一、软件环境
1.1 所需软件
1、 大疆智图:点击下载;
2、 ArcGIS Pro 3.1.5:点击下载,建议使用IDM或Aria2等多线程下载器;
3、 IDM下载器:点击下载,或自行搜索;
4、 FastCopy:自行搜索;
5、 Rclone:自行搜索配置;
6、 Python:安装软件ArcGIS Pro 3.1.5过程已安装,或自行搜索安装。
1.2 软件介绍
1、 大疆智图:进行空三、二维重建,软件需授权。无有效授权使用其他同替软件;
2、 ArcGIS Pro 3.1.5:使用Python脚本进行金字塔构建;
3、 FastCopy:局域网内成果快速拷贝;
4、 Rclone:配置账号成果上传分发;
以上软件按需使用。
二、大疆智图软件操作
2.1 软件启动
鼠标双击桌面"DJI Terra"图标,登录账号后进入软件。

2.2 任务创建
鼠标点击"新建任务",选择"可见光"。
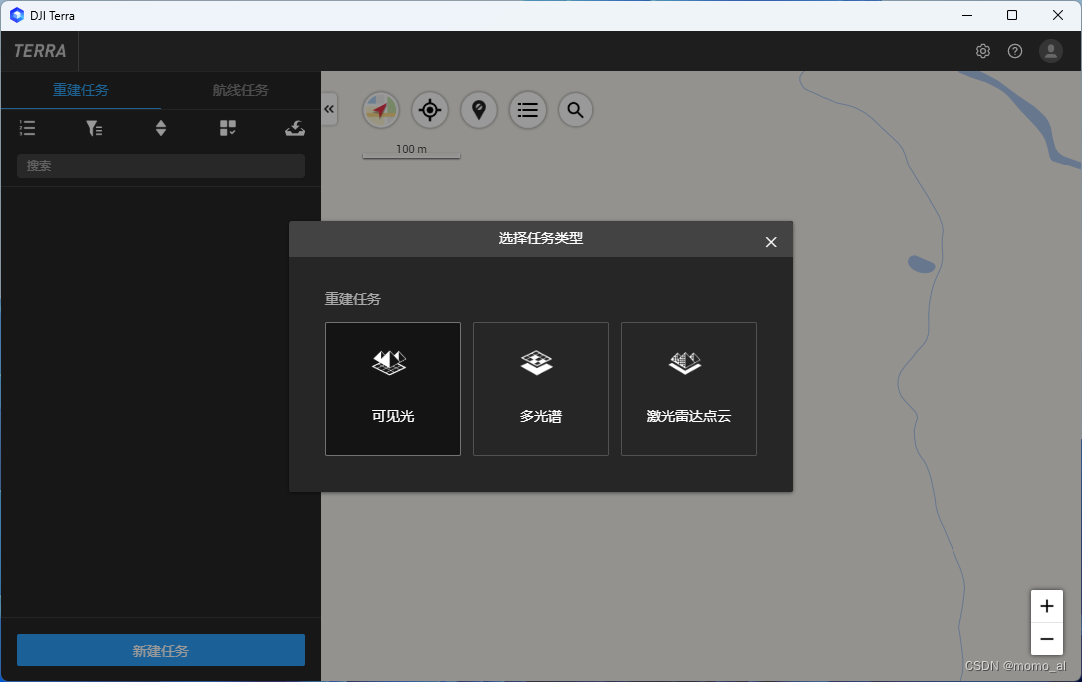 输入"任务名称"后点击"确定"。
输入"任务名称"后点击"确定"。
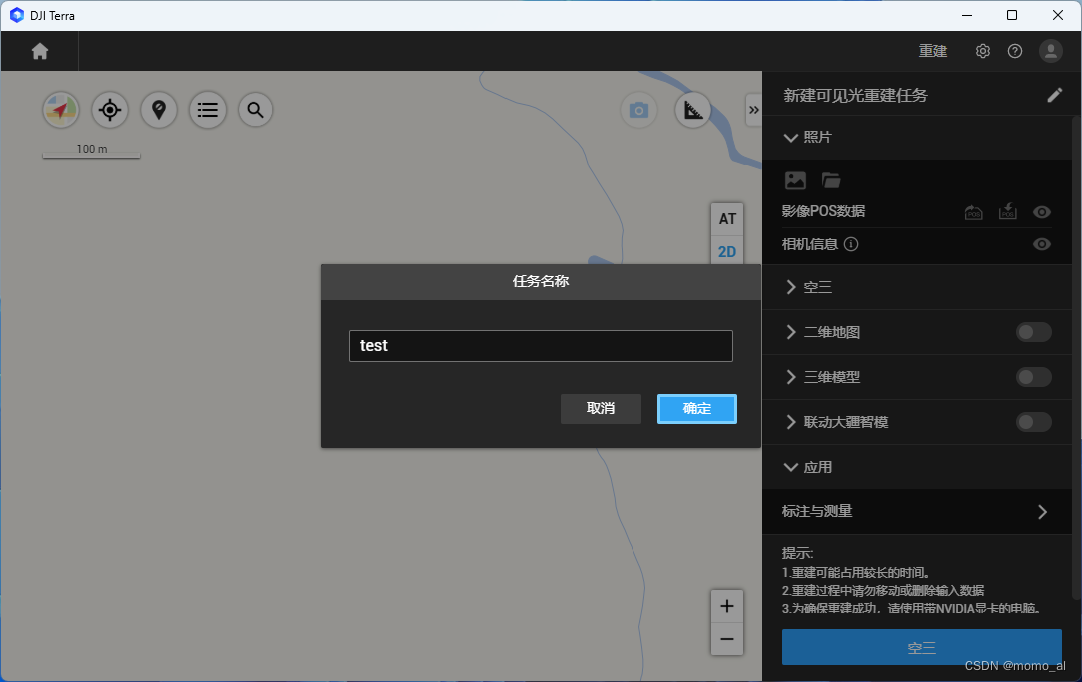
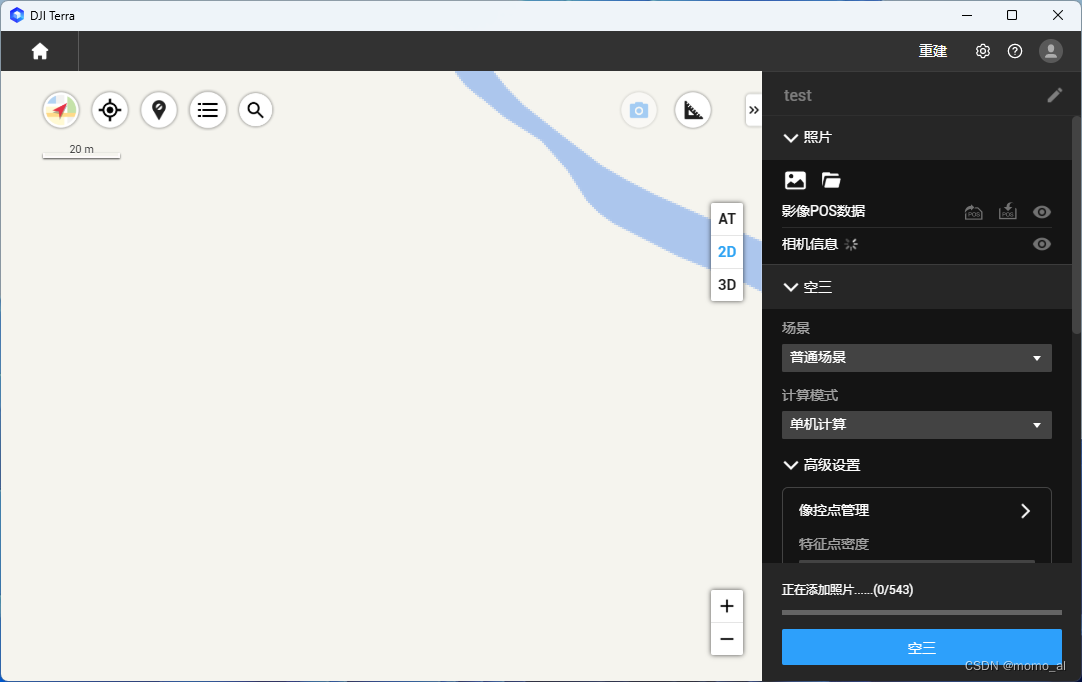
2.3 导入照片
点击"添加照片"或"添加文件夹",等待照片导入。
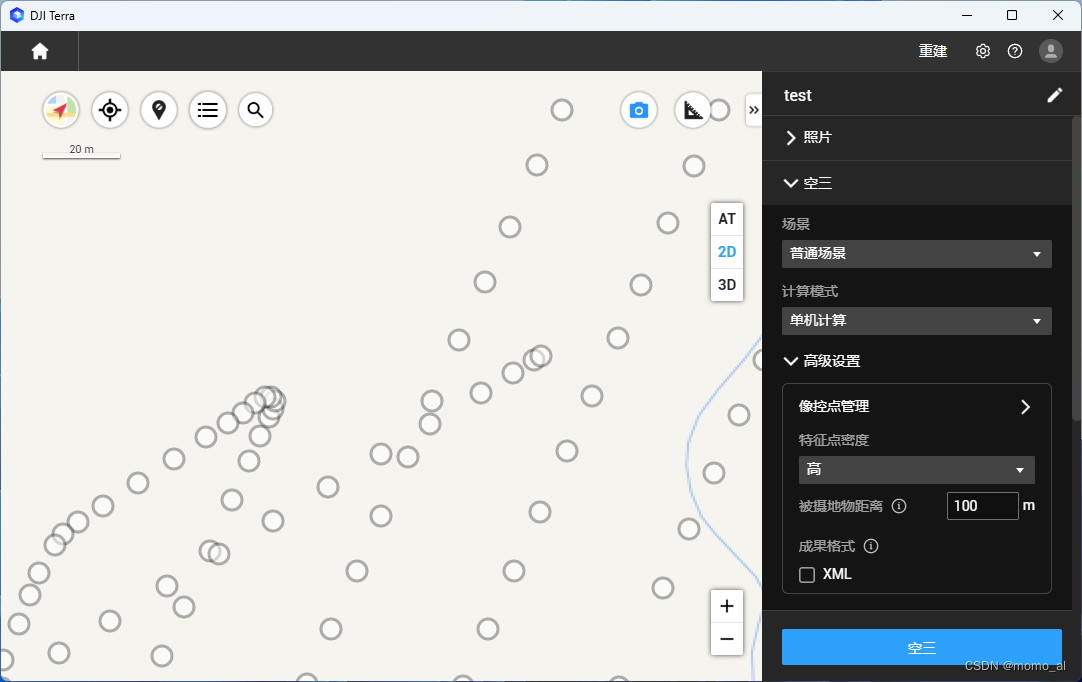
2.4 空三(建议操作,可跳过)
点击"空三","场景":普通场景 ,点击"高级设置"---"像控点管理"。
 点击"坐标系","水平设置":建议与二维重建坐标系一致 ;"高程设置":按需设置。
点击"坐标系","水平设置":建议与二维重建坐标系一致 ;"高程设置":按需设置。
 点击"空三",等待重建。
点击"空三",等待重建。
2.5 空三质量报告导出(建议操作,可跳过)
空三重建完成后,核实无误。点击"空三质量报告",点击"导出PDF"。
2.6 二维重建
"分辨率":高 ;"场景":测绘场景 (一般为测绘场景,农田无高差可选农田场景);
点击"高级设置","水平设置":选择所需坐标系 ;"高程设置":按需设置。
点击"开始重建",等待重建。
三、成果传输操作
鼠标右键点击"影像_构建金字塔.py";
选择"Run with ArcGIS Pro",或选择"Edit with IDLE(ArcGIS Pro)"后按键盘"F5"按键。
