kafka数据写入流程
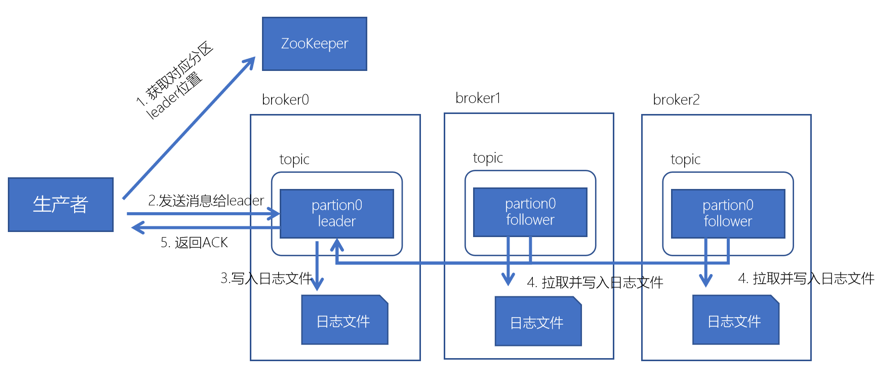
1.生产者先从zookeeper的"/brokers/topic/主题名/partitions/分区名/state"节点找到该partition的leader
生产者在ZK中找到对应的broker
broker进程上的leader将消息写入到本地log中。
follower从leader上拉取消息,写入到本地log,并向leader发送ACK
leader接收到所有的ISR中的Replica的ACK中,并向生产者返回ACK
Kafka数据消费流程
两种消息队列消费

kafka采用拉取模型,由消费者自己记录消费状态,每个消费者相互独立的顺序拉取消息。
消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
Kafka消费数据流程

- 每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区。
- 获取到consumer对应的offset(默认从ZK获取上一次消费的offset)
- 找到分区的leader,拉取数据。
- 消费者提交offset
Kafka的数据存储形式
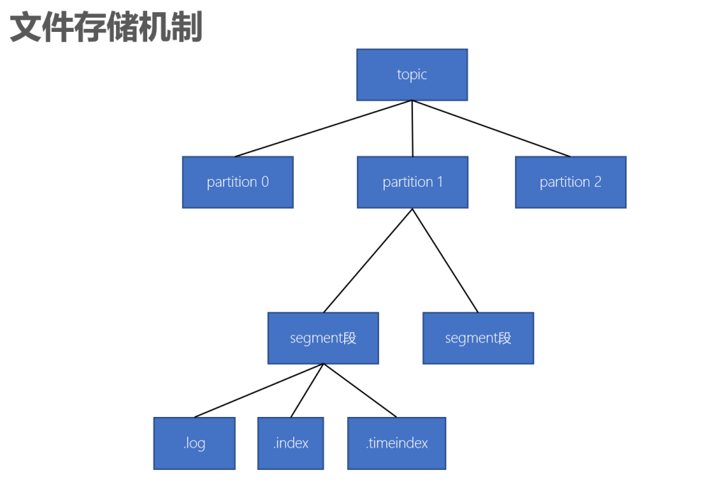
一个topic有多个partition分区组成。
一个分区(partition)有多个segment(段)组成。
一个segment(段)由多个文件组成(log,index,timeindex)
存储日志
Kafka中的数据到底是怎么在磁盘中存储的。
kafka中的数据保存在/export/server/kafka_2.12-2.41/data中
消息是保存在以:【主题名-分区ID】的文件夹中的。
数据文件夹中包含以下内容

