
🎨 前言
最近在B站刷视频的时候,看到很多up主都在用AI生成那种超可爱的Q版大头照,看着就很心动。想着自己也搞一个试试,结果发现这玩意儿比想象中复杂多了...
折腾了好几天,从环境搭建到模型下载,踩了无数个坑,总算是成功跑出了第一张图。虽然效果一般般(毕竟配置有限),但那种成就感还是很爽的。
这篇文章就记录一下我从完全不懂到成功出图的整个过程,包括:
- 环境搭建(各种依赖安装的血泪史)
- 模型下载和使用(主模型、LoRA什么的)
- 实际操作步骤(怎么调参数、写提示词)
- 踩坑经验分享(能让你少走点弯路)
如果你也对AI绘画感兴趣,或者想试试生成自己的专属头像,希望这篇文章能帮到你。有问题的话欢迎评论区讨论,大家一起交流学习。
📖 文章导览
-
这篇文章基本上就是按我自己的折腾顺序来写的,大概分这几个部分
-
⚡ 安装Cuda - 给显卡装上加速器,让AI跑得更快
-
🖥️ 安装stable_diffusion_webUI - 搭建AI绘画的操作界面
-
🔰 生成第一张图 - 先跑个简单的图试试手感
-
🇨🇳 汉化界面 - 把英文界面改成中文,用起来更舒服
-
🎭 生成一只灵梦酱 - 下载专门的模型,生成高质量角色图
-
每一步都有详细的截图和说明,跟着操作基本不会出错。
⚡ 安装Cuda
先安装一下cuda,如果你有就直接跳过这一步
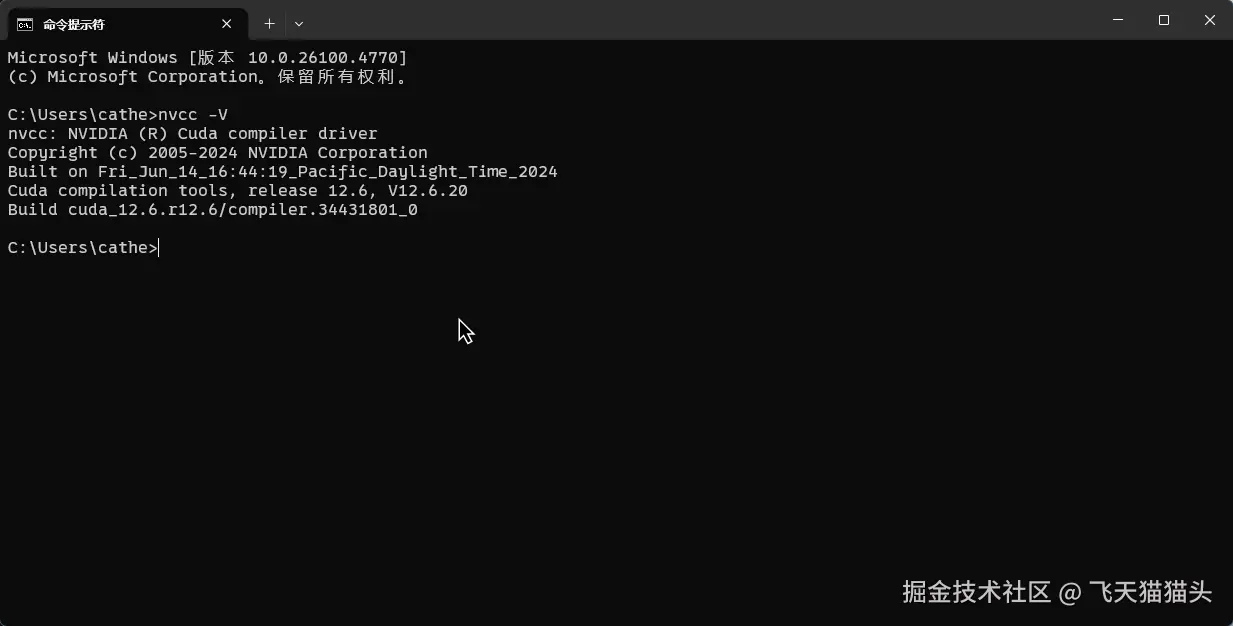
先用nvidia-smi命令查看一下自己支持的cuda版本
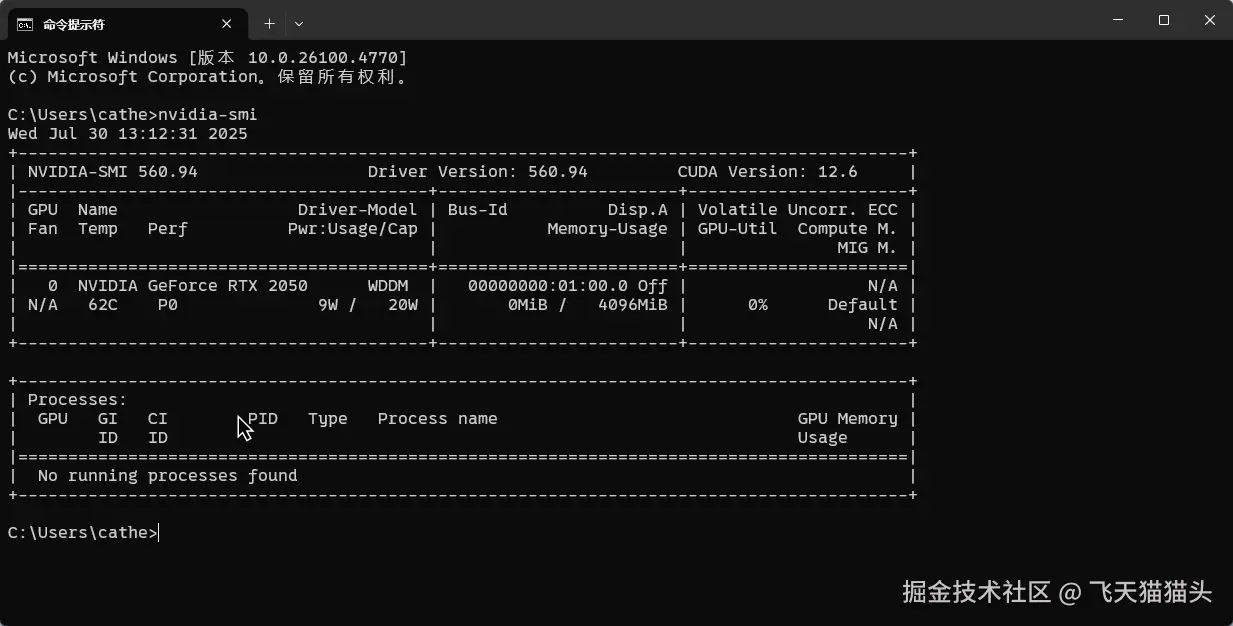
然后去官网下载对应版本的cuda:developer.nvidia.com/
比如我是12.6 那我就下载12.6版本的cudaa
下载之后,直接无脑下一步用精简安装即可
当然你有需要的话,可以自己自定义
等他安装完成就好了
安装完成之后用nvcc -V命令查看一下,如果有出息下面这个版本号,就说明安装成功了
🖥️ 安装stable_diffusion_webUI
🤔 是什么?