输入"1"后,按"回车"键确认。
 输入或粘贴局域网存放成果的路径。
输入或粘贴局域网存放成果的路径。
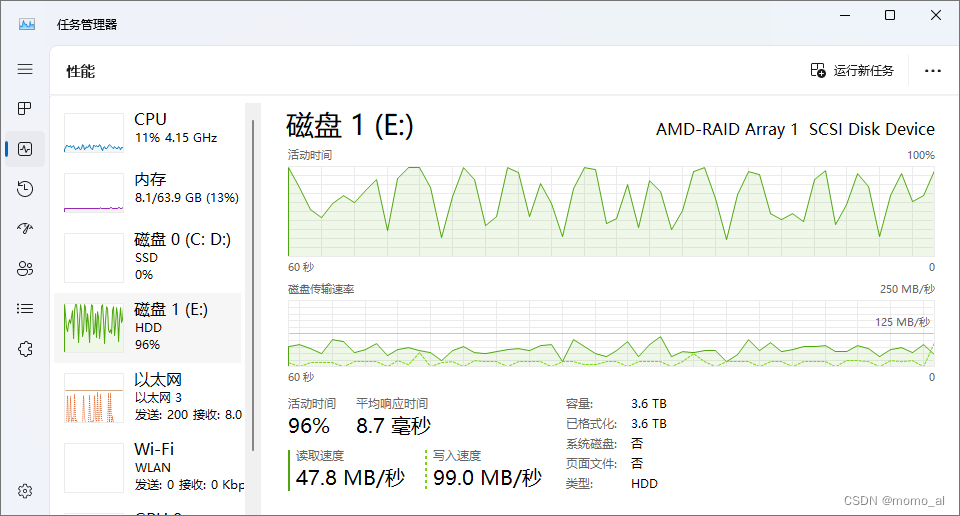
 构建金字塔运行情况。
构建金字塔运行情况。
四、代码
复制以下代码或点击下载脚本文件,并修改(注释、删除)以下(或者更多)参数,确保脚本能够正确执行。
#拼接大疆任务目录
dom_path
# 设置 7-Zip 可执行文件路径
seven_zip_path
# 设置 fcp 可执行文件路径
fcp_path
# 设置 rclone 可执行文件路径
rclone_path
# 设置 rclone 上传文件路径
rclone_up_path
#压缩至E盘根目录
compressed_file
python
# -*- coding: cp936 -*-
import arcpy
import os
import time
import datetime
import subprocess
import concurrent.futures
# 判断指定目录是否存在
def check_path_exists(dir_path):
if not os.path.exists(dir_path):
print(f"指定目录:{dir_path} 不存在!")
exit()
# 判断金字塔文件是否存在
def check_pyramids_file_exists(file_path):
if os.path.isfile(f"{file_path}.ovr"):
print(f"已经存在:{file_path} 金字塔文件")
check_pyramids_file(file_path)
else:
pyramids_file(file_path)
# 检查金字塔文件是否正确
def check_pyramids_file(file_path):
result = arcpy.management.CheckPyramids(file_path)
if result:
print(f"检查文件:{file_path} 金字塔文件正确")
else:
print(f"检查文件:{file_path} 金字塔文件错误")
pyramids_file(file_path)
# 构建金字塔文件
def pyramids_file(file_path):
print(f"开始构建:{file_path} 金字塔文件")
