本篇会加入个人的所谓鱼式疯言
❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言
而是理解过并总结出来通俗易懂的大白话,
小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的.
🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接受我们这个概念 !!!

前言
在前几篇文章中,我们主要讲解了关于 数据表的CRUD 的各种 基础操作 , 而本篇文章我们讲继续学习 数据库的索引
索引 很重要, 是我们面试中 HR经常问到的很经典``,很热门`的考题之一 。
所以小伙伴们一定要好好理解消化本篇文章哦,说不定你下一次面试的时候,就会遇到这样的考题哦 💖 💖 💖 💖
目录
-
索引的初识
-
索引的不足
-
如何使用SQL 来操作索引
-
索引背后的数据结构
一. 索引的初识
1. 索引的概念
索引的英文名: index
小伙伴们是不是很眼熟,是的,这个英文单词本质上就是我们
Java数组中常用的 下标 的含义 。
除了这个含义,本质上我们还有一个含义就是 :目录。
是的,索引的认识 ,本质上就是相当于我们 新华词典上的目录
但是索引是针对数据库中的 某一列 来说的,就是说每个
不同的列可以构建不同的索引,
就是我们的新华词典的目录一样,有我们的拼音目录,部首目录,生僻字目录等...
居然 索引 相当于 目录 , 我们设想下目录的作用不就是 方便我们查找吗? 那么数据库索引是不是也是如此呢 ? ? ?
2. 索引的作用
索引作用就是 加快我们查找速度,提高我们
查找的效率。
因为索引是针对某个列来说的,所以小伙伴使用时,你要查询的 哪个列 要和索引对应的列相统一,才能触发 索引 的作用,
对于数据库本身来说,索引是有自动创建和手动创建的
<1>. 自动创建索引