Stable Diffusion WebUI 是一个开源、基于浏览器的图形界面,让普通人也能轻松驾驭强大的 Stable Diffusion 模型。你可以将它理解为:
- 可视化操作面板: 告别命令行,所有功能直观呈现于网页。
- 生成器控制台: 提供精细参数,深度控制图像生成过程。
- 模型管理平台: 轻松加载切换社区模型、VAE、LoRA 等资源及扩展插件。

我们后续需要用这个工具来加载模型
📂 拉取代码
shell
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 拉取到本地之后,就可以看到,这是一个python项目,所以我们需要安装一下相关的依赖
📦 安装依赖
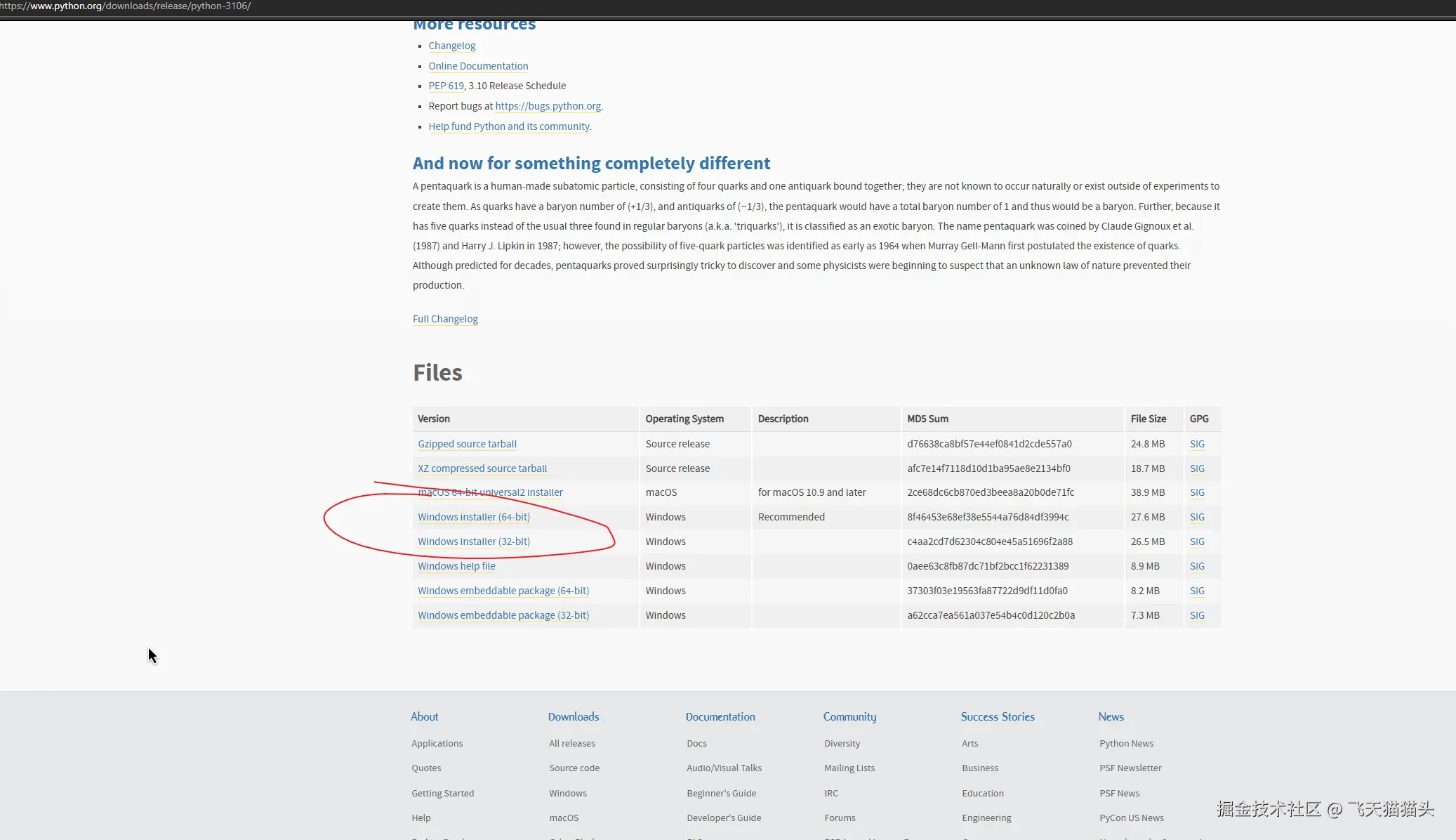
注: 我这里使用的python版本是 Python 3.10.6
首先你要确保你本机安装了python,如果没有得去官网下载一个
版本的话最好一致官方给的说明是更高版本的 Python不支持 torch,推荐使用3.10.6
官网3.10.6版本下载地址:Python Release Python 3.10.6 | Python.org
安装完成之后测试一下

