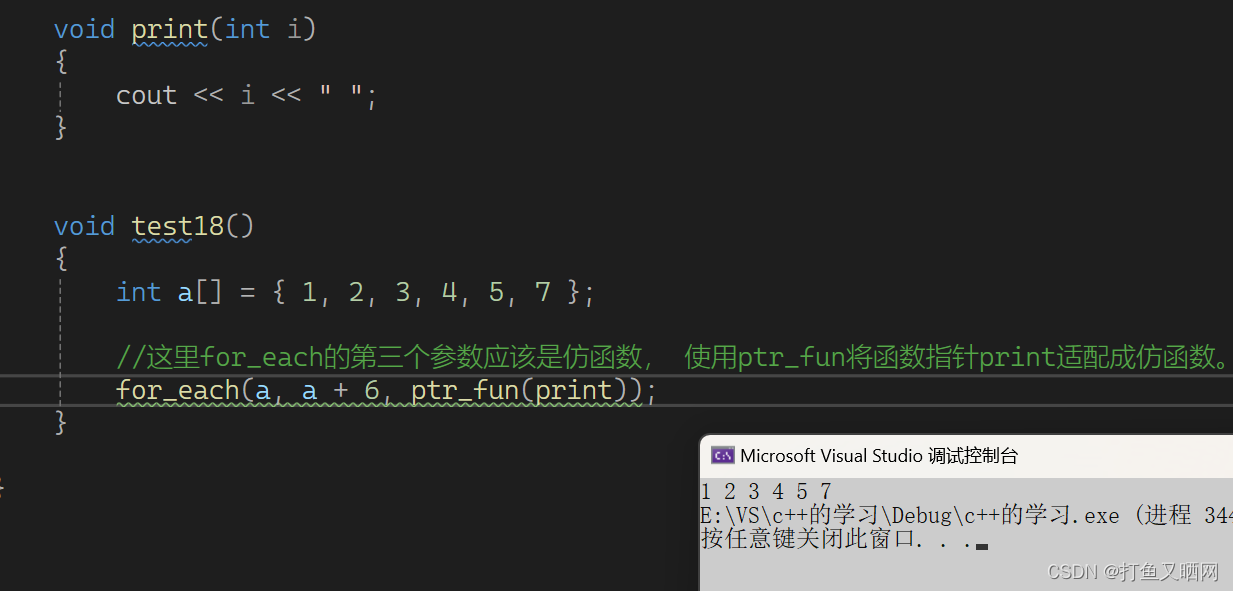
cppvoid print(int i) { cout << i << " "; } int main() { int a[] = { 1, 2, 3, 4, 5, 7 }; //这里for_each的第三个参数应该是仿函数, 使用ptr_fun将函数指针print适配成仿函数。 for_each(a, a + 6, ptr_fun(print)); return 0; }
以上, 即Function Adaptor常见适配器的用法。接下来手撕代码, 探究底层原理.
Container Adaptor
容器适配器有queue, stack, priority_queue. 这里首先看queue
queue
queue的模板参数:
cpp
template<class Container> //要包装的容器类型。
class queue queue的保存的数据类型如何解决?