当我们 创建表 时, 凡是以下三种情况就会创建 我们的索引
- 主键索引
sql
-- 创建该表
create table if not exist my_table (id int primary key , name varchar(49));
-- 查看表结构
desc my_table;
-- 查看该表的索引
show index from my_table;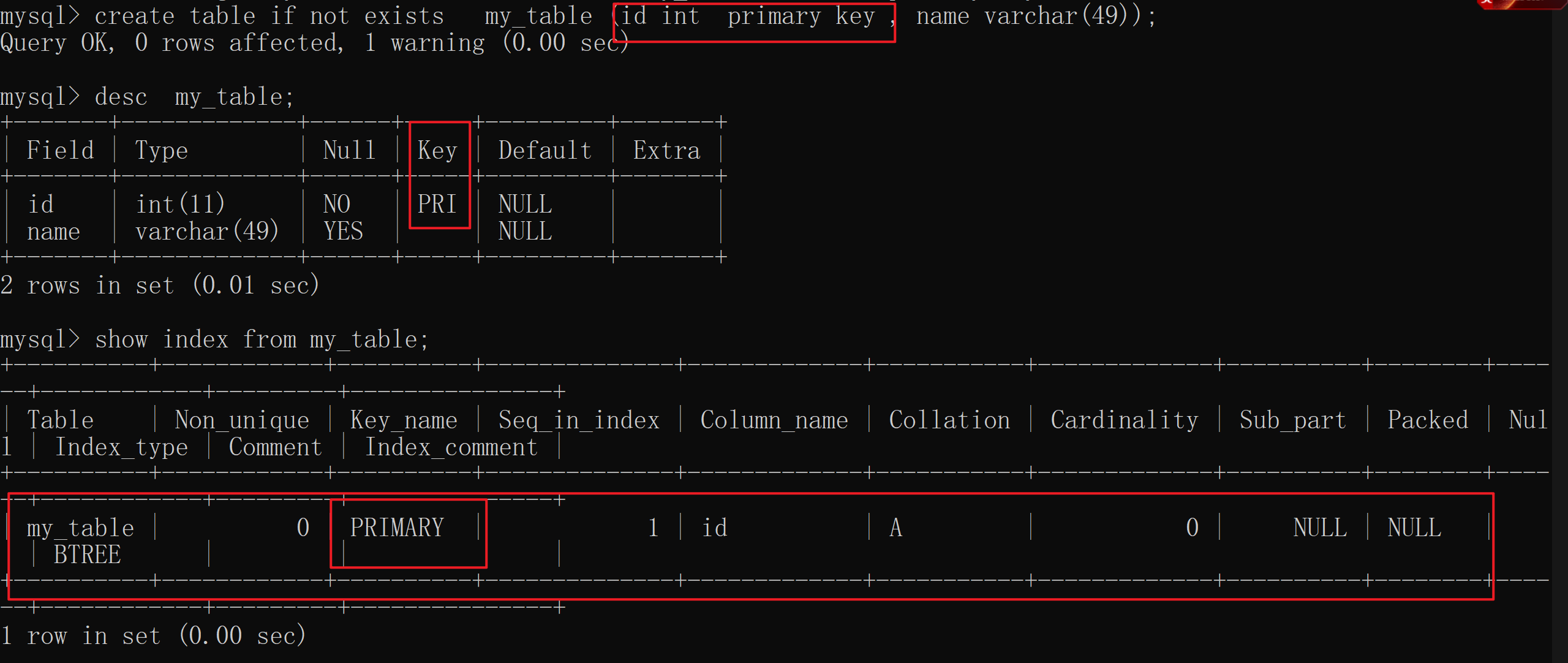
像上面这样我们创建 主键 时,就会自动生成该 字段的索引
这里的 show index from my_table;
小编在下面会在 . 如何使用 SQL 来操作索引 中,给小伙伴们细细道来哦 ❣️ ❣️ ❣️ ❣️
小伙伴们只需要知道,这是我们 查询表中索引 的 SQL语句即可哦
- unique 索引
sql
-- 删除前面的表
drop table if exists my_table;
# 创建该表
create table my_table ( id int unique , name varchar(45));
-- 查看表结构
desc my_table;
-- 查看该表中的索引
show index from my_table;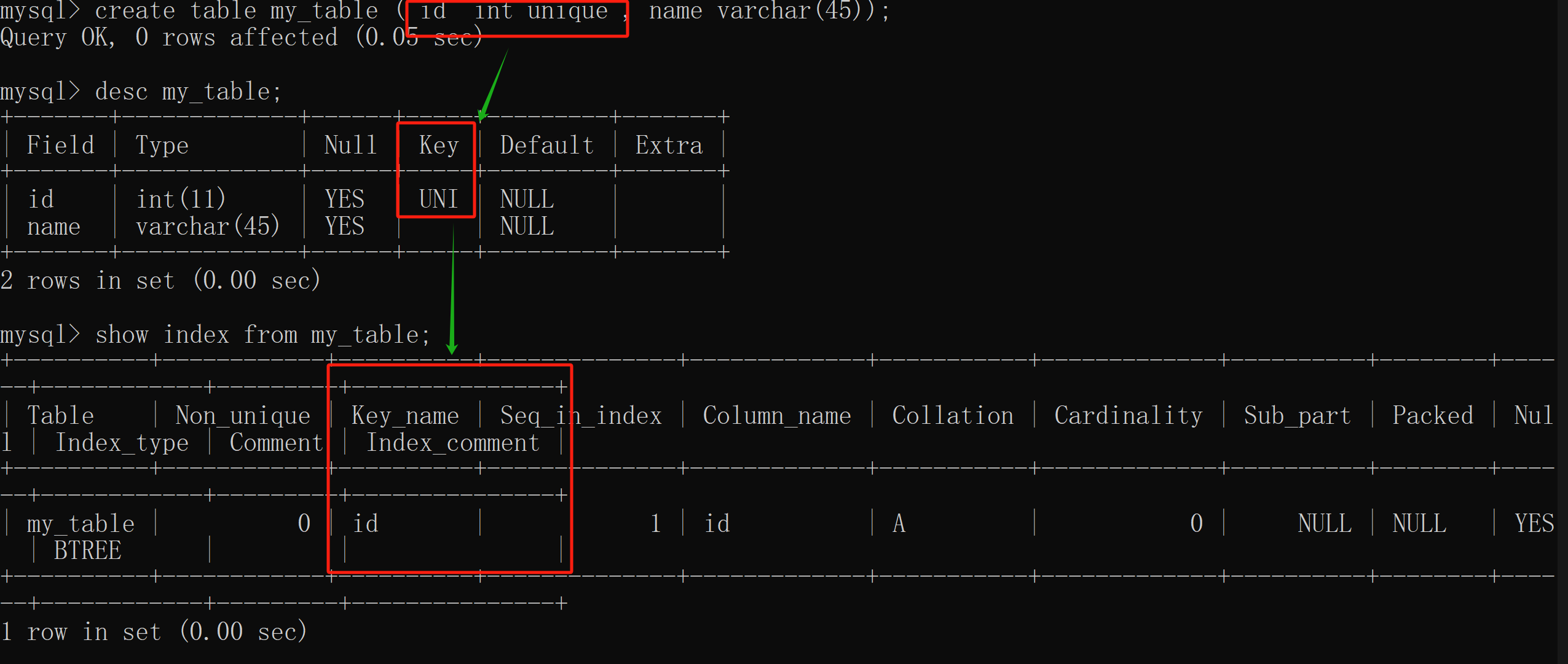
- 外键索引
sql
-- 创建父表
create table father ( father_id int primary key , name varchar(23));
-- 创建子表并进行外键连接
create table son ( son_id int primary key , name varchar(38),
father_id int , foreign key(father_id) references father(father_id));
-- 查看索引
