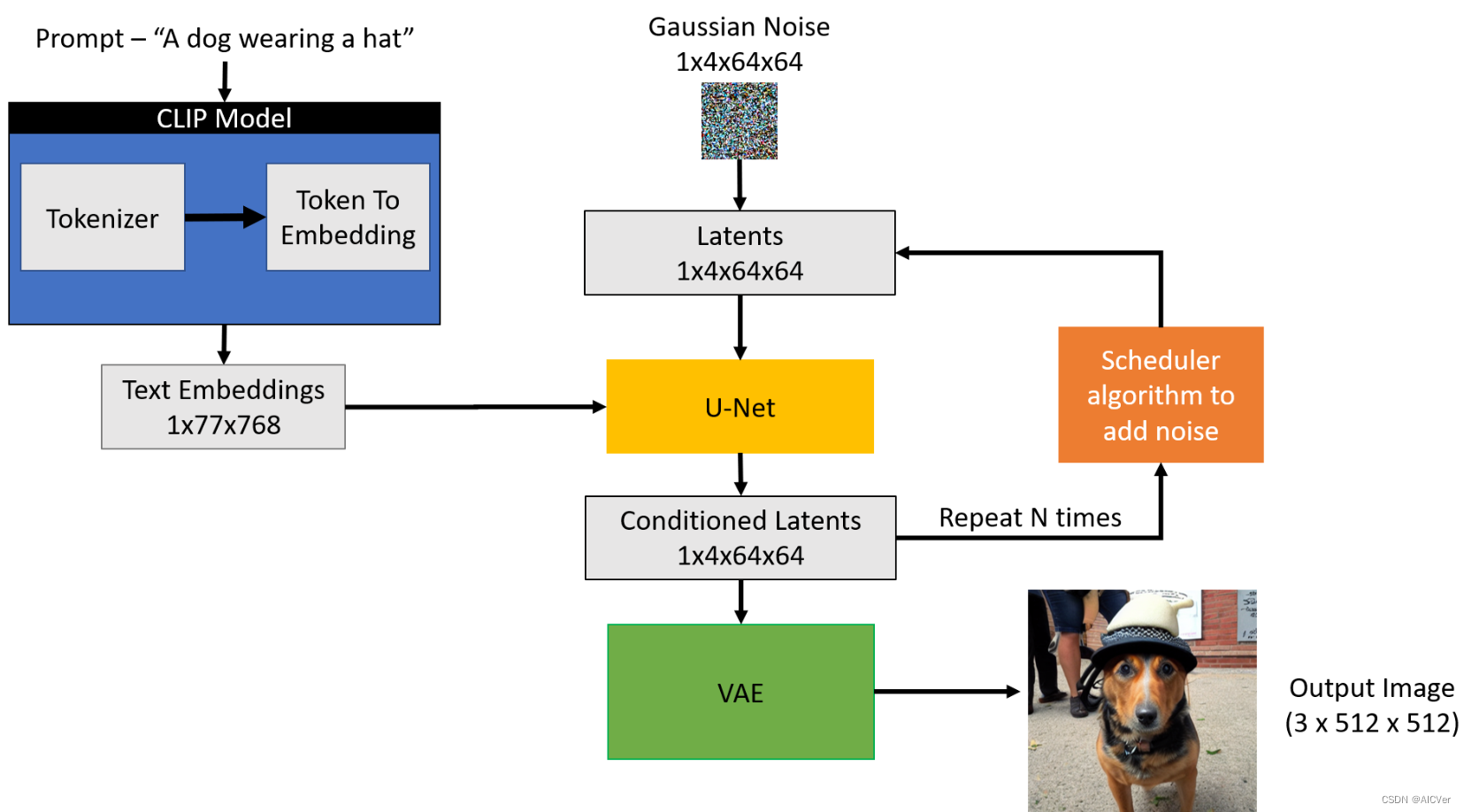
扩散模型构成
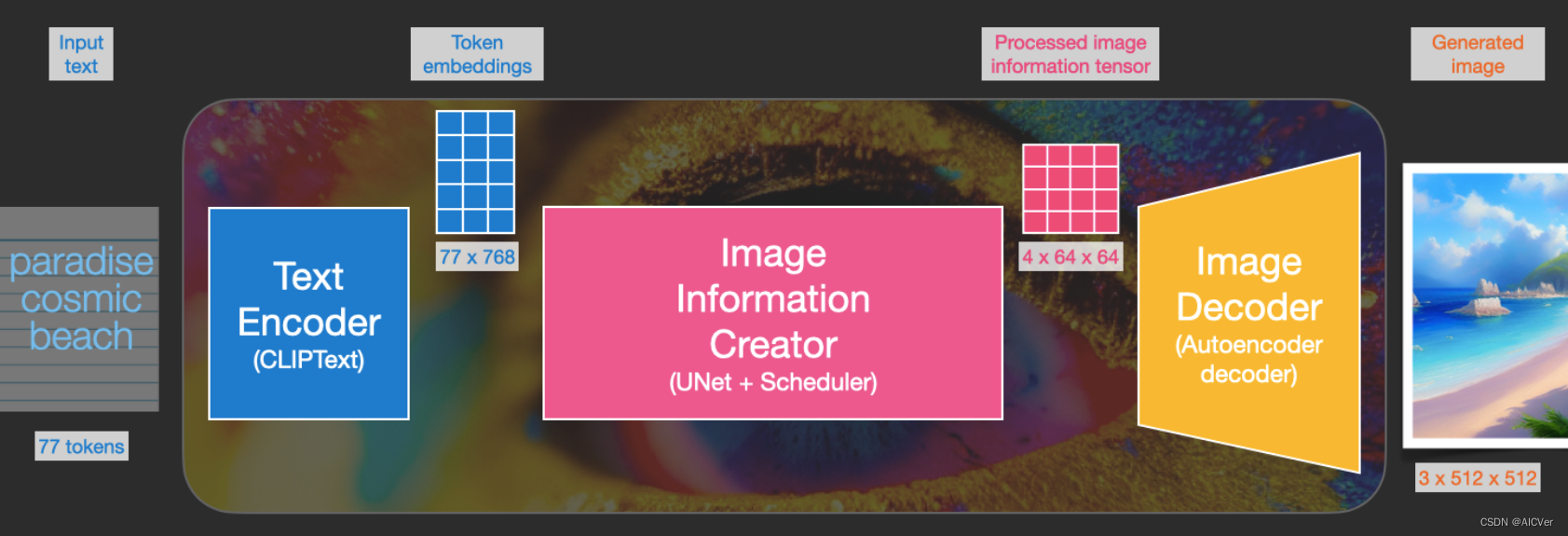
Text Encoder(CLIPText)
Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
Diffusion(UNet+Scheduler)
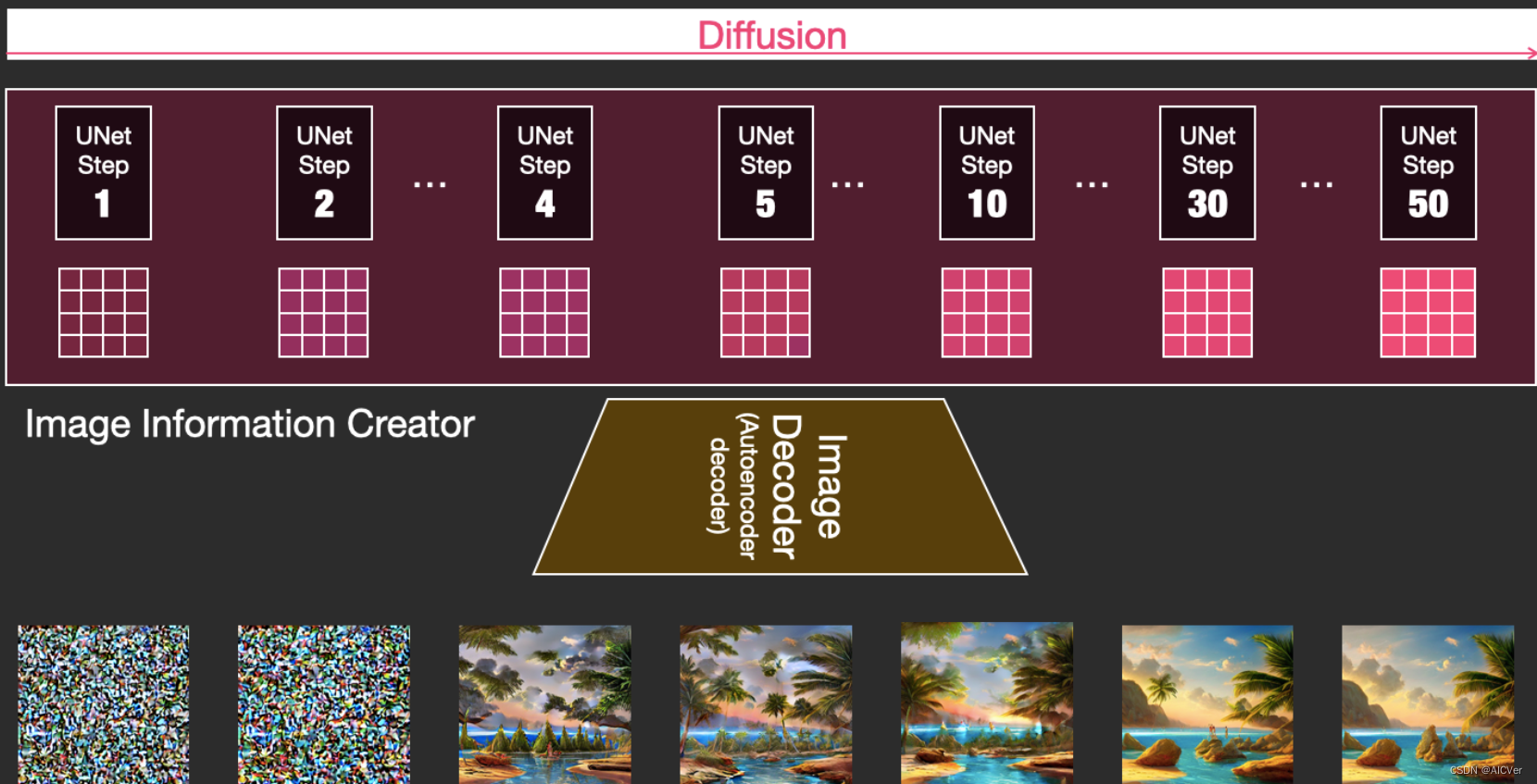