第一种解决方法是在queue的模板参数中再加一个参数类型, 也就是:
cpp
template<class T, class Container>//第一个模板参数是存储的数据类型, 第二个模板参数是封装的容器类型
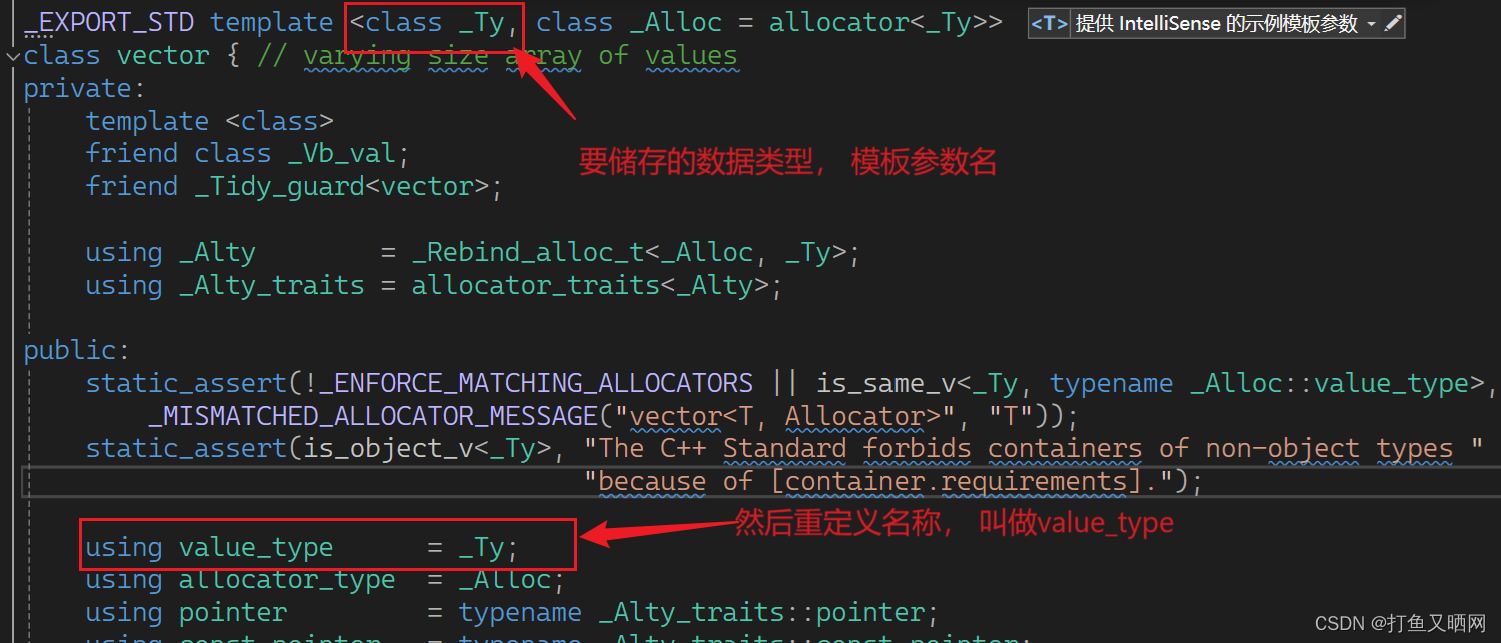
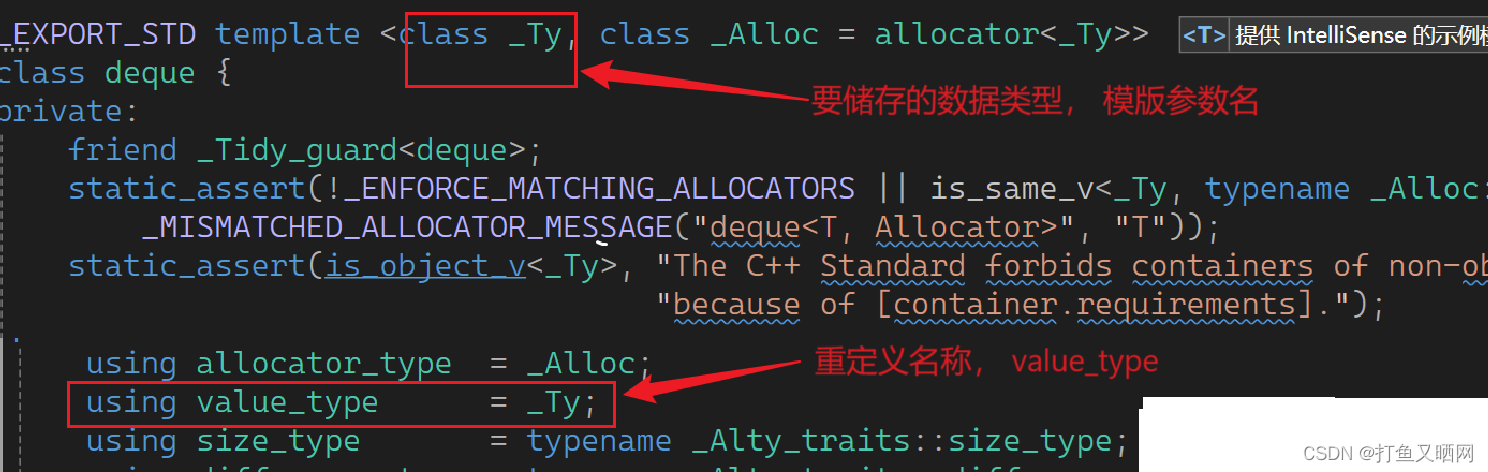
class queue 第二种方法就是就是萃取(traits):直接使用typename在指定类型后再进行识别要储存到类型。 但是typename需要知道我们要封装的容器Container里面要储存的数据类型------这里就用到了STL的强大的复用性。 在STL中, 每一个容器要储存的类型名称都叫做value_type。下面尾vs中的标准库:
vector:
deque:
list:
其他的容器就不看了, 但是基本上存储的数据类型都会被重定义为value_type。
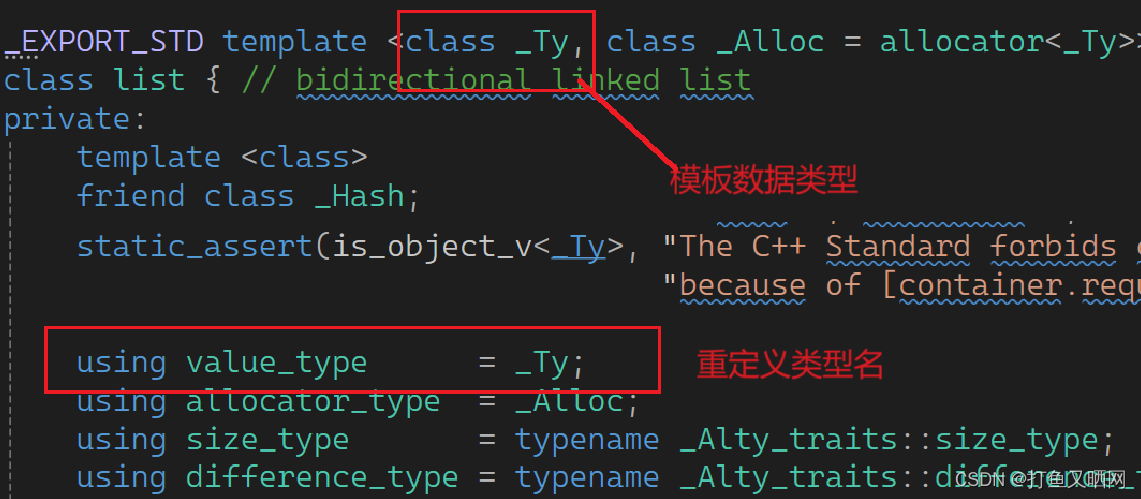
所以,第二种方式如下:
cpp
template<class Container>
class queue
{
typedef typename Container::value_type value_type;
//............其他成员函数
}
知道了这些, 我们就可以着手完善我们的queue库了。
因为我们是要对Container容器进行封装。 所以要创建Container对象。 那么就是:
cpp
//容器适配器queue, 模板参数为Container, 意思是传一个容器的类型过来
template<class Container>
class queue
{
typedef typename Container::value_type value_type;
public:
private:
Container _con; //根据容器的类型创建一个对象
};那么要将Container封装成queue, 就要保留Container的尾差:push_bac()、头删:pop_front()、取对头元素:front()、取队尾元素:back()以及empty, size, capacity这些接口。 但是要封住它的迭代器等接口(对于非默认成员函数不定义即可, 但是对于默认成员函数如果要封住就要加delete。 对于这个queue类来说, 没必要封住默认成员函数)
其他接口的定义实现:
cpp
//容器适配器queue, 模板参数为Container, 意思是传一个容器的类型过来
template<class Container>
class queue
{
typedef typename Container::value_type value_type;
public:
//conductor
queue() {}
queue(const queue<Container>& q)
:_con(q._con)
{}
~queue() {}
//modify
void push(const value_type& x)
{
//queue的push在尾部入队列。
_con.push_back(x);
}
void pop()
{
//queue的pop去掉头部的元素, 就是调用容器的头删。
_con.pop_front();
}
value_type& front()
{
return _con.front();
}
value_type& back()
{
return _con.back();
}
//capacity
bool empty()
{
return _con.empty();
}
size_t size()
{
_con.size();
}
size_t capacity()
{
return _con.capacity();
}
private:
Container _con; //根据容器的类型创建一个对象
};stack
stack的实现思想基本和queue的一样。都是一个模版参数Container, 然后利用这个模版参数实例化出对象。 同时使用一下Container里面的vatue_type。如下代码:
cpp
template<class Container>
class stack
{
typedef typename Container::value_type _Ty;
public:
private:
Container _con;