show index from son;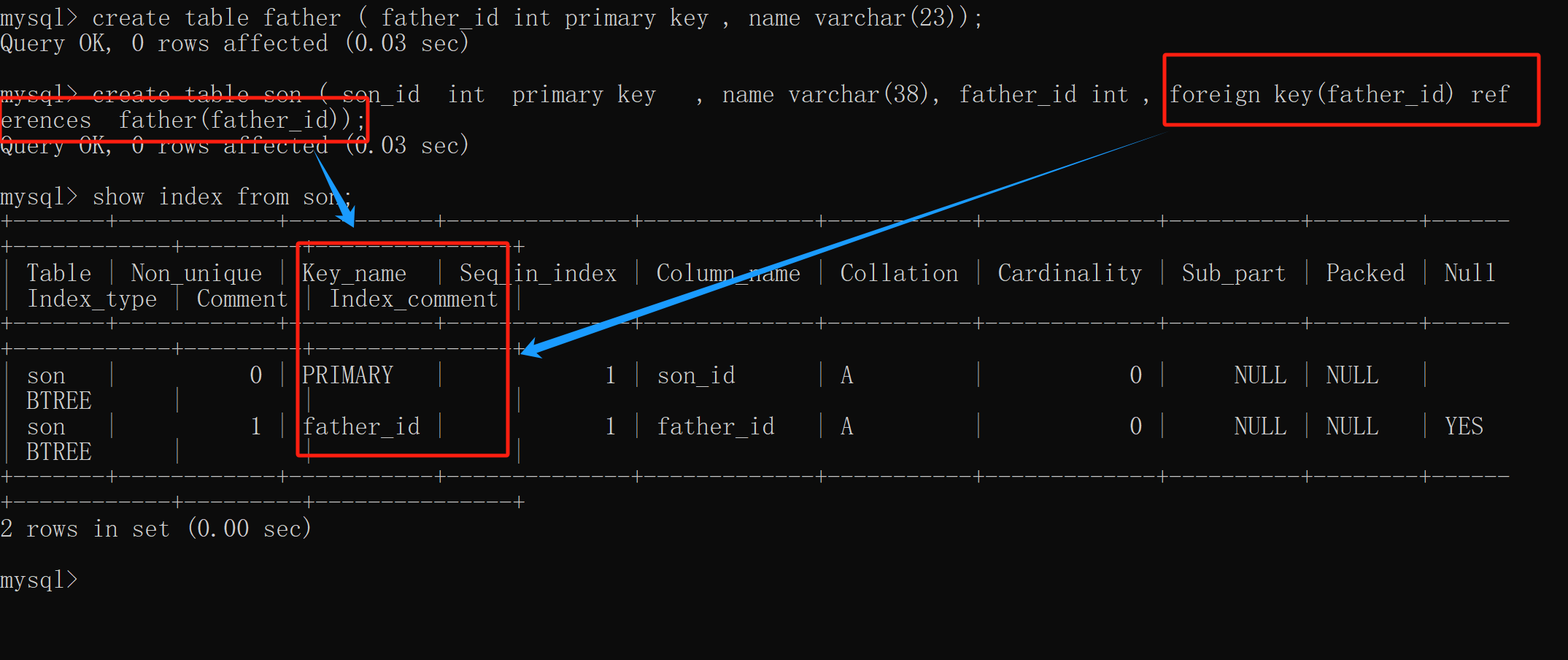
有个问题想问 小伙伴,为什么我们在创建 主键, unique , 外键 时, MySQL会自动添加索引呢 ?
我们可以回归到
unique和主键自身的作用来看 : 他们有一个 共同的作用 就是保持该字段的数据是唯一的,
为了保证 唯一性, MySQL的底层是需要 进行查询 ,从查询中返回该数据是否唯一, 居然用到了查询,那么我们就需要 索引来加快我们的查询速度 。
还有一个就是我们的 外键 , 外键的作用就是保证 子表的该字段数据 在父表的范围中, 父表的该外键字段数据必须 含有子表 的数据范围
当我们建立好 外键连接 后
如果需要对子表的数据进行
增加和修改,MySQL自身就会 查询一遍父表 ,看 子表要新添加的数据在子表中是否存在,存在就添加,不存在就无法添加 。
同样当我们需要对父表的数据进行删除和修改时, 我们就要 查询子表的数据 ,如果子表中含有该数据,我们就不能对父表和子表中都含有的数据进行 删除和修改
居然都要涉及到 查询 , 所以我们MySQL就会对外键自动添加 索引,以此来加快 查询速度 。
关于程序员自身如何 手动创建索引 ,小编在这里就 不剧透 哦,在如何使用SQL 来操作索引 会详细解释哦 💞 💞 💞 💞
鱼式疯言
关于自动创建索引,小编有两点想和小伙伴分享:
- 索引是针对表中 某一个字段 而言的,当我们需要对
某个字段查询时要和对应 字段索引 相统一
- 像我们
主键,外键,unique修饰的字段, 他们都涉及到 查询, MySQL都会自动创建 索引 益于 查询速度的加快 。- MySQL
自动创建的索引是 不允许删除 的,小编下面也会细细讲解哦
二. 索引的不足
世间万物,凡事都 有好的一面 和 不好的一面 ,居然索引能 加快我们的查询速度 ,必然也要付出一定的代价
不足一
创建索引 时,需要占用 额外的空间.