start_time = time.time()
arcpy.management.BuildPyramids(file_path)
end_time = time.time()
execution_time = end_time - start_time
td = datetime.timedelta(seconds=execution_time)
hh, mm, ss = str(td).split(":") # 将时间差转换为时分秒
print(f"构建用时:{file_path} 构建{hh}小时{mm}分钟{ss}秒")
# fascoy同步最新日期目录
def sync_update_folder(source_path, destination_path):
print(f"正在同步:{source_path}")
cmd = f'"{fcp_path}" /cmd=sync_update /force_close "{source_path}" /to="{destination_path}"'
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
subprocess.run(cmd, startupinfo=startupinfo, shell=True)
# fascoy同步目录
def sync_folder(source_path, destination_path):
print(f"正在同步:{source_path}")
cmd = f'"{fcp_path}" /cmd=sync /force_close "{source_path}" /to="{destination_path}"'
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
subprocess.run(cmd, startupinfo=startupinfo, shell=True)
# rclone同步文件
def upload_file(compressed_file, rclone_up_path):
print(f"正在上传:{compressed_file}")
cmd = f"{rclone_path} sync {compressed_file} {rclone_up_path} --progress"
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
subprocess.run(cmd, startupinfo=startupinfo, shell=True)
print(f"上传成功:{compressed_file}")
# 7Z压缩目录
def seven_zip_file(dom_path):
# 获取文件名
cmd = f'{rclone_path} ls "{rclone_up_path}"'
process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
output, error = process.communicate()
# 解析输出,将文件名存入列表中
rclone_list = [line.split()[-1] for line in output.decode('utf-8').splitlines() if line.split()[-1]]
for foldername in os.listdir(dom_path):
folder_path = os.path.join(dom_path, foldername)
if f"{foldername}.7z" not in rclone_list:
compressed_file = f"E:\{foldername}.7z"#压缩至E盘根目录
compressed_files.append(compressed_file)
command = f'"{seven_zip_path} u {compressed_file} "{os.path.join(folder_path, "map", "result*.*")}"'
print(f"正在压缩:{foldername}")
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
subprocess.run(command, startupinfo=startupinfo, shell=True)
else:
print(f"已经存在:{foldername} ;如需更新,请先删除 {rclone_up_path} 中同名文件。")
# 删除本地 7z 文件
def delete_file(compressed_file):
for file in compressed_files:
os.remove(file)
print(f"本地文件:{file} 已删除!")