};然后要提供压栈:push()就是调用Container的push_back()。 出栈就是Container的pop_back()。以及栈顶就是back()、empty、size、capacity等等。
如下代码实现:
cpp
template<class Container>
class stack
{
typedef typename Container::value_type _Ty;
public:
//conductor
stack() {};
stack(const stack<Container>& st)
:_con(st._con)
{}
~stack() {}
//modify
void push(const _Ty& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
_Ty top()
{
return _con.back();
}
//capacity
bool empty()
{
return _con.empty();
}
size_t size()
{
return _con.size();
}
size_t capacity()
{
return _con.capacity();
}
private:
Container _con;
};priority_queue
优先级队列和上面两个的参数略有不同。 因为优先级队列的类型不是单一的。 有大根堆还有小根堆之分。 而要分开大根还是小根, 使用的是一个模版参数Compare, 这个Compare是个仿函数模版,利用仿函数控制向上调整算法(这里博主默认友友们熟悉向上调整算法)比较逻辑。 就可以控制大根堆还是小根堆。 那么如何控制的?请看代码:
cpp
template<class T, class Container, class Compare = less<T>>
class priority_queue
{
public:
protected:
//向上调整算法
void adjust_up()
{
Compare com; //Compare 创建一个可调用对象。
int child = _con.size() - 1;
int parent = (child - 1) / 2;
//
while (child > 0)
{
//小堆是大于, 孩子小上去
if (com(_con[parent], _con[child])) //利用可调用对象来实行判断逻辑。
{
swap(_con[parent], _con[child]);
child = parent;
parent = (parent - 1) / 2;
}
else break;
}
}
private:
Container _con;
};向下调整算法用的是同样的方法, 都是利用仿函数模板的实例对象实行判断逻辑。
cpp
void adjust_down(int i)
{
Compare com;
int parent = i;
int child = parent * 2 + 1;
int n = _con.size();
while (child < n)
{
//大堆是小于, 孩子大上去
if (child + 1 < n && com(_con[child], _con[child + 1])) ++child;
if (_con[parent], _con[child])
{
swap(_con[parent], _con[child]);
parent = child;
child = child * 2 + 1;
}
else break;
}
}知道了这些, 就可以着实现代码:
cpp
template<class T, class Container, class Compare = less<T>>
class priority_queue
{
public:
//conductor
priority_queue() {}
priority_queue(const priority_queue<T, Container, Compare>& pq)
:_con(pq._con)
{}
~priority_queue() {}
//modify
void push(const T& x)
{
//标准的堆插入操作, 先尾差, 再向上调整
_con.push_back(x);
adjust_up();
}
void pop()
{
//标准的堆
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
T& top()
{
return _con[0];
}
//capacity
