1.1 内存设置 💾
常见的内存设置有两类:堆内和堆外 💡
我们作业中大量的设置 driver 和 executor 的堆外内存为 4g,造成资源浪费 📉。
通常 executor 堆外内存在 executor.cores=1 的时候,1g 足够了,正常来说最大值不超过 2g;driver 1g-2g 足够了 ✅。
注意:如果有 c++ 库这种计算,executor 堆外内存可以保持原有配置。 📚
| 各版本推荐配置的 key 以及配置值 | 各版本不推荐配置的 key 及配置值 | 过去无效配置,建议删除 🚫 | |
|---|---|---|---|
| driver 堆内 💽 | --conf spark.driver.memory=6G | 无 | 无 |
| driver 堆外 💾 | --conf spark.driver.memoryOverhead=2G | --conf spark.yarn.driver.memoryOverhead=4g | --conf spark.yarn.driver.direct* |
| executor 堆内 💽 | --conf spark.executor.memory=3G | 无 | 无 |
| executor 堆外 💾 | --conf spark.executor.memoryOverhead=1G | --conf spark.yarn.executor.memoryOverhead=4g | --conf spark.yarn.executor.direct* |
1.2 动态资源调度相关参数 📊
不开启动态资源管理或者参数设置不合理,会导致明显的资源浪费 💸:
涉及到动态资源调度的参数主要有以下几个 📝:
| 参数名 🛠️ | 默认值 ⚙️ | 作用 🧐 | 错误使用案例 🚫 | 使用建议 🌟 |
|---|---|---|---|---|
| spark.dynamicAllocation.enabled ✅ | false | 开启资源动态能力,在 executor 空闲时可以释放,需要资源是发起请求 | 不开启 | 开启资源动态功能,尤其是运行时间比较长或者有数据倾斜的情况 🌟 |
| spark.dynamicAllocation.executorIdleTimeout ⏲️ | 60s | executor 空闲多久开始释放资源 | 30000 或者 1200s 过大的数值 🚫 | 60s-120s 🌟 |
| spark.dynamicAllocation.minExecutors 📉 | 0 | 最小持有的 executor 数,到达该值,空闲也不会释放 | 200 🚫 | 推荐设置为 1-5 🌟 |
| spark.dynamicAllocation.maxExecutors 📈 | infinity | 作业申请 executor 资源的最大值 | 1000 以上 🚫 | 通常最大值建议 256-500 即可,小作业可以更小的设置 🌟 |
1.3 序列化参数 📝
Spark 中序列化主要有两种,java、kryo。相对来说 kryo 序列化效率更高,作为推荐 💡:
scala
1 spark.serializer org.apache.spark.serializer.KryoSerializer与 kryo 相关的设置有 📊:
scala
1 spark.kryoserializer.buffer,默认值 64k,这个不需要设置,设置值过大会常驻
2 spark.kryoserializer.buffer.max,默认值 64m不需要设置 spark.kryoserializer.buffer,默认的 buffer 会在 64k 到 64m 动态伸缩,没有特殊需要不需要设置,如果数据比较大,设置 spark.kryoserializer.buffer.max
1.4 并行度设置 ⚙️
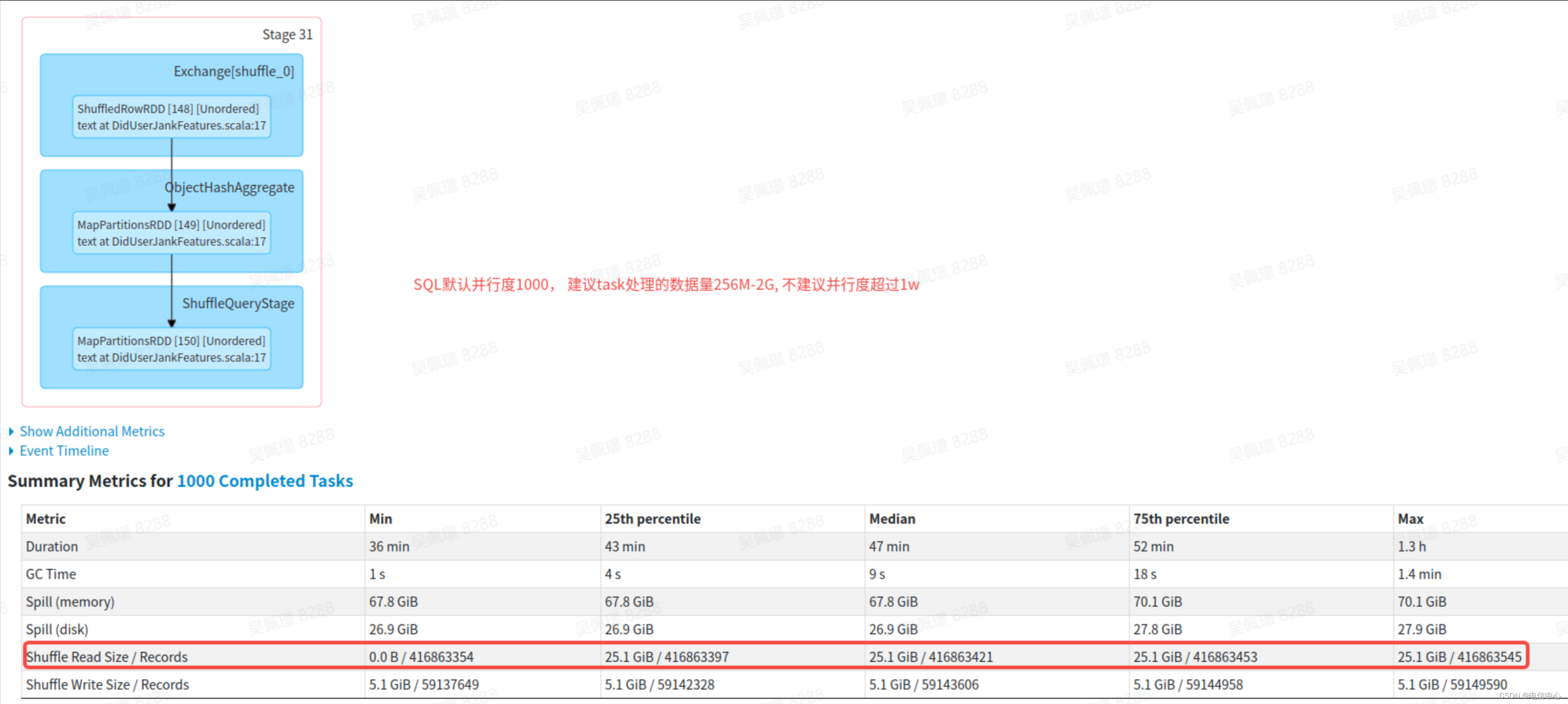
常见的并行度配置有两个 🔧:
- spark.default.parallelism 默认值:会继承上游 stage 的并行度,主要用于 rdd 的 shuffle 操作
- spark.sql.shuffle.partitions 默认值 200,主要用于 sql 的 shuffle 操作
算法作业绝大多数是 rdd 操作,合理设置并行度,事半功倍 💪,后面会专门介绍怎么优化自己的并行度设置 🌟
spark.default.parallelism 不建议设置的非常大。 🚫