这就好比我们的新华词典中的目录一样,我们目录也是占用 纸张页数的
不足二
可能会
加快数据表 的增删改操作的 执行速度 。
可能会减慢数据表的增删改操作的 执行速度 。
也可能不会影响数据表的增删改的操作的 执行速度 。
鱼式疯言
小编在这里解释下哈 💥 💥 💥 💥
sql
delete from 表名 set 列名=新数据 where 条件 ;-
像我们这里涉及到
查询操作的时候,就会 加快执行速度 -
像有些
删除或者修改了数据之后, 我们对应的索引就 需要调整 , 就有可能会 触发 多次 硬盘IO , 减慢 执行速度。 -
也有可能和我们索引无关的,就
不影响我们的执行速度
三. 如何使用SQL 来操作索引
1. 查看当前索引
<1>. SQL语句
sql
show index from 表名 ;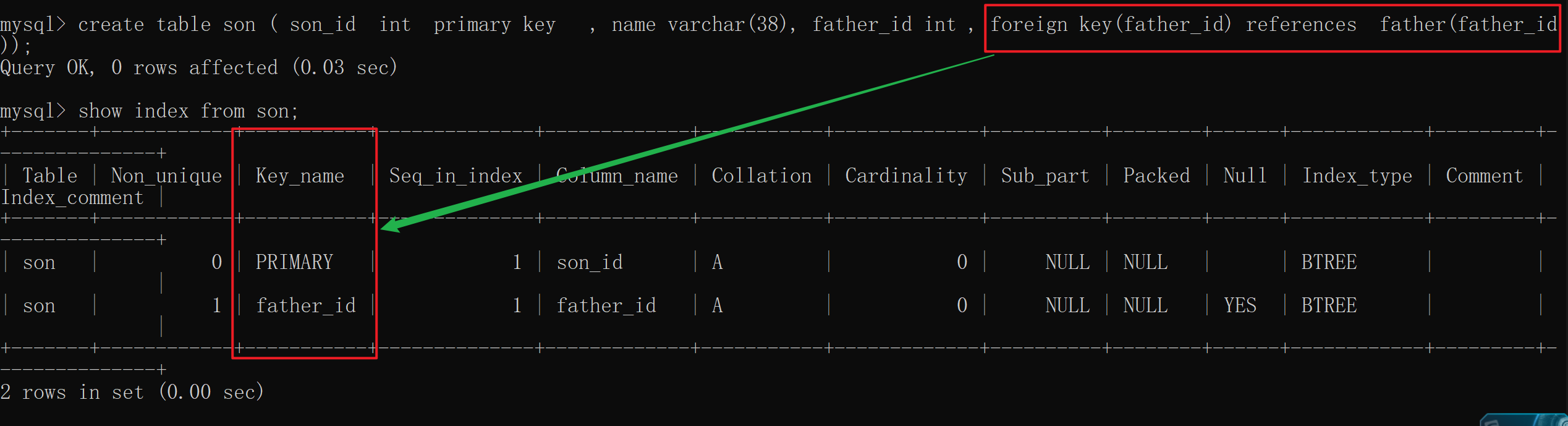
<2>. 语句分析
查询索引的关键标识是
show index后面再配上表名即可 。
<3>. 注意事项
虽然和我们查询 数据库 和 数据表 中的
show很像, 但是我们需要注意一点是 查询当前 数据库和数据表 是需要 再后面加上S的 ,而我们的 索引 是不需要的。
2. 创建索引
在上面的内容中,小编主要讲解了 数据表中 自动创建索引 的内容, 而这里要重点我们程序员本身用 SQL 手动创建索引 的方式