bool empty()
{
_con.empty();
}
size_t size()
{
return _con.size();
}
size_t capacity()
{
return _con.capacity();
}
protected:
//向上调整算法
void adjust_up()
{
Compare com;
int child = _con.size() - 1;
int parent = (child - 1) / 2;
//
while (child > 0)
{
//小堆是大于, 孩子小上去
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (parent - 1) / 2;
}
else break;
}
}
//向下调整算法, 从基准点开始, 所以要有一个基准点
void adjust_down(int i)
{
Compare com;
int parent = i;
int child = parent * 2 + 1;
int n = _con.size();
while (child < n)
{
//小于是大堆, 孩子大上去
if (child + 1 < n && com(_con[child], _con[child + 1])) ++child;
if (_con[parent], _con[child])
{
swap(_con[parent], _con[child]);
parent = child;
child = child * 2 + 1;
}
else break;
}
}
private:
Container _con;
};Iterator Adaptor
ps:在本节内容中, 所实现的迭代器适配器之中都有五个特性: iterator_category、 value_type、difference_type、pointer、reference;这五个类型是为了让我们写的迭代器操作能够胶合算法和容器, 并且融于STL之中, 并不是本节适配器的重点内容。 如果有兴趣, 请看侯捷老师的STL源码剖析-p85-Traits编程技法。
inserter Iterator
front_inserter_iterator
想要使用front_Inserter需要容器含有push_front接口, 而vector没有这个接口。 那么vector就无法使用front_inserter。
cpp
template<class Container>
class front_inserter_iterator
{
//迭代器的五个特性。 分别是:迭代的分类、迭代器的类型、迭代器之间的距离, 也是容器的最大容量、迭代器指向的对象、迭代器引用的对象;五个特性为迭代器相关内容,主要功能是为了胶合算法与容器。
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
public:
//conductor传一个容器对象
front_inserter_iterator(Container& con)
:_con(&con)
{}
//赋值操作就是Container容器的头插操作。
front_inserter_iterator<Container> operator=(typename Container::value_type x)
{
_con->push_front(x);
return *this;
}
//解引用和前置++, 后置++都是它本身。
front_inserter_iterator<Container> operator*() { return *this; }
front_inserter_iterator<Container> operator++() { return *this; };
front_inserter_iterator<Container> operator++(int) { return *this; }
private:
Container* _con;
};
//为了方便使用front_inserter_iterator而设计的函数模板。 只需要传容器过去即可
template<class Container>
front_inserter_iterator<Container> front_inserter(typename Container& x)
{
return front_inserter_iterator<Container>(x); //构造一个front_inserter_iterator进行头插