成功打印出版本号,说明安装成功了
然后找到前面用git拉取下来的webui项目
用非管理员模式去运行这个webui-user.bat文件,就普通的点击运行就好了
如果运行之后发现安装依赖很慢,就给pip换一下镜像源
shell
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple再去运行这个文件
等他下载完成就可以了
如果你安装成功第一次会把程序运行起来的
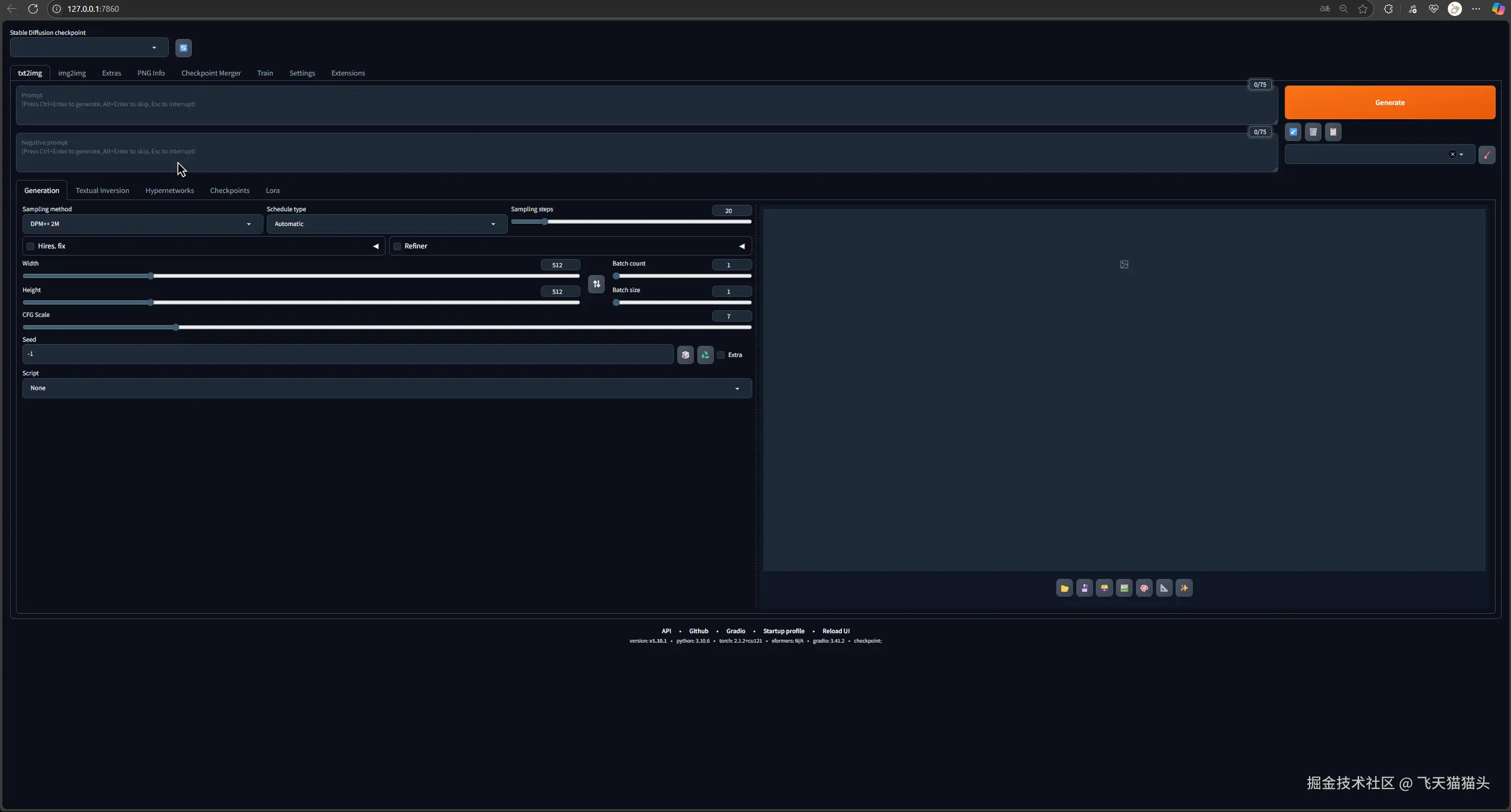
就可以出现上面这个界面
如果没有成功,那就是有一些依赖包下载失败了,可以看一下日志
重新运行几次webui-user.bat文件,一般就解决了
📁 放置模型
这里我下载了一个sd-v1-4.ckpt模型文件,这个不用管,后面会教去哪里下载模型,简单的介绍模型之间的区别
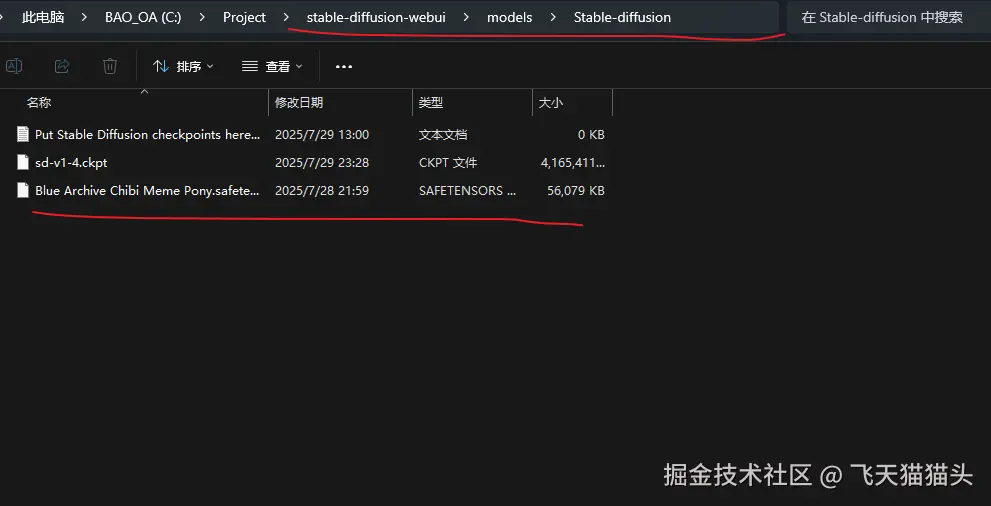
🚀 运行项目
放置这模型之后,再次运行项目,执行webui-user.bat这个文件
一开始会有点慢,第二次就快起来了
成功运行的话,会打开下面这个界面
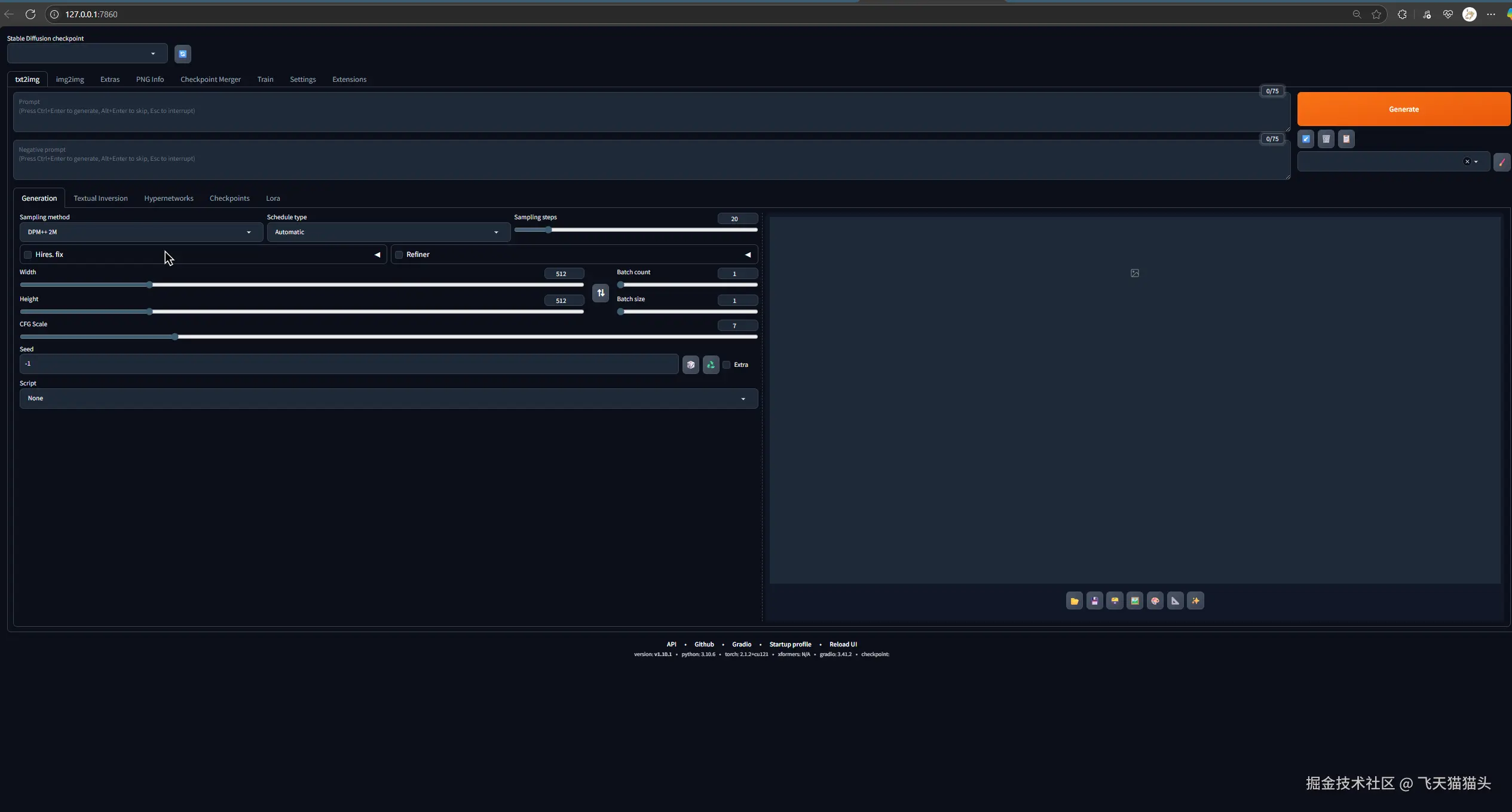
🔰 生成第一张图