# 多线程处理map目录下dsm.tif与result.tif文件
def process_folder(foldername):
folder_path = os.path.join(dom_path, foldername)
if os.path.isdir(folder_path):
check_pyramids_file_exists(os.path.join(folder_path, r"map\dsm.tif"))
check_pyramids_file_exists(os.path.join(folder_path, r"map\result.tif"))
# 选择目录
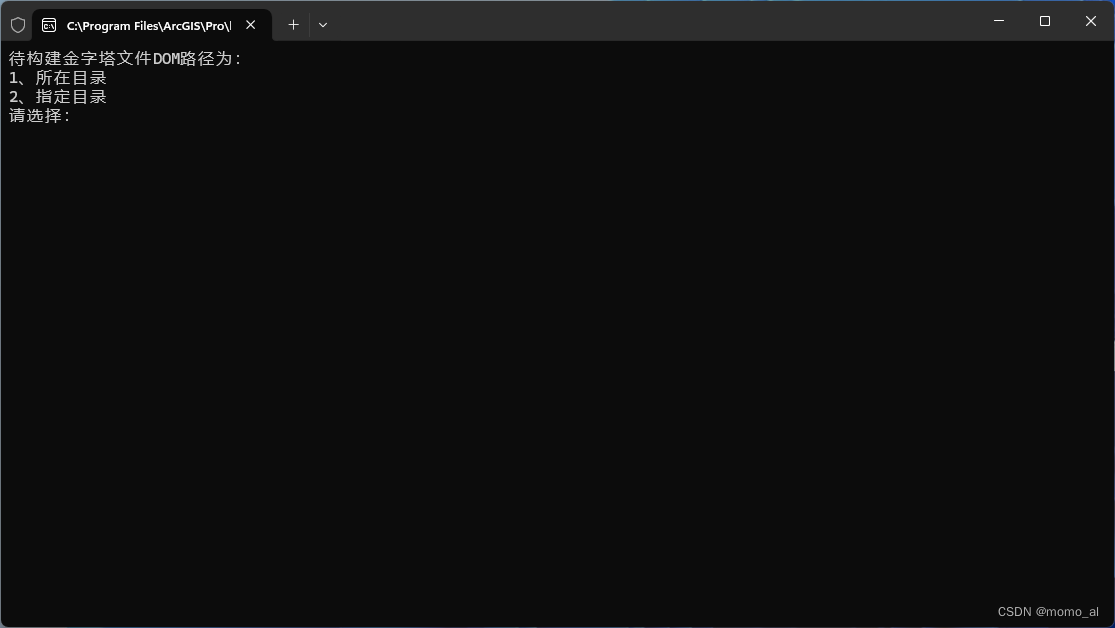
choice = input("待构建金字塔文件DOM路径为:\n1、所在目录\n2、指定目录\n请选择:")
if choice == "1":
current_file_path = os.path.abspath(__file__)
folder_path = os.path.dirname(current_file_path)
#拼接大疆任务目录
dom_path = os.path.join(folder_path, "PCGSPRO\\xxx")
else:
dom_path = input("请输入指定目录:")
check_path_exists(dom_path)
# 局域网存放路径
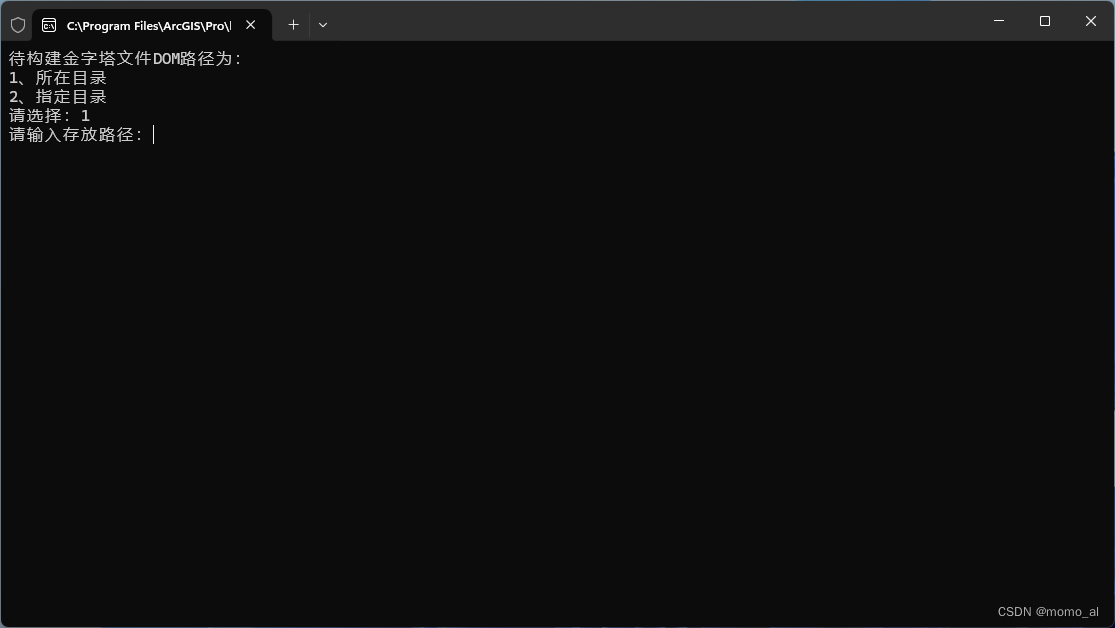
dst_path = input("请输入存放路径:")
check_path_exists(dst_path)
if __name__ == "__main__":
# 设置 7-Zip 可执行文件路径
seven_zip_path = f'"C:/Program Files/7-Zip/7z.exe"'
# 设置 fcp 可执行文件路径
fcp_path = f'"C:/Program Files/FastCopy5.7.10_x64/fcp.exe"'
# 设置 rclone 可执行文件路径
rclone_path = f'"D:/Program Files/rclone/rclone.exe"'
# 设置 rclone 上传文件路径
rclone_up_path = "OneDrive:/成果数据"
# 压缩文件的列表
compressed_files = []
# 创建线程池,最大线程为4,构建金字塔文件
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