<1>. SQL语句
sql
create index 索引名 on 表名(列名); 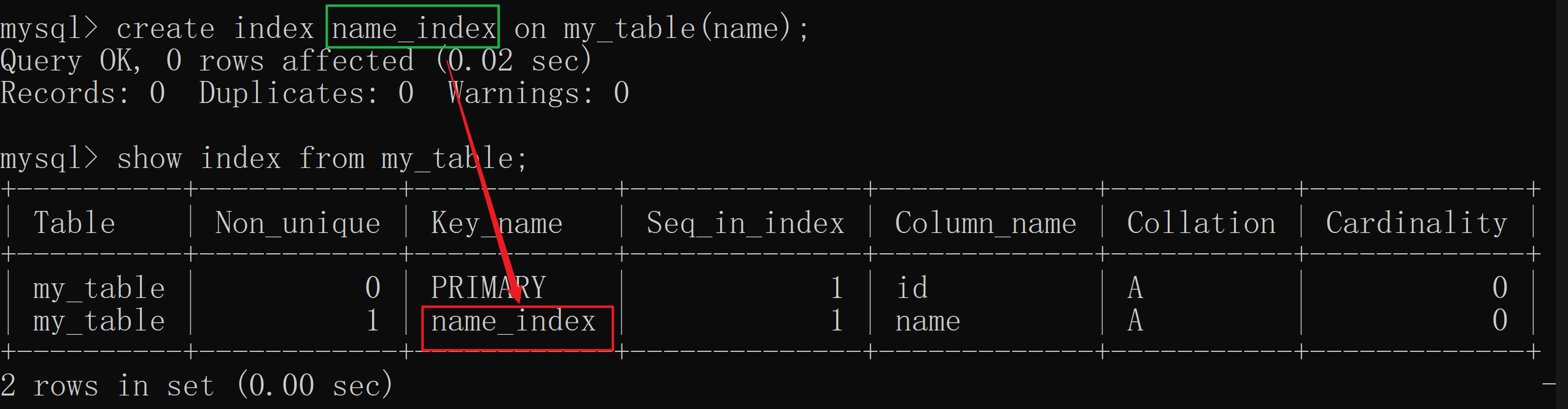
<2>. 语句分析
需要创建索引 时, 标识关键字
create index跟上索引名, 并用 on 来连接。
这和我们创建表和创建数据库不同的是, 因为我们的索引是针对列而已的,所以我们需要用on指定对应表中的列来 创建 我们的索引 。
<3>. 注意事项
对于索引本身来说是
利大于弊的 ,但是对于 手动创建索引 来说,其实有些情况是一种危险的操作 。
当数据表是空表或者是 只有几千行几万行数据时, 我们再 创建索引的 影响不大的 。
但是当我们数据表中存放上 百万行 ,千万行数据 时, 如果再去创建索引时,就会触发硬盘上大量的 IO, 这样会导致整个数据库直接挂掉 。
这样的操作就相当于给正在飞的飞机换发动机 ,这是一个 非常危险 的操作 。

所以当我们需要在数据表中存储的
数据规模非常大的时候, 就需要对数据库的用 哪些列 创建索引, 有一个具体的 规划和预测 ,以免出现大量数据,当创建数据库就会 触发 大量硬盘IO。
3. 删除索引
<1>. 语句分析
sql