第一次运行的运行的时候会自动下载一个默认模型,我这里因为之前加了一个模型进去,所以没有自动安装模型
如果你第一次打开这个,记得在上面选择你的模型,刚开始的时候会一直加载,需要等一会儿

完成之后,你就可以使用设置一些提示词跑一张图出来了
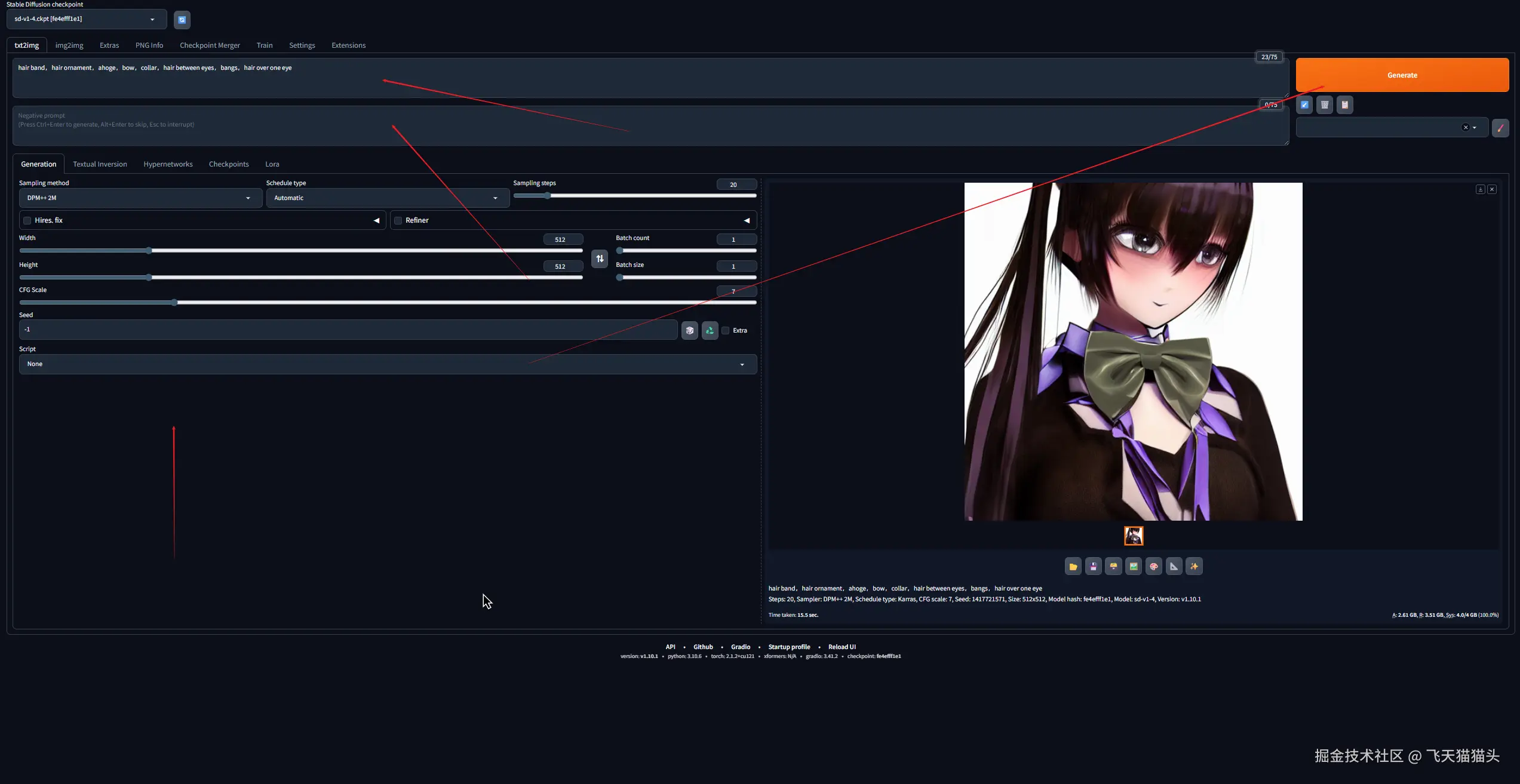
🇨🇳 汉化界面
界面一开始是全英文的,对于有英文不好的小伙伴可以选择汉化,官方有提供插件支持
打开插件选项卡,点下面的加载插件

将标签列表那边的locaalization标签去掉,并在输入框输入zh
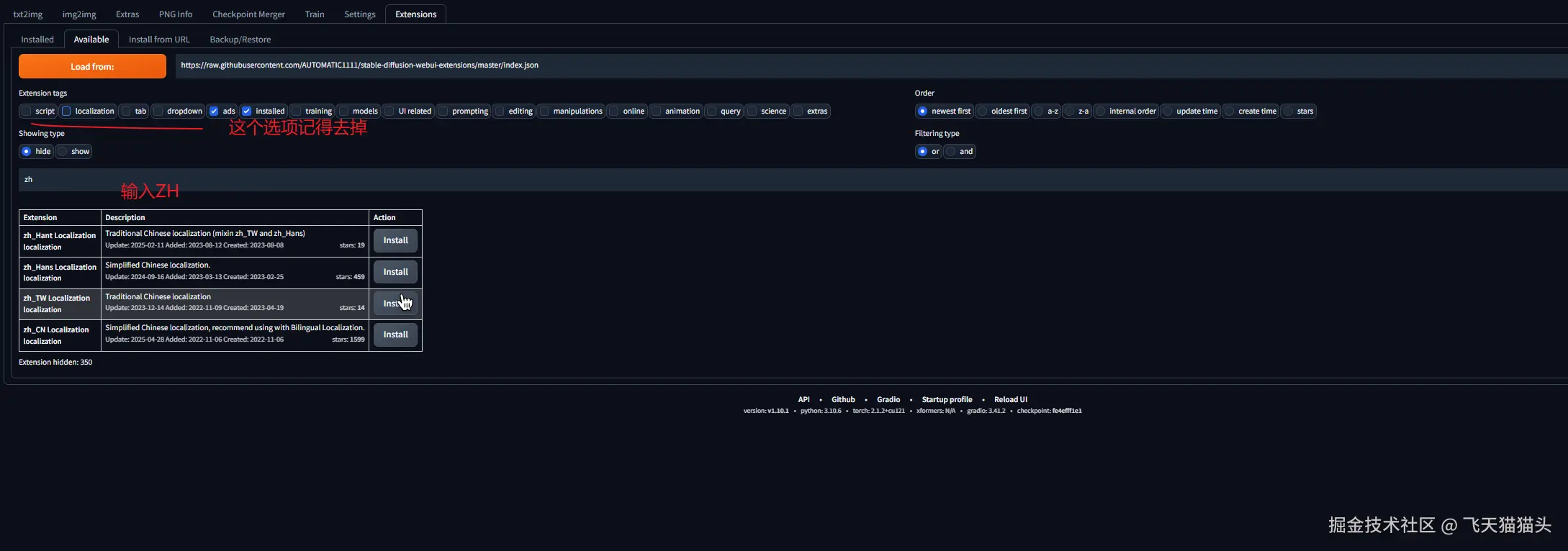
搜索出来的结果中有一个zh_CN Loacalization安装它即可
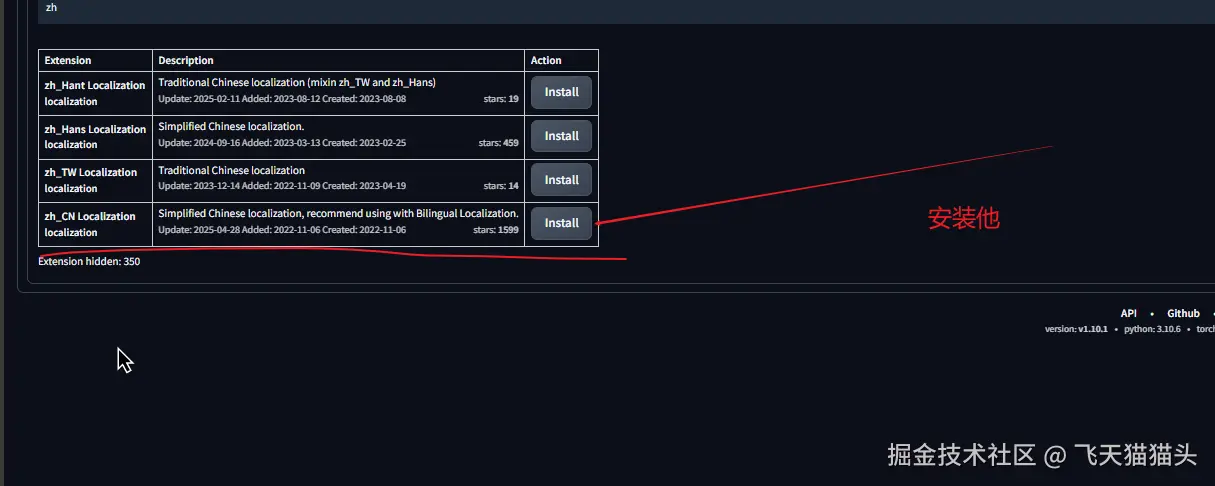
这里可以看到已经安装了它
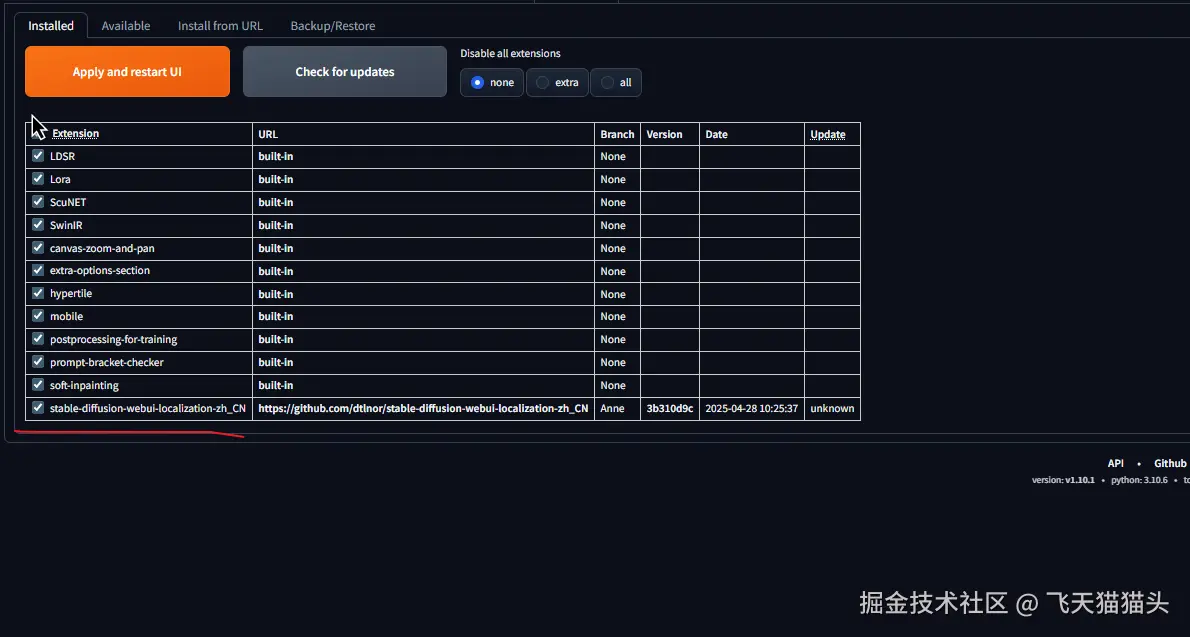
接下来关掉程序,重启项目
打开之后进入到设置选项卡
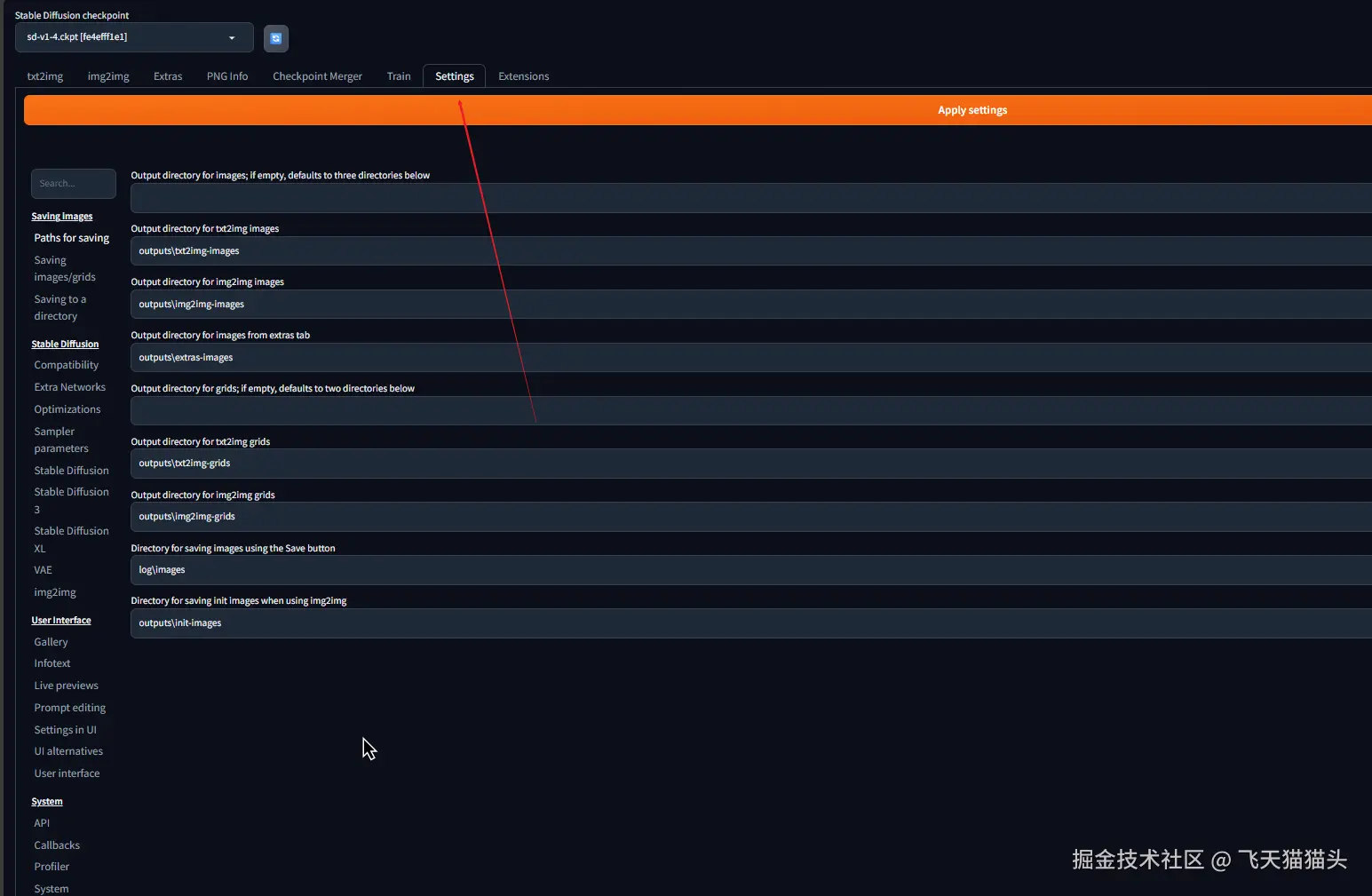
左侧找到 user interface,在顶部的localization中可以看到前面安装的语言包