}back_inserter_iterator
cpp
template<class Container>
class back_inserter_iterator
{
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void defference_type;
typedef void reference;
typedef void pointer;
public:
//conductor
back_inserter_iterator(Container& con)
:_con(&con)
{}
//返回值,赋值的操作其实就是尾插。和front_inserter_iterator是一样的
back_inserter_iterator<Container>& operator=(typename Container::value_type x)
{
_con->push_back(x);
return *this;
}
//解引用和前置++以及后置++都是返回它本身
back_inserter_iterator<Container>& operator*() { return *this; }
back_inserter_iterator<Container>& operator++() { return *this; }
back_inserter_iterator<Container>& operator++(int) { return *this; }
private:
Container* _con;
};
//辅助函数, 方便使用
template<class Container>
back_inserter_iterator<Container>& back_inserter(Container& x)
{
return back_inserter_iterator<Container>(x);
}inserter_iterator
随机位置插入和上面两个迭代器有所不同, 随机位置需要用到容器的迭代器。 这也就意味着queue, stack这些没有迭代器的直接无法使用inserter。
cpp
template<class Container>
class inserter_iterator
{
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
public:
//inserter的构建需要传两个参数, 一个容器, 一个容器的迭代器。 当进行插入时, 就在迭代器指向位置进行插入。
inserter_iterator(Container& con, typename Container::iterator iter)
:_con(&con)
,_iter(iter)
{}
inserter_iterator<Container> operator=(typename Container::value_type x)
{
_con->insert(_iter, x);
++_iter;
return *this;
}
inserter_iterator<Container> operator*() { return *this; }
inserter_iterator<Container> operator++() { return *this; }
inserter_iterator<Container> operator++(int) { return *this; }
private:
Container* _con;
typename Container::iterator _iter;
};
template<class Container>
inserter_iterator<Container> inserter(Container& con, typename Container::iterator iter)
{
return inserter_iterator<Container>(con);
}Reverse_iterator
这个适配器应该是除了Container Adaptor,友友们最熟悉的一种适配器。 而且友友们如果熟悉list的底层封装, 其实就应该使用过Reverse_iterator封装过list的迭代器。 同样的,和其他适配器一样。 Reverse_iterator的封装屏蔽了list迭代器的底层细节, 并修改相应的接口。同时还使用了萃取获得需要使用的迭代器特性。
那么为什么会有Reverse_iterator?
