Multimodal Dynamics(MD)是可信赖的多模态分类算法,该算法动态评估不同样本的特征级和模态级信息量,从而可信赖地对多模态进行融合。
来自:Multimodal Dynamics: Dynamical Fusion for Trustworthy Multimodal Classification
问题
假设有一个包含 N N N个数据的 M M M模态带标签数据集 { { x n m } m = 1 M , y n } n = 1 N \left\{\left\{x_{n}^{m}\right\}{m=1}^{M},y{n}\right\}_{n=1}^{N} {{xnm}m=1M,yn}n=1N,多模态分类的目标是构建多模态数据到标签的映射 f f f。
特征维度动态信息
对于高维特征向量 x m ∈ R d m x^{m}\in R^{d_{m}} xm∈Rdm,通常存在与类别相关的特征子集,反映分类任务中不同特征的信息量,且特征的具体信息量在不同的样本中是动态变化的。因此,在多模态融合时应该:
- 保留重要特征,去除冗余和噪声
- 增强多模态融合的可解释性
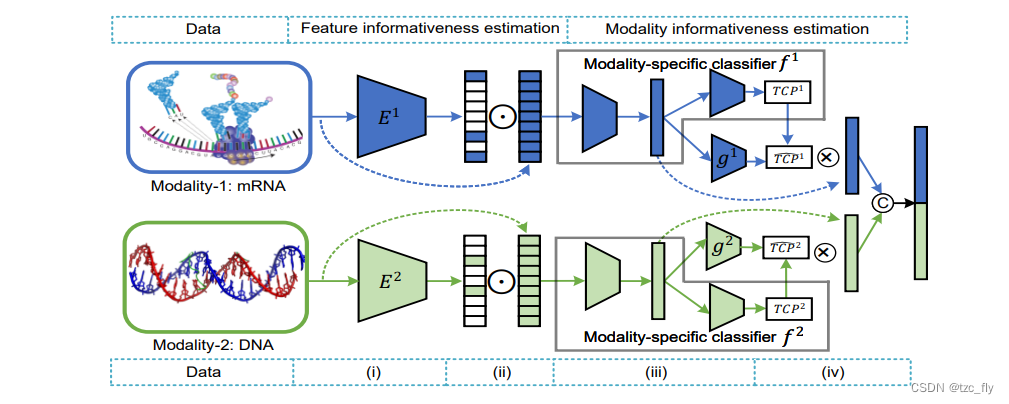
MD中引入了动态特征信息量编码网络,在不同模态下保留信息特征,抑制非信息特征。特征信息量编码网络通过对特征进行加权以分离信息特征和非信息特征: w m = σ ( E m ( x m ) ) = w 1 m , . . . , w d m m w^{m}=\sigma(E^{m}(x^{m}))=w_{1}\^{m},...,w_{d_{m}}\^{m} wm=σ(Em(xm))=w1m,...,wdmm其中, w m ∈ R d m w^{m}\in R^{d_{m}} wm∈Rdm是特征信息向量,对于高维数据,引入 l 1 l_{1} l1-norm 寻找特征的信息子集: L l 1 s = ∑ m = 1 M ∣ ∣ w m ∣ ∣ 1 L_{l_{1}}^{s}=\sum_{m=1}^{M}||w^{m}||_{1} Ll1s=m=1∑M∣∣wm∣∣1
模态维度动态信息
作者使用真实类概率来量化不同模态的分类置信度。在分类任务中,最终结果通常由最大类概率(MCP)来决定。这种方式虽然能给出预测分类,但会导致模型过度自信。不同于MCP使用最大概率同时表示预测和置信度,真实类概率(TCP)使用真实标签对应的softmax输出概率作为置信度。具体的,给定预测分布 p m ( y ∣ x m ) = p 1 m , . . . , p k m p^{m}(y|x^{m})=p_{1}\^{m},...,p_{k}\^{m} pm(y∣xm)=p1m,...,pkm和相应的标签 y y y, T C P m TCP^{m} TCPm表示为: T C P m = y ⋅ p m ( y ∣ x m ) = ∑ k = 1 K y k p k m TCP^{m}=y\cdot p^{m}(y|x^{m})=\sum_{k=1}^{K}y_{k} p_{k}^{m} TCPm=y⋅pm(y∣xm)=k=1∑Kykpkm当样本分类正确时,TCP等于MCP,当分类错误时,TCP更有可能是一个很低的值,为了在预测时给出TCP,每个模态 m m m训练一个置信度网络 g m : x m → T C P m g^{m}:x^{m}\rightarrow TCP^{m} gm:xm→TCPm来逼近训练集上的 T C P m TCP^{m} TCPm: L c o n f = ∑ m = 1 M ( g m ( x m ) − T C P m ) 2 + L c l s L^{conf}=\sum_{m=1}^{M}(g^{m}(x^{m})-TCP^{m})^{2}+L^{cls} Lconf=m=1∑M(gm(xm)−TCPm)2+Lcls
多模态融合
MD的整体架构如下图,门控用于保留信息特征: x ~ m = x m ⊙ w m \widetilde{x}^{m}=x^{m}\odot w^{m} x m=xm⊙wm, ⊙ \odot ⊙表示元素相乘,预测置信度用于多模态融合: h = g 1 ( h 1 ) , . . . , g M ( h M ) h=g\^{1}(h\^{1}),...,g\^{M}(h\^{M}) h=g1(h1),...,gM(hM)其中 h m = f 1 m ( x ~ m ) h^{m}=f^{m}{1}(\widetilde{x}^{m}) hm=f1m(x m), , , ,是拼接操作, f 1 m f{1}^{m} f1m是去掉最后一个全连接层的分类器。额外的分类器 f : h → y f:h\rightarrow y f:h→y通过交叉熵损失训练。
总结
MD特征维度是用可学习的网络输出特征权重,模态维度则通过每个模态设置一个置信度网络,输出分类置信度。注意这是处理联合数据的,因为每个模态下的样本都是匹配的。