在潜在空间中逐步处理扩散信息。以文本嵌入向量和由噪声组成的起始多维数组为输入,输出处理的信息数组。
UNet
训练过程
- 随机噪声添加到图像上,构成一个训练样本
- 不同的噪声不同的图像,可构成训练集
- 使用上述训练集,训练噪声预测模型(Unet)
推理过程
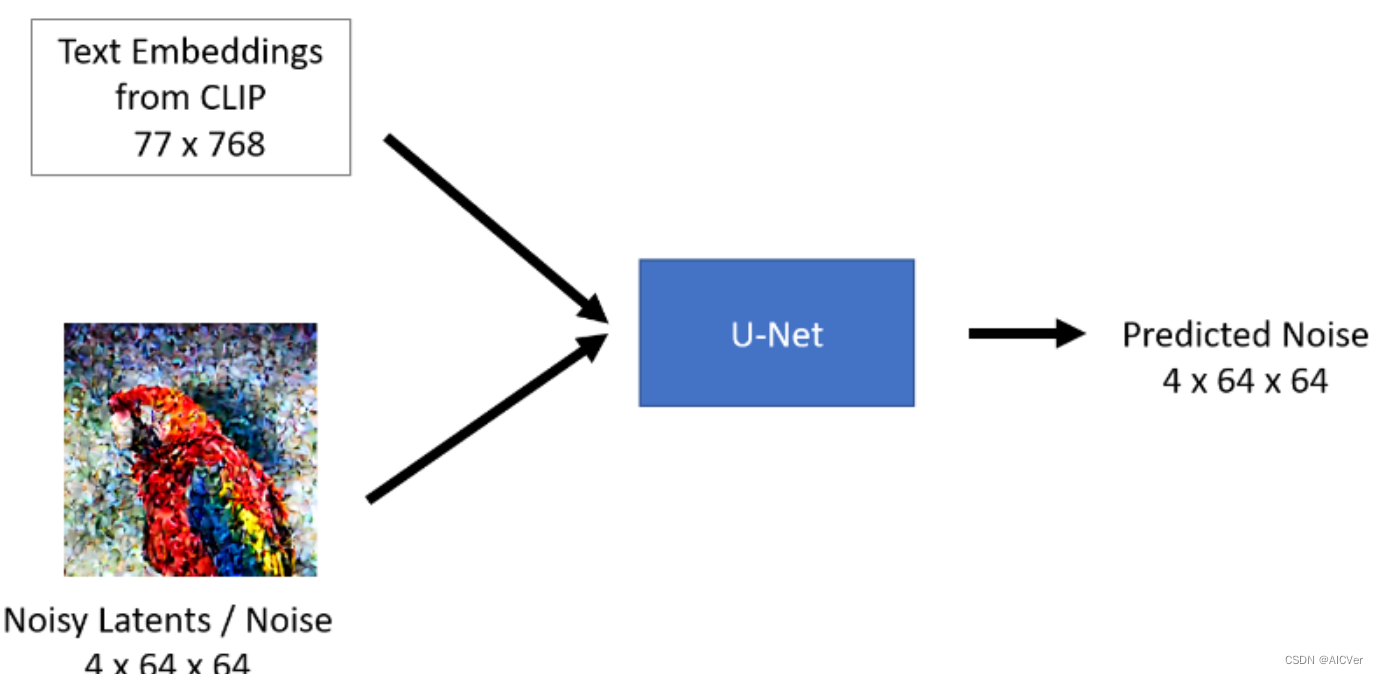
通常来说一个U-Net包含两个输入:
- Noisy latent/Noise : 该Noisy latent主要是由VAE编码器产生并在其基础上添加了噪声;或者如果我们想仅根据文本描述来创建随机的新图像,则可以采用纯噪声作为输入。
- Text embeddings: 基于CLIP的将文本输入提示转化为文本语义嵌入(embedding)
U-Net模型的输出:
- 从包含输入噪声的Noisy Latents中预测其所包含的噪声。换句话说,它预测输出的为Noisy Latents减去de-noised latents后的结果。
Scheduler
scheduler的目的是确定在扩散过程中的给定的步骤中向latent 添加多少噪声。随着step的增大,添加噪声的权重在逐渐减小。