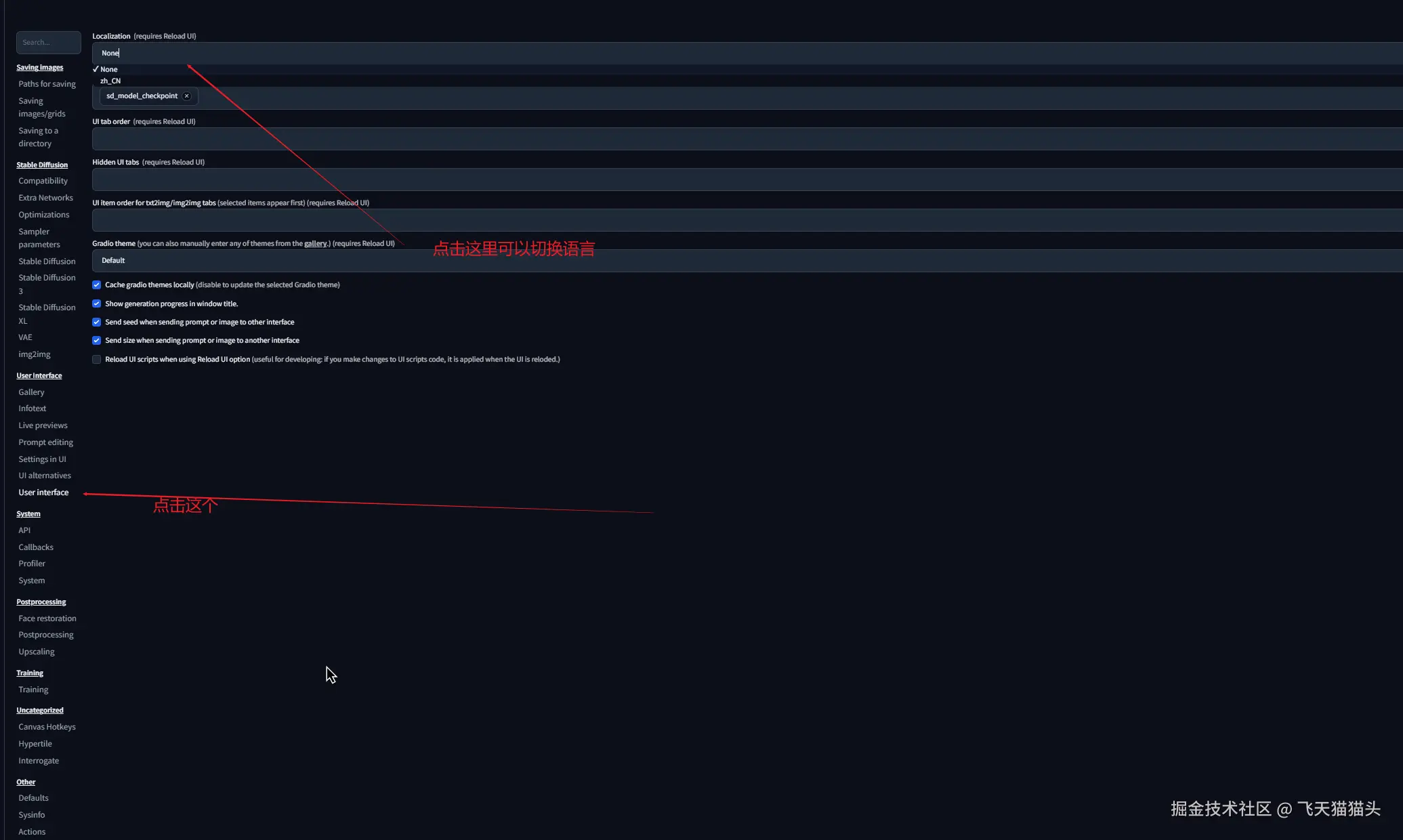
选择语言包之后,保存配置,并且重新加载UI
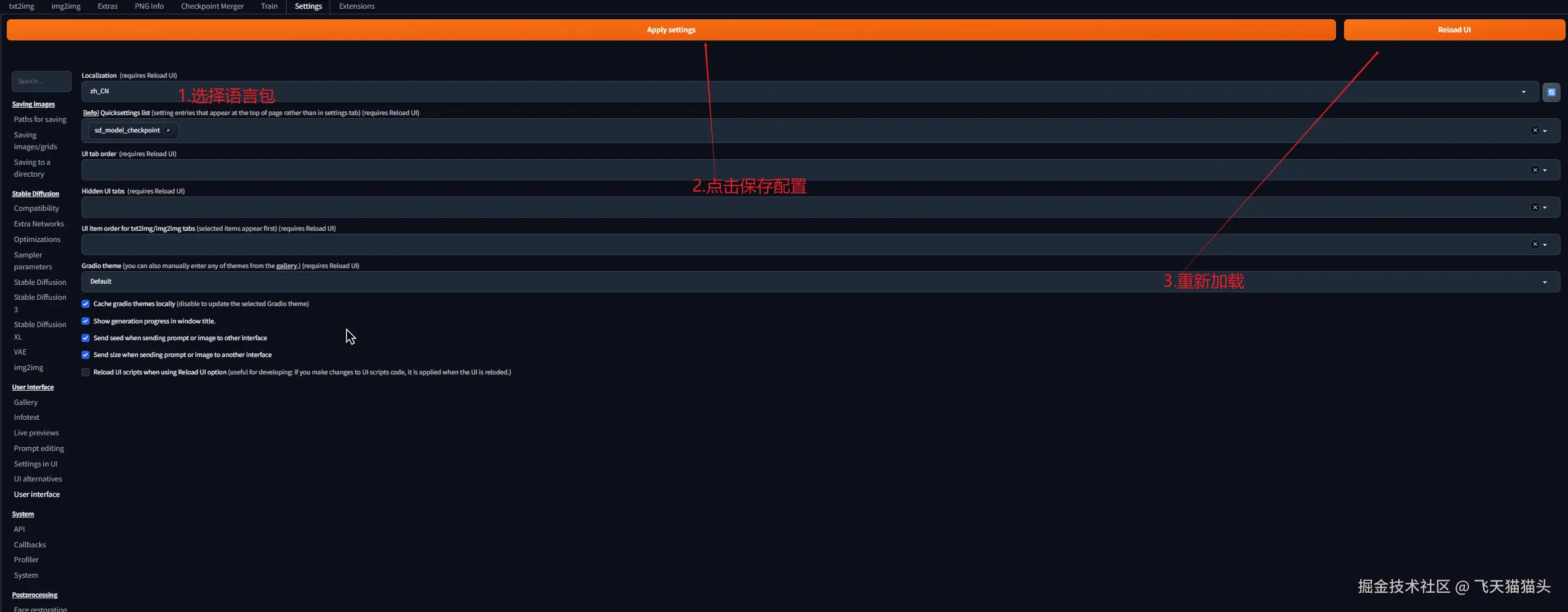
如果你的操作没有问题的话,现在看到的界面就是一个中文界面了
🎭 生成一只灵梦酱
前面跑出来的图不是很好看,接下来要使用别的模型去跑。
下面借助ai介绍一下等下要用的两种模型
🏗️ 主模型(Base Model)
主模型是Stable Diffusion的核心,它就像是一个"通用画师":
- 作用:负责图像的基础生成,包括构图、光影、色彩等基本要素
- 特点:体积较大(通常2-7GB),包含了大量的通用绘画知识
- 比喻:就像一个会画画的AI大脑,掌握了绘画的基本功
前面我跑图用的那个模型就是主模型,大小一般很大,通常都有几G
🎯 Lora模型(Low-Rank Adaptation)
LoRA模型是对主模型的"专业化训练",它就像是给AI画师增加的"专业技能包":
- 作用:在主模型基础上,针对特定角色、风格或概念进行精细化调整
- 特点:体积小(通常几十MB到几百MB),专门用于特定用途
- 比喻:就像给画师上了一堂"如何画灵梦"的专业课
直接理解成微调模型,用来配合主模型用的