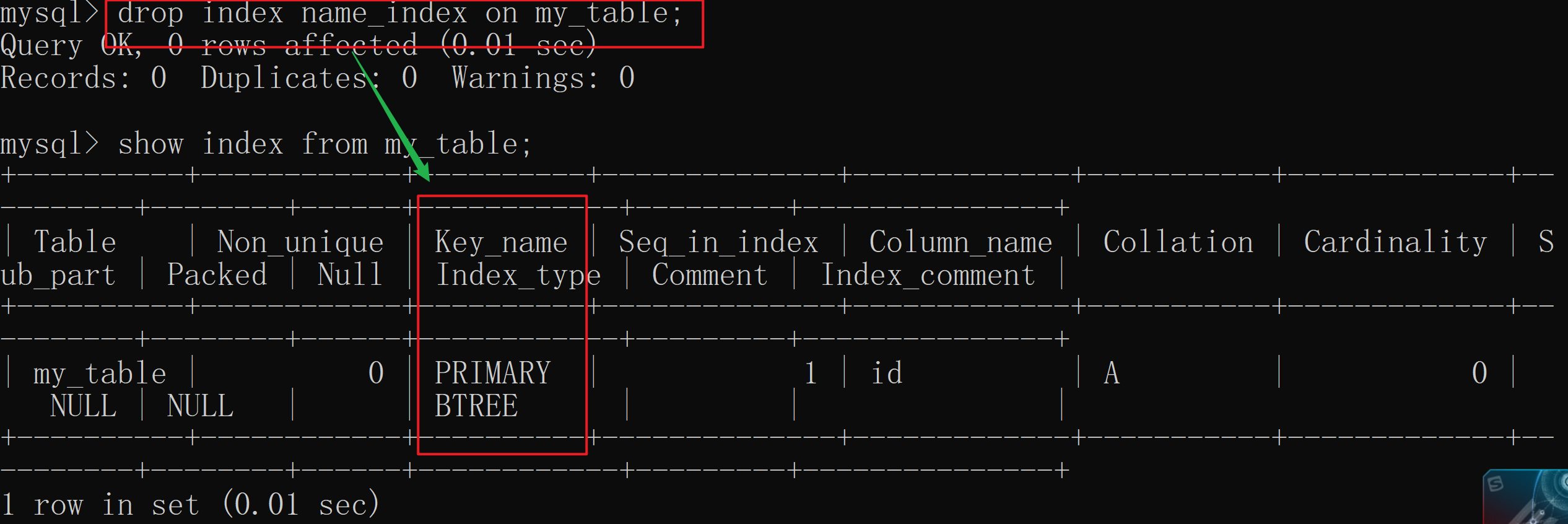
drop index 索引名 on 表名;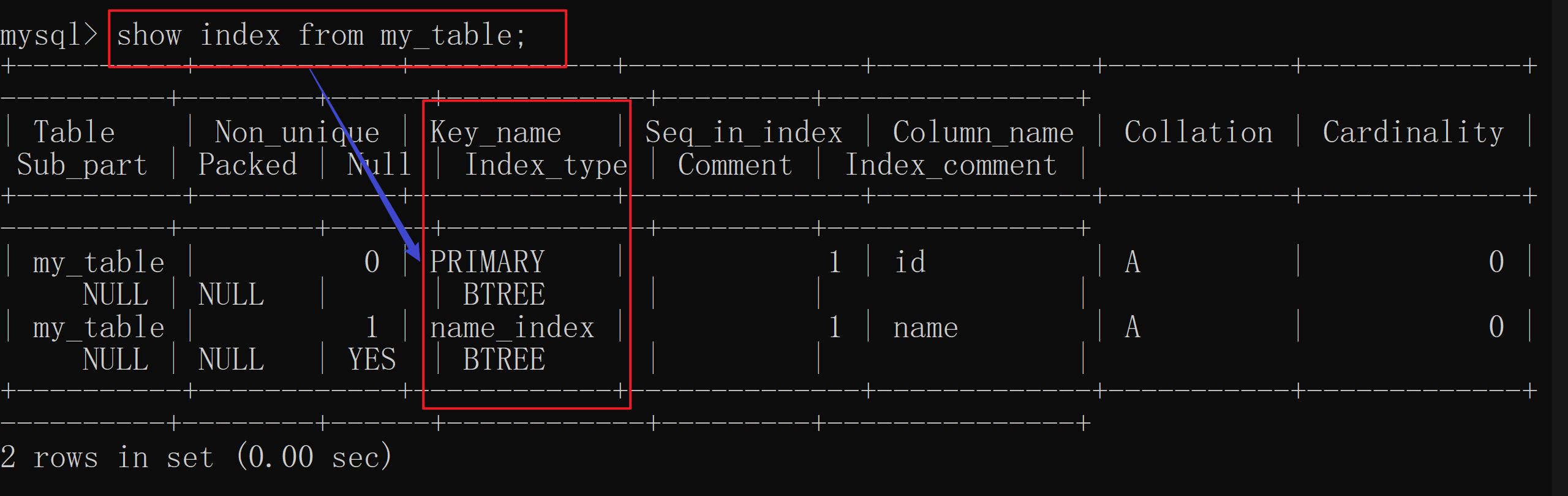
<2>. 语句分析
删除索引 的标志关键字就是 drop index ,因为 索引名不同表的可能一样 , 所以我们需要注意后面用 on 来指定指定 对应的表
<3>. 注意事项
这里需要 注意的一点 就是 :
- 小伙伴们手动自己创建的
索引是可以删除 的,但是 MySQL自动生成的索引 是无法删除的。
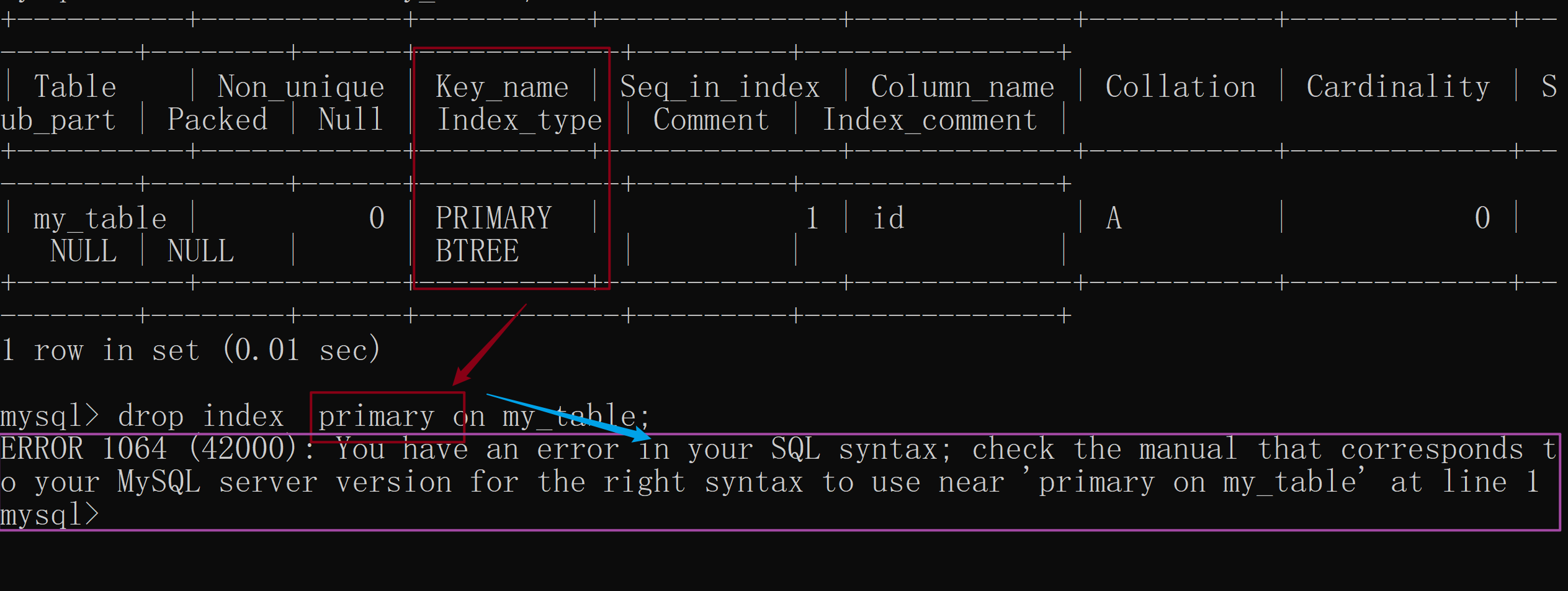
- 删除索引也是一个 非常危险 的操作,和我们上面的 创建索引 一样,当
数据规模很大时,这种操作是相当于给 正在飞的飞机上拆发动机 。
所以小伙伴一定要考虑好 何时删除索引 才是解决之道哦
四. 索引背后的数据结构
1. 索引背后数据结构的探讨
小伙伴可以猜想下我们索引背后是哪有一种神秘的 数据结构做支持 ,才能达到像 书的目录 一样 , 能 加快 我们 查询的速度 。
说到小伙伴学过的关于有查找功能的数据结构无非就是 以下两个 :
二叉搜索树: 我们知道对于 普通的二叉搜索树 来说, 一般都不是平衡二叉树,这样就会导致我们的时间复杂度最坏能达到O(N), 对于硬盘来说O(N)级别的时间复杂度 可 比 内存中O(N)的时间复杂度还大的多很多 。
