查询性能优化
重构查询的方式
在优化有问题的查询时,目标应该是找到一个更优的方法获得实际需要的记过------而不是一定总是需要从MySQL获取一模一样的结果集。有时候,可以将查询转换一种写法让其返回一样的结果,但是性能更好。但也可以通过修改应用代码,用另一种方式完成查询,最终达到一样的目的。
一个复杂查询还是多个简单查询
设计查询的时候一个需要考虑的重要问题是,是否需要将一个复杂的查询分成多个简单的查询,在传统实现中,总是强调需要数据库层完成尽可能多的工作,这样做的逻辑在于以前总是认为网络通信、查询解析和优化是一件代价很高的事情。但是这样的想法对于MySQL并不适用,MySQL从设计上让连接和断开连接都很轻量级,在返回一个小的查询结果方面很高效。现代的网络速度比以前要快很多,无论是贷款还是延迟。在某些版本的MySQL上,即使在一个通用服务器上,也能够运行超过10万的查询,即使是一个千兆网卡(1000Mbps / 8 bit = 125M/s)也能轻松满足每秒超过2000次的查询。所以运行多个小查询现在已经不是大问题了。MySQL内部每秒能够扫描内存中上百万行数据,相比之下,MySQL响应数据给客户端就慢得多了。在其他条件都相同的时候,适用尽可能少的查询当然是更好地。但是有时候,将一个大查询分解为多个小查询是很有必要的。别害怕这样做,好好衡量一下这样做是不是会减少工作量。
不过,在应用设计的时候,如果一个查询能够胜任时还写成多个独立查询是不明智的。例如,有些应用对一个数据表做10次独立的查询来返回10行数据,每个查询返回一条结果,查询10次
切分查询
有时候对于一个大查询我们需要"分而治之",将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。删除旧的数据就是一个很好的例子。定期地清除大量数据时,如果用一个大的语句一次性完成的话,则可能需要依次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但很重要的查询。将一个大的DELETE语句切分成多个较小的查询可以尽可能小地影响MySQL性能,同时还可以减少MySQL复制地延迟。例如,我们需要每个月运行一次下面的查询:
sql
mysql> DELETE FROM message WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONT那么可以用类似下面的办法来完成同样的工作:
sql
rows_affected=0
do {
rows_affected = do_query(
"DELETE FROM message WHERE created < DATE_SUB(NOW(), INTERVAL 3 MONTH)
LIMIT 10000"
)
} while rows_affected > 0一次性删除一万行数据一般来说是一个比较高效而且对服务器影响也是最小的做法(如果是事务型引擎,很多时候小事务能够更高效),同时,需要注意的是,如果每次删除数据后,都暂停一会儿再做下一次删除,这样也可以将服务器上原本一次性的压力分散到一个很长的时间段中,就可以大大降低对服务器的影响,还可以大大减少删除时锁的持有时间
分阶关联查询
很多高性能的应用都会对关联查询进行分解。简单地,可以对每一个表进行一次单表查询,然后将结果在应用程序中进行关联。例如,下面这个查询:
sql
mysql> SELECT * FROM tag
-> JOIN tag_post ON tag_post.tag_id=tag.id