🔄 两者的协作关系
主模型 + LoRA模型 = 更精准的生成结果
基础绘画能力 + 角色特化能力 = 高质量的角色图像📥下载模型
上面介绍了两种模型之后,我们就需要去下载这两种模型
模型下载的网站有很多,我这里选择使用civital网站,它里面有很多模型
地址:Civitai: The Home of Open-Source Generative AI
注: 这个网站需要挂梯子访问,如果你没有梯子,可以选择国内的,搜索一下都有一堆
如果你成功访问到了,就可以看到如下界面
注:这个下载的时候会要求登录,你得要有一个谷歌或者github账号,也可以直接注册这个网站的账号, 我是直接用github登录的
然后你就可以在上搜索自己需要的模型了
主模型方面我选择使用AnythingV5NijiMix
下载地址:AnythingV5NijiMix - 25 (BEST) | Stable Diffusion Checkpoint | Civitai
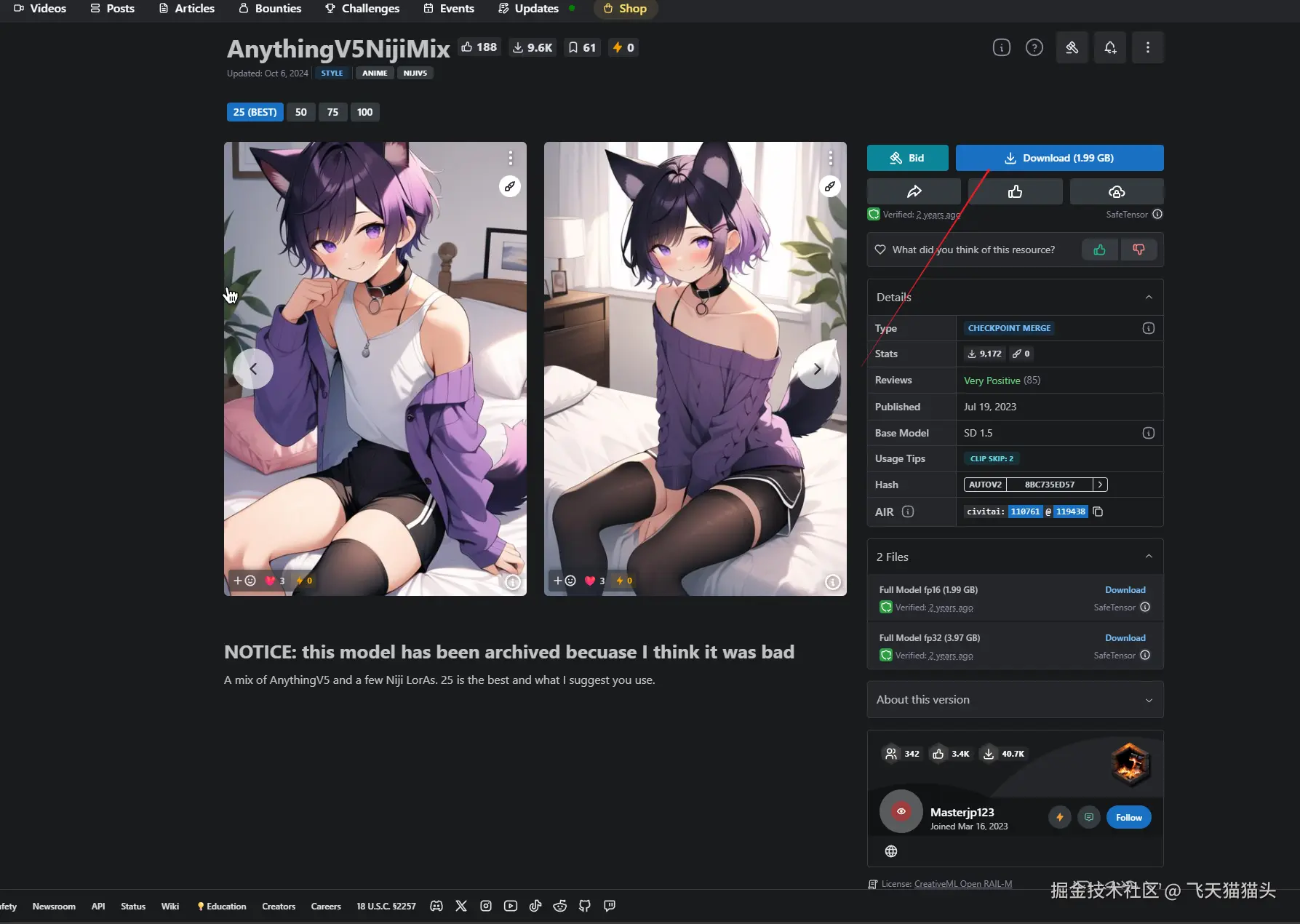
在这个下载界面还可以看到,有一个文件列表
这个根据你自己电脑的配置,选择是否要用fp32的
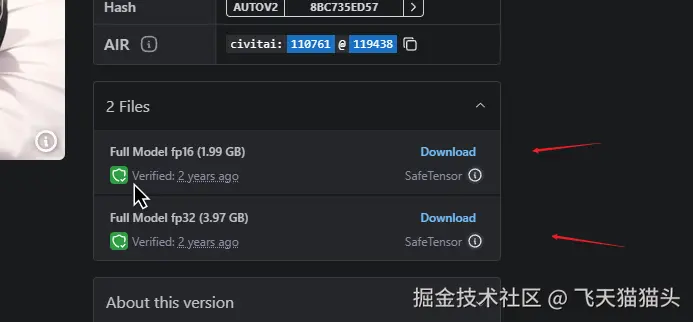