这些分别对应:
|-------------------------------|------------------------------------------------------------------|
| 文件名 | 说明 |
| 0000000000000000000.index | 索引文件,根据offset查找数据就是通过该索引文件来操作的。 |
| 0000000000000000000.log | 日志数据文件 |
| 0000000000000000000.timeindex | 时间索引 |
| leader-epoch-checkpoint | 持久化每个partition leader对应的LEO(log end offset,日志文件中下一条待写入消息的offset) |
| | |
每个日志文件的文件名为起始偏移量,因为每个分区的起始偏移量是0,所以,分区的日志文件都以0000000000000000000.log开始
默认的每个日志文件最大为「log.segment.bytes =1024*1024*1024」1G
为了简化根据offset查找消息,Kafka日志文件名设计为开始的偏移量
观察测试
为了方便测试观察,新创建一个topic:「test_10m」,该topic每个日志数据文件最大为10
bin/kafka-topics.sh --create --zookeeper node1.itcast.cn --topic test_10m --replication-factor 2 --partitions 3 --config segment.bytes=10485760使用之前的生产者程序往「test_10m」主题中生产数据,可以观察到如下:
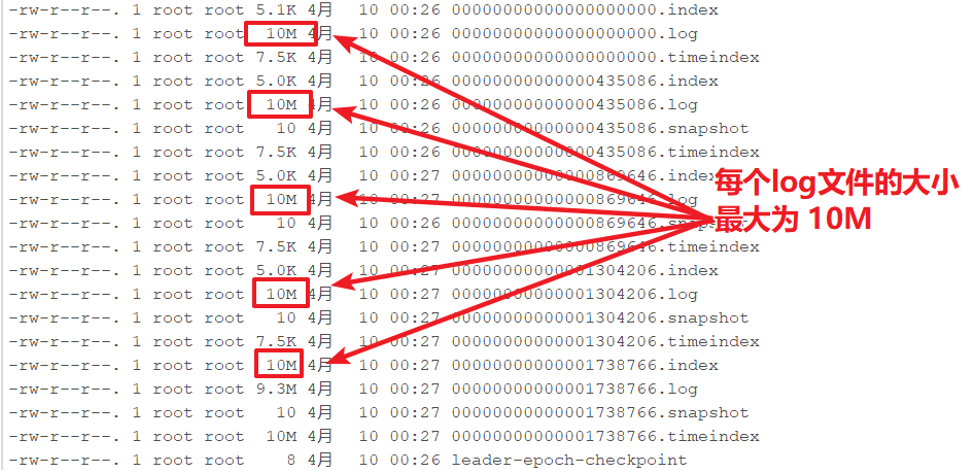

新的消息总是写入到最后的一个日志文件中
该文件如果到达指定的大小(默认为:1GB)时,将滚动到一个新的文件中

读取消息
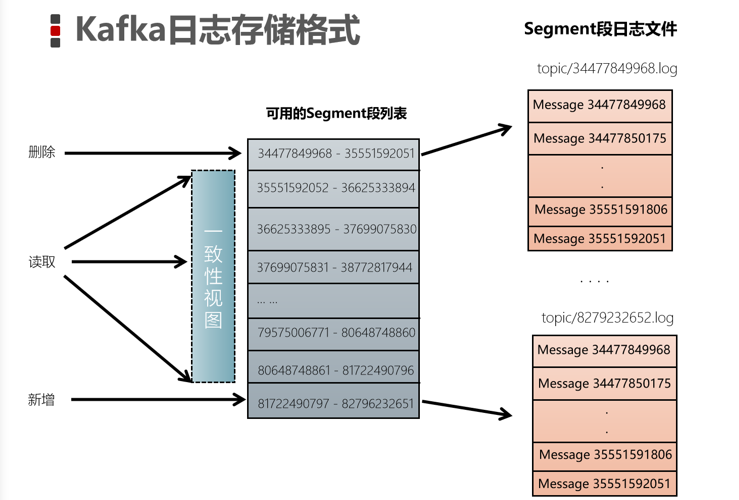
根据【offset】首先需要找到存储数据的segment段(注意:offset指定分区的全局偏移量)
然后根据这个【全局分区offset】找到相对于文件的【segment段offset】

最后再根据 「segment段offset」读取消息
为了提高查询效率,每个文件都会维护对应的范围内存,查找的时候就是使用简单的二分查找
删除消息
在Kafka中,消息是会被定期清理的。一次删除一个segment段的日志文件
Kafka的日志管理器,会根据Kafka的配置,来决定哪些文件可以被删除