在平时的业务中,可能一个简单的SQL语句也执行很慢,这种情况其实大多数都是要么没有使用索引,要么出现锁竞争造成执行阻塞。本篇主要来介绍具体的场景
CREATE TABLE
t(
idint(11) NOT NULL,
cint(11) DEFAULT NULL,PRIMARY KEY (
id)) ENGINE=InnoDB;
delimiter;create procedure idata()
begin declare i int;
set i=1; while(i<=100000) do
insert into t values(i,i);
set i=i+1; end while; end;; delimiter;
call idata();
第一类:查询长时间不返回
在平时我们可能通过一个主键查询表 sql select * from t where id=1;,但是很久没有返回数据,这种一般都是表被锁住,没办法执行。可以使用 show processlist 进行查看。可能是如下三种情况,我们来一一分析。
等 MDL 锁
我本地使用的是8.0版本,没有办法直接复现。

Session A
sql
mysql> lock table t write;
Query OK, 0 rows affected (0.00 sec)Session B
sql
mysql> select * from t where id = 1;session A 使用lock对表T进行加了全局写锁,session B 通过获取id=1的记录,被阻塞。
解决方案
通过 mysql> show processlist; 可以看到在waiting for table metadata lock,但是没有获取谁占用锁资源。
通过查询 sys.schema_table_lock_waits 这张表,我们就可以直接找出造成阻塞的 process id,把这个连接用 kill 命令断开即可。
sql
mysql> show processlist;
sql
mysql> select blocking_pid from sys.schema_table_lock_waits;
可以发现kill 29会话之后,立马查询到数据。
sql
mysql> kill 29;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t where id = 1;
+----+---+
| id | c |
+----+---+
| 1 | 1 |
+----+---+
1 row in set (1418.40 sec)等 flush
sql
Waiting for table flush当出现这种提示,可以分析,当前执行的SQL在等待flush操作。如果要复现的话。

sql
mysql> select sleep(1) from t; //等待
mysql> flush tables t; //阻塞表t
mysql> select * from t where id = 1; //获取不到数据 可以通过process list
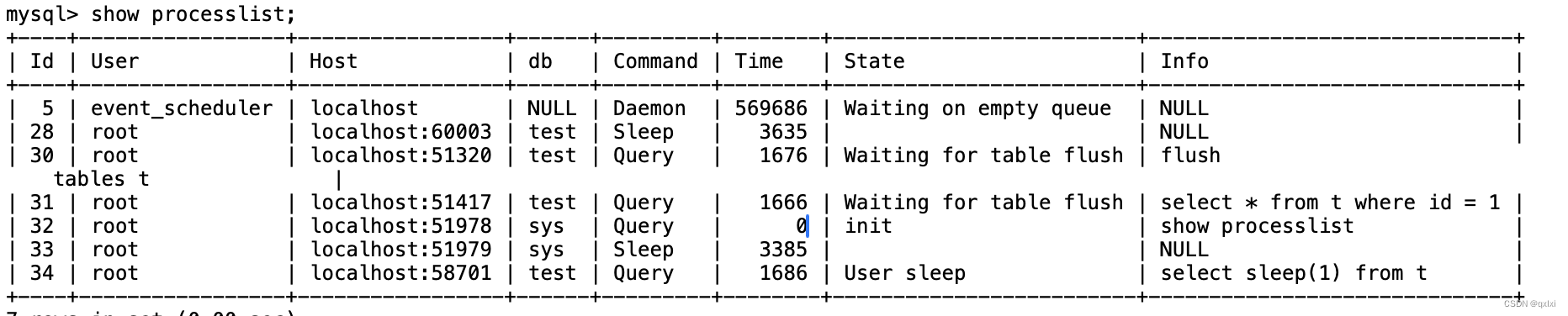
发现由于id = 34的阻塞了整个执行流程,直接kill 就可以。
等行锁
当我们执行如下语句,要对ID=1的记录进行添加读锁。
sql
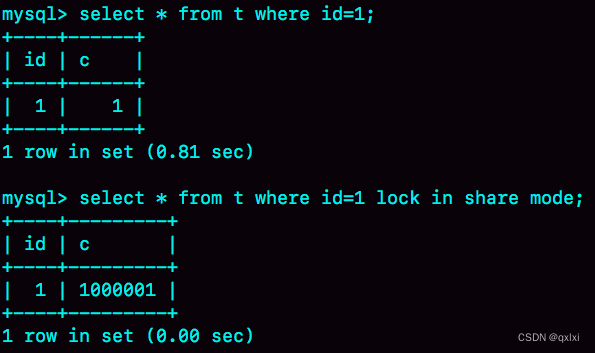
select * from t where id=1 lock in share mode; 
session a 会对ID=1加写锁操作,就会造成sessionb的阻塞。
sql
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update t set c = c + 1 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql>
sql
mysql> select * from t where id = 1 lock in share mode;
1205 - Lock wait timeout exceeded; try restarting transaction
mysql> 
我使用的是8.0 版本,可以发现获取不到锁,超时失败。尝试重新获取事务。1205 - Lock wait timeout exceeded; try restarting transaction
第二类:查询慢
没有使用索引
sql
select * from t where c=50000 limit 1;
可以发现,使用了全表扫描。虽然对于10W的数据量在0.02S内返回,但是坏查询不等于慢查询。当数据集过大时,非常影响系统性能。
大量undo log情况

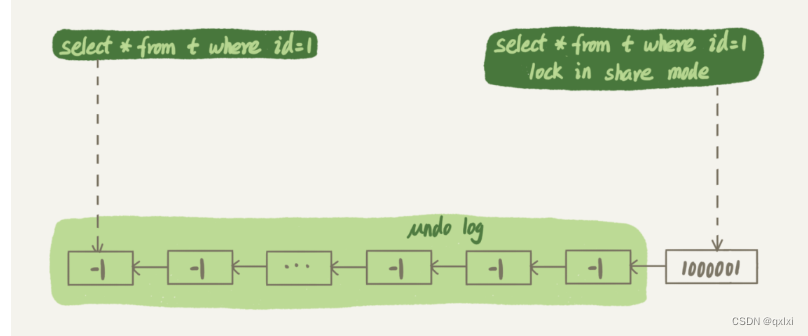
为什么一个不使用lock in share mode的语句比一个有的还执行的慢。在于如果lock in share mode是当前读,也就是不会回溯 undo log。而seesion A是一致性读,一步步执行 undo log,然后读取最原始的值。
小结
读取不返回结果和查询慢两种不一样,前者是有共享资源被占用,要么行锁、表锁,被其他线程占用。而查询慢一般没有使用索引、或者一致性读的过程。所以我们需要多分析系统上可能存在的语句阻塞问题。