我们可以看一下vs中那些双向序列容器的底层源码
- vector:
- list:
- deque:


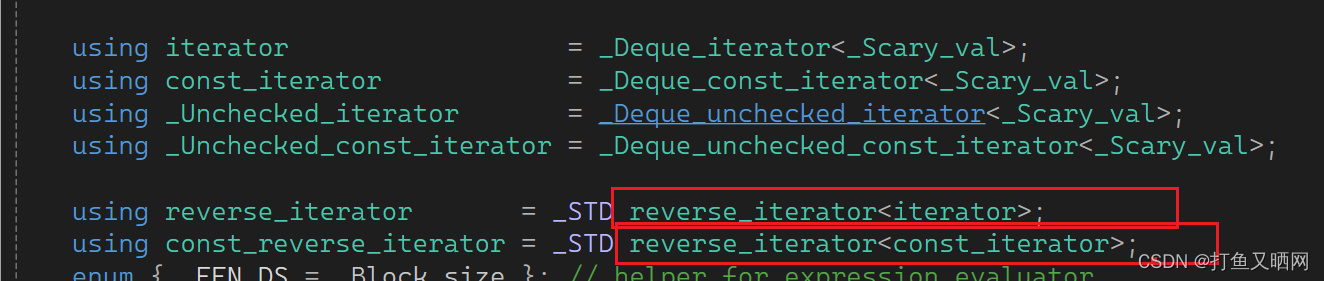
其他双向数列容器这里不进行举例, 但是只要你找对应的源码就会发现, 所有双向序列容器的reverse_iterator都是通过reverse_iterator封装来的。 (关于反向迭代器的加加和减减操作, 这里并没有讲解, 个人认为这里最重要的是理解这个萃取的概念。)
以下为底层源码实现:
cpp
template<class Container>
inserter_iterator<Container> inserter(Container& con, typename Container::iterator iter)
{
return inserter_iterator<Container>(con);
}
template<class Iterator>
class reverse_Iterator
{
public:
//先进行萃取:
typedef typename Iterator::iterator_catecory iterator_catecory;
typedef typename Iterator::value_type value_type;
typedef typename Iterator::difference_type difference_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
reverse_Iterator(Iterator it)
:_cur(it)
{}
//拷贝构造
reverse_Iterator(const reverse_Iterator<Iterator>& it)
:_cur(it._cur)
{}
reverse_Iterator& operator++()
{
--_cur;
return *this;
}
reverse_Iterator operator++(int)
{
Iterator tmp = _cur;
--_cur;
return tmp;
}
reverse_Iterator& operator--()
{
++_cur;
return *this;
}
reverse_Iterator operator--(int)
{
Iterator tmp = _cur;
++_cur;
return tmp;
}
//*
reference operator*()
{
Iterator tmp = _cur;
--tmp;
return *tmp;
}
pointer operator->()
{
Iterator tmp = _cur;
--tmp;
return &(*tmp);
}
bool operator!=(const Iterator& it)
{
return _cur != it._cur;
}
bool operator==(const Iterator& it)
{
return _cur == it._cur;
}
Iterator _cur;
};stream iterator
stram_iterator可以将一个迭代器对象绑定到一个数据流身上。 如果是绑定到istream身上, 那么就是istream_iterator。 如果是绑定到ostream身上, 那么就是ostream_iterator。这个时候它们分别有输入(读)或者输出(写)的能力。
这个的本质其实就是利用stream_iterator适配器将流对象封装起来。 然后对外修改一下接口------将原本的>> 或者 << 封装成赋值操作。并且每次加加都会赋值。 也就是连续插入或者提取。
istream_iterator
需要注意的是, 我们在定义istream_iterator对象的时候就会进行一次读取数据。所以, 使用该适配器需要在特定的地方进行使用。
cpp
template<class T, class Distance = ptrdiff_t>
class istream_iterator
{
template<class T>
friend bool operator!=(istream_iterator& x1, istream_iterator& x2);
public:
//先定义迭代器特性
typedef input_iterator_tag iterator_category;
typedef T value_type;
typedef T* pointer;
typedef T& reference;
typedef Distance difference_type;
//无参构造函数, 构造出来的istream对象是一个判断是否读取错误的EOF
istream_iterator()
:_stream(&cin)
, end_marker(false)
{}
//istream对象
istream_iterator(istream stream)
:_stream(&stream)
{
read();
}
//对该对象解引用就是获得上一个提取的数据
reference operator*() { return value; }
pointer operator->() { return &(operator*()); }
//迭代器前进的时候, 就要读取数据
istream_iterator<T, Distance> operator++()
{
read();
return *this;
}
istream_iterator<T, Distance> operator++(int)
{
auto tmp = *this;
read();
return tmp;
}
private:
istream* _stream;
T value;
bool end_marker; //用来标记是否到了读取错误。一般会定义一个错误对象来进行比较
void read()
{
if (end_marker) *_stream >> value;
if (*_stream) end_marker = true;
else end_marker = false;
}
};ostream_iterator