下载了主模型之后,还要去下载一个lora模型
这里我选择Blue Archive Cute Chibi Style Meme,来辅助
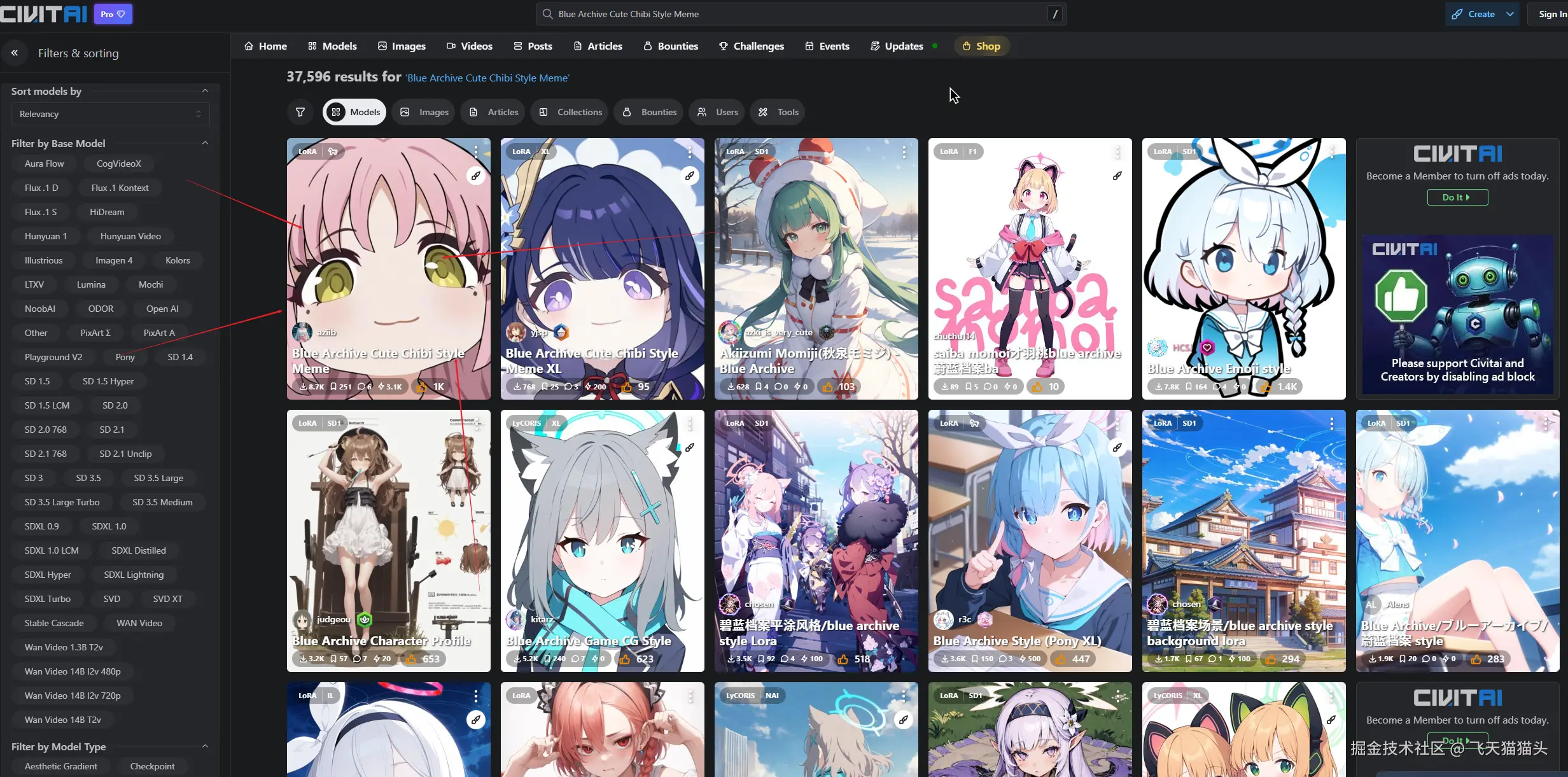
这个第一个就是我们要下载的模型,点击进入这里面把模型下载下来
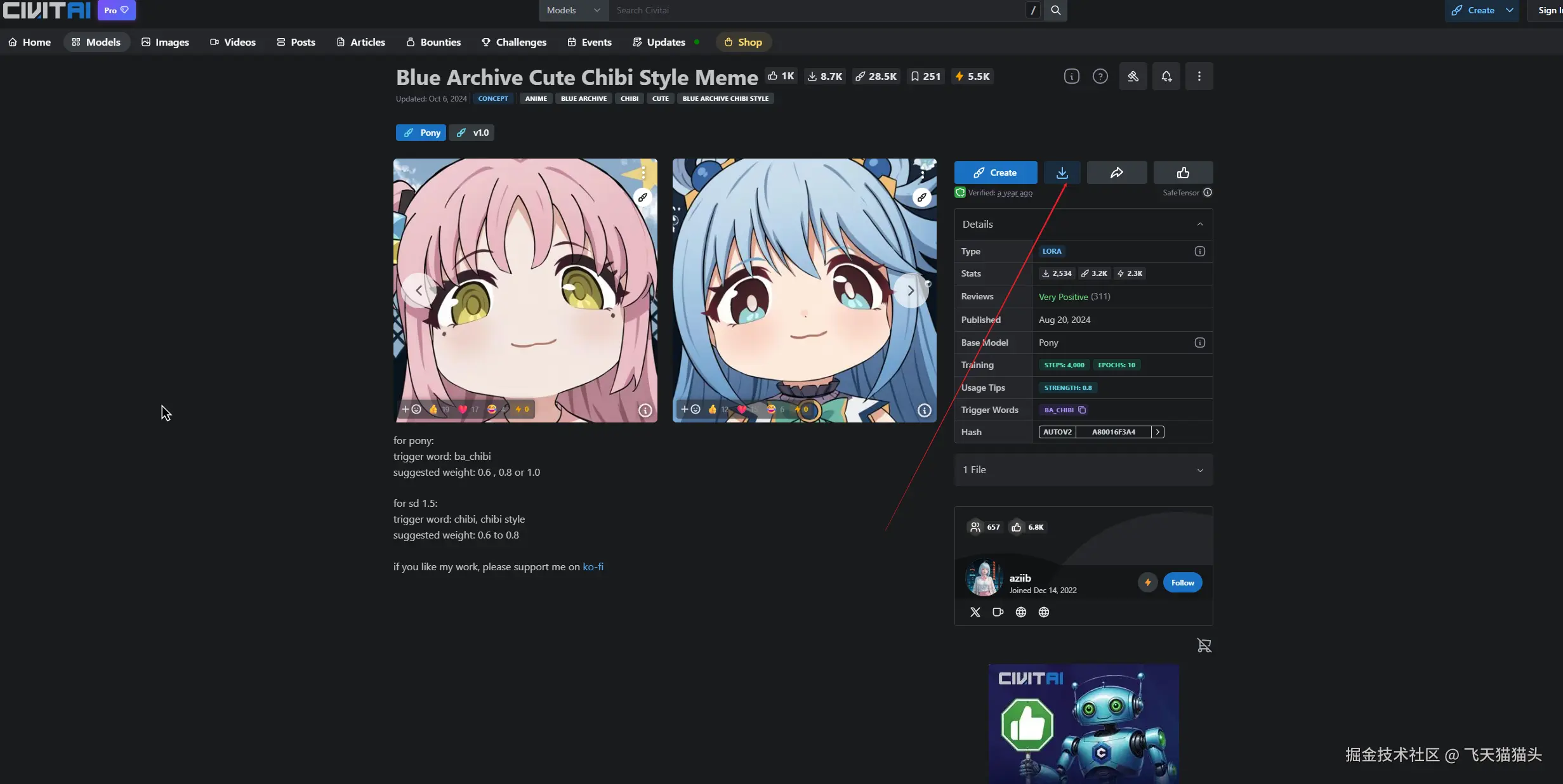
把模型下载下来之后需要放到指定的文件夹里面
把模型放好之后重新运行一下webui-user.bat
进入之后, 左上角记得切换一下我们前面下载的模型,刚切换可能会加载一会儿
生成图片
接下来就可以开始生成图片了
我们需要一些提示词和参数,这里有一个便捷的方法
还是前面那个网站civitai,里面有很多大佬跑出来的图片, 一般都会把配置信息放出来
像这样

我们把它复制下来,黏贴到这个位置
再点击右边的这个,他就会自动按照复制过来的提示词和配置信息,自动修改我们的配置
就像下面这样
搞定这个之后,你就可以点击生成开始跑图了
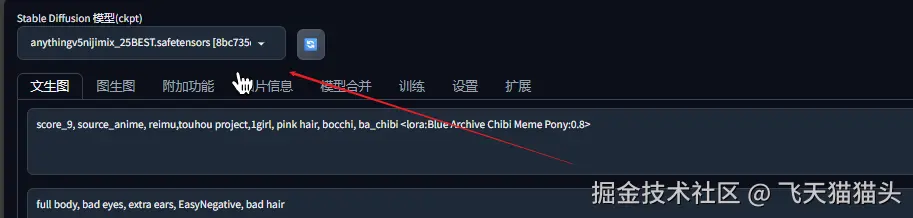
对了这里还有一个地方,前面我们复制过来的提示词中有一句这个,意思就是以0.8的权重调用lora模型 Blue Archive Chibi Meme Pony