executor.map(process_folder, os.listdir(dom_path))
# 局域网同步目录
for foldername in os.listdir(dom_path):
folder_path = os.path.join(dom_path, foldername)
if os.path.isdir(folder_path):
sync_folder(f'"{os.path.join(folder_path, "map", "dsm*.*")}" "{os.path.join(folder_path, "map", "result*.*")}"', os.path.join(dst_path, foldername))
sync_folder(f'"{os.path.join(folder_path, "map", "*_质量报告.pdf")}" "{os.path.join(folder_path, r"AT/report/POS_residual_of_camera.csv")}"', os.path.join(dst_path, foldername, "空三"))
#压缩文件
seven_zip_file(dom_path)
# 异步上传文件
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(upload_file, file, rclone_up_path) for file in compressed_files]
concurrent.futures.wait(futures)
#删除压缩文件
delete_file(compressed_file)
print("\nOVER!")
input("按任意键继续...")五、说明
1、大疆智图空三丢失图片:
因空三导入的区域不连续,并且接壤的地方没有重叠。导致空三时,无法获取到对应的特征点,从而重建缺失或者失败。只能单独重建或补飞。见官方说明,与客服沟通情况。

2、构建金字塔:
默认使用4线程操作,最大线程数量可修改;
3、局域网同步:
sync_update_folder或sync_folder可选,考虑硬盘读写情况,使用FastCopy顺序同步;
FastCopy同步:支持通配符,无需额外搭建环境;
Rclone同步:自用更倾向于搭建webdav等方式同步,速度尚可;
4、压缩文件:
7Z参数可修改,考虑硬盘读写情况,使用7Z顺序压缩;
5、脚本文件使用:
需要键入参数适合人工交互处理,修改代码固定参数之后便于定时任务自动化处理。
六、更新
20240611:
1、调整脚本文件代码顺序,便于注释、删除功能;
2、修改金字塔文件验证方式。