ostram_iterator不同于istream, 它的内部实现不需要保存数据。只需要将一个赋值接口将用户传来的数据打印即可。
cpp
template<class T>
class ostream_iterator
{
public:
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void reference;
typedef void pointer;
ostream_iterator(ostream out)
:_stream(&out)
,_str(nullptr)
{}
ostream_iterator(ostream out, const char* str)
:_stream(&out)
, _str(str)
{}
//对迭代器进行赋值操作, 就是将要进行输出的数据进行打印
ostream_iterator<T> operator=(const T& x)
{
*_stream << x;
if (_str) *_stream << _str;
return *this;
}
//前置加加, 解引用, 后置加加都是自己本身
ostream_iterator<T> operator*() { return *this; }
ostream_iterator<T> operator++() { return *this; }
ostream_iterator<T> operator++(int) { return *this; }
private:
ostream* _stream;
const char* _str;
};Function Adaptor
在进行学习仿函数适配器之前需要知道------仿函数可配接性------这个性质的根本目的是为了更加灵活的组合成各种各样功能的函数, 从而更灵活的配合算法实现各种功能。 而为了保证仿函数的可配接性, STL提供了两个关键------unary_function(一元函数)、binary_function(二元函数)【STL不支持三元函数】, 他们也是仿函数的特性------就如同迭代器为了胶合容器与算法, 更好融入STL之中, 仿函数的特性也是为了更好的配合算法, 更好的融入STL之中。
unary_function和binary_function都是类。他们被仿函数继承从而让仿函数获得相应特性。 并且他们的定义如下:
cpptemplate<class Arg, class Result> class unary_function { typedef Arg argument_type; typedef Result result_type; }; template<class Arg1, class Arg2, class Result> class binary_function { typedef Arg1 first_argument_type; typedef Arg2 second_argument_type; typedef Result result_type; };
bind(系结)
bind1st
cpp
template<class Operation>
class binder1st : public unary_function<typename Operation::second_argument_type,
typename Operation::result_type>
{
public:
//conductor, 将第一个参数进行绑定。
binder1st(const Operation& op, const typename Operation::first_argument_type& y)
:_op(op)
,_value(y)
{}
//这里是调用仿函数, 系结好的仿函数第一个参数已经被绑定。 只接收外部传来的第二个参数
typename Operation::result_type operator()(const typename Operation::second_argument_type& x)
{
return _op(_value, x); //实际上用的就是构造的时候的第一个参数,圆括号时候的第二个参数。
}
private:
Operation _op;
typename Operation::second_argument_type _value;
};
//辅助函数, 方便使用。 传要封装的仿函数, 以及第一个参数。
template<class Operation, class T>
inline binder1st<Operation> bind1st(Operation& op, const T& x)
{
return binder1st<Operation>(op, typename Operation::first_argument_type(x));
}bind2st
cpp
template<class Operation, class T>
inline binder1st<Operation> bind1st(Operation& op, const T& x)
{
return binder1st<Operation>(op, typename Operation::first_argument_type(x));
}
template<class Operation>
class binder2nd : public unary_function<typename Operation::first_argument_type,
typename Operation::result_type>
{
public:
//conductor, 将第二个参数进行绑定。
binder2nd(const Operation& op, const typename Operation::second_argument_type& x)
:_op(op)
,_value(x)
{}
typename Operation::result_type operator()(const typename Operation::first_argument_type& x)
{
return _op(x, _value);
}
private:
Operation _op;