并且对于二叉树来说 , 如果数据规模很大,树的高度就 很高 ,经历的 硬盘 IO 次数也是 很大 的 , 就会大幅度 减慢 查询速度 。
所以二叉搜索树是不适合做我们数据结构背后的索引
哈希表: 哈希表的本质是讲一组 key 值 通过 哈希函数 转化为我们数组的下标进行存储 ,但是这个也只能 查找某个值 ,对于 我们 SQLx > m这种范围查找,Hash(x) > Hash(m)这种结果并不成立的 。 所以也不适合用作我们 索引的数据结构 。
那么会是哪种数据结构呢? 答案就是我们的 B + 树 ...
可以这么说 ,我们的 B + 树 是专门为 数据库索引 量身定做的一种特殊的数据结构 。
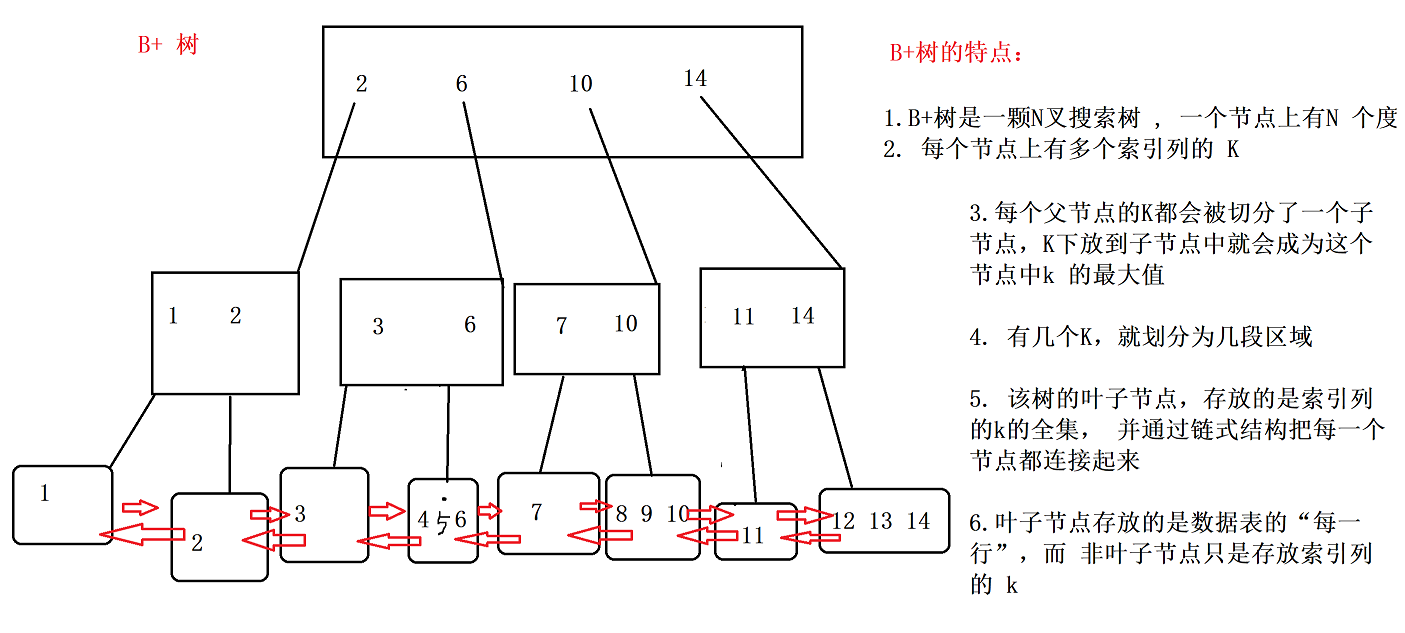
2. B+ 树的特点
B+树本身是一个N 叉搜索树,一个节点上有 N 个度- 每个节点都有 多个 K 值, 而有
多少个 K就把 划分了多少段区域,就有多少个 子节点 。- K 为
父节点,下放到子节点时,是作为该节点的 最大的 K- B+ 树的
叶子节点,是该 数据表的全集 ,并且 通过 链式结构 来连接每一个叶子节点- 叶子节点存储的数据表中的每一行 , 非叶子结构存储的是
索引列 的K.