-> JOIN post ON tag_post.post_id=post.id
-> WHERE tag.tag = 'mysql';可以分解成下面这些查询来代替:
sql
mysql> SELECT * FROM tag WHERE tag = 'mysql';
mysql> SELECT * FROM tag_post WHERE tag_id = 1234;
mysql> SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);到底为什么要这样做呢?乍一看,这样做并没有什么好处,原本一条查询,这里却变成多条查询,返回的结果又是一模一样的。事实上,用分解关联查询的方式重构查询有如下的优势:
- 1.让缓存的效率更高。许多应用程序可以方便地缓存单表查询对应的结果对象。例如,上面查询中的tag已经被缓存了,那么应用就可以跳过第一个查询。再例如,应用中已经缓存了ID为123、567、9098的内容,那么第三个查询中的IN()中就可以少几个ID.另外,对MySQL的查询缓存来说(Query Cache),如果关联中的某个表发生了变化,那么就无法适用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了
- 2.将查询分解后,执行单个查询可以减少锁的竞争
- 3.再在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展
- 4.查询本身效率也可能会有所提升。这个例子中,使用IN()代替关联查询,可以让MySQL按照ID顺序进行查询,这可能比随机关联要更高效。
- 5.可以减少冗余记录的查询。在应用层做关联查询,意味着对于某条记录应用只需要查询一次,而在数据库中做关联查询,则可能需要重复地访问一部分数据。从这点看,这样的重构还可能会减少网络和内存的消耗
- 6.更进一步,这样做相当于在应用中实现了哈希关联,而不是使用MySQL的嵌套循环关联。某些场景哈希关联的效率要高很多。
在很多场景下,通过重构查询将关联放到应用程序中将会更加高效,这样的场景有很多。比如,当应用能够方便地缓存单个查询的结果的时候、当可以将数据分不到不同的MySQL服务器上的时候、当能够使用IN()的方式代替关联查询的时候、当查询中使用同一个数据表的时候
查询执行的基础
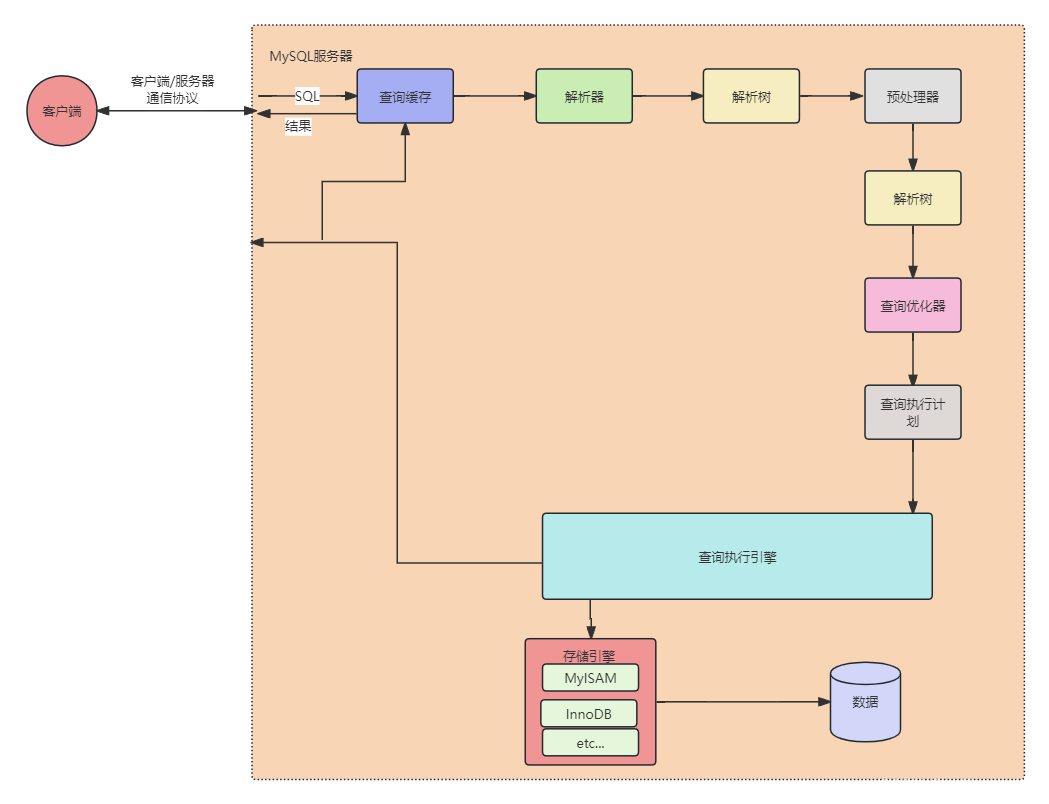
当希望MySQL能够以更高效的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的。一旦理解这一点,很多查询优化工作实际上就是遵循一些原则让优化器能够按照预想的合理的方式运行。MySQL执行一个查询的过程。根据如图所示,我们可以看到当向MySQL发送一个请求的时候,MySQL到底做了些什么。
- 1.客户端发送一条查询给服务器
- 2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
- 3.服务器端进入SQL解析、预处理,再由优化器生成对应的执行计划
- 4.MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询
- 5.将结果返回给客户端
上面的每一步都比想象的复杂,接下来我们会看到在每一个阶段查询处于何种状态。查询优化器是其中特别复杂也特别难以理解的部分。还有很多的例外情况,例如,当查询使用绑定变量后,执行路径会有所不同