typename Operation::first_argument_type _value;
};
template<class Operation, class T>
inline binder2nd<Operation> bind2nd(Operation& op, const T& x)
{
return binder2nd<Operation>(op, typename Operation::first_argument_type(x));
}not(否定)
not用来表示一个仿函数Adaptable Predicate(可返回真假且可配接表达式)的逻辑负值。 以下是两个否定适配器的代码实现:
not1
cpp
template<class Predicate>
class unary_negate : public unary_function<typename Predicate::argument_type,
typename Predicate::result_type>
{
public:
//利用会返回真假表达式进行适配。
unary_negate(const Predicate& x)
:_pred(x)
{}
//就是对原本的表达式进行一下取反操作
bool operator()(const typename Predicate::argument_type& x) const
{
return !_pred(x);
}
private:
Predicate _pred;
};
//辅助函数, 方便使用:
template<class Predicate>
inline unary_negate<Predicate> not1(const Predicate& pred)
{
return unary_negate<Predicate>(pred);
}not2
cpp
template<class Predicate>
inline unary_negate<Predicate> not1(const Predicate& pred)
{
return unary_negate<Predicate>(pred);
}
template<class Predicate>
class binary_negate : public binary_function<typename Predicate::first_argument_type,
typename Predicate::second_argument_type, typename Predicate::result_type>
{
public:
binary_negate(const Predicate& x)
:_pred(x)
{}
//
bool operator()(const typename Predicate::first_argument_type x, typename Predicate::second_argument_type y) const
{
return !_pred(x, y);
}
private:
Predicate _pred;
};
template<class Predicate>
inline binary_negate<Predicate> not2(const Predicate& pred)
{
return binary_negate<Predicate>(pred);
}修饰
ptr_fun
ptr_fun是将函数修饰为仿函数的适配器。 ptr_fun需要定义两份, 一份用来适配一元函数,一份用来适配二元函数。
一元函数:
一元函数适配器其实就是把一个一元函数包起来, 然后()运算符就是调用这个一元函数
cpp
template<class Arg, class Result>
class pointer_to_unary_function : public unary_function<Arg, Result>
{
typedef Result(*F_P) (Arg);
public:
pointer_to_unary_function() {}
//带参构造用来接收函数指针。
pointer_to_unary_function(F_P ptr)
:_ptr(ptr)
{}
//通过()调用该函数。
Result operator()(const Arg& x)
{
return _ptr(x);
}
private:
F_P _ptr; //一元函数成员
};
//辅助函数, 方便使用
template<class Arg, class Result>
inline pointer_to_unary_function<Arg, Result> ptr_fun(Result(*ptr)(Arg))
{
return pointer_to_unary_function<Arg, Result>(ptr);
}二元函数
二元函数其实就是把二元函数包起来, 然后()就是调用这个二元函数
cpp
template<class Arg1, class Arg2, class Result>
class pointer_to_binary_function : public binary_function<Arg1, Arg2, Result>
{
typedef Result(*F_P) (Arg1, Arg2);
public:
pointer_to_binary_function() {}
pointer_to_binary_function(F_P* ptr)
:_ptr(ptr)
{}
//
Result operator()(const Arg1 x1, const Arg2 x2)
{
return _ptr(x1, x2);
}
private:
F_P _ptr;
};
//辅助函数, 方便调用
template<class Arg1, class Arg2, class Result>
inline pointer_to_binary_function<Arg1, Arg2, Result> ptr_fun(Result(*ptr)(Arg1, Arg2))
{
return pointer_to_binary_function<Arg1, Arg2, Result>(ptr);
}