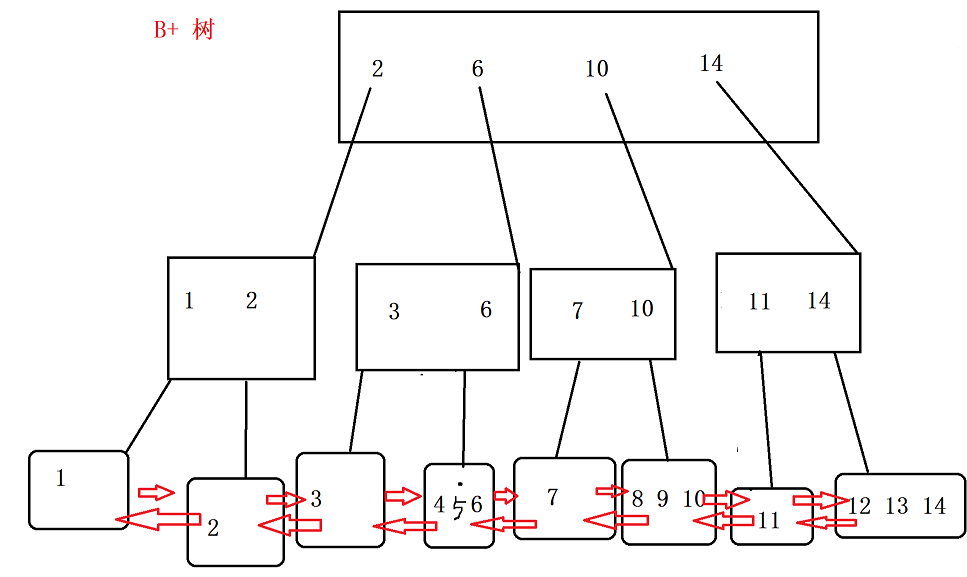
3. B+ 树的优势
-
因为 B+ 树 本身是
N叉树,所以有效的 降低了 树的高度,从而 减少 经历硬盘IO次数。 -
B+ 树 中每个节点存储的是多个K , 先让
硬盘读取该节点,然后在内存进行比较 ,这样就可以有效的减少经历硬盘IO的次数。 -
叶子节点因为是 数据的全集 ,这样经历硬盘的次数和比较的次数相当,能够更稳定预估结果
-
一个个叶子节点 是由 链表 来连接的,当我们
查找某个范围时, 就可以利用链式结构快速查找该范围的区间 。 -
叶子节点 是存储数据表中的 每一行 ,但非叶子节点存储的是
索引列的 K, 就可以减少每个节点的 存储空间 ,甚至让内存来读取数据 。
鱼式疯言
在这里小编最后想提及一个小概念
-
对于我们平常 学习的
数据库,数据表,以及本篇文章学习的 索引 , 本质上只是一种逻辑结构,而不是我们真正意义上的 表 或者 目录 . -
真正提的上
物理结构的,那便是我们的 数据结构 , 所以说我们的数据库的这种 逻辑结构 的背后是需要数据结构这样的物理结构作为支持的 -
数据库本身就是一种 "客户端" - "服务器" 结构的程序 。
总结
- 索引的初识 :
我们知道对于索引就是一本书特殊的 "目录" ,能加快查询的速度
但需要注意的是,我们的索引是针对列而已的,我们指定列查询一定要和索引列一一对应才能, 索引的查询效果才能生效。
并且MySQL会对 主键,unique , 外键 的自动生成索引, 且不能删除 。
- 索引的不足 :
唯一两点不足就是 :
-
占有额外的空间
-
可能会影响增删改的速度
- 如何使用SQL 来操作索引
1.查看当前索引
sql
show index from 表名;- 生成索引
sql
create index 索引名 on 表名(列名) ;- 删除索引
sql
drop index 索引名 on 表名 ;注意要点:
-
生成索引和删除索引在大规模的数据库来说,是危险操作。
-
删除索引只能删除自己创建的索引,不能删除MySQL生成的索引。
- 索引背后的数据结构
本身就是一颗B+树,是一颗为索引而量身定做的一种数据结构。
如果觉得小编写的还不错的咱可支持 三连 下 (定有回访哦) , 不妥当的咱请评论区 指正
希望我的文章能给各位宝子们带来哪怕一点点的收获就是 小编创作 的最大 动力 💖 💖 💖