makefile
<lora:Blue Archive Chibi Meme Pony:0.8>我们前面下载的那个lora模型就用到这里了
这是固定的调用语法,你也可以用配置的方式去调用
我的效果
这里我自己调整了一下配置和提示词,跑了一张灵梦的图片出来,可惜电脑配置有限,效果就这样了
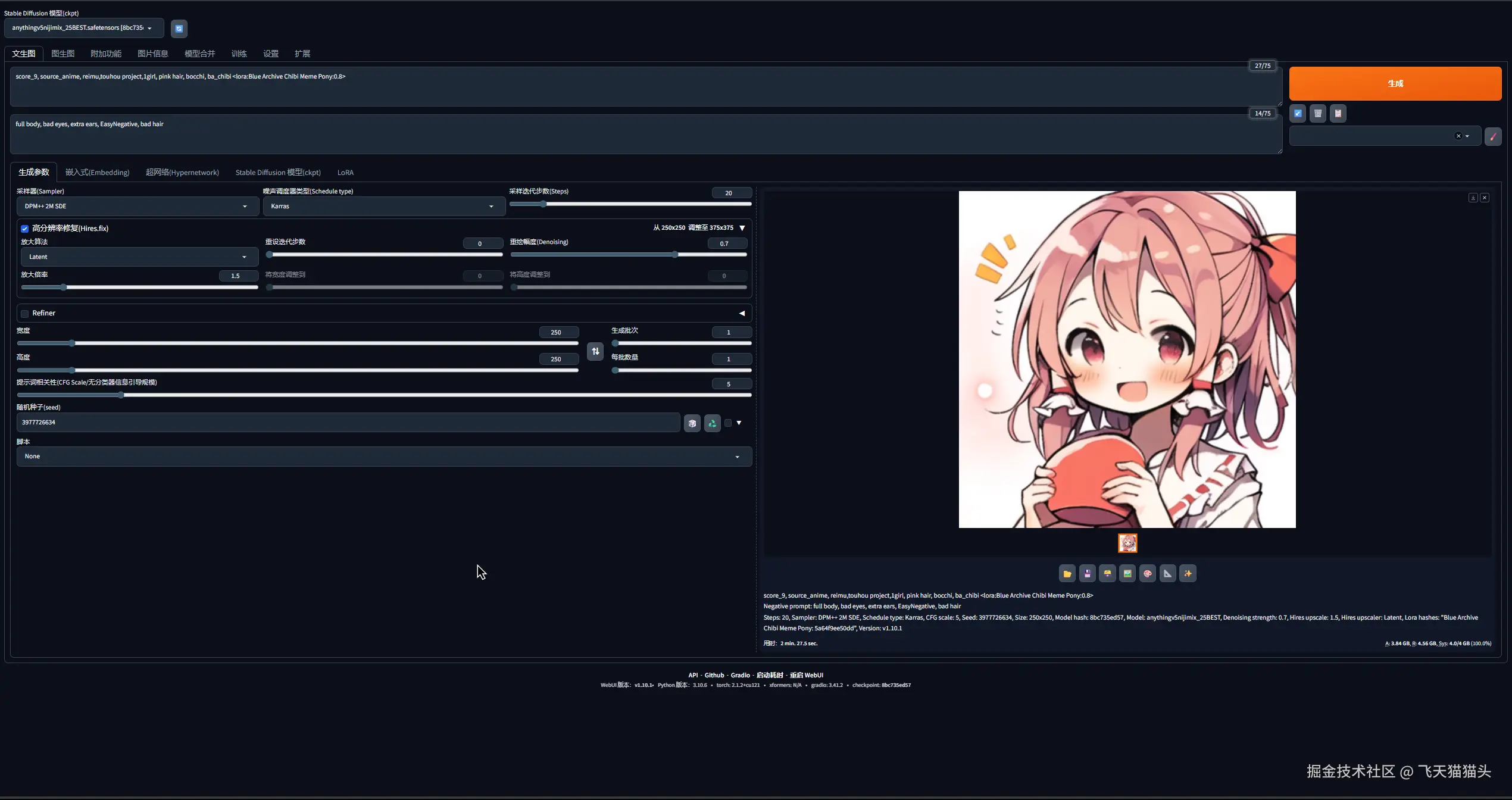
下面附上我用的提示词
正向提示词:
txt
score_9, source_anime, reimu,touhou project,1girl, pink hair, bocchi, ba_chibi <lora:Blue Archive Chibi Meme Pony:0.8>反向提示词
txt
full body, bad eyes, extra ears, EasyNegative, bad hair🎯 结尾
从找资料到运行项目,中途各种问题都有, 终于是给它搞定了。
正常使用的话,其实是会直接去用别人封装好的整合包,可以节省不少时间。不过我是第一次搞ai绘画,所以还是选择从0开始搞。
那么到这里,基本的ai绘画流程就跑通了。之后就是对于一些配置的使用